Potrzeba osiągnięcia wysokiej dostępności bazy danych jest dość powszechnym zadaniem i często koniecznością. Jeśli Twoja firma ma ograniczony budżet, utrzymywanie urządzenia podrzędnego replikacji (lub więcej niż jednego) działającego u tego samego dostawcy chmury (tylko czekanie, jeśli kiedyś będzie potrzebne) może być kosztowne. W zależności od typu aplikacji, istnieją pewne przypadki, w których urządzenie podrzędne replikacji jest niezbędne do poprawy RTO (Cel czasu odzyskiwania).
Istnieje jednak inna opcja, jeśli Twoja firma może zaakceptować krótkie opóźnienie, aby przywrócić system do trybu online.
Cold Standby to metoda nadmiarowości, w której masz węzeł gotowości (jako zapasowy) dla węzła podstawowego. Ten węzeł jest używany tylko podczas awarii głównej. Przez resztę czasu węzeł zimnego czuwania jest wyłączony i używany tylko do ładowania kopii zapasowej w razie potrzeby.
Aby skorzystać z tej metody, konieczne jest posiadanie wstępnie zdefiniowanych zasad tworzenia kopii zapasowych (z nadmiarowością) zgodnie z akceptowalnym RPO (celem punktu odzyskiwania) dla firmy. Może się okazać, że dla firmy akceptowalna jest utrata 12 godzin danych lub utrata tylko jednej godziny może być dużym problemem. Każda firma i aplikacja musi określić własny standard.
W tym blogu dowiesz się, jak tworzyć zasady tworzenia kopii zapasowych i przywracać je do serwera w trybie gotowości w trybie gotowości za pomocą ClusterControl i jego integracji z Amazon AWS.
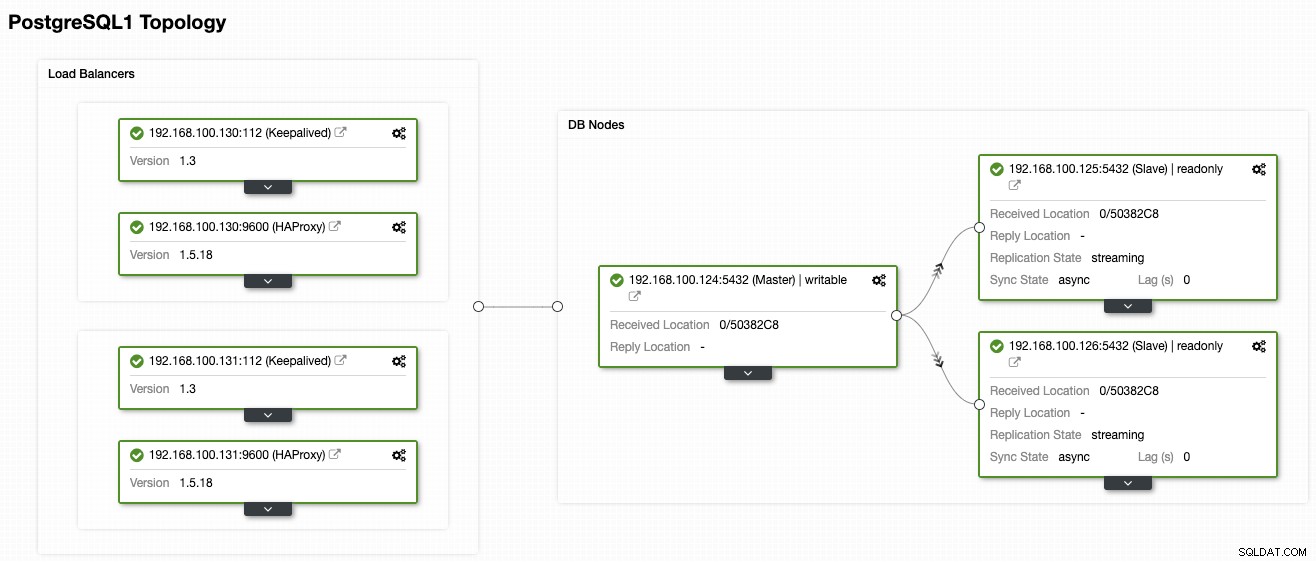
W tym blogu założymy, że masz już konto AWS i zainstalowany ClusterControl. Chociaż w tym przykładzie zamierzamy używać AWS jako dostawcy chmury, możesz użyć innego. Użyjemy następującej topologii PostgreSQL wdrożonej przy użyciu ClusterControl:
- 1 główny węzeł PostgreSQL
- 2 węzły PostgreSQL w trybie gotowości
- 2 Load Balancery (HAProxy + Keepalved)
Tworzenie akceptowalnych zasad tworzenia kopii zapasowych
Najlepszą praktyką przy tworzeniu tego typu zasad jest przechowywanie plików kopii zapasowych w trzech różnych miejscach, jeden przechowywany lokalnie na serwerze bazy danych (dla szybszego odzyskiwania), drugi na scentralizowanym serwerze kopii zapasowych oraz ostatni w chmurze.
Możesz to poprawić, używając również pełnych, przyrostowych i różnicowych kopii zapasowych. Dzięki ClusterControl możesz wykonywać wszystkie powyższe najlepsze praktyki, wszystkie z tego samego systemu, z przyjaznym i łatwym w użyciu interfejsem użytkownika. Zacznijmy od stworzenia integracji AWS w ClusterControl.
Konfigurowanie integracji ClusterControl AWS
Przejdź do ClusterControl -> Integracje -> Dostawcy chmury -> Dodaj poświadczenia chmury.
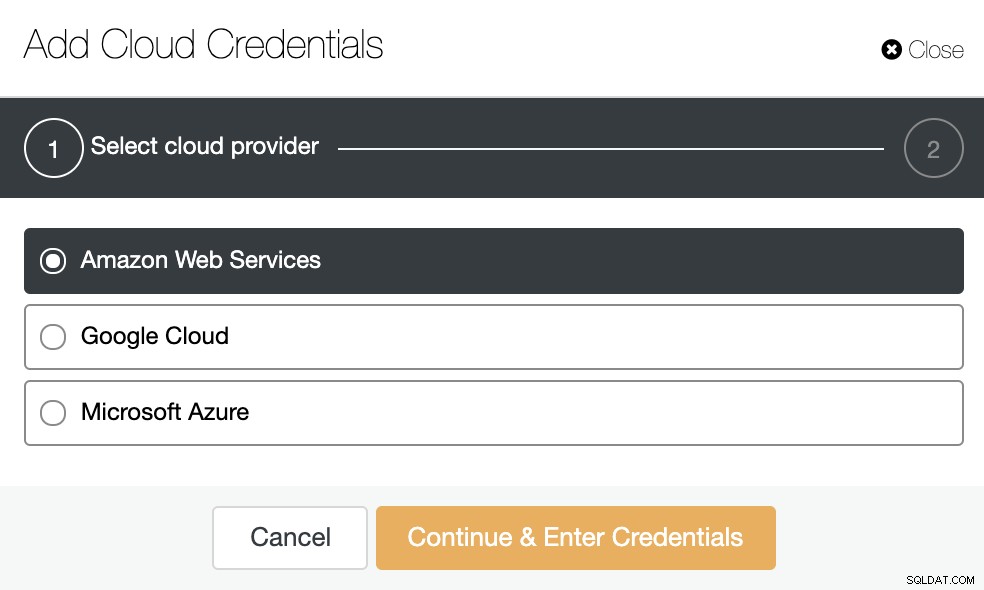
Wybierz dostawcę chmury. Obsługujemy AWS, Google Cloud czy Azure. W takim przypadku wybierz AWS i kontynuuj.
