Dane są prawdopodobnie jednym z najcenniejszych aktywów w firmie. Z tego powodu zawsze powinniśmy mieć plan odzyskiwania po awarii (DRP), aby zapobiec utracie danych w razie wypadku lub awarii sprzętu.
Kopia zapasowa jest najprostszą formą DR, jednak nie zawsze może wystarczyć do zagwarantowania akceptowalnego celu punktu odzyskiwania (RPO). Zaleca się przechowywanie co najmniej trzech kopii zapasowych w różnych miejscach fizycznych.
Najlepsze praktyki nakazują, aby pliki kopii zapasowych były przechowywane lokalnie na serwerze bazy danych (dla szybszego odzyskiwania), drugie na scentralizowanym serwerze kopii zapasowych, a ostatnie w chmurze.
W tym blogu przyjrzymy się, jakie opcje zapewnia Amazon AWS do przechowywania kopii zapasowych PostgreSQL w chmurze i pokażemy kilka przykładów, jak to zrobić.
Informacje o Amazon AWS
Amazon AWS jest jednym z najbardziej zaawansowanych dostawców usług w chmurze na świecie pod względem funkcji i usług, z milionami klientów. Jeśli chcemy uruchomić nasze bazy danych PostgreSQL na Amazon AWS, mamy kilka opcji...
-
Amazon RDS:Pozwala nam w łatwy i szybki sposób tworzyć, zarządzać i skalować bazę danych PostgreSQL (lub inne technologie baz danych) w chmurze.
-
Amazon Aurora:jest to baza danych kompatybilna z PostgreSQL zbudowana dla chmury. Według strony internetowej AWS jest ona trzy razy szybsza niż standardowe bazy danych PostgreSQL.
-
Amazon EC2:Jest to usługa sieciowa, która zapewnia skalowalną moc obliczeniową w chmurze. Zapewnia pełną kontrolę nad zasobami obliczeniowymi i pozwala skonfigurować i skonfigurować wszystko w swoich instancjach, od systemu operacyjnego po aplikacje.
Ale w rzeczywistości nie musimy mieć naszych baz danych działających na Amazon, aby przechowywać tutaj nasze kopie zapasowe.
Przechowywanie kopii zapasowych w Amazon AWS
Istnieją różne opcje przechowywania kopii zapasowej PostgreSQL w AWS. Jeśli uruchamiamy naszą bazę danych PostgreSQL na AWS, mamy więcej opcji i (ponieważ jesteśmy w tej samej sieci) może być również szybszy. Zobaczmy, jak AWS może pomóc nam przechowywać nasze kopie zapasowe.
AWS CLI
Najpierw przygotujmy nasze środowisko do testowania różnych opcji AWS. W naszych przykładach użyjemy lokalnego serwera PostgreSQL 11, działającego na CentOS 7. Tutaj musimy zainstalować AWS CLI zgodnie z instrukcjami z tej strony.
Kiedy mamy zainstalowany nasz interfejs AWS CLI, możemy go przetestować z wiersza poleceń:
[example@sqldat.com ~]# aws --version
aws-cli/1.16.225 Python/2.7.5 Linux/4.15.18-14-pve botocore/1.12.215Teraz następnym krokiem jest skonfigurowanie naszego nowego klienta uruchamiającego polecenie aws z opcją configure.
[example@sqldat.com ~]# aws configure
AWS Access Key ID [None]: AKIA7TMEO21BEBR1A7HR
AWS Secret Access Key [None]: SxrCECrW/RGaKh2FTYTyca7SsQGNUW4uQ1JB8hRp
Default region name [None]: us-east-1
Default output format [None]:Aby uzyskać te informacje, możesz przejść do sekcji IAM AWS i sprawdzić bieżącego użytkownika lub, jeśli wolisz, utworzyć nowego do tego zadania.
Po tym jesteśmy gotowi do użycia AWS CLI, aby uzyskać dostęp do naszych usług Amazon AWS.
Amazon S3
Jest to prawdopodobnie najczęściej używana opcja przechowywania kopii zapasowych w chmurze. Amazon S3 może przechowywać i pobierać dowolną ilość danych z dowolnego miejsca w Internecie. Jest to prosta usługa przechowywania, która oferuje niezwykle trwałą, wysoce dostępną i nieskończenie skalowalną infrastrukturę przechowywania danych przy niskich kosztach.
Amazon S3 zapewnia prosty interfejs usługi sieciowej, którego można używać do przechowywania i pobierania dowolnej ilości danych, w dowolnym czasie, z dowolnego miejsca w sieci oraz (za pomocą AWS CLI lub AWS SDK) może zintegrować go z różnymi systemami i językami programowania.
Jak z tego korzystać
Amazon S3 korzysta z wiader. Są to wyjątkowe pojemniki na wszystko, co przechowujesz w Amazon S3. Tak więc pierwszym krokiem jest uzyskanie dostępu do konsoli zarządzania Amazon S3 i utworzenie nowego zasobnika.
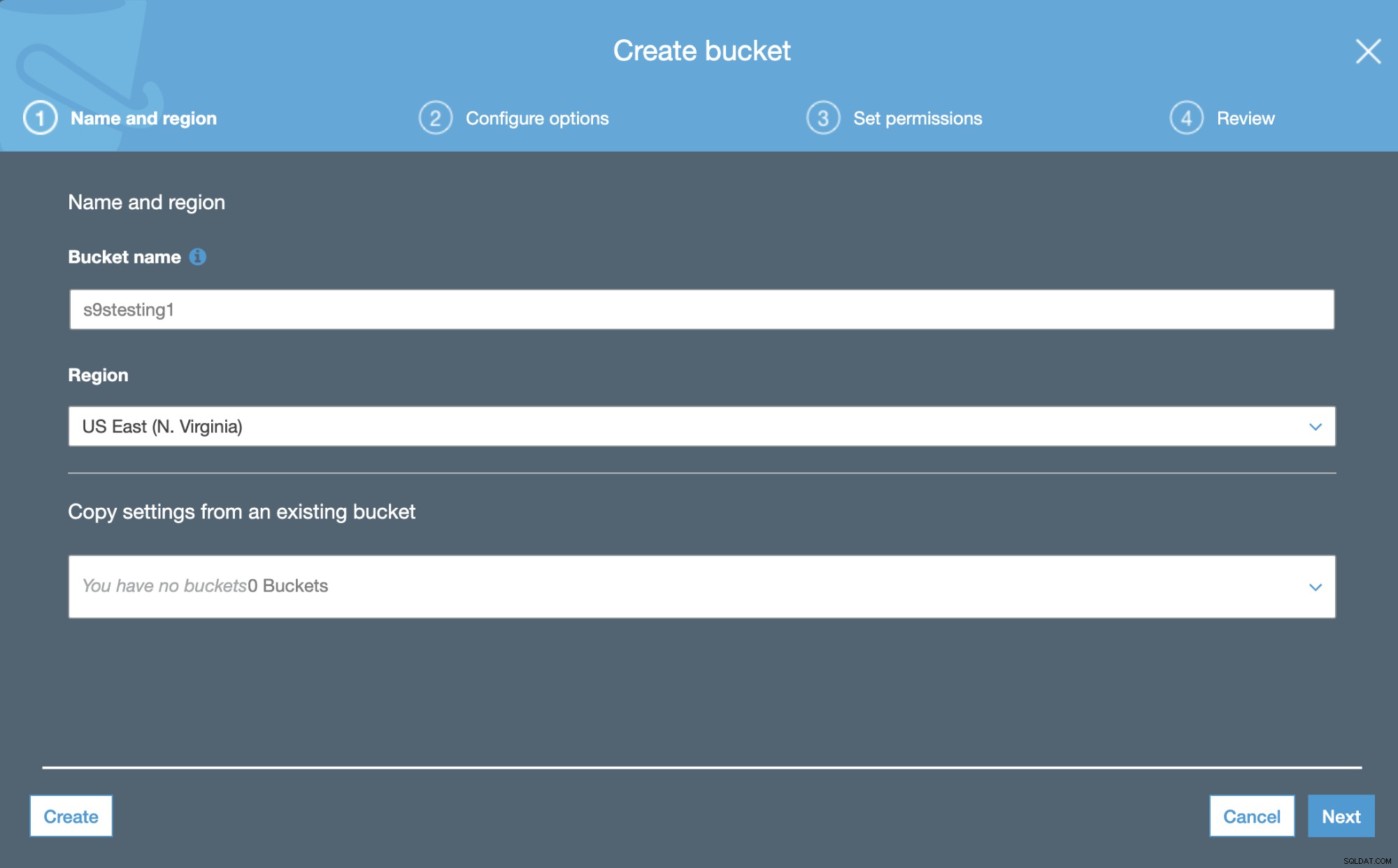
W pierwszym kroku wystarczy dodać nazwę zasobnika i Region AWS.
