Zamknięcie dostawcy jest dobrze znaną koncepcją technologii baz danych. Wraz ze wzrostem wykorzystania chmury ta blokada rozszerzyła się również na dostawców chmury. Możemy zdefiniować uzależnienie od dostawcy jako zastrzeżone uzależnienie, które uzależnia klienta od dostawcy w zakresie jego produktów lub usług. Czasami ta blokada nie oznacza, że nie możesz zmienić sprzedawcy/dostawcy, ale może to być kosztowne lub czasochłonne zadanie.
PostgreSQL, technologia baz danych o otwartym kodzie źródłowym, sama w sobie nie wiąże się z problemem uzależnienia od dostawcy, ale jeśli używasz swoich systemów w chmurze, prawdopodobnie będziesz musiał sobie z tym poradzić ten problem w pewnym momencie.
W tym blogu podzielimy się kilkoma wskazówkami, jak uniknąć blokady PostgreSQL w chmurze, a także przyjrzymy się, jak ClusterControl może pomóc w jego unikaniu.
Wskazówka nr 1:Sprawdź ograniczenia lub ograniczenia dostawcy chmury
Dostawcy usług w chmurze zazwyczaj oferują prosty i przyjazny sposób (lub nawet narzędzie) migracji danych do chmury. Problem polega na tym, że gdy chcesz je opuścić, może być trudno znaleźć łatwy sposób na migrację danych do innego dostawcy lub do konfiguracji lokalnej. To zadanie zwykle wiąże się z wysokimi kosztami (często w oparciu o natężenie ruchu).
Aby uniknąć tego problemu, należy zawsze najpierw sprawdzić dokumentację i ograniczenia dostawcy chmury, aby poznać ograniczenia, które mogą być nieuniknione przy opuszczaniu.
Wskazówka nr 2:zaplanuj wyjście z dostawcy chmury
Najlepszą rekomendacją, jaką możemy Ci dać, jest nie czekanie do ostatniej chwili, aby dowiedzieć się, jak opuścić dostawcę chmury. Powinieneś to zaplanować z dużym wyprzedzeniem, aby poznać najlepszy, najszybszy i najtańszy sposób na wyjście.
Ponieważ ten plan najprawdopodobniej zależy od konkretnych wymagań biznesowych, plan będzie się różnił w zależności od tego, czy możesz zaplanować okna konserwacji i czy firma zaakceptuje jakiekolwiek okresy przestoju. Planując to wcześniej, na pewno unikniesz bólu głowy pod koniec dnia.
Wskazówka #3:Unikaj używania jakichkolwiek ekskluzywnych produktów dostawcy chmury
Produkt dostawcy chmury prawie zawsze będzie działał lepiej niż produkt open source. Wynika to z faktu, że został zaprojektowany i przetestowany pod kątem działania w infrastrukturze dostawcy chmury. Wydajność będzie często znacznie lepsza niż w przypadku drugiej.
Jeśli musisz przeprowadzić migrację baz danych do innego dostawcy, będziesz mieć problem z zablokowaniem technologii, ponieważ produkt dostawcy chmury jest dostępny tylko w obecnym środowisku dostawcy chmury. Oznacza to, że nie będziesz w stanie łatwo przeprowadzić migracji. Prawdopodobnie możesz znaleźć sposób, aby to zrobić, generując plik zrzutu (lub inną metodę tworzenia kopii zapasowej), ale prawdopodobnie będziesz mieć długi czas przestoju (w zależności od ilości danych i technologii, których chcesz użyć).
Jeśli korzystasz z Amazon RDS lub Aurora, Azure SQL Database lub Google Cloud SQL (aby skupić się na najczęściej używanych obecnie dostawcach chmury), powinieneś rozważyć sprawdzenie alternatyw w celu migracji do open source Baza danych. Dzięki temu nie mówimy, że powinieneś go migrować, ale zdecydowanie powinieneś mieć możliwość zrobienia tego w razie potrzeby.
Wskazówka 4:Przechowuj kopie zapasowe u innego dostawcy chmury
Dobrą praktyką skracania przestojów, czy to w przypadku migracji, czy odzyskiwania po awarii, jest nie tylko przechowywanie kopii zapasowych w tym samym miejscu (ze względu na szybsze odzyskiwanie), ale także przechowywanie kopii zapasowych w innego dostawcy chmury lub nawet lokalnie.