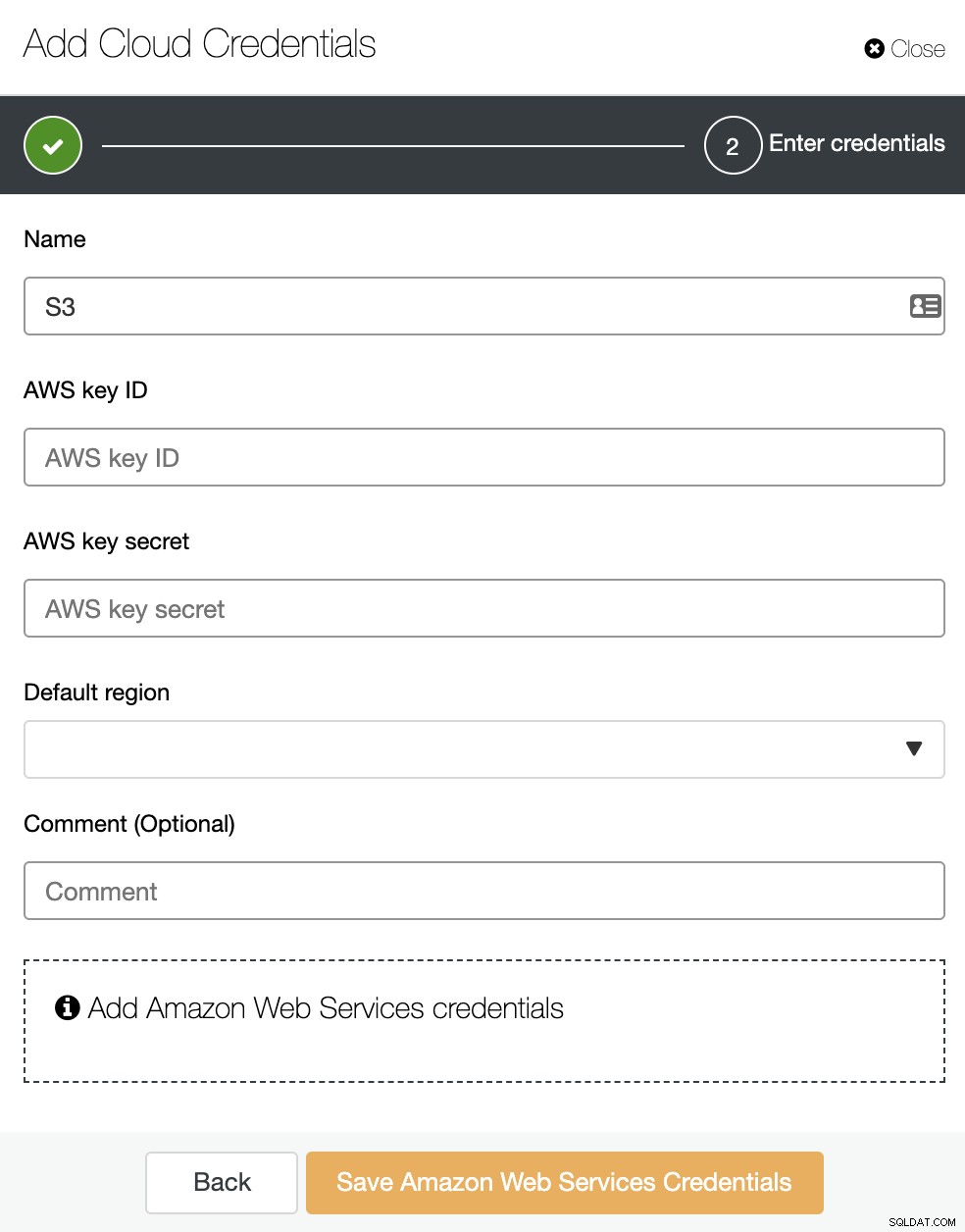
Tutaj musisz dodać Nazwę, Domyślny region i AWS identyfikator klucza i klucz tajny. Aby uzyskać lub utworzyć te ostatnie, należy przejść do sekcji IAM (zarządzanie tożsamością i dostępem) w konsoli zarządzania AWS. Aby uzyskać więcej informacji, zapoznaj się z naszą dokumentacją lub dokumentacją AWS.
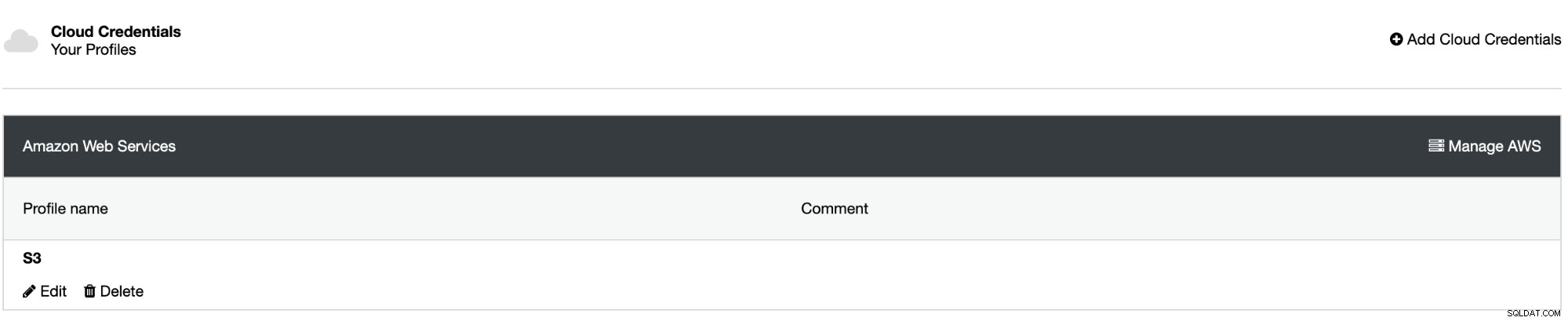
Teraz masz już utworzoną integrację, chodźmy zaplanować pierwszą kopię zapasową za pomocą ClusterControl.
Planowanie kopii zapasowej za pomocą ClusterControl
Przejdź do ClusterControl -> Wybierz klaster PostgreSQL -> Kopia zapasowa -> Utwórz kopię zapasową.
