W każdym z silników relacyjnych baz danych wymagane jest wygenerowanie najlepszego możliwego planu, który odpowiada wykonaniu zapytania przy jak najmniejszym nakładzie czasu i zasobów. Ogólnie rzecz biorąc, wszystkie bazy danych generują plany w formacie struktury drzewa, gdzie węzeł liścia każdego drzewa planów jest nazywany węzłem skanowania tabeli. Ten konkretny węzeł planu odpowiada algorytmowi używanemu do pobierania danych z tabeli bazowej.
Rozważmy na przykład prosty przykład zapytania jako SELECT * FROM TBL1, TBL2 gdzie TBL2.ID>1000; i załóżmy, że wygenerowany plan wygląda następująco:
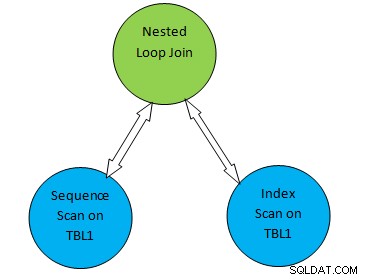
W powyższym drzewie planu „Skanowanie sekwencyjne na TBL1” i „ Index Scan on TBL2” odpowiada metodzie skanowania tabeli odpowiednio w tabeli TBL1 i TBL2. Tak więc zgodnie z tym planem TBL1 będzie pobierany sekwencyjnie z odpowiednich stron, a dostęp do TBL2 można uzyskać za pomocą skanowania indeksu.
Wybór odpowiedniej metody skanowania w ramach planu jest bardzo ważny z punktu widzenia ogólnej wydajności zapytań.
Zanim przejdziemy do wszystkich typów metod skanowania obsługiwanych przez PostgreSQL, przyjrzyjmy się niektórym z głównych kluczowych punktów, które będą często używane podczas przeglądania bloga.
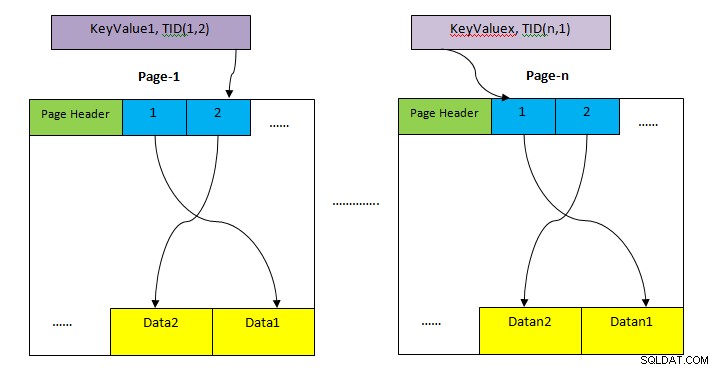
- KOTA: Powierzchnia do przechowywania całego rzędu stołu. Jest to podzielone na wiele stron (jak pokazano na powyższym obrazku), a każda strona ma domyślnie 8 KB. Na każdej stronie każdy wskaźnik elementu (np. 1, 2, ….) wskazuje na dane na stronie.
- Przechowywanie indeksów: Ta pamięć przechowuje tylko wartości kluczy, tj. wartości kolumn zawarte w indeksie. Jest to również podzielone na wiele stron, a każdy rozmiar strony to domyślnie 8 KB.
- Identyfikator krotki (TID): TID to 6 bajtowa liczba składająca się z dwóch części. Pierwsza część to 4-bajtowy numer strony, a pozostałe 2-bajtowe indeksy krotek wewnątrz strony. Połączenie tych dwóch liczb jednoznacznie wskazuje miejsce przechowywania określonej krotki.