Postępując zgodnie z tą praktyką, gdy trzeba przywrócić lub przeprowadzić migrację danych, wystarczy skopiować najnowsze dane po przywróceniu kopii zapasowej. Ilość ruchu i czas będą znacznie mniejsze niż kopiowanie wszystkich danych bez kompresji podczas migracji lub zdarzenia niepowodzenia.
Wskazówka nr 5:Użyj modelu wielochmurowego lub hybrydowego
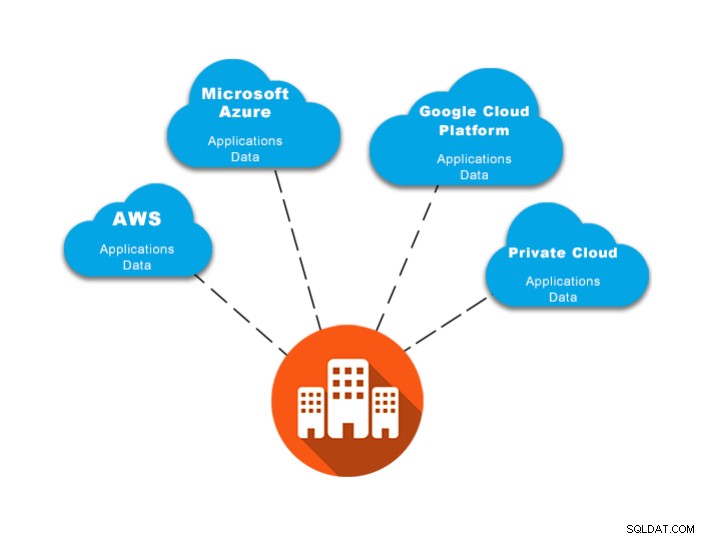
To prawdopodobnie najlepsza opcja, jeśli chcesz uniknąć blokowania chmury . Przechowywanie danych w dwóch lub więcej miejscach w czasie rzeczywistym (lub tak zbliżonym do czasu rzeczywistego, jak to tylko możliwe) pozwala na szybką migrację i możesz to zrobić przy jak najmniejszym przestoju. Jeśli masz klaster PostgreSQL w jednym dostawcy chmury, a węzeł zapasowy PostgreSQL w innym, na wypadek konieczności zmiany dostawcy możesz po prostu promować węzeł zapasowy i wysyłać ruch do tego nowego głównego węzła PostgreSQL.
Podobną koncepcję stosuje się do modelu hybrydowego. Możesz trzymać swój klaster produkcyjny w chmurze, a następnie utworzyć on-prem klaster zapasowy lub węzeł bazy danych, który generuje topologię hybrydową (chmura/on-prem), a w przypadku awarii lub konieczności migracji możesz awansować węzeł gotowości bez blokady w chmurze, ponieważ korzystasz z własnego środowiska.
W takim przypadku należy pamiętać, że prawdopodobnie dostawca chmury będzie pobierał opłaty za ruch wychodzący, więc przy dużym natężeniu ruchu utrzymywanie tej metody może generować nadmierne koszty dla firmy.
Jak ClusterControl może pomóc uniknąć blokady PostgreSQL
Aby uniknąć blokady PostgreSQL, możesz również użyć ClusterControl do wdrażania (lub importowania), zarządzania i monitorowania klastrów baz danych. W ten sposób nie będziesz zależny od konkretnej technologii lub dostawcy, aby utrzymać swoje systemy w stanie gotowości.
ClusterControl ma przyjazny i łatwy w użyciu interfejs użytkownika, więc nie musisz używać konsoli zarządzania usługodawcą w chmurze do zarządzania bazami danych, wystarczy się zalogować i będziesz mieć przegląd wszystkich klastrów baz danych w tym samym systemie.