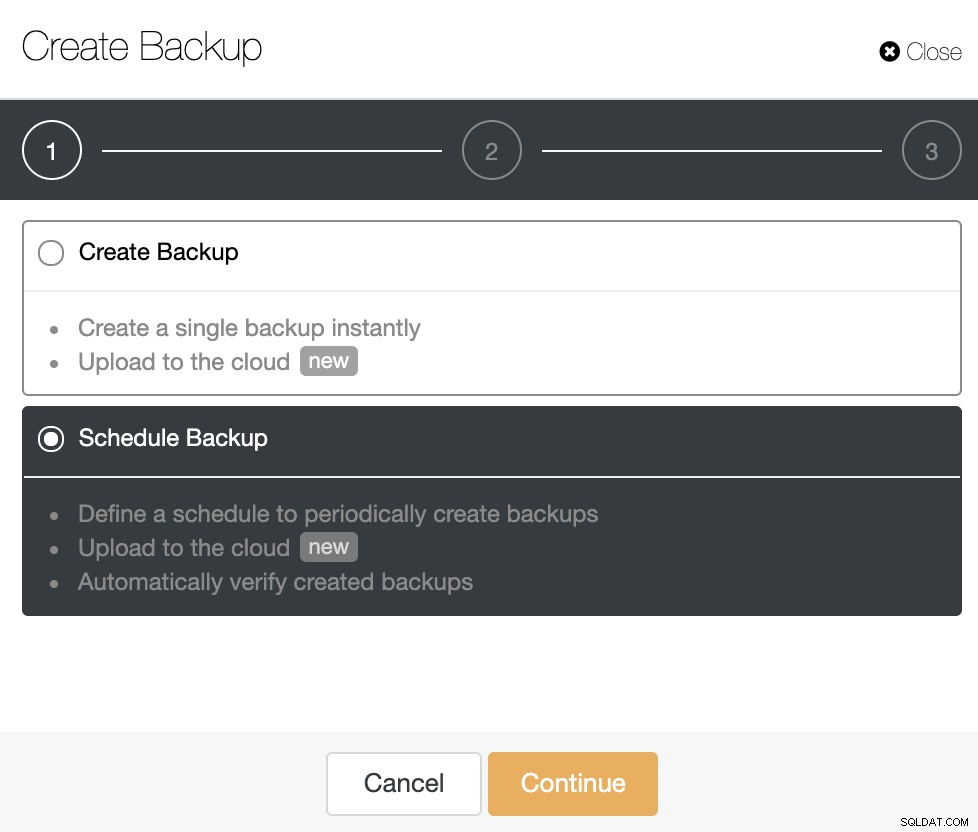
Możesz wybrać, czy chcesz utworzyć pojedynczą kopię zapasową natychmiast, czy zaplanować nowa kopia zapasowa. Wybierzmy więc drugą opcję i kontynuujmy.
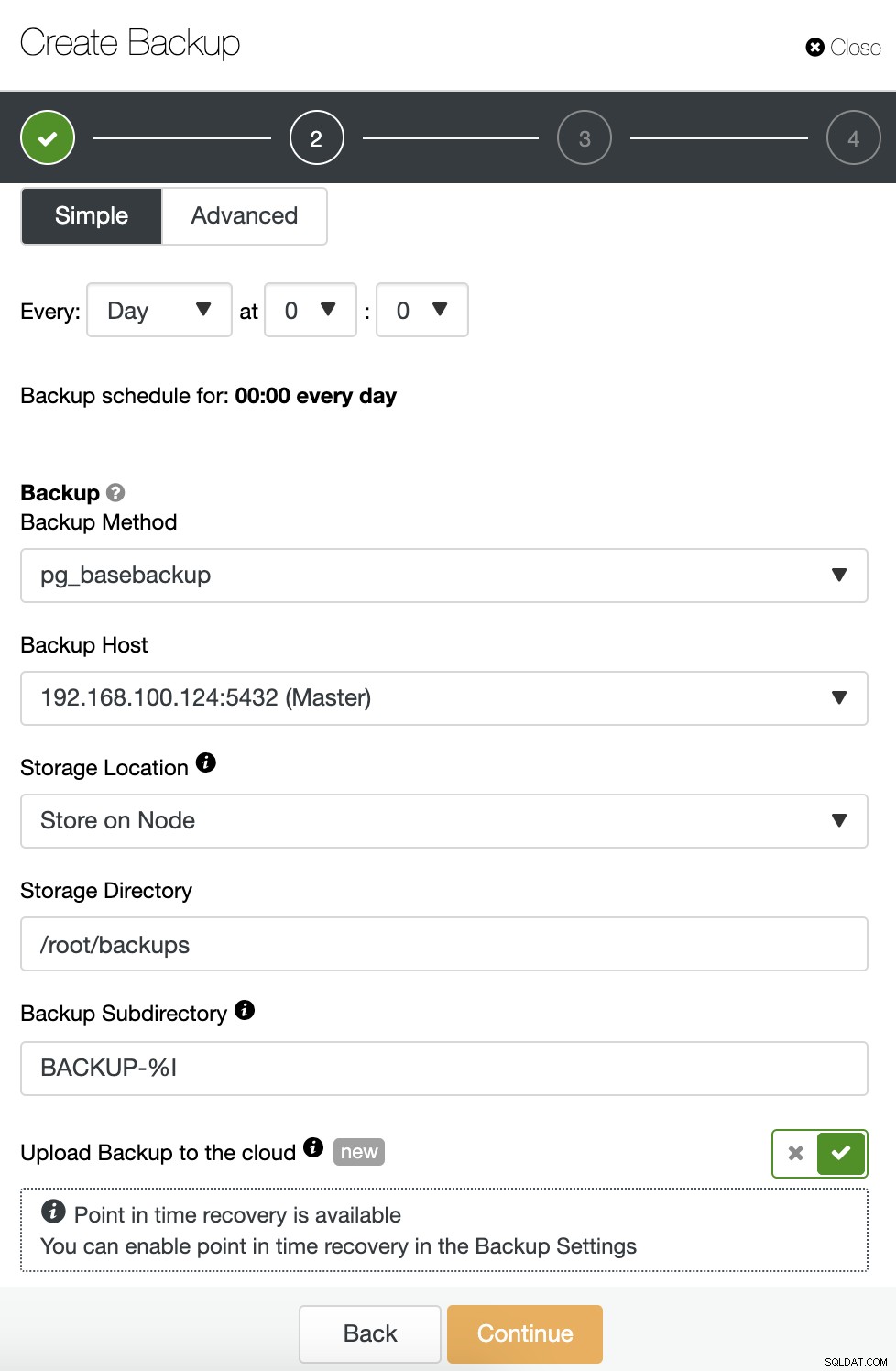
Gdy planujesz tworzenie kopii zapasowej, najpierw musisz określić harmonogram /częstotliwość. Następnie należy wybrać metodę tworzenia kopii zapasowej (pg_dumpall, pg_basebackup, pgBackRest), serwer, z którego zostanie pobrana kopia zapasowa oraz gdzie chcesz przechowywać kopię zapasową. Możesz również przesłać naszą kopię zapasową do chmury (AWS, Google lub Azure), włączając odpowiedni przycisk.