Obecnie PostgreSQL obsługuje poniższe metody skanowania, za pomocą których można odczytać wszystkie wymagane dane z tabeli:
- Skanowanie sekwencyjne
- Skanowanie indeksu
- Skanuj tylko indeks
- Skanowanie mapy bitowej
- Skanowanie TID
Każda z tych metod skanowania jest równie przydatna w zależności od zapytania i innych parametrów, np. kardynalność tabeli, selektywność tabeli, koszt dysku we/wy, losowy koszt we/wy, koszt sekwencji we/wy itp. Stwórzmy tabelę ustawień wstępnych i wypełnijmy danymi, które będą często używane, aby lepiej wyjaśnić te metody skanowania .
postgres=# CREATE TABLE demotable (num numeric, id int);
CREATE TABLE
postgres=# CREATE INDEX demoidx ON demotable(num);
CREATE INDEX
postgres=# INSERT INTO demotable SELECT random() * 1000, generate_series(1, 1000000);
INSERT 0 1000000
postgres=# analyze;
ANALYZEW tym przykładzie wstawiany jest milion rekordów, a następnie tabela jest analizowana, aby wszystkie statystyki były aktualne.
Skanowanie sekwencyjne
Jak sama nazwa wskazuje, skanowanie sekwencyjne tabeli odbywa się poprzez sekwencyjne skanowanie wszystkich wskaźników elementów na wszystkich stronach odpowiednich tabel. Jeśli więc dla danej tabeli jest 100 stron, a na każdej stronie znajduje się 1000 rekordów, w ramach skanowania sekwencyjnego pobierze 100*1000 rekordów i sprawdzi, czy pasuje zgodnie z poziomem izolacji, a także zgodnie z klauzulą predykatu. Więc nawet jeśli tylko 1 rekord zostanie wybrany jako część skanowania całej tabeli, będzie musiał przeskanować 100 000 rekordów, aby znaleźć zakwalifikowany rekord zgodnie z warunkiem.
Zgodnie z powyższą tabelą i danymi, następujące zapytanie spowoduje sekwencyjne skanowanie, ponieważ większość danych jest wybierana.
postgres=# explain SELECT * FROM demotable WHERE num < 21000;
QUERY PLAN
--------------------------------------------------------------------
Seq Scan on demotable (cost=0.00..17989.00 rows=1000000 width=15)
Filter: (num < '21000'::numeric)
(2 rows)UWAGA
Chociaż bez obliczenia i porównania kosztów planu, prawie niemożliwe jest określenie, jakiego rodzaju skany zostaną użyte. Aby jednak użyć skanowania sekwencyjnego, przynajmniej poniższe kryteria powinny być zgodne:
- Brak dostępnego indeksu dla klucza, który jest częścią predykatu.
- Większość wierszy jest pobieranych jako część zapytania SQL.
WSKAZÓWKI
W przypadku, gdy pobieranych jest tylko kilka % wierszy, a predykat znajduje się w jednej (lub więcej) kolumnie, spróbuj ocenić wydajność z indeksem lub bez.
Skanowanie indeksu
W przeciwieństwie do skanowania sekwencyjnego, skanowanie indeksu nie pobiera wszystkich rekordów sekwencyjnie. Raczej używa innej struktury danych (w zależności od typu indeksu) odpowiadającej indeksowi użytemu w zapytaniu i lokalizuje wymagane dane (zgodnie z predykatem) z bardzo minimalnymi skanami. Następnie wpis znaleziony przy użyciu skanowania indeksu wskazuje bezpośrednio na dane w obszarze sterty (jak pokazano na powyższym rysunku), które są następnie pobierane w celu sprawdzenia widoczności zgodnie z poziomem izolacji. Tak więc skanowanie indeksu składa się z dwóch kroków:
- Pobierz dane ze struktury danych powiązanej z indeksem. Zwraca TID odpowiednich danych w stercie.
- Następnie odpowiednia strona sterty jest bezpośrednio dostępna w celu uzyskania pełnych danych. Ten dodatkowy krok jest wymagany z następujących powodów:
- Zapytanie mogło zażądać pobrania większej liczby kolumn niż to, co jest dostępne w odpowiednim indeksie.
