Wielokrotnie wspominaliśmy o zaletach używania Load Balancer w topologii bazy danych. Może to być przekierowanie ruchu do sprawnych węzłów bazy danych, rozłożenie ruchu na wiele serwerów w celu poprawy wydajności lub po prostu skonfigurowanie jednego punktu końcowego w aplikacji w celu ułatwienia konfiguracji i procesu przełączania awaryjnego.
Teraz dzięki nowej wersji ClusterControl 1.7.6 możesz nie tylko wdrożyć swój klaster PostgreSQL bezpośrednio w chmurze, ale także wdrożyć Load Balancery w tym samym zadaniu. W tym celu ClusterControl obsługuje AWS, Google Cloud i Azure jako dostawców chmury. Przyjrzyjmy się tej nowej funkcji.
Tworzenie nowego klastra baz danych
W tym przykładzie założymy, że masz konto u jednego ze wspomnianych obsługiwanych dostawców chmury i skonfigurowałeś swoje poświadczenia w instalacji ClusterControl 1.7.6.
Jeśli nie masz tego skonfigurowanego, musisz przejść do ClusterControl -> Integracje -> Dostawcy chmury -> Dodaj poświadczenia chmury.

Tutaj musisz wybrać dostawcę chmury i dodać odpowiednie informacje.
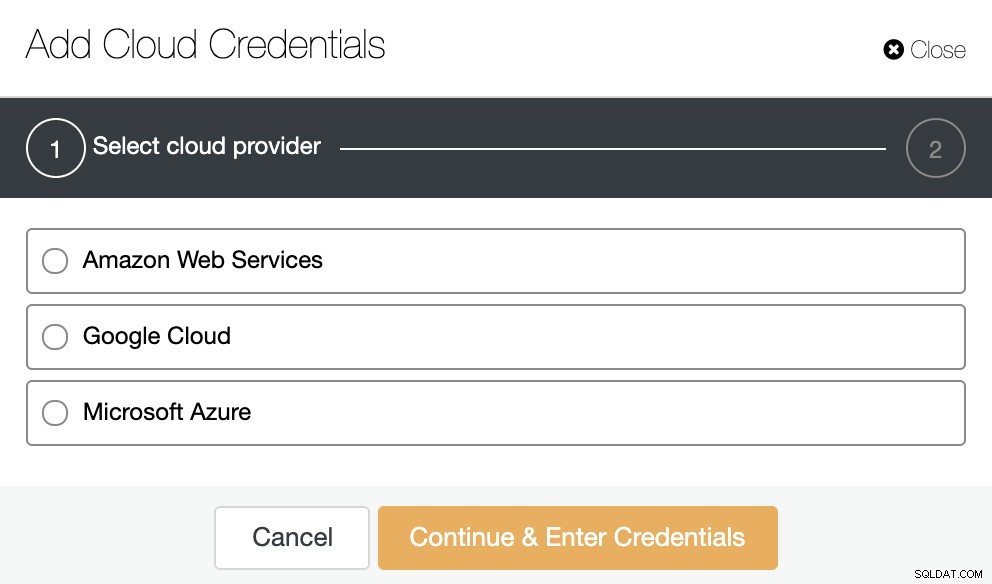
Te informacje zależą od samego dostawcy chmury. Aby uzyskać więcej informacji, zapoznaj się z naszą oficjalną dokumentacją.
Nie musisz uzyskiwać dostępu do konsoli zarządzania dostawcy chmury, aby cokolwiek tworzyć, możesz wdrożyć swoje maszyny wirtualne, bazy danych i systemy równoważenia obciążenia bezpośrednio z ClusterControl. Przejdź do sekcji wdrażania i wybierz „Wdróż w chmurze”.
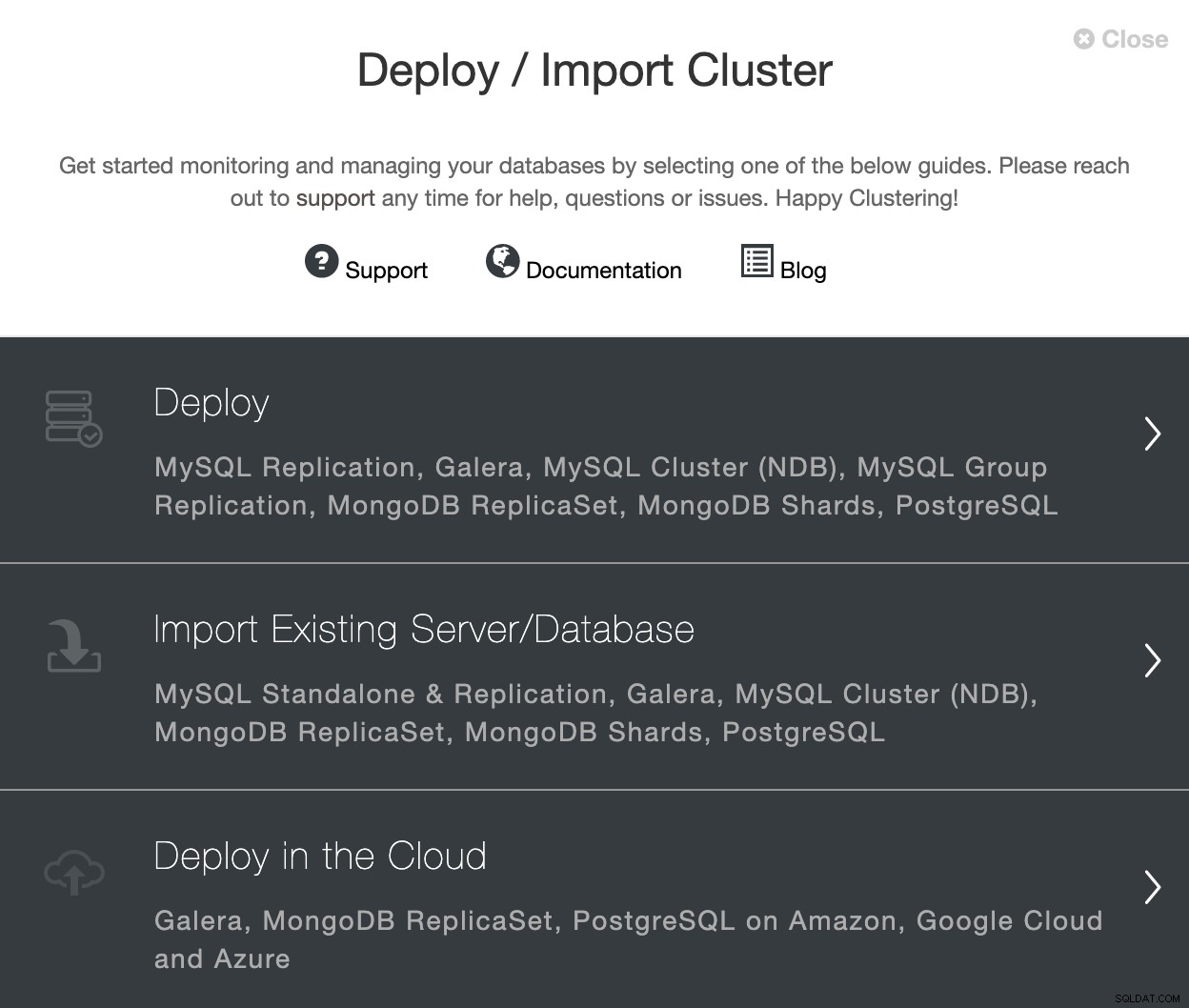
Określ dostawcę i wersję nowego klastra bazy danych. W tym przypadku użyjemy PostgreSQL 12.