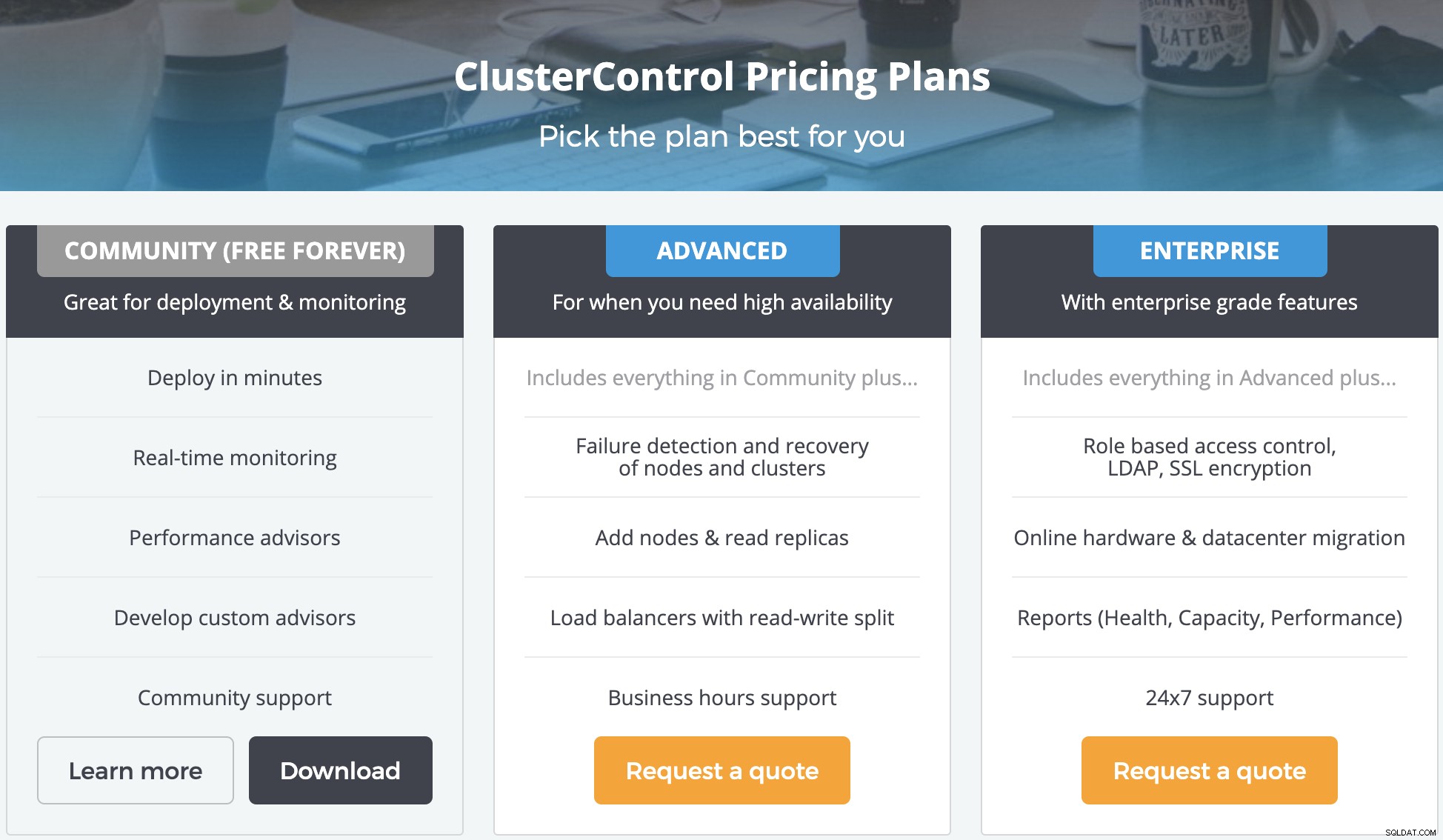
Ma trzy różne wersje (w tym wersję bezpłatną dla społeczności). Nadal możesz używać ClusterControl (bez niektórych płatnych funkcji), nawet jeśli Twoja licencja wygasła i nie wpłynie to na wydajność Twojej bazy danych.
Można wdrażać różne aparaty baz danych typu open source z tego samego systemu i tylko Do korzystania z niego wymagany jest dostęp SSH i uprzywilejowany użytkownik.