- Informacje o widoczności nie są zachowywane wraz z danymi indeksu. Aby więc sprawdzić widoczność danych zgodnie z poziomem izolacji, musi uzyskać dostęp do danych sterty.
Teraz możemy się zastanawiać, dlaczego nie zawsze używać skanowania indeksu, jeśli jest ono tak wydajne. Jak wiemy, wszystko wiąże się z pewnymi kosztami. Tutaj koszt związany jest z typem I/O, który wykonujemy. W przypadku skanowania indeksowego zaangażowane jest losowe we/wy, ponieważ każdy rekord znaleziony w pamięci indeksowej musi pobrać odpowiednie dane z pamięci HEAP, podczas gdy w przypadku skanowania sekwencyjnego zaangażowane jest we/wy sekwencyjne, które zajmuje około 25% losowego taktowania we/wy.
Tak więc skanowanie indeksu powinno być wybierane tylko wtedy, gdy ogólny zysk przewyższa obciążenie poniesione z powodu losowego kosztu we/wy.
Zgodnie z powyższą tabelą i danymi, następujące zapytanie spowoduje skanowanie indeksu, ponieważ wybierany jest tylko jeden rekord. Tak więc losowe we/wy jest mniej, a wyszukiwanie odpowiedniego rekordu jest szybkie.
postgres=# explain SELECT * FROM demotable WHERE num = 21000;
QUERY PLAN
--------------------------------------------------------------------------
Index Scan using demoidx on demotable (cost=0.42..8.44 rows=1 width=15)
Index Cond: (num = '21000'::numeric)
(2 rows)Skanowanie tylko indeksu
Skanowanie tylko indeksu jest podobne do skanowania indeksu z wyjątkiem drugiego kroku, tj. jak sama nazwa wskazuje, skanuje tylko strukturę danych indeksu. Istnieją dwa dodatkowe warunki wstępne, aby wybrać opcję Skanowanie tylko indeksu w porównaniu ze skanowaniem indeksu:
- Zapytanie powinno pobierać tylko kluczowe kolumny, które są częścią indeksu.
- Wszystkie krotki (rekordy) na wybranej stronie sterty powinny być widoczne. Jak omówiono w poprzedniej sekcji, struktura danych indeksu nie zachowuje informacji o widoczności, więc aby wybrać dane tylko z indeksu, powinniśmy unikać sprawdzania widoczności, a to może się zdarzyć, jeśli wszystkie dane tej strony są uważane za widoczne.
Następujące zapytanie spowoduje tylko skanowanie indeksu. Mimo że to zapytanie jest prawie podobne pod względem wybierania liczby rekordów, ale ponieważ wybierane jest tylko pole kluczowe (tj. „liczba”), wybierze opcję Skanowanie tylko indeksu.
postgres=# explain SELECT num FROM demotable WHERE num = 21000;
QUERY PLAN
-----------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..8.44 rows=1 Width=11)
Index Cond: (num = '21000'::numeric)
(2 rows)Skanowanie mapy bitowej
Skanowanie mapy bitowej to połączenie skanowania indeksowego i skanowania sekwencyjnego. Próbuje rozwiązać problem skanowania indeksu, ale nadal zachowuje jego pełną zaletę. Jak omówiono powyżej, dla wszystkich danych znalezionych w strukturze danych indeksu, musi znaleźć odpowiednie dane na stronie sterty. Więc alternatywnie musi raz pobrać stronę indeksu, a następnie stronę sterty, co powoduje wiele losowych operacji we/wy. Tak więc metoda skanowania bitmapy wykorzystuje zalety skanowania indeksu bez losowych operacji we/wy. Działa to na dwóch poziomach, jak poniżej:
- Skanowanie indeksu mapy bitowej:Najpierw pobiera wszystkie dane indeksu ze struktury danych indeksu i tworzy mapę bitową wszystkich TID. Dla łatwiejszego zrozumienia możesz uznać, że ta bitmapa zawiera hash wszystkich stron (haszowany na podstawie numeru strony), a każdy wpis na stronie zawiera tablicę wszystkich przesunięć na tej stronie.
- Skanowanie sterty bitmapy:Jak sama nazwa wskazuje, odczytuje bitmapę stron, a następnie skanuje dane ze sterty odpowiadającej zapisanej stronie i przesunięciu. Na koniec sprawdza widoczność i predykat itp. i zwraca krotkę na podstawie wyników wszystkich tych sprawdzeń.
Poniższe zapytanie spowoduje skanowanie mapy bitowej, ponieważ nie wybiera bardzo niewielu rekordów (tj. za dużo dla skanowania indeksu) i jednocześnie nie wybiera ogromnej liczby rekordów (tj. za mało dla sekwencyjnego skanowanie).
postgres=# explain SELECT * FROM demotable WHERE num < 210;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on demotable (cost=5883.50..14035.53 rows=213042 width=15)
Recheck Cond: (num < '210'::numeric)
-> Bitmap Index Scan on demoidx (cost=0.00..5830.24 rows=213042 width=0)
Index Cond: (num < '210'::numeric)
(4 rows)Teraz rozważ poniższe zapytanie, które wybiera taką samą liczbę rekordów, ale tylko pola kluczowe (tj. tylko kolumny indeksu). Ponieważ wybiera tylko klucz, nie musi odnosić się do stron sterty dla innych części danych, a zatem nie ma losowych operacji we/wy. Więc to zapytanie wybierze Skanowanie tylko indeksu zamiast Skanowanie bitmapy.
postgres=# explain SELECT num FROM demotable WHERE num < 210;
QUERY PLAN
---------------------------------------------------------------------------------------
Index Only Scan using demoidx on demotable (cost=0.42..7784.87 rows=208254 width=11)
Index Cond: (num < '210'::numeric)
(2 rows)Skanowanie TID
TID, jak wspomniano powyżej, to liczba 6 bajtów, która składa się z 4-bajtowego numeru strony i pozostałych 2-bajtowych indeksów krotek wewnątrz strony. Skanowanie TID jest bardzo specyficznym rodzajem skanowania w PostgreSQL i jest wybierane tylko wtedy, gdy w predykacie zapytania występuje TID. Rozważ poniższe zapytanie demonstrujące skanowanie TID:
postgres=# select ctid from demotable where id=21000;
ctid
----------
(115,42)
(1 row)
postgres=# explain select * from demotable where ctid='(115,42)';
QUERY PLAN
----------------------------------------------------------
Tid Scan on demotable (cost=0.00..4.01 rows=1 width=15)
TID Cond: (ctid = '(115,42)'::tid)
(2 rows)Więc tutaj w predykacie, zamiast podawać dokładną wartość kolumny jako warunek, podawany jest TID. Jest to coś podobnego do wyszukiwania opartego na ROWID w Oracle.
Bonus
Wszystkie metody skanowania są szeroko stosowane i znane. Ponadto te metody skanowania są dostępne w prawie wszystkich relacyjnych bazach danych. Istnieje jednak inna metoda skanowania, która jest ostatnio przedmiotem dyskusji w społeczności PostgreSQL, a także została ostatnio dodana w innych relacyjnych bazach danych. Nazywa się „Loose IndexScan” w MySQL, „Index Skip Scan” w Oracle i „Jump Scan” w DB2.
Ta metoda skanowania jest używana w konkretnym scenariuszu, w którym wybrana jest odrębna wartość wiodącej kolumny klucza indeksu B-Tree. W ramach tego skanowania unika przechodzenia przez wszystkie równe wartości kolumny klucza, a raczej po prostu przechodzi przez pierwszą unikalną wartość, a następnie przeskakuje do następnej dużej.
Ta praca jest nadal w toku w PostgreSQL pod wstępną nazwą „Index Skip Scan” i możemy się spodziewać, że zobaczymy to w przyszłej wersji.