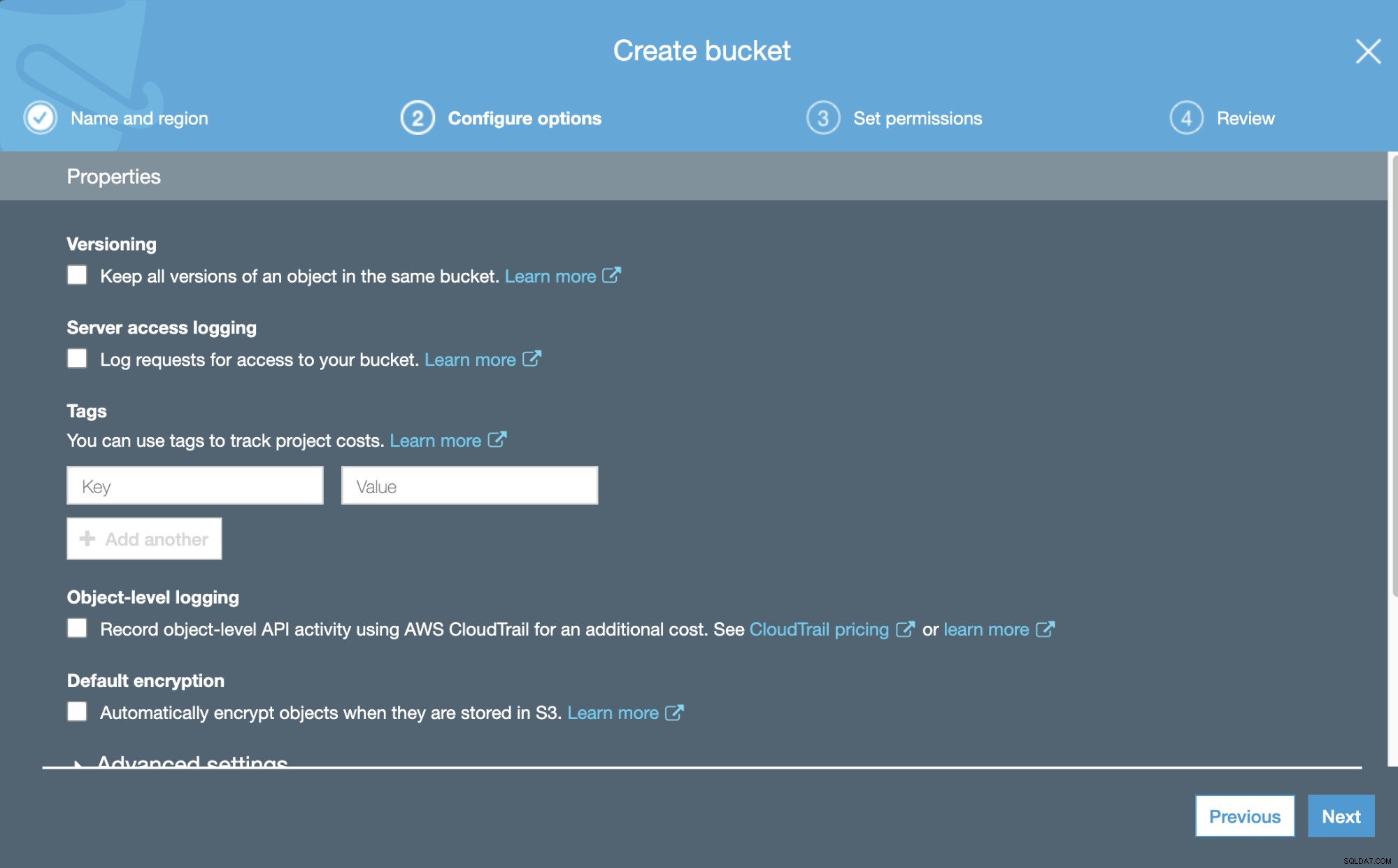
Teraz możemy skonfigurować niektóre szczegóły dotyczące naszego nowego zasobnika, takie jak przechowywanie wersji i logowanie.

Następnie możemy określić uprawnienia dla tego nowego zasobnika.
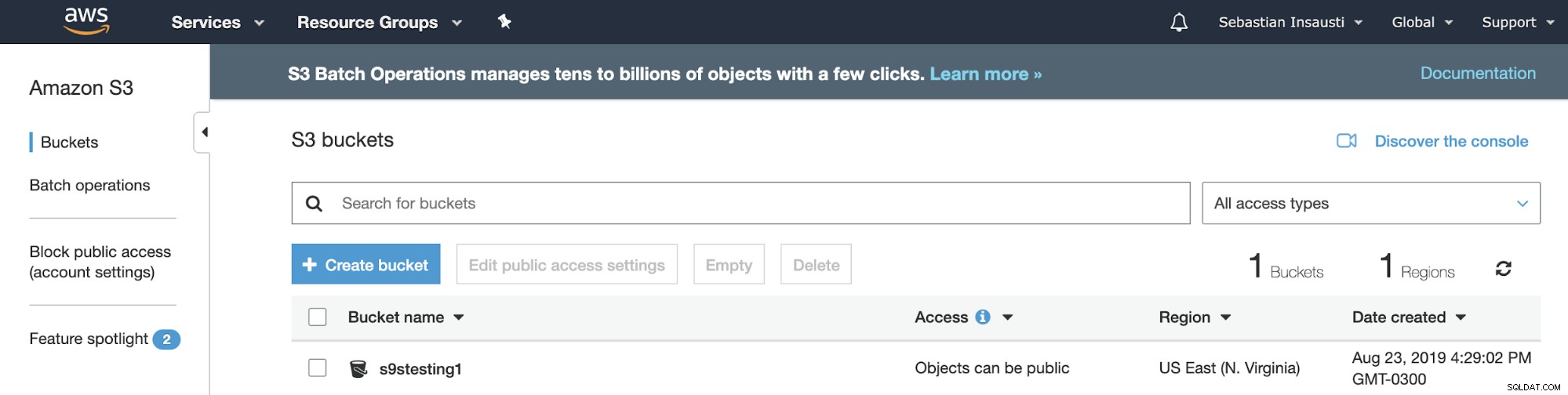
Teraz mamy utworzony nasz Bucket, zobaczmy, jak możemy go użyć do przechowuj nasze kopie zapasowe PostgreSQL.
Najpierw przetestujmy naszego klienta podłączając go do S3.
[example@sqldat.com ~]# aws s3 ls
2019-08-23 19:29:02 s9stesting1To działa! W poprzednim poleceniu wyświetlamy listę aktualnie utworzonych zasobników.
Teraz możemy po prostu przesłać kopię zapasową do usługi S3. W tym celu możemy użyć polecenia aws sync lub aws cp.
[example@sqldat.com ~]# aws s3 sync /root/backups/BACKUP-5/ s3://s9stesting1/backups/
upload: backups/BACKUP-5/cmon_backup.metadata to s3://s9stesting1/backups/cmon_backup.metadata
upload: backups/BACKUP-5/cmon_backup.log to s3://s9stesting1/backups/cmon_backup.log
upload: backups/BACKUP-5/base.tar.gz to s3://s9stesting1/backups/base.tar.gz
[example@sqldat.com ~]#
[example@sqldat.com ~]# aws s3 cp /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz s3://s9stesting1/backups/
upload: backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz to s3://s9stesting1/backups/pg_dump_2019-08-23_205919.sql.gz
[example@sqldat.com ~]# Możemy sprawdzić zawartość Bucket na stronie internetowej AWS.
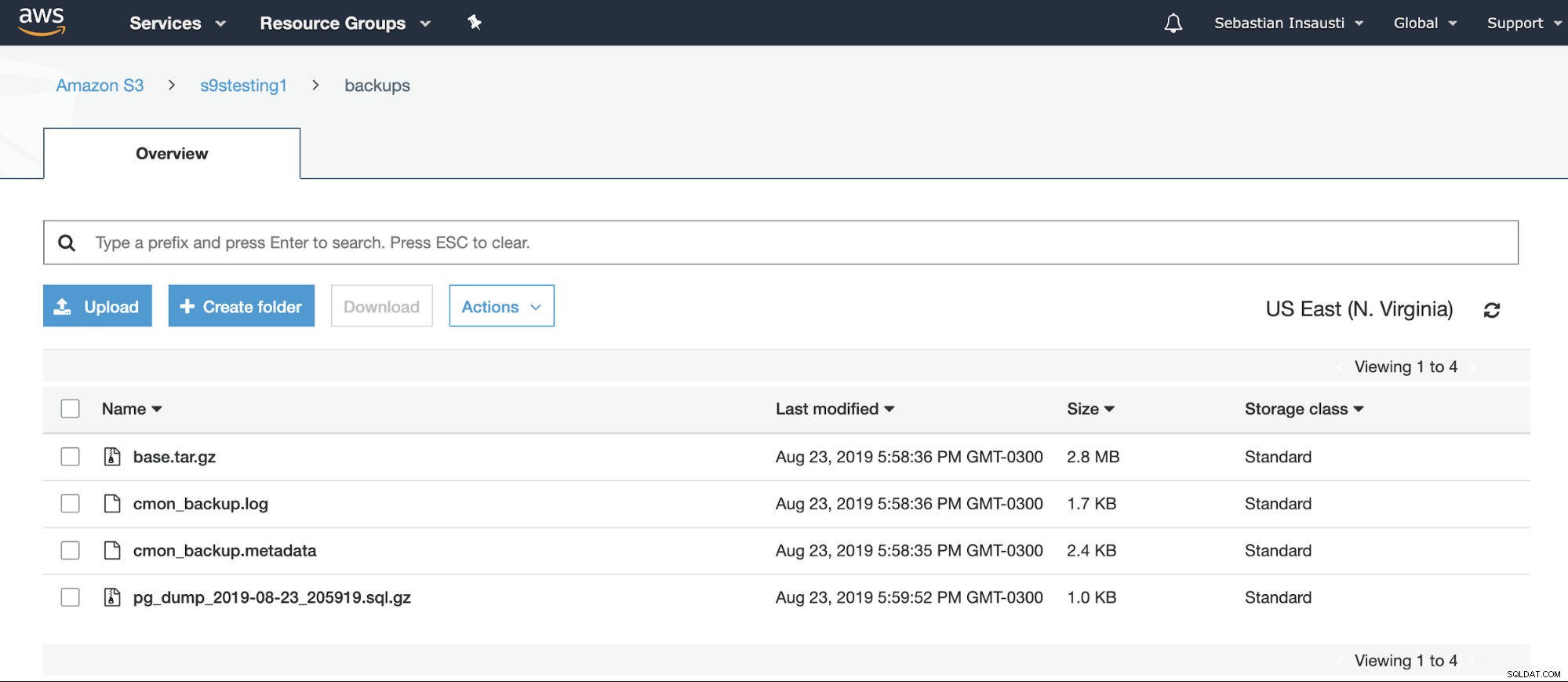
Lub nawet za pomocą interfejsu AWS CLI.
[example@sqldat.com ~]# aws s3 ls s3://s9stesting1/backups/
2019-08-23 19:29:31 0
2019-08-23 20:58:36 2974633 base.tar.gz
2019-08-23 20:58:36 1742 cmon_backup.log
2019-08-23 20:58:35 2419 cmon_backup.metadata
2019-08-23 20:59:52 1028 pg_dump_2019-08-23_205919.sql.gzWięcej informacji o AWS S3 CLI znajdziesz w oficjalnej dokumentacji AWS.