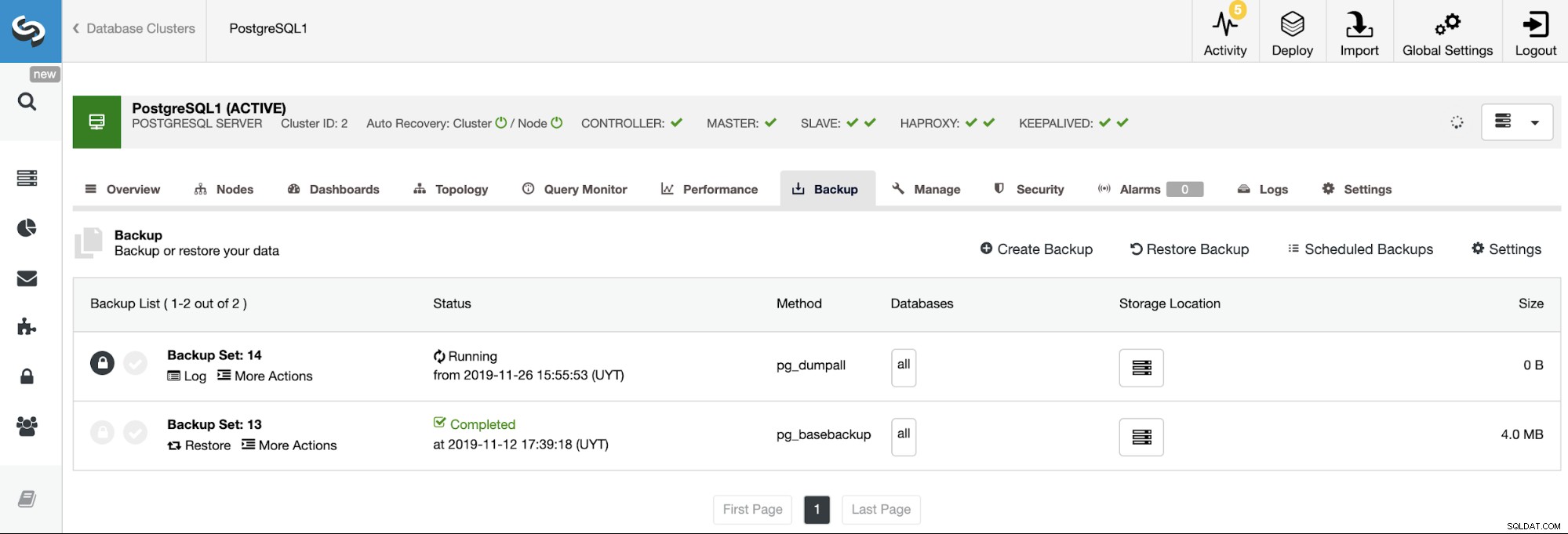
ClusterControl może również pomóc w zarządzaniu systemem kopii zapasowych. Z tego miejsca możesz zaplanować nową kopię zapasową przy użyciu różnych metod tworzenia kopii zapasowych (w zależności od silnika bazy danych), kompresować, szyfrować, weryfikować kopie zapasowe, przywracając je w innym węźle. Możesz również przechowywać go w wielu różnych lokalizacjach jednocześnie (w tym w chmurze).
