W moim poprzednim blogu omawialiśmy różne sposoby wybierania lub skanowania danych z jednej tabeli. Jednak w praktyce pobieranie danych z jednej tabeli nie wystarczy. Wymaga wybrania danych z wielu tabel, a następnie skorelowania między nimi. Korelację tych danych między tabelami nazywamy łączeniem tabel i można to zrobić na różne sposoby. Ponieważ łączenie tabel wymaga danych wejściowych (np. ze skanowania tabeli), nigdy nie może być węzłem liścia w wygenerowanym planie.
Np. rozważ prosty przykład zapytania jako SELECT * FROM TBL1, TBL2 gdzie TBL1.ID> TBL2.ID; i załóżmy, że wygenerowany plan wygląda następująco:
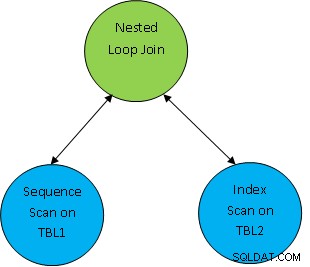
Więc tutaj pierwsze obie tabele są skanowane, a następnie są łączone razem jako zgodnie z warunkiem korelacji jako TBL.ID> TBL2.ID
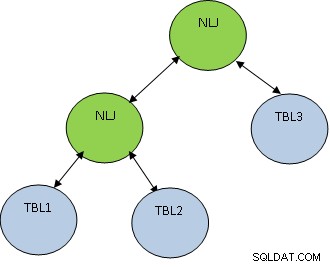
Oprócz metody łączenia, bardzo ważna jest również kolejność łączenia. Rozważ poniższy przykład:
WYBIERZ * Z TBL1, TBL2, TBL3 GDZIE TBL1.ID=TBL2.ID ORAZ TBL2.ID=TBL3.ID;
Rozważ, że TBL1, TBL2 i TBL3 mają odpowiednio 10, 100 i 1000 rekordów.
Warunek TBL1.ID=TBL2.ID zwraca tylko 5 rekordów, podczas gdy TBL2.ID=TBL3.ID zwraca 100 rekordów, wtedy lepiej najpierw połączyć TBL1 i TBL2, aby uzyskać mniejszą liczbę rekordów połączone z TBL3. Plan będzie taki, jak pokazano poniżej:
PostgreSQL obsługuje poniższe rodzaje złączeń:
- Zagnieżdżone łączenie pętli
- Dołącz haszujący
- Połącz Dołącz
Każda z tych metod Join jest równie użyteczna w zależności od zapytania i innych parametrów, np. zapytanie, dane tabeli, klauzula łączenia, selektywność, pamięć itp. Te metody łączenia są implementowane przez większość relacyjnych baz danych.
Stwórzmy tabelę ustawień wstępnych i wypełnijmy danymi, które będą często używane do lepszego wyjaśnienia tych metod skanowania.
postgres=# create table blogtable1(id1 int, id2 int);
CREATE TABLE
postgres=# create table blogtable2(id1 int, id2 int);
CREATE TABLE
postgres=# insert into blogtable1 values(generate_series(1,10000),3);
INSERT 0 10000
postgres=# insert into blogtable2 values(generate_series(1,1000),3);
INSERT 0 1000
postgres=# analyze;
ANALYZEWe wszystkich naszych kolejnych przykładach uwzględniamy domyślny parametr konfiguracyjny, chyba że konkretnie określono inaczej.