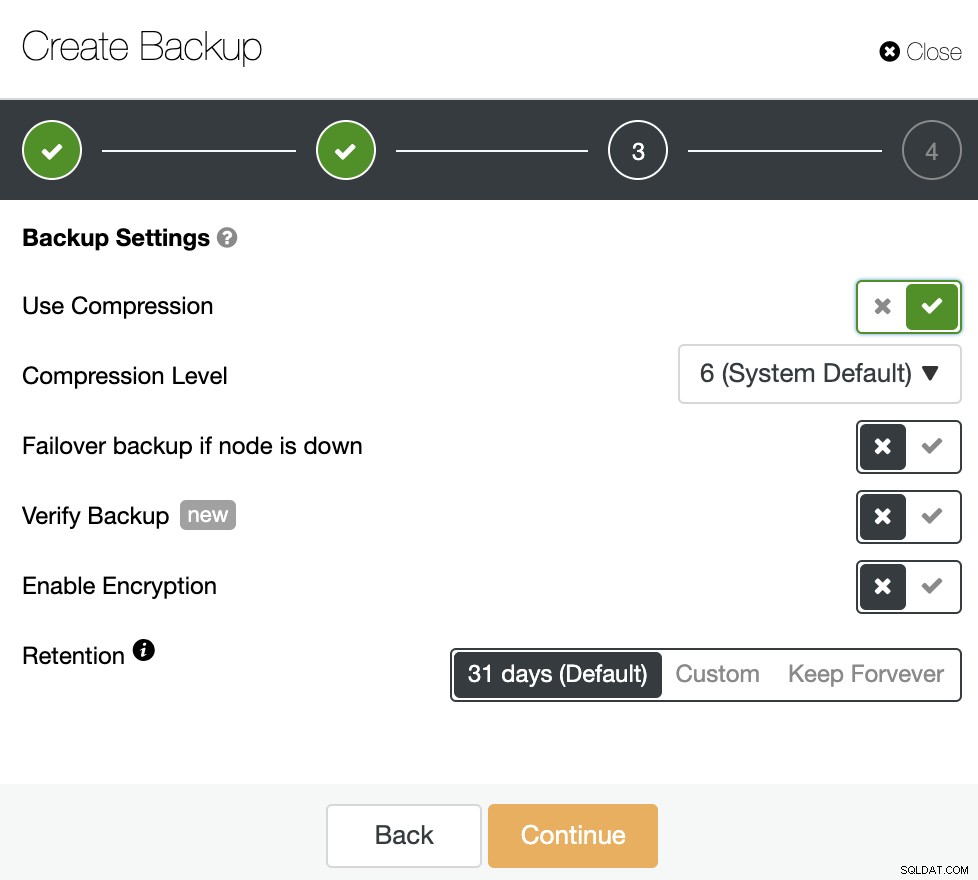
Następnie określ użycie kompresji, poziom kompresji, szyfrowanie i okres przechowywania dla kopii zapasowej. Istnieje inna funkcja o nazwie „Zweryfikuj kopię zapasową”, o której więcej szczegółów zobaczysz wkrótce w tym poście na blogu.
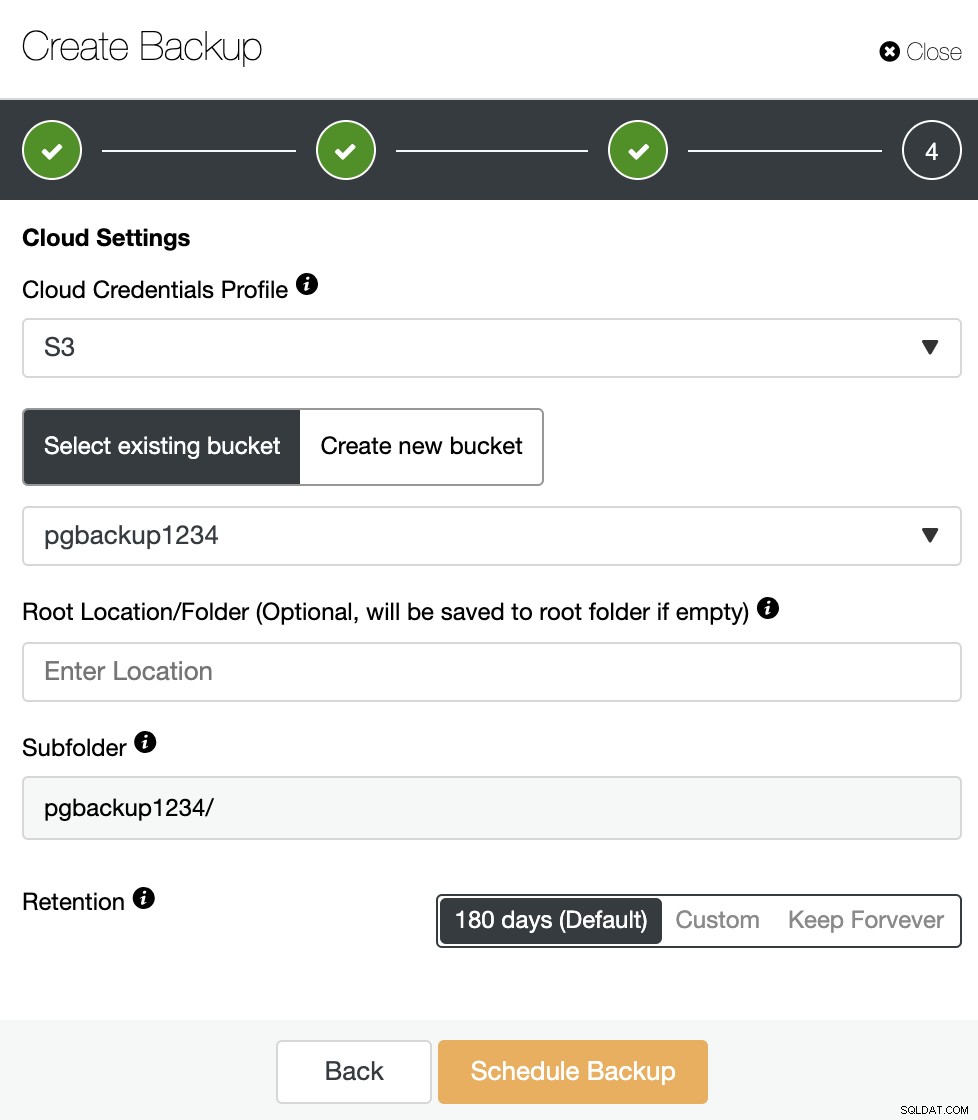
Jeśli opcja „Prześlij kopię zapasową do chmury” była włączona, Zobaczymy ten krok, w którym należy wybrać poświadczenia chmury i utworzyć lub wybrać zasobnik S3, w którym ma być przechowywana kopia zapasowa. Musisz również określić okres przechowywania.