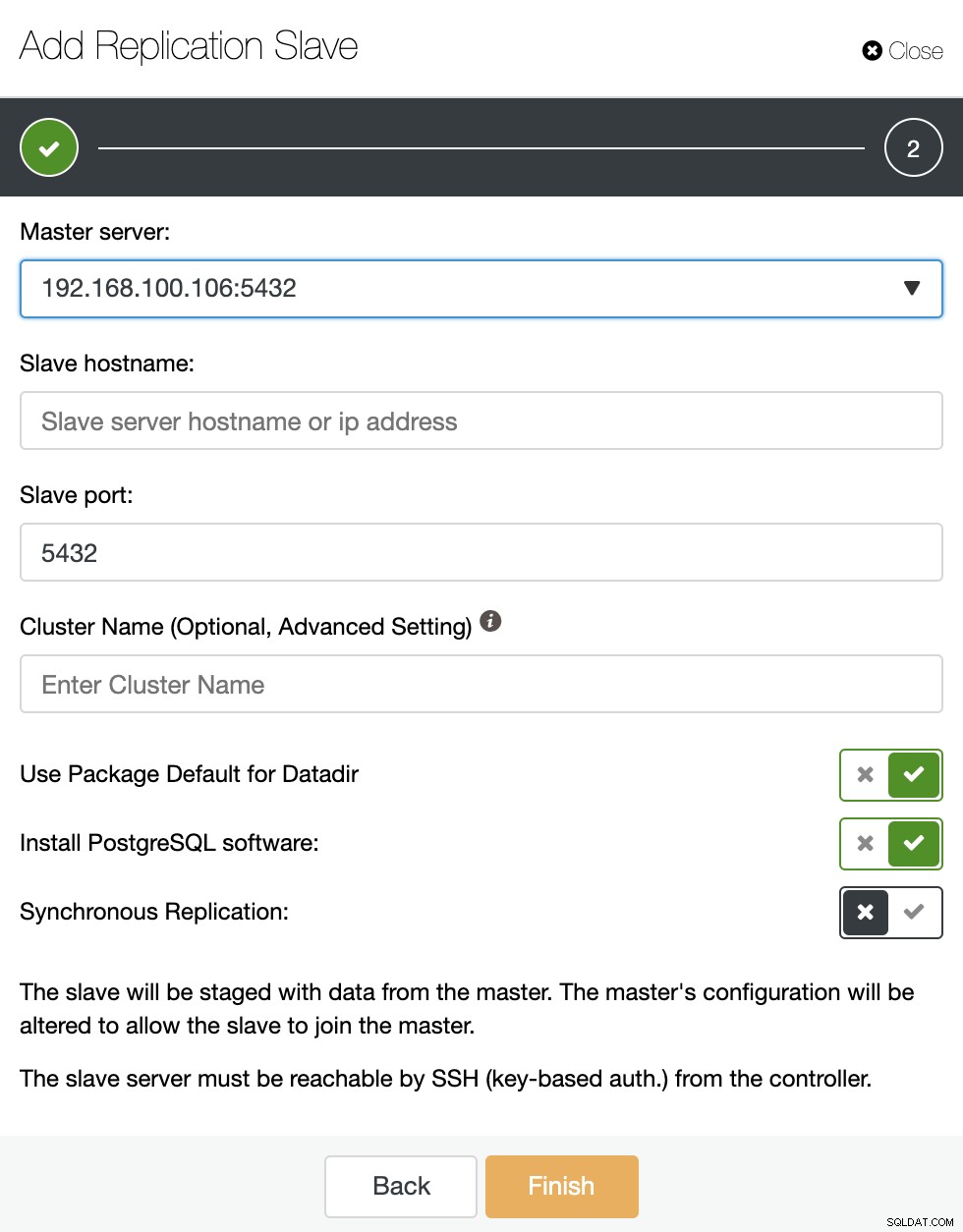
Wdrożenie wielochmurowe lub hybrydowe jest łatwe do wykonania za pomocą ClusterControl za pomocą Replikacja klastrów do klastrów lub funkcja Dodaj podrzędną replikację. Wystarczy postępować zgodnie z prostym kreatorem, aby wdrożyć nowy węzeł bazy danych lub klaster w innym miejscu.
Wnioski
Ponieważ dane są prawdopodobnie najważniejszym zasobem firmy, najprawdopodobniej będziesz chciał zachować jak największą kontrolę nad danymi. Blokada chmury nie pomaga w tym. Jeśli jesteś w scenariuszu z blokadą w chmurze, oznacza to, że nie możesz zarządzać swoimi danymi tak, jak chcesz, a to może stanowić problem.
Jednak blokada chmury nie zawsze stanowi problem. Możliwe, że korzystasz z całego systemu (bazy danych, aplikacje itp.) u tego samego dostawcy chmury, korzystając z produktów dostawcy (Amazon RDS lub Aurora, Azure SQL Database lub Google Cloud SQL) i nie szukasz migrując cokolwiek, zamiast tego możliwe jest, że korzystasz ze wszystkich zalet dostawcy chmury. Unikanie blokady w chmurze nie zawsze jest koniecznością, ponieważ zależy to od każdego przypadku.
Mamy nadzieję, że podobał Ci się nasz blog, w którym przedstawiono najczęstsze sposoby na uniknięcie blokady PostgreSQL w chmurze i sposób, w jaki ClusterControl może pomóc.