Połączenie zagnieżdżonej pętli
Zagnieżdżone łączenie pętli (NLJ) to najprostszy algorytm łączenia, w którym każdy rekord relacji zewnętrznej jest dopasowywany do każdego rekordu relacji wewnętrznej. Połączenie relacji A i B z warunkiem A.ID Zagnieżdżone łączenie pętli (NLJ) to najpopularniejsza metoda łączenia i może być używana prawie w każdym zbiorze danych z dowolnym typem klauzuli łączenia. Ponieważ ten algorytm skanuje wszystkie krotki relacji wewnętrznej i zewnętrznej, jest uważany za najbardziej kosztowną operację łączenia. Zgodnie z powyższą tabelą i danymi, następujące zapytanie spowoduje połączenie zagnieżdżonej pętli, jak pokazano poniżej: Ponieważ klauzula join to „<”, jedyną możliwą metodą łączenia jest tutaj Nested Loop Join. Zwróć uwagę na jeden nowy rodzaj węzła, jakim jest Materialize; węzeł ten pełni rolę pośredniej pamięci podręcznej wyników, tzn. zamiast wielokrotnie pobierać wszystkie krotki relacji, pierwszy raz pobrany wynik jest zapisywany w pamięci, a przy kolejnym żądaniu pobrania krotki zostanie obsłużony z pamięci zamiast ponownie pobierać ze stron relacji . W przypadku, gdy wszystkie krotki nie mieszczą się w pamięci, krotki przelewowe przechodzą do pliku tymczasowego. Jest to głównie przydatne w przypadku Nested Loop Join i do pewnego stopnia w przypadku Merge Join, ponieważ polegają one na ponownym skanowaniu wewnętrznej relacji. Materialize Node nie ogranicza się tylko do buforowania wyników relacji, ale może buforować wyniki dowolnego węzła poniżej w drzewie planu. WSKAZÓWKA:W przypadku, gdy klauzula join ma wartość „=” i wybrano łączenie zagnieżdżone pomiędzy relacją, to naprawdę ważne jest zbadanie, czy można wybrać bardziej wydajną metodę łączenia, taką jak hash lub merge join przez dostrajanie konfiguracji (np. work_mem, ale nie tylko) lub przez dodanie indeksu itp. Niektóre z zapytań mogą nie mieć klauzuli join, w takim przypadku również jedyną opcją przyłączenia jest zagnieżdżone łączenie pętli. Np. rozważ poniższe zapytania zgodnie z danymi konfiguracji wstępnej: Złączenie w powyższym przykładzie jest po prostu iloczynem kartezjańskim obu tabel. Algorytm ten działa w dwóch fazach: Połączenie relacji A i B z warunkiem A.ID =B.ID można przedstawić w następujący sposób: Zgodnie z powyższą tabelą ustawień wstępnych i danymi, następujące zapytanie spowoduje połączenie haszujące, jak pokazano poniżej: Tutaj tablica mieszająca jest tworzona w tabeli blogtable2, ponieważ jest to mniejsza tabela, więc minimalna ilość pamięci wymagana dla tablicy mieszającej i całej tablicy mieszającej może zmieścić się w pamięci. Merge Join to algorytm, w którym każdy rekord relacji zewnętrznej jest dopasowywany do każdego rekordu relacji wewnętrznej, dopóki nie istnieje możliwość dopasowania klauzuli join. Ten algorytm łączenia jest używany tylko wtedy, gdy obie relacje są posortowane, a operatorem klauzuli łączenia jest „=”. Sprzężenie relacji A i B z warunkiem A.ID =B.ID można przedstawić następująco: Przykładowe zapytanie, które spowodowało Hash Join, jak pokazano powyżej, może spowodować Merge Join, jeśli indeks zostanie utworzony dla obu tabel. Dzieje się tak, ponieważ dane tabeli mogą być pobierane w kolejności posortowanej ze względu na indeks, który jest jednym z głównych kryteriów metody Merge Join: Więc, jak widzimy, obie tabele używają skanowania indeksu zamiast skanowania sekwencyjnego, z powodu którego obie tabele będą emitować posortowane rekordy. PostgreSQL obsługuje różne konfiguracje związane z planowaniem, które mogą być użyte do wskazania optymalizatorowi zapytań, aby nie wybierał określonego rodzaju metod złączenia. Jeśli metoda łączenia wybrana przez optymalizator nie jest optymalna, te parametry konfiguracyjne można wyłączyć, aby zmusić optymalizator zapytań do wybrania innego rodzaju metod łączenia. Wszystkie te parametry konfiguracyjne są domyślnie włączone. Poniżej znajdują się parametry konfiguracyjne planera specyficzne dla metod łączenia. Istnieje wiele parametrów konfiguracyjnych związanych z planem używanych do różnych celów. Na tym blogu ograniczamy go tylko do metod dołączania. Te parametry można modyfikować w określonej sesji. Tak więc na wypadek, gdybyśmy chcieli poeksperymentować z planem z określonej sesji, można manipulować tymi parametrami konfiguracyjnymi, a inne sesje będą nadal działać bez zmian. Rozważmy teraz powyższe przykłady łączenia przez scalanie i łączenia mieszającego. Bez indeksu, optymalizator zapytań wybrał opcję Hash Join dla poniższego zapytania, jak pokazano poniżej, ale po użyciu konfiguracji przełącza się na scalanie join nawet bez indeksu: Początkowo wybrano opcję Hash Join, ponieważ dane z tabel nie są sortowane. Aby wybrać plan łączenia scalającego, należy najpierw