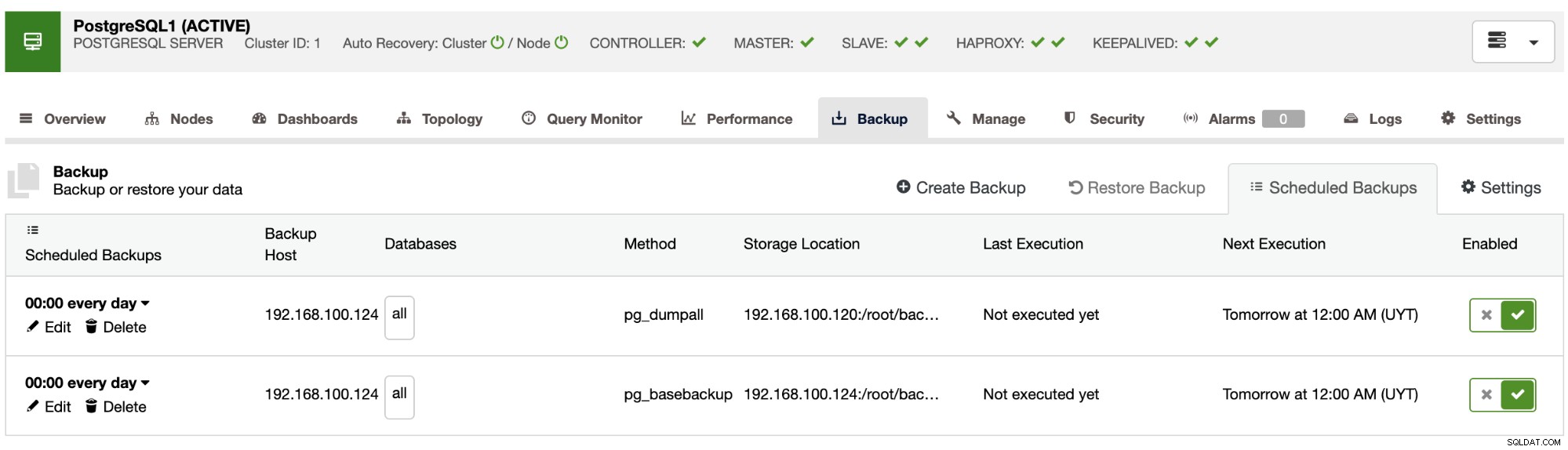
Teraz będziesz mieć zaplanowaną kopię zapasową w sekcji ClusterControl Harmonogram kopii zapasowych. Aby uwzględnić najlepsze praktyki wspomniane wcześniej, możesz zaplanować utworzenie kopii zapasowej na serwerze zewnętrznym (serwer ClusterControl) oraz w chmurze, a następnie zaplanować kolejną kopię zapasową, aby przechowywać ją lokalnie w węźle bazy danych, aby przyspieszyć odzyskiwanie.
Przywracanie kopii zapasowej w Amazon EC2
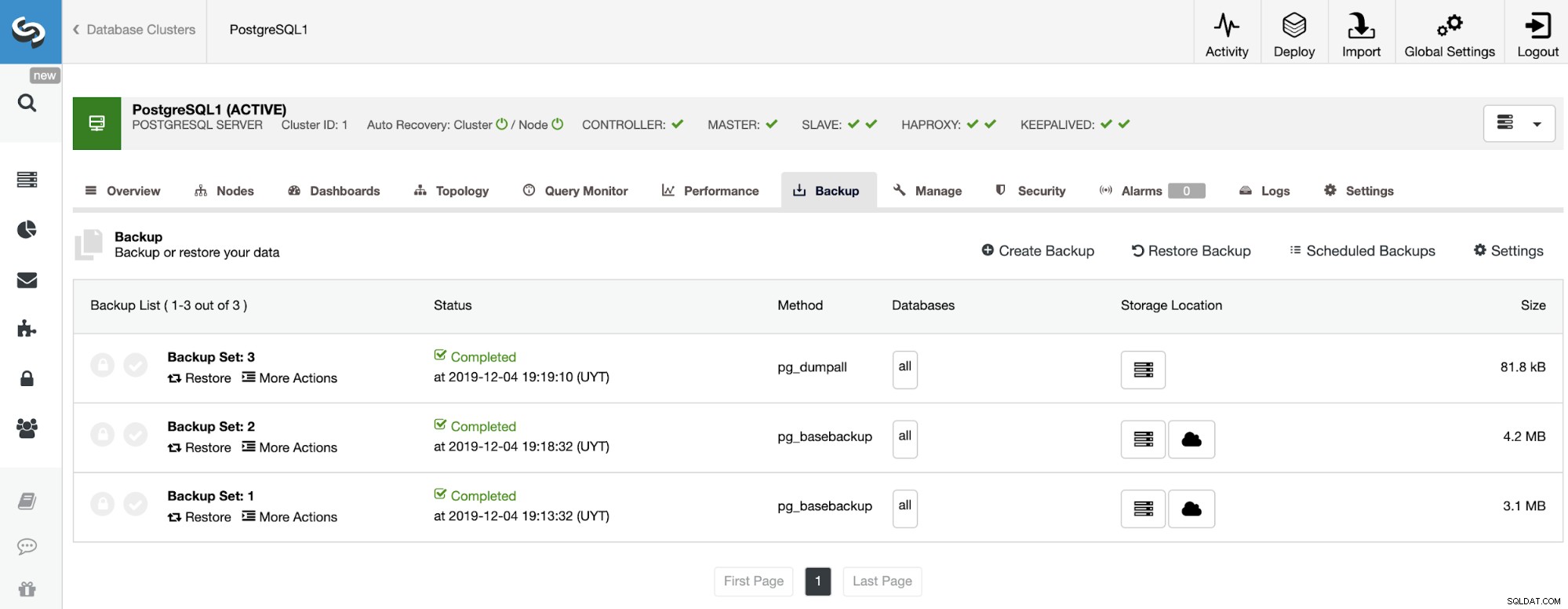
Po zakończeniu tworzenia kopii zapasowej możesz ją przywrócić za pomocą ClusterControl w sekcji Kopia zapasowa.
Tworzenie instancji Amazon EC2
Przede wszystkim, aby go przywrócić, musisz gdzieś to zrobić, więc stwórzmy podstawową instancję Amazon EC2. Przejdź do „Uruchom instancję” w konsoli zarządzania AWS w sekcji EC2 i skonfiguruj swoją instancję.
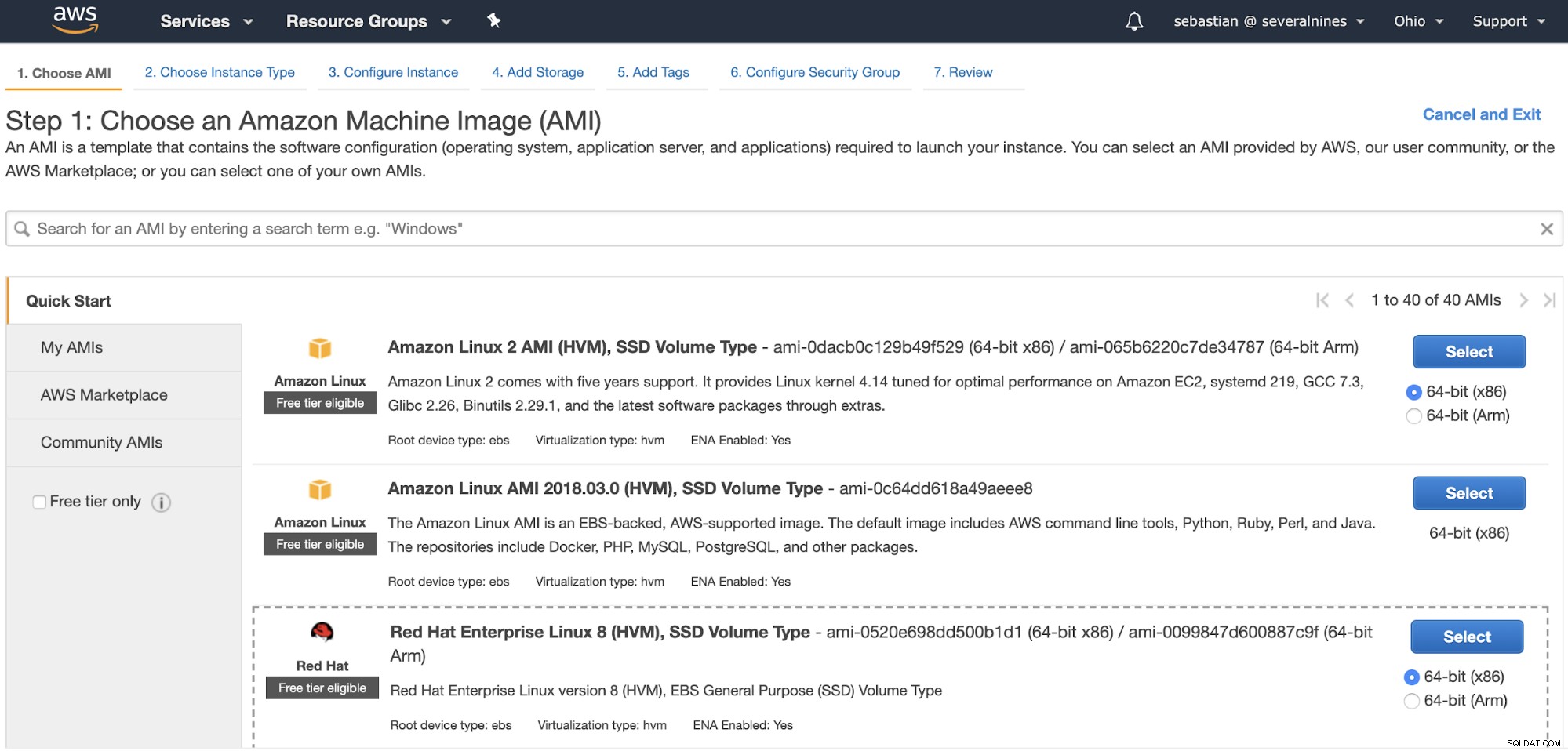
Po utworzeniu instancji konieczne będzie skopiowanie publicznego protokołu SSH klucz z serwera ClusterControl.
Przywracanie kopii zapasowej za pomocą ClusterControl
Teraz masz nową instancję EC2, użyjmy jej do przywrócenia tam kopii zapasowej. W tym celu w ClusterControl przejdź do sekcji kopii zapasowej (ClusterControl -> Wybierz Cluster -> Kopia zapasowa) i tam możesz wybrać „Przywróć kopię zapasową” lub bezpośrednio „Przywróć” kopii zapasowej, którą chcesz przywrócić.
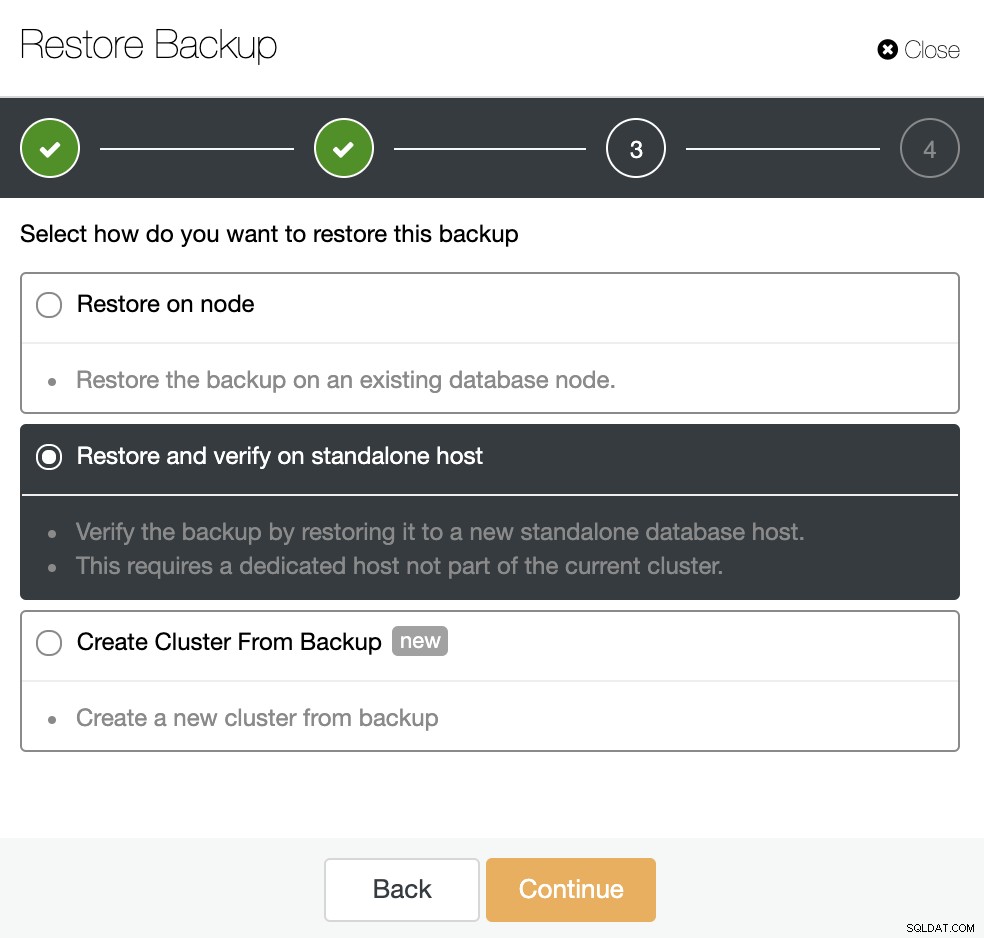
Masz trzy opcje przywrócenia kopii zapasowej. Możesz przywrócić kopię zapasową w istniejącym węźle bazy danych, przywrócić i zweryfikować kopię zapasową na samodzielnym hoście lub utworzyć nowy klaster z kopii zapasowej. Jeśli chcesz utworzyć zimny węzeł gotowości, użyjmy drugiej opcji „Przywróć i weryfikuj na samodzielnym hoście”.
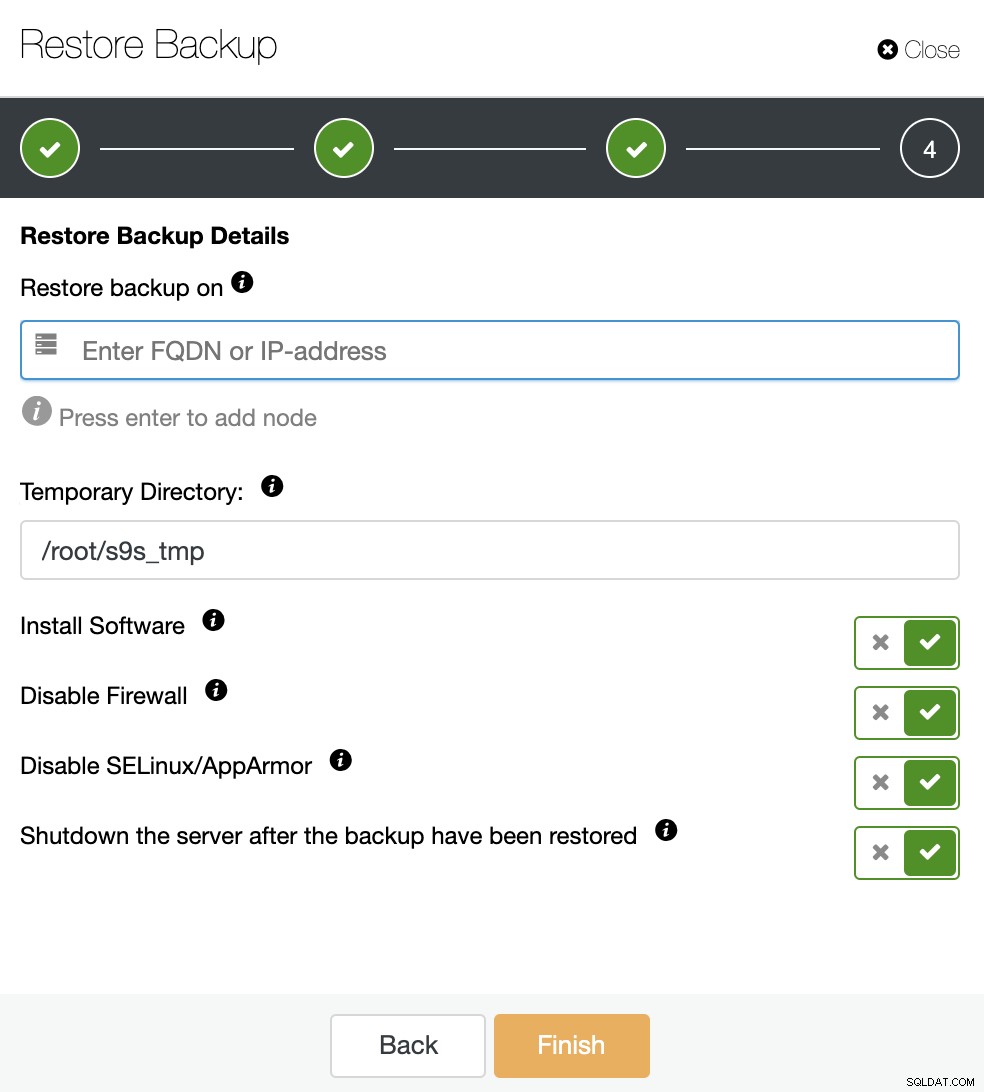
Potrzebujesz dedykowanego hosta (lub maszyny wirtualnej), która nie jest częścią klastra do przywrócenia kopii zapasowej, użyjmy więc instancji EC2 utworzonej dla tego zadania. ClusterControl zainstaluje oprogramowanie i przywróci kopię zapasową na tym hoście.
Jeśli opcja „Zamknij serwer po przywróceniu kopii zapasowej” jest włączona, ClusterControl zatrzyma węzeł bazy danych po zakończeniu zadania przywracania i to jest dokładnie to, czego potrzebujemy do tworzenia tego zimnego trybu gotowości.
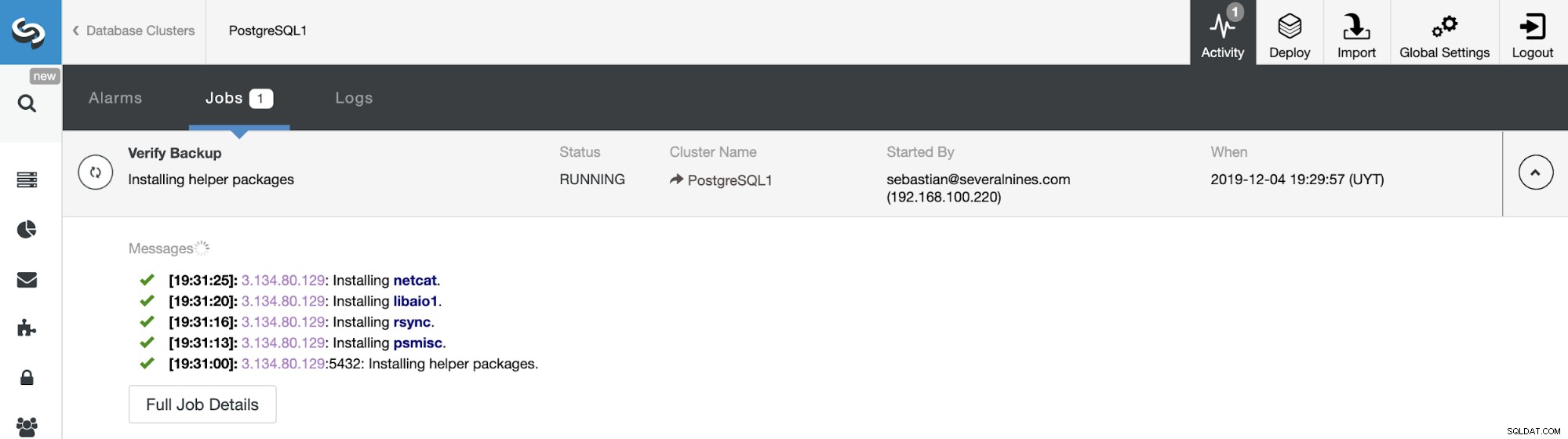
Możesz monitorować postęp tworzenia kopii zapasowej w sekcji ClusterControl Activity.
Korzystanie z funkcji weryfikacji kopii zapasowej ClusterControl
Kopia zapasowa nie jest kopią zapasową, jeśli nie można jej przywrócić. Dlatego upewnij się, że kopia zapasowa działa i często ją przywracaj w zimnym węźle gotowości.
Ta funkcja ClusterControl Verify Backup polega na zautomatyzowaniu konserwacji węzła zimnej gotowości, przywracając ostatnią kopię zapasową, aby zapewnić jej jak największą aktualność, unikając zadania ręcznego przywracania kopii zapasowej. Zobaczmy, jak to działa.
Jako zadanie „Przywróć i weryfikuj na hoście autonomicznym”, do przywrócenia kopii zapasowej będzie potrzebny dedykowany host (lub maszyna wirtualna), która nie jest częścią klastra, więc użyjmy tej samej instancji EC2 tutaj.
Funkcja automatycznej weryfikacji kopii zapasowej jest dostępna dla zaplanowanych kopii zapasowych. Przejdź do ClusterControl -> Wybierz Klaster PostgreSQL -> Kopia zapasowa -> Utwórz kopię zapasową i powtórz kroki, które widziałeś wcześniej, aby zaplanować nową kopię zapasową.
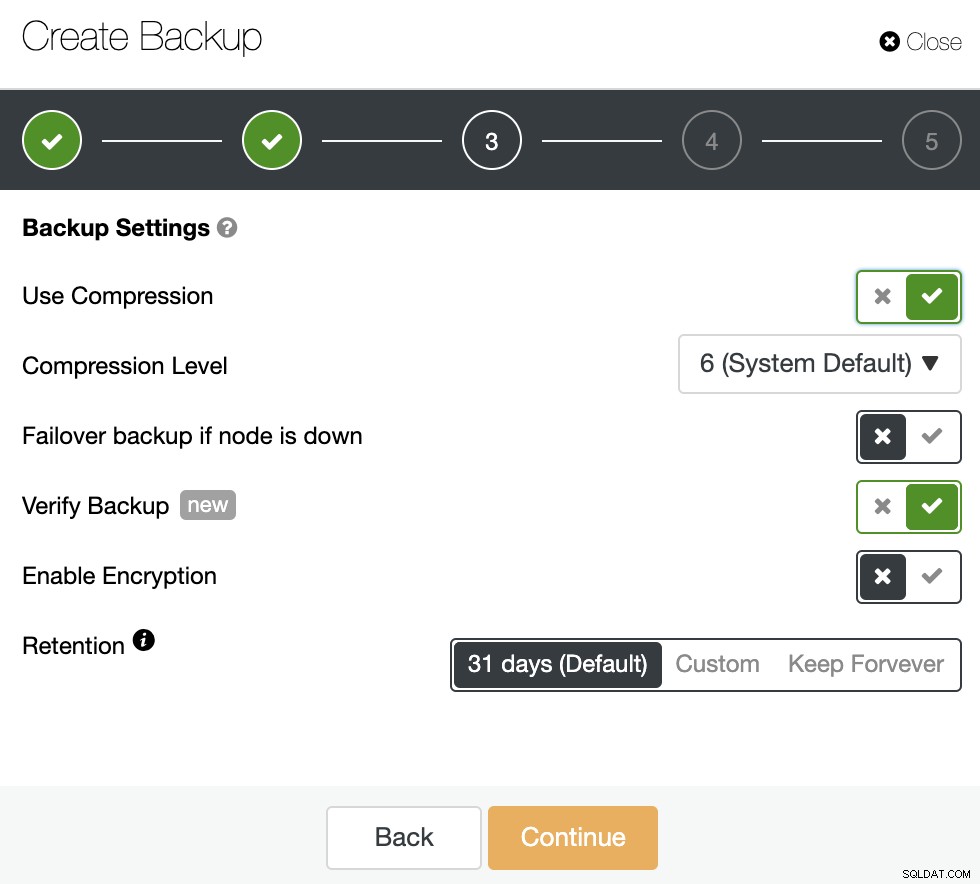
W drugim kroku dostępna będzie funkcja „Zweryfikuj kopię zapasową” aby go włączyć.
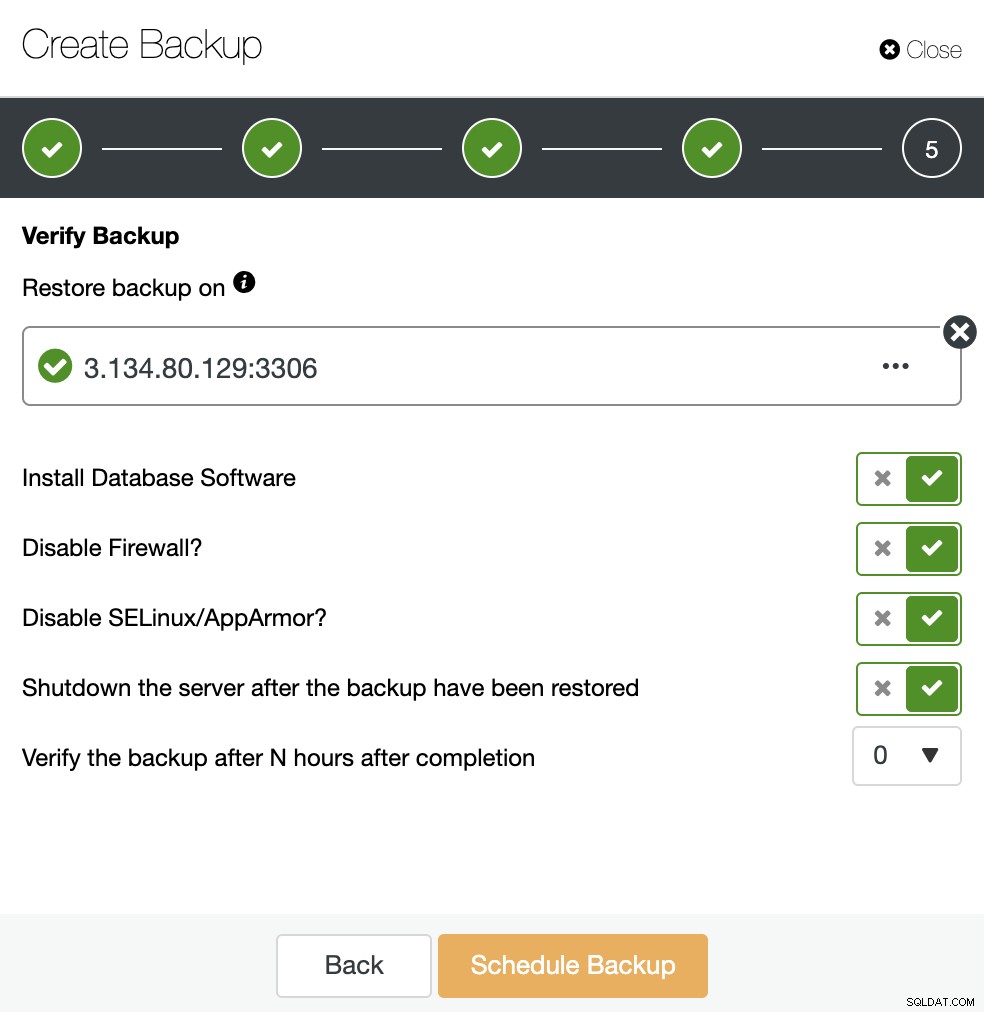
Używając powyższych opcji, ClusterControl zainstaluje oprogramowanie i przywróci kopię zapasową na gospodarz. Po przywróceniu, jeśli wszystko poszło dobrze, zobaczysz ikonę weryfikacji w sekcji ClusterControl Backup.
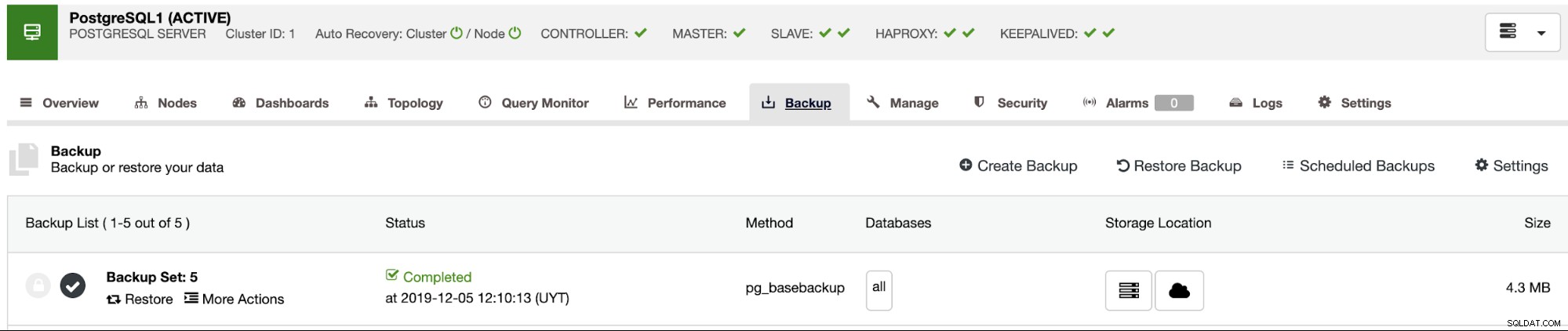
Wnioski
Jeśli masz ograniczony budżet, ale potrzebujesz wysokiej dostępności, możesz użyć węzła PostgreSQL w stanie gotowości, który może być prawidłowy lub nie, w zależności od RTO i RPO firmy. W tym blogu pokazaliśmy, jak zaplanować tworzenie kopii zapasowej (zgodnie z polityką biznesową) i jak przywrócić ją ręcznie. Pokazaliśmy również, jak automatycznie przywrócić kopię zapasową na serwerze w trybie czuwania zimnego za pomocą ClusterControl, Amazon S3 i Amazon EC2.