Lodowiec Amazon S3
To jest tańsza wersja Amazon S3. Główną różnicą między nimi jest prędkość i dostępność. Możesz użyć Amazon S3 Glacier, jeśli koszt przechowywania musi pozostać niski i nie potrzebujesz milisekundowego dostępu do swoich danych. Użycie to kolejna ważna różnica między nimi.
Jak z tego korzystać
Zamiast wiader, Amazon S3 Glacier używa krypt. To pojemnik do przechowywania dowolnego przedmiotu. Tak więc pierwszym krokiem jest uzyskanie dostępu do konsoli zarządzania lodowcem Amazon S3 i utworzenie nowego skarbca.
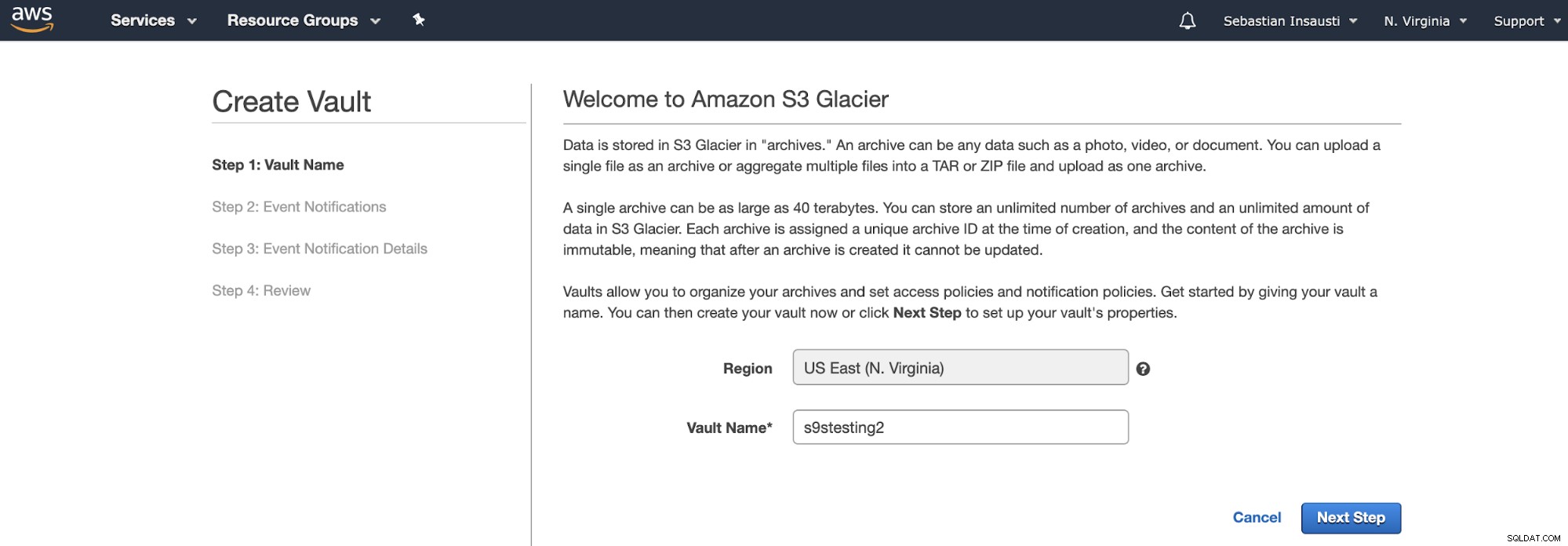
Tutaj musimy dodać nazwę skarbca i region, a w w następnym kroku możemy włączyć powiadomienia o zdarzeniach korzystające z usługi Amazon Simple Notification Service (Amazon SNS).
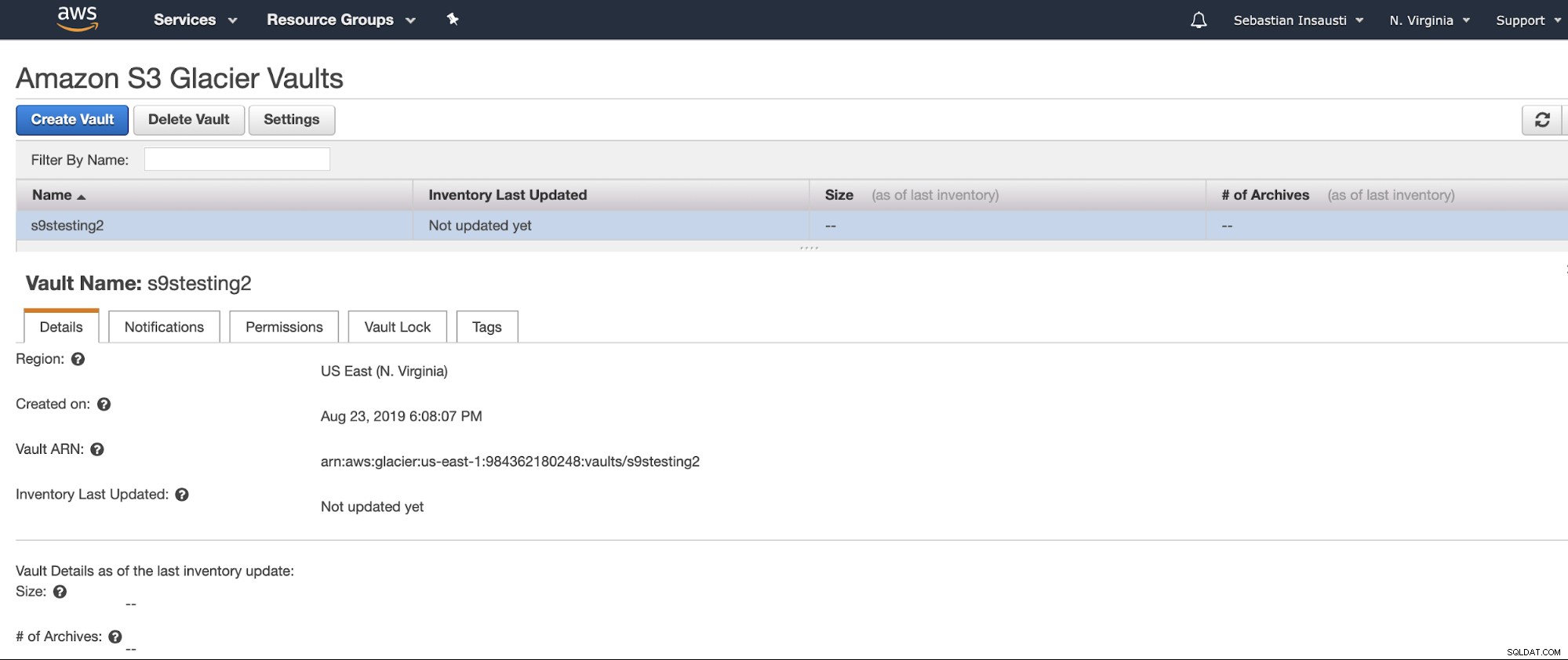
Teraz mamy utworzony nasz Vault, możemy uzyskać do niego dostęp z AWS CLI .
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 0,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"NumberOfArchives": 0,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}To działa. Więc teraz możemy przesłać naszą kopię zapasową tutaj.
[example@sqldat.com ~]# aws glacier upload-archive --body /root/backups/BACKUP-6/pg_dump_2019-08-23_205919.sql.gz --account-id - --archive-description "Backup upload test" --vault-name s9stesting2
{
"archiveId": "ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg",
"checksum": "258faaa90b5139cfdd2fb06cb904fe8b0c0f0f80cba9bb6f39f0d7dd2566a9aa",
"location": "/984227183428/vaults/s9stesting2/archives/ddgCJi_qCJaIVinEW-xRl4I_0u2a8Ge5d2LHfoFBlO6SLMzG_0Cw6fm-OLJy4ZH_vkSh4NzFG1hRRZYDA-QBCEU4d8UleZNqsspF6MI1XtZFOo_bVcvIorLrXHgd3pQQmPbxI8okyg"
}Jedną ważną rzeczą jest to, że stan Vault jest aktualizowany raz dziennie, więc powinniśmy poczekać, aż zobaczymy przesłany plik.
[example@sqldat.com ~]# aws glacier describe-vault --account-id - --vault-name s9stesting2
{
"SizeInBytes": 33796,
"VaultARN": "arn:aws:glacier:us-east-1:984227183428:vaults/s9stesting2",
"LastInventoryDate": "2019-08-24T06:37:02.598Z",
"NumberOfArchives": 1,
"CreationDate": "2019-08-23T21:08:07.943Z",
"VaultName": "s9stesting2"
}Tutaj mamy nasz plik przesłany do naszego S3 Glacier Vault.
Więcej informacji o AWS Glacier CLI znajdziesz w oficjalnej dokumentacji AWS.
EC2
Ta opcja przechowywania kopii zapasowych jest droższa i czasochłonna, ale jest przydatna, jeśli chcesz mieć pełną kontrolę nad środowiskiem przechowywania kopii zapasowych i chcesz wykonywać niestandardowe zadania na kopiach zapasowych (np. Weryfikacja kopii zapasowych .)
Amazon EC2 (Elastic Compute Cloud) to usługa internetowa, która zapewnia skalowalną pojemność obliczeniową w chmurze. Zapewnia pełną kontrolę nad zasobami obliczeniowymi i pozwala skonfigurować i skonfigurować wszystko w swoich instancjach, od systemu operacyjnego po aplikacje. Umożliwia również szybkie skalowanie pojemności, zarówno w górę, jak i w dół, w miarę zmiany wymagań obliczeniowych.
Amazon EC2 obsługuje różne systemy operacyjne, takie jak Amazon Linux, Ubuntu, Windows Server, Red Hat Enterprise Linux, SUSE Linux Enterprise Server, Fedora, Debian, CentOS, Gentoo Linux, Oracle Linux i FreeBSD.
Jak z tego korzystać
Przejdź do sekcji Amazon EC2 i naciśnij Instancję uruchamiania. W pierwszym kroku musisz wybrać system operacyjny instancji EC2.
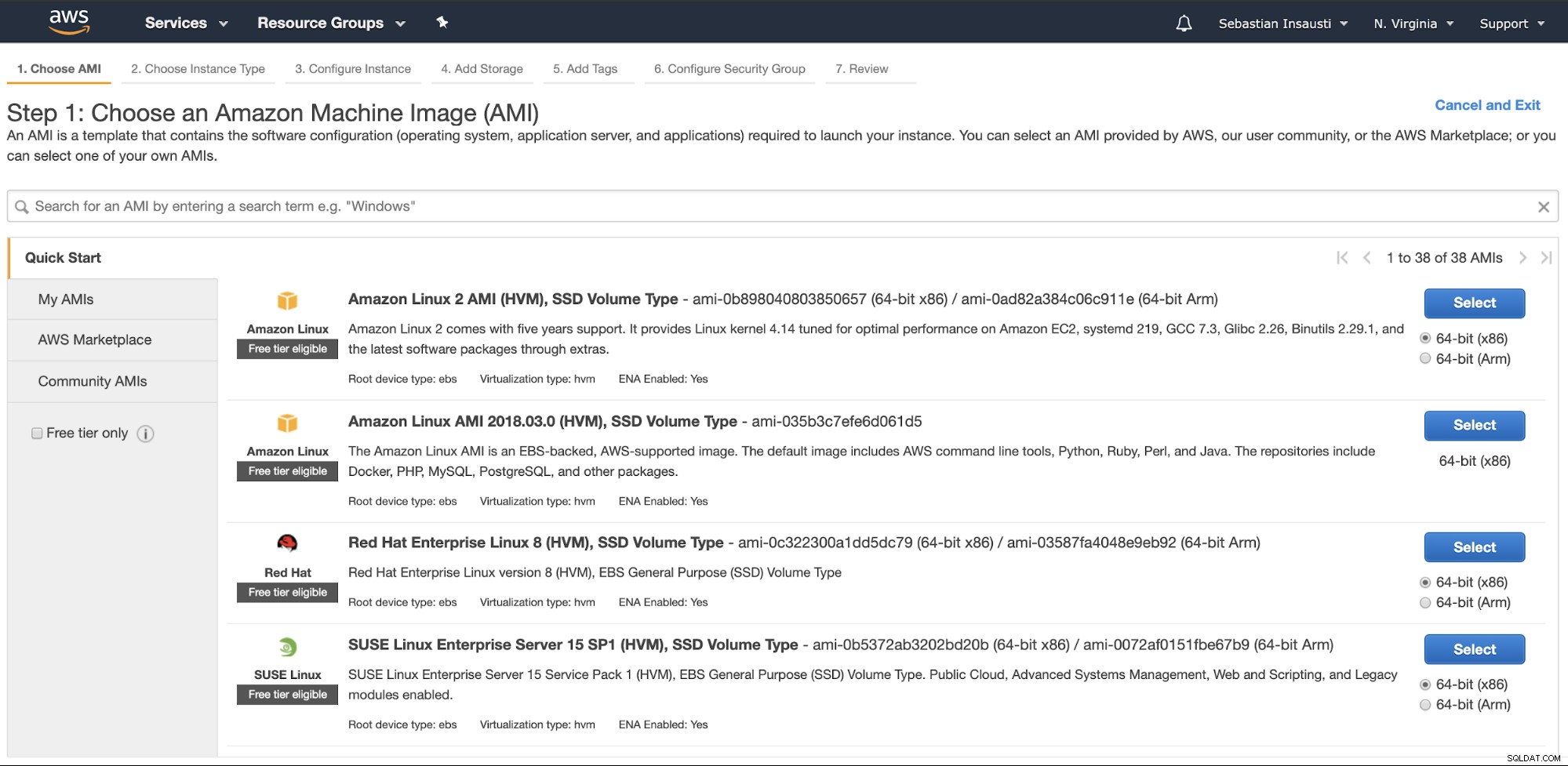
W następnym kroku należy wybrać zasoby dla nowej instancji.
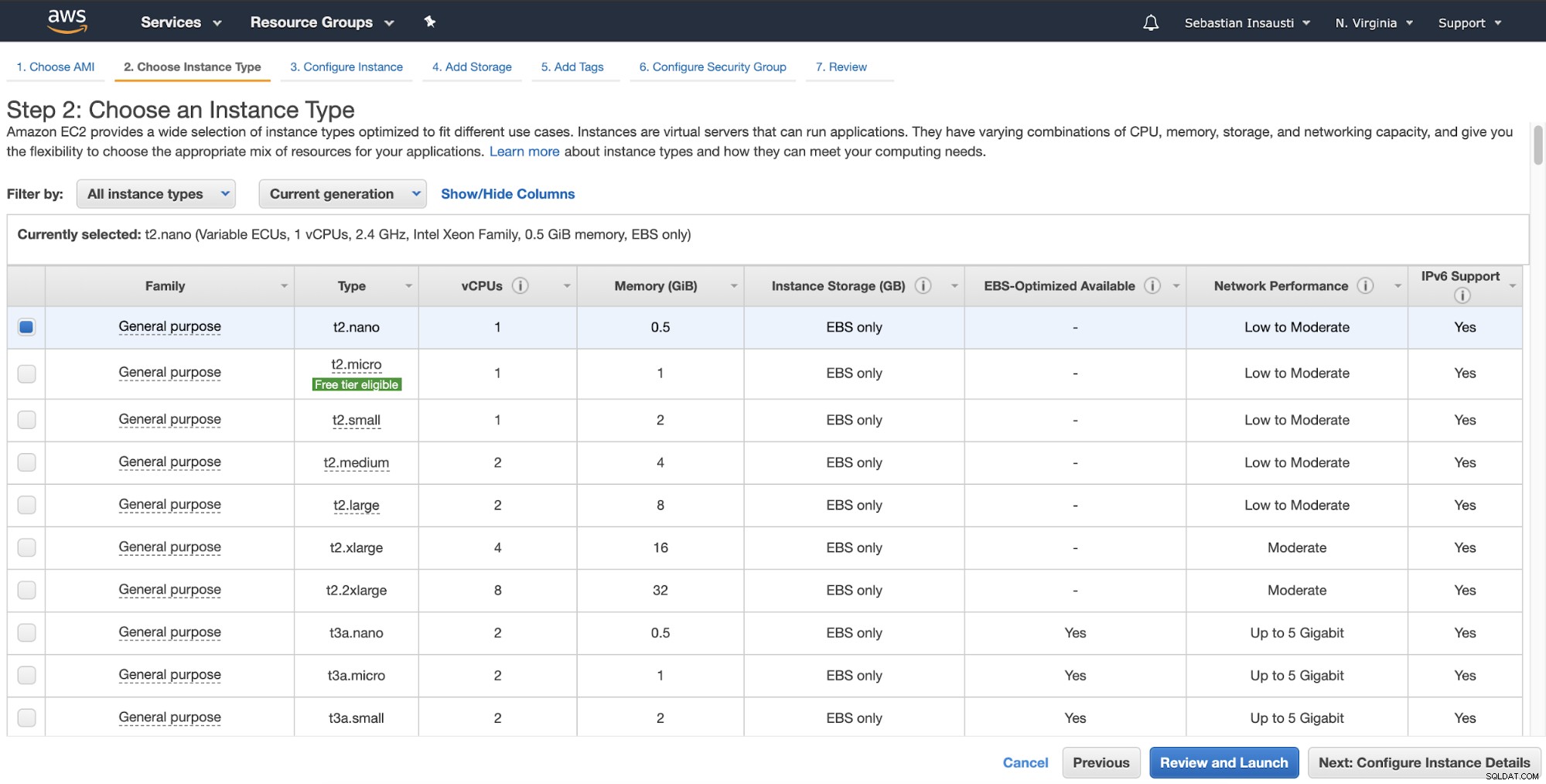
Następnie możesz określić bardziej szczegółową konfigurację, taką jak sieć, podsieć i inne .
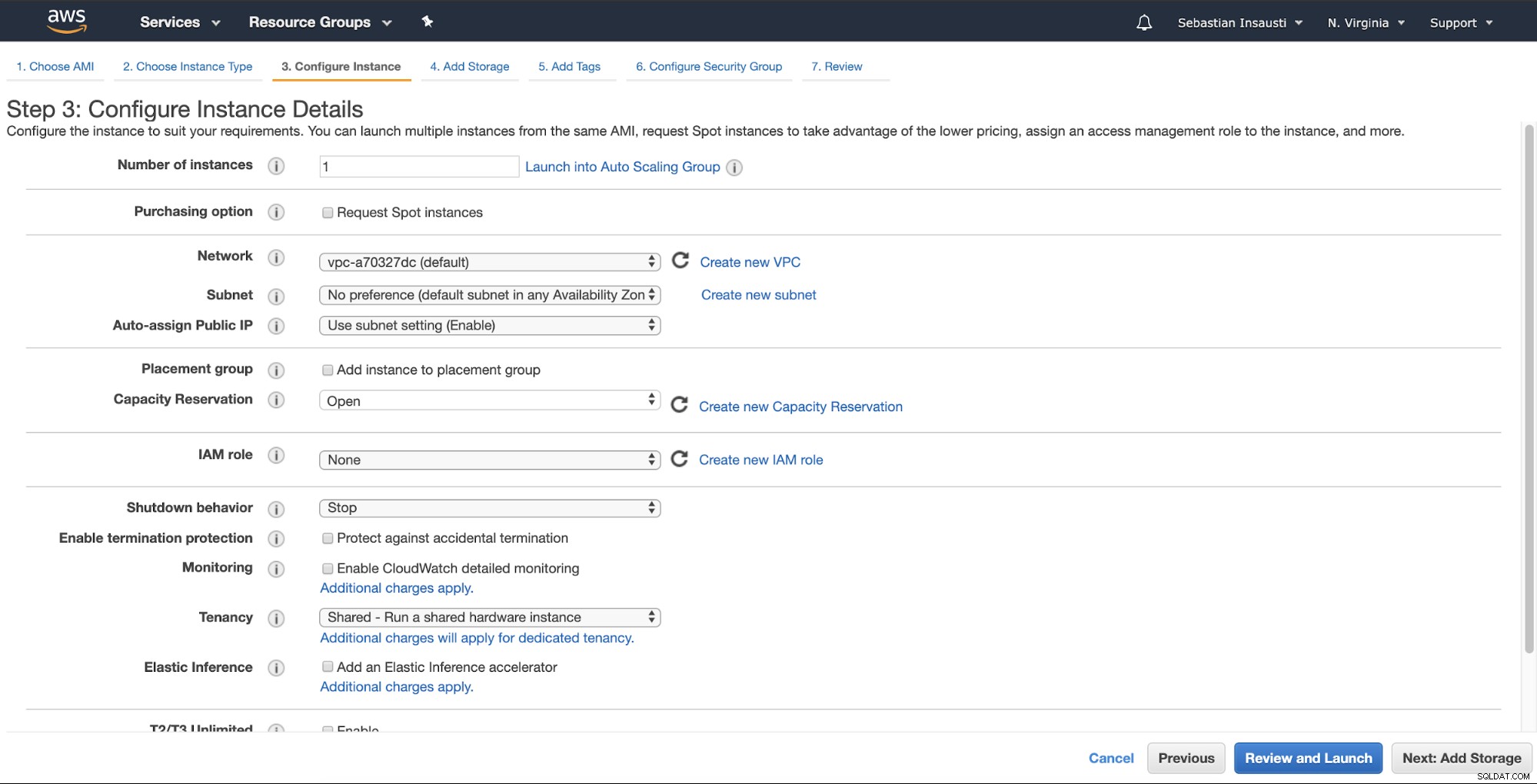
Teraz możemy dodać więcej miejsca w tym nowym wystąpieniu i jako serwer zapasowy, powinniśmy to zrobić.
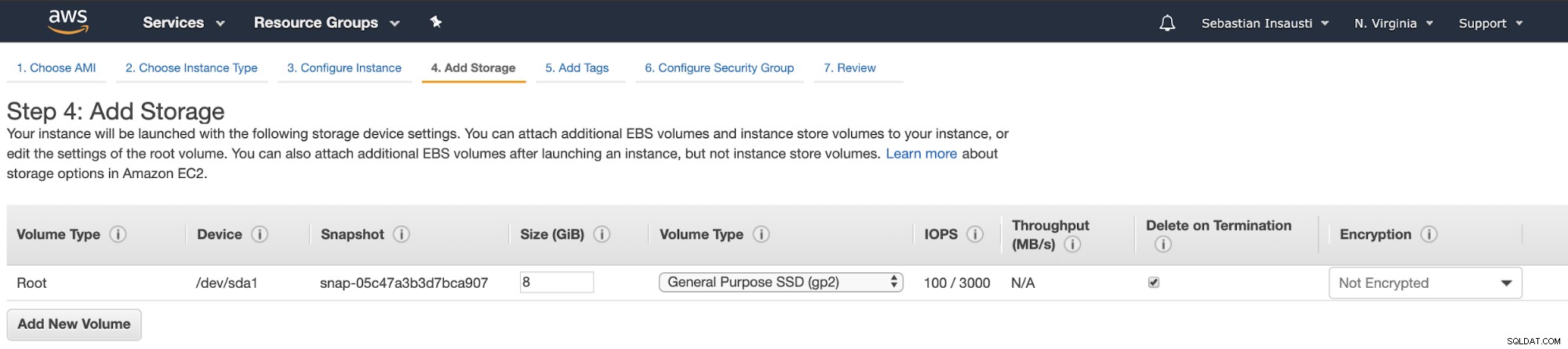
Po zakończeniu zadania tworzenia możemy przejść do sekcji Instancje, aby zobacz naszą nową instancję EC2.
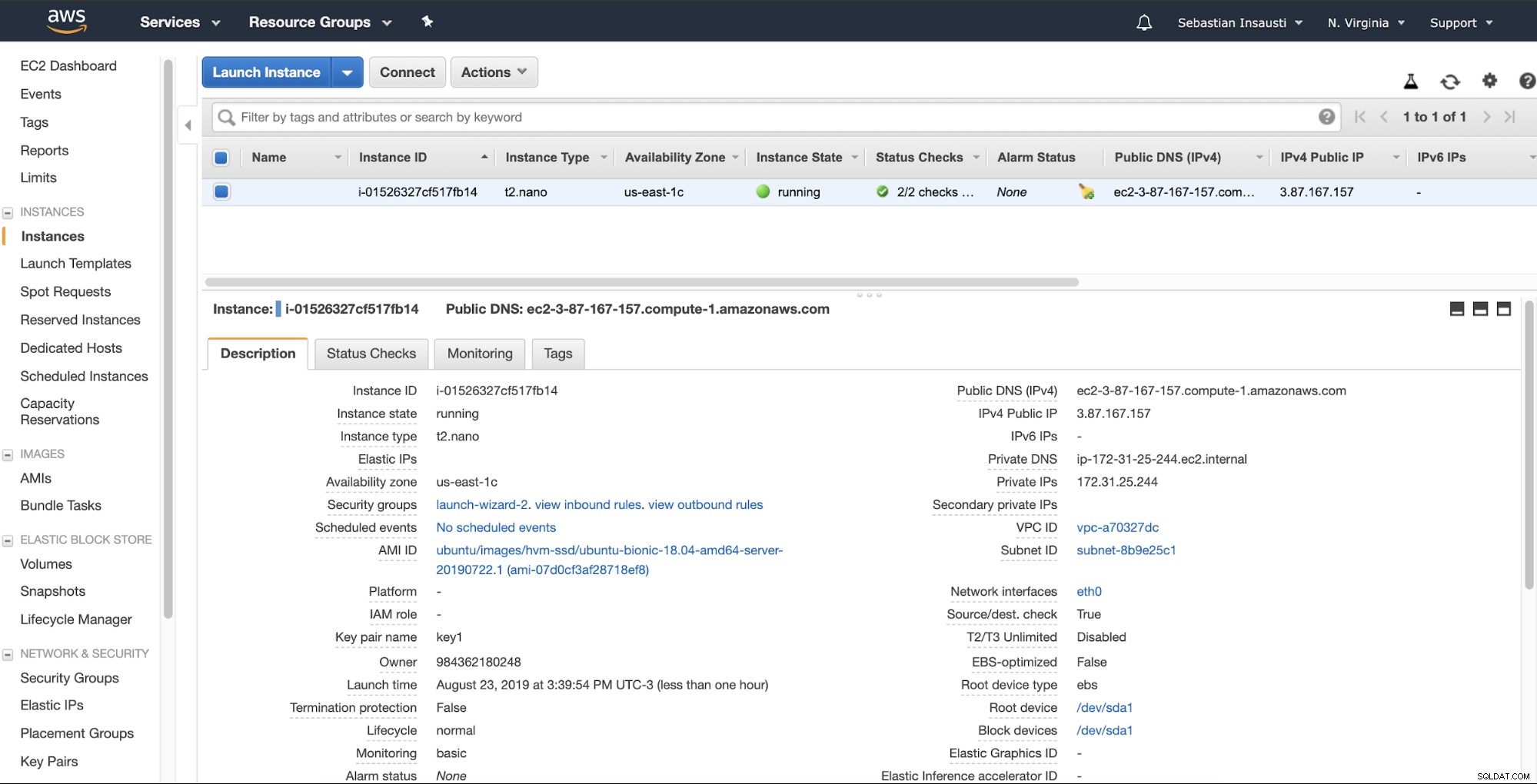
Gdy instancja jest gotowa (stan instancji jest uruchomiony), możesz zapisać kopie zapasowe tutaj, na przykład wysyłając je przez SSH lub FTP za pomocą publicznego DNS utworzonego przez AWS. Zobaczmy przykład z Rsync i inny z poleceniem SCP Linux.
[example@sqldat.com ~]# rsync -avzP -e "ssh -i /home/user/key1.pem" /root/backups/BACKUP-11/base.tar.gz example@sqldat.com:/backups/20190823/
sending incremental file list
base.tar.gz
4,091,563 100% 2.18MB/s 0:00:01 (xfr#1, to-chk=0/1)
sent 3,735,675 bytes received 35 bytes 574,724.62 bytes/sec
total size is 4,091,563 speedup is 1.10
[example@sqldat.com ~]#
[example@sqldat.com ~]# scp -i /tmp/key1.pem /root/backups/BACKUP-12/pg_dump_2019-08-25_211903.sql.gz example@sqldat.com:/backups/20190823/
pg_dump_2019-08-25_211903.sql.gz 100% 24KB 76.4KB/s 00:00Kopia zapasowa AWS
AWS Backup to scentralizowana usługa tworzenia kopii zapasowych, która zapewnia funkcje zarządzania kopiami zapasowymi, takie jak planowanie kopii zapasowych, zarządzanie przechowywaniem i monitorowanie kopii zapasowych, a także dodatkowe funkcje, takie jak cykliczne tworzenie kopii zapasowych w celu obniżenia kosztów warstwa pamięci, miejsce na kopie zapasowe i szyfrowanie niezależne od danych źródłowych i zasad dostępu do kopii zapasowych.
Możesz użyć AWS Backup do zarządzania kopiami zapasowymi woluminów EBS, baz danych RDS, tabel DynamoDB, systemów plików EFS i woluminów Storage Gateway.
Jak z tego korzystać
Przejdź do sekcji AWS Backup w AWS Management Console.
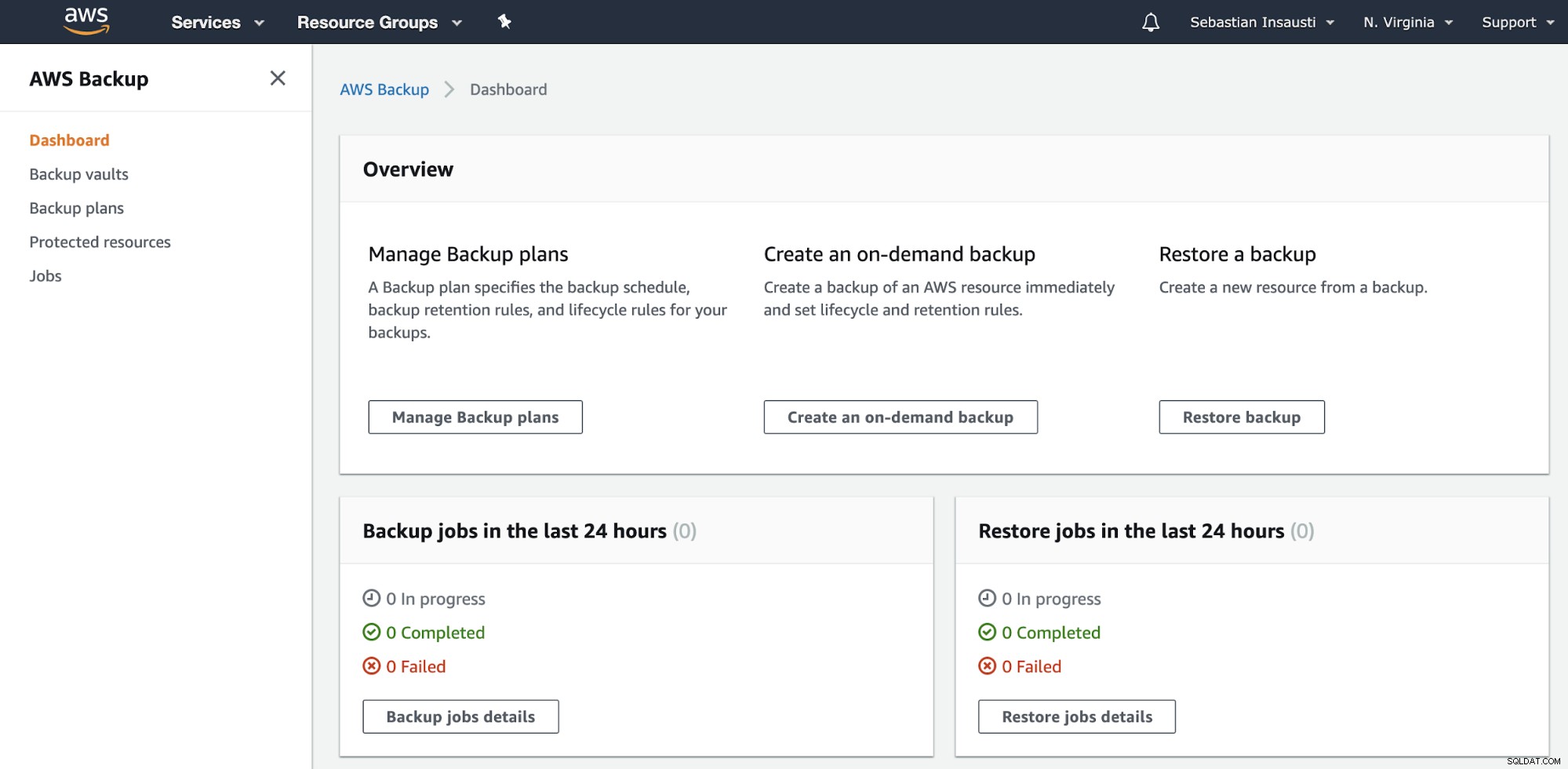
Tutaj masz różne opcje, takie jak Zaplanuj, Utwórz lub Przywróć kopię zapasową . Zobaczmy, jak utworzyć nową kopię zapasową.
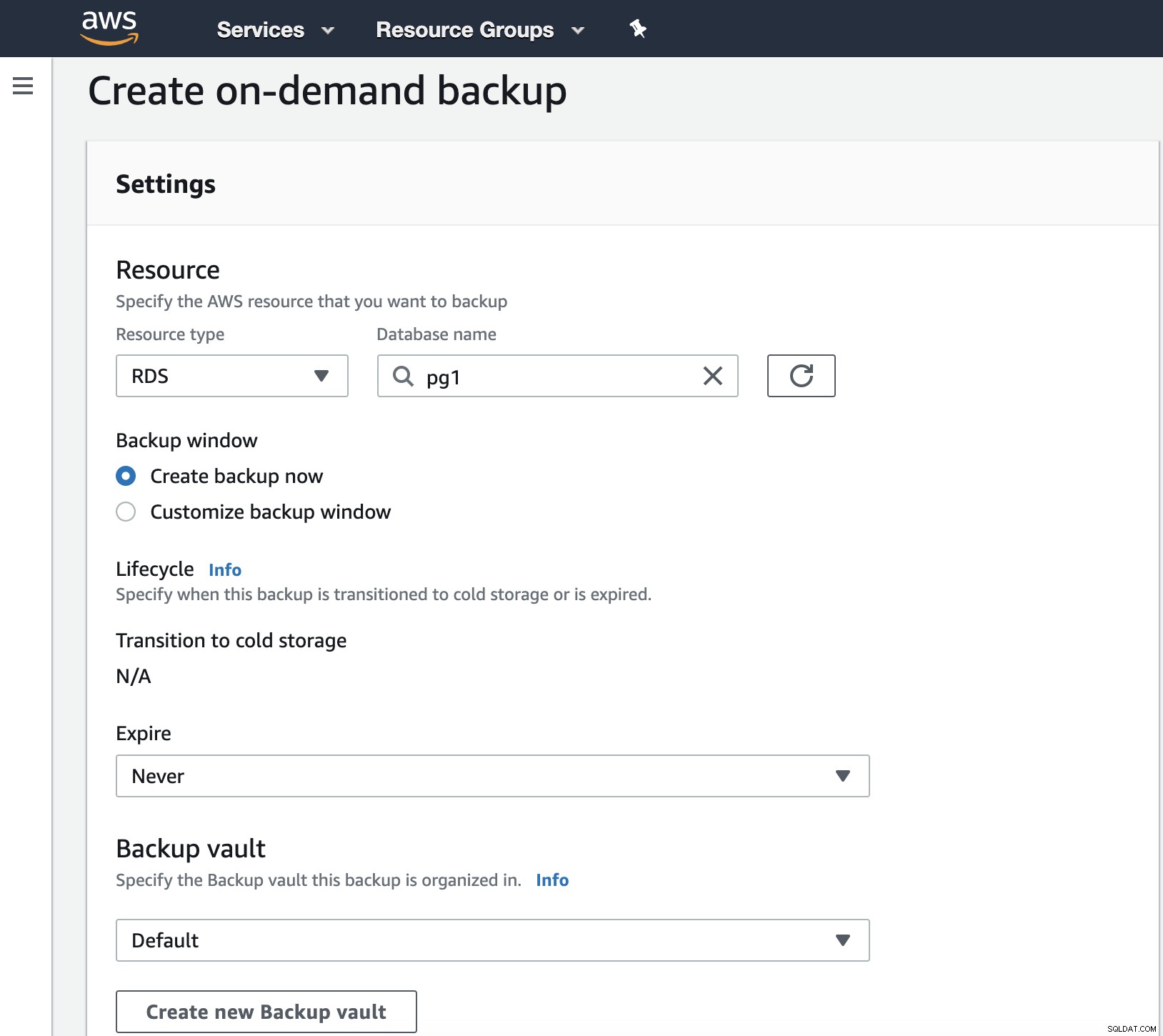
W tym kroku musimy wybrać typ zasobu, którym może być DynamoDB, RDS, EBS, EFS lub Storage Gateway oraz więcej szczegółów, takich jak data wygaśnięcia, skarbiec kopii zapasowych i rola uprawnień.
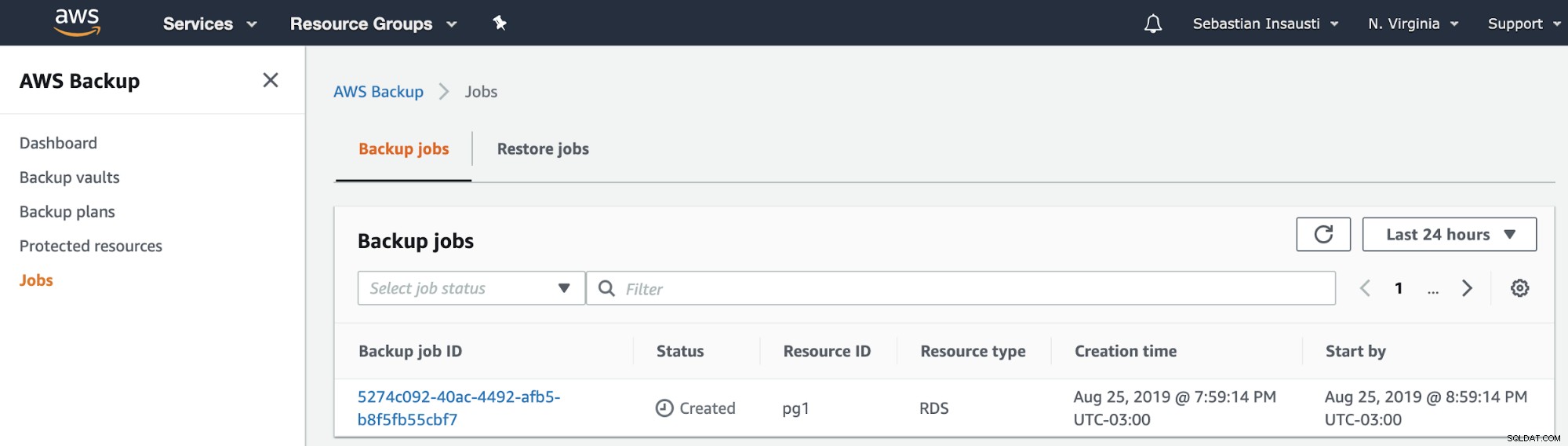
Następnie widzimy nowe zadanie utworzone w sekcji Zadania kopii zapasowych AWS .
Migawka
Teraz możemy wspomnieć o tej znanej opcji we wszystkich środowiskach wirtualizacji. Migawka jest kopią zapasową wykonaną w określonym momencie, a AWS pozwala nam używać jej dla produktów AWS. Oto przykład migawki RDS.
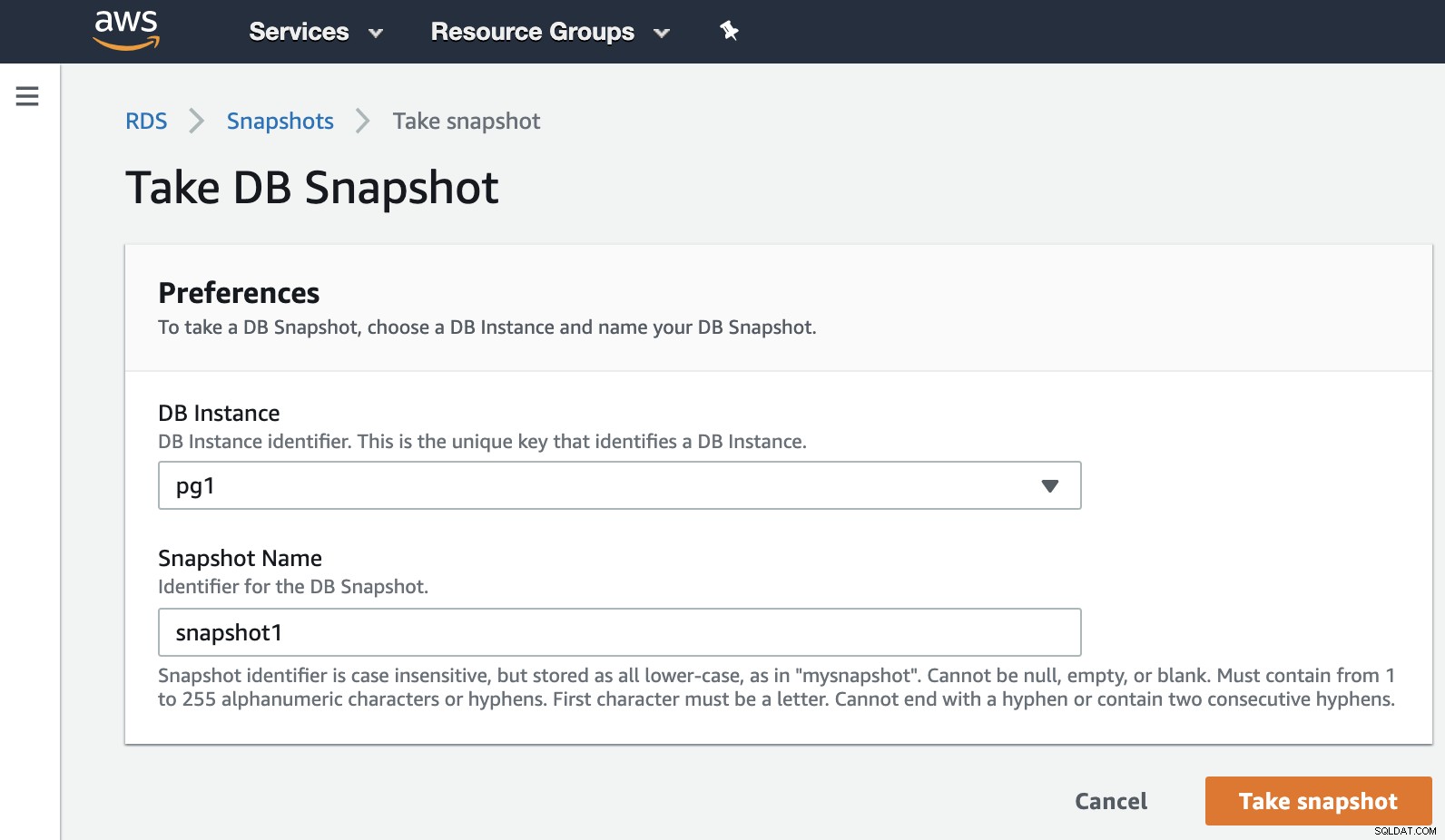
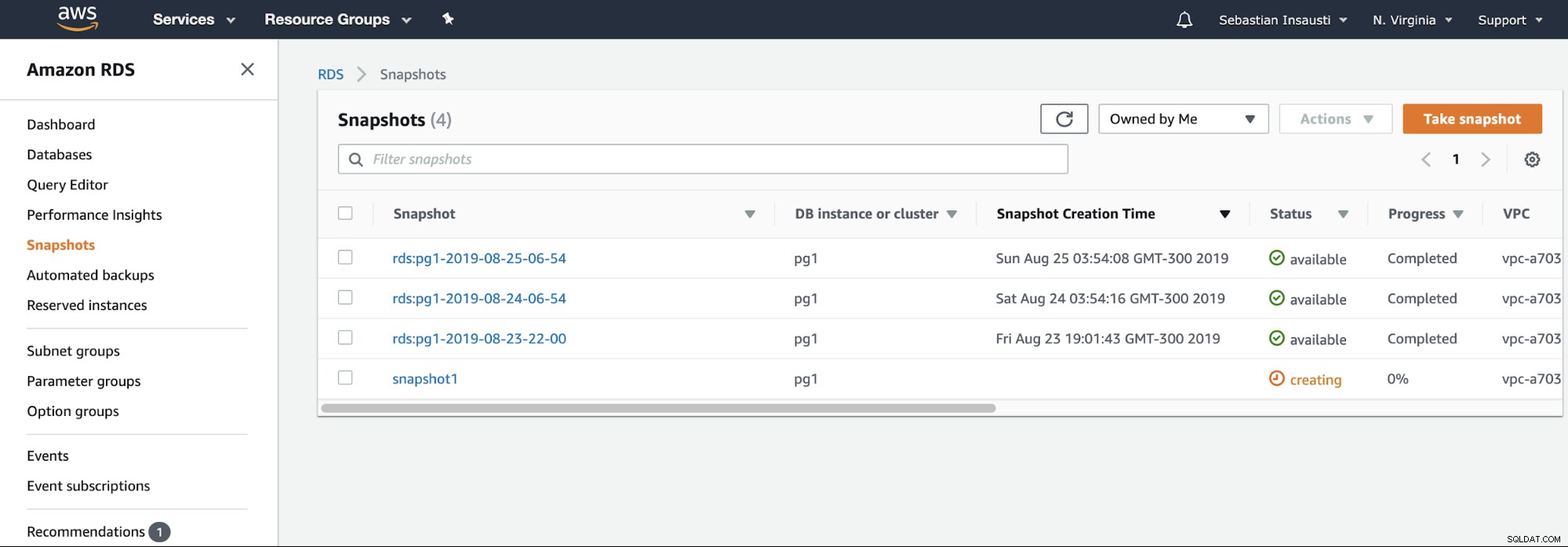
Musimy tylko wybrać instancję i dodać nazwę migawki, i to jest to. Możemy zobaczyć tę i poprzednią migawkę w sekcji Migawka RDS.
Zarządzanie kopiami zapasowymi za pomocą ClusterControl
ClusterControl to kompleksowy system zarządzania bazami danych typu open source, który automatyzuje funkcje wdrażania i zarządzania, a także monitorowanie kondycji i wydajności. ClusterControl wspiera wdrażanie, zarządzanie, monitorowanie i skalowanie dla różnych technologii i środowisk baz danych, w tym EC2. Możemy więc na przykład stworzyć naszą instancję EC2 na AWS i wdrożyć/importować naszą usługę bazy danych za pomocą ClusterControl.

Tworzenie kopii zapasowej
W tym zadaniu przejdź do ClusterControl -> Wybierz Cluster -> Kopia zapasowa -> Utwórz kopię zapasową.
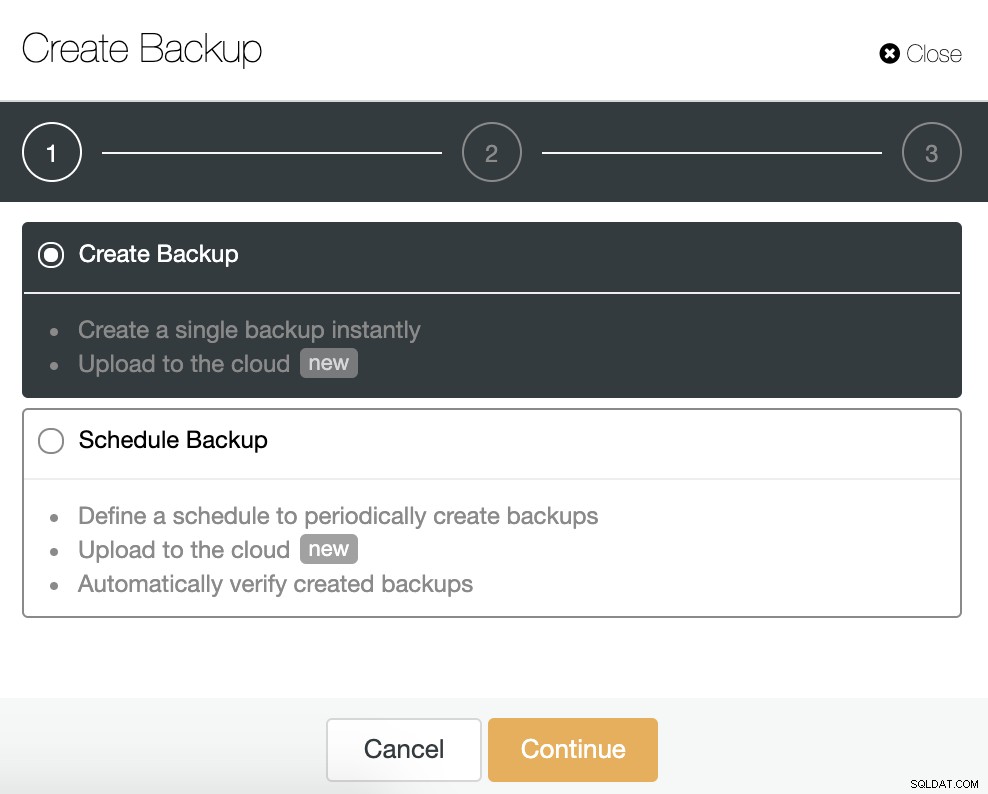
Możemy utworzyć nową kopię zapasową lub skonfigurować zaplanowaną. W naszym przykładzie natychmiast utworzymy pojedynczą kopię zapasową.
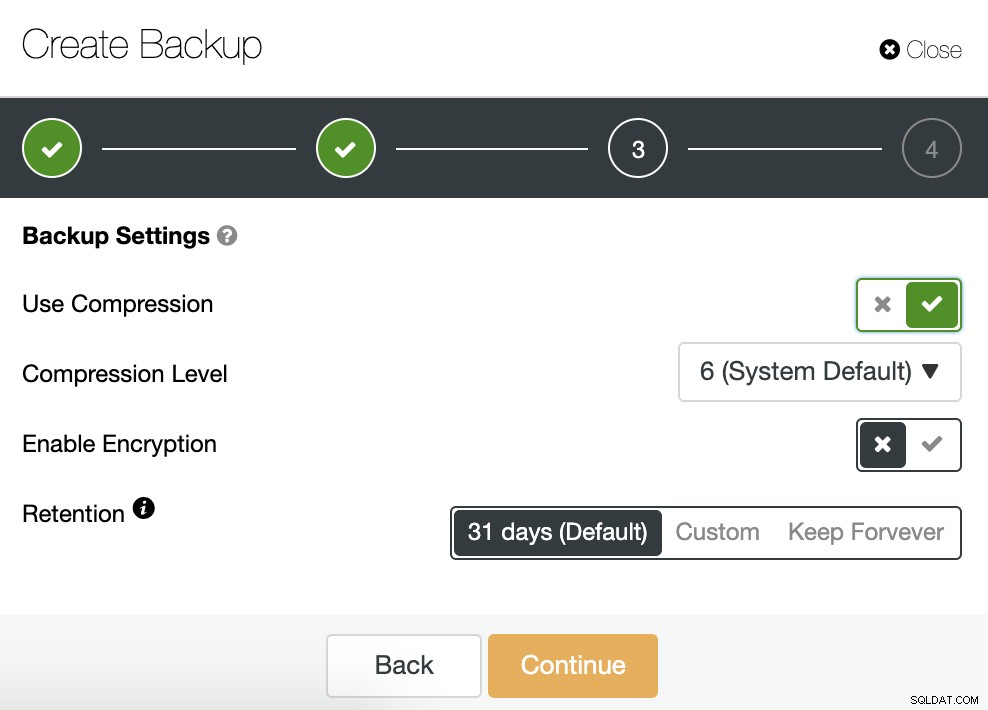
Musimy wybrać jedną metodę, serwer, z którego zostanie pobrana kopia zapasowa i gdzie chcemy przechowywać kopię zapasową. Możemy również przesłać naszą kopię zapasową do chmury (AWS, Google lub Azure), włączając odpowiedni przycisk.
Następnie określamy użycie kompresji, poziom kompresji, szyfrowanie i przechowywanie okres na naszą kopię zapasową.
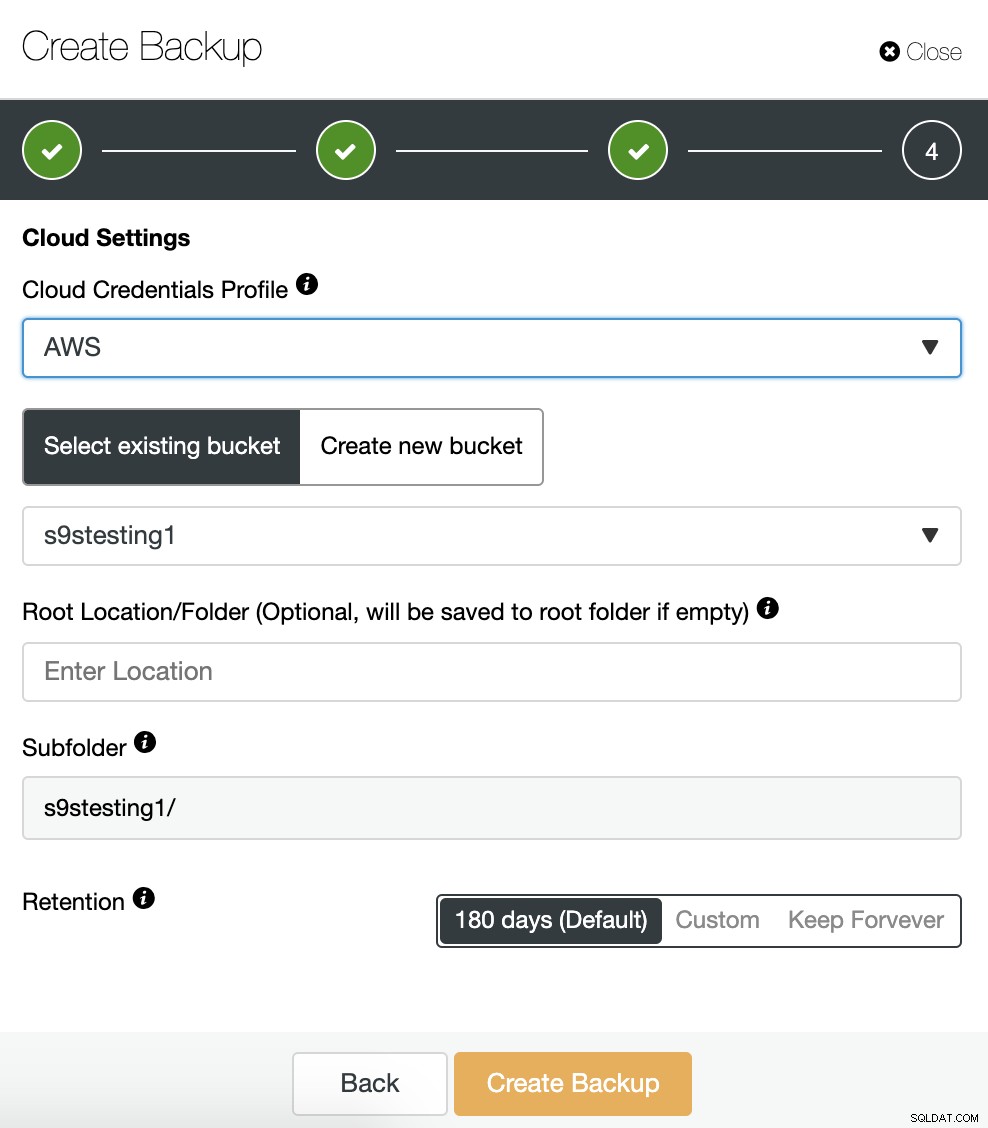
Jeśli włączyliśmy opcję przesyłania kopii zapasowej do chmury, zobaczymy sekcję do określenia dostawcy chmury (w tym przypadku AWS) i poświadczeń (ClusterControl -> Integracje -> Dostawcy Chmury). W przypadku AWS korzysta z usługi S3, więc musimy wybrać Bucket lub nawet utworzyć nowy, aby przechowywać nasze kopie zapasowe.
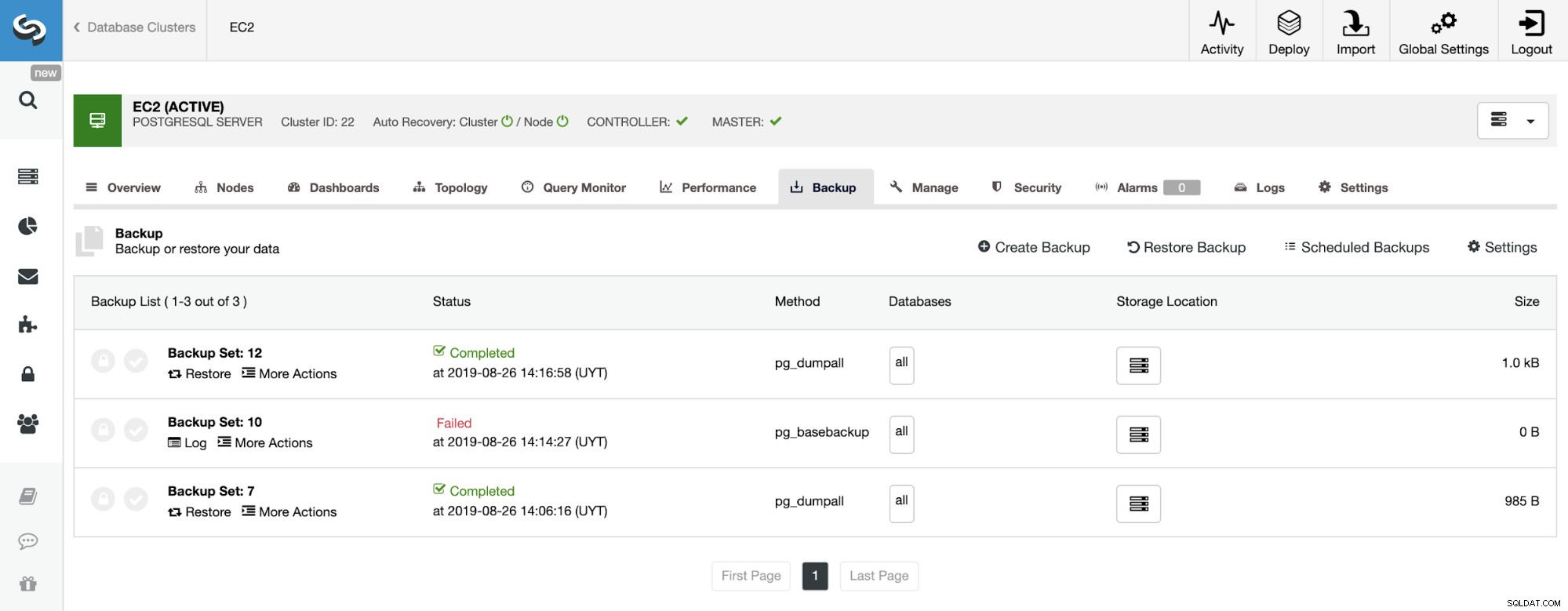
W sekcji kopii zapasowej możemy zobaczyć postęp tworzenia kopii zapasowej oraz informacje takie jak metoda, rozmiar, lokalizacja i inne.
Wnioski
Amazon AWS pozwala nam przechowywać nasze kopie zapasowe PostgreSQL, niezależnie od tego, czy używamy go jako dostawcy chmury baz danych, czy nie. Aby mieć efektywny plan tworzenia kopii zapasowych, należy rozważyć przechowywanie co najmniej jednej kopii zapasowej bazy danych w chmurze, aby uniknąć utraty danych w przypadku awarii sprzętu w innym magazynie kopii zapasowych. Chmura pozwala przechowywać tyle kopii zapasowych, ile chcesz przechowywać lub za które zapłacić.