posortować wszystkie rekordy pobrane z obu tabel, a następnie zastosować łączenie scalające. Tak więc koszt sortowania będzie dodatkowy, a zatem ogólny koszt wzrośnie. Możliwe więc, że w tym przypadku całkowity (w tym zwiększony) koszt jest większy niż całkowity koszt Hash Join, więc wybrano Hash Join. Gdy parametr konfiguracyjny enable_hashjoin zostanie zmieniony na „off”, oznacza to, że optymalizator zapytań bezpośrednio przypisze koszt łączenia haszującego jako koszt wyłączenia (=1.0e10 tj. 100000000000.00). Koszt ewentualnego przyłączenia będzie niższy. Tak więc ten sam wynik zapytania w Merge Join po zmianie enable_hashjoin na „off”, ponieważ nawet wliczając koszt sortowania, całkowity koszt łączenia scalającego jest niższy niż koszt wyłączenia. Teraz rozważmy poniższy przykład: Jak widać powyżej, nawet jeśli parametr konfiguracyjny związany z łączeniem zagnieżdżonej pętli jest zmieniony na „wyłączony”, nadal wybiera zagnieżdżone łączenie pętli, ponieważ nie ma alternatywnej możliwości uzyskania innego rodzaju metody łączenia wybrany. Mówiąc prościej, ponieważ Nested Loop Join jest jedynym możliwym połączeniem, to bez względu na koszt, zawsze będzie zwycięzcą (tak samo, jak byłem zwycięzcą wyścigu na 100 m, gdybym biegał sam…:-)). Zwróć także uwagę na różnicę w kosztach w pierwszym i drugim planie. Pierwszy plan pokazuje rzeczywisty koszt łączenia zagnieżdżonej pętli, ale drugi pokazuje koszt wyłączenia tego samego. Wszystkie rodzaje metod łączenia PostgreSQL są przydatne i są wybierane na podstawie charakteru zapytania, danych, klauzuli join itp. W przypadku, gdy zapytanie nie działa zgodnie z oczekiwaniami, tj. metody join nie są wybrany zgodnie z oczekiwaniami, użytkownik może bawić się różnymi dostępnymi parametrami konfiguracji planu i sprawdzić, czy czegoś brakuje.For each tuple r in A
For each tuple s in B
If (r.ID < s.ID)
Emit output tuple (r,s)postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 < bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (bt1.id1 < bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# explain select * from blogtable1, blogtable2;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..125162.50 rows=10000000 width=16)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(4 rows)Dołącz haszujący
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
------------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (bt1.id1 = bt2.id1)
-> Seq Scan on blogtable1 bt1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 bt2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows) Scal Dołącz
For each tuple r in A
For each tuple s in B
If (r.ID = s.ID)
Emit output tuple (r,s)
Break;
If (r.ID > s.ID)
Continue;
Else
Break;postgres=# create index idx1 on blogtable1(id1);
CREATE INDEX
postgres=# create index idx2 on blogtable2(id1);
CREATE INDEX
postgres=# explain select * from blogtable1 bt1, blogtable2 bt2 where bt1.id1 = bt2.id1;
QUERY PLAN
---------------------------------------------------------------------------------------
Merge Join (cost=0.56..90.36 rows=1000 width=16)
Merge Cond: (bt1.id1 = bt2.id1)
-> Index Scan using idx1 on blogtable1 bt1 (cost=0.29..318.29 rows=10000 width=8)
-> Index Scan using idx2 on blogtable2 bt2 (cost=0.28..43.27 rows=1000 width=8)
(4 rows)Konfiguracja
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Hash Join (cost=27.50..220.00 rows=1000 width=16)
Hash Cond: (blogtable1.id1 = blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Hash (cost=15.00..15.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_hashjoin to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 = blogtable2.id1;
QUERY PLAN
----------------------------------------------------------------------------
Merge Join (cost=874.21..894.21 rows=1000 width=16)
Merge Cond: (blogtable1.id1 = blogtable2.id1)
-> Sort (cost=809.39..834.39 rows=10000 width=8)
Sort Key: blogtable1.id1
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Sort (cost=64.83..67.33 rows=1000 width=8)
Sort Key: blogtable2.id1
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(8 rows)postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=0.00..150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)
postgres=# set enable_nestloop to off;
SET
postgres=# explain select * from blogtable1, blogtable2 where blogtable1.id1 < blogtable2.id1;
QUERY PLAN
--------------------------------------------------------------------------
Nested Loop (cost=10000000000.00..10000150162.50 rows=3333333 width=16)
Join Filter: (blogtable1.id1 < blogtable2.id1)
-> Seq Scan on blogtable1 (cost=0.00..145.00 rows=10000 width=8)
-> Materialize (cost=0.00..20.00 rows=1000 width=8)
-> Seq Scan on blogtable2 (cost=0.00..15.00 rows=1000 width=8)
(5 rows)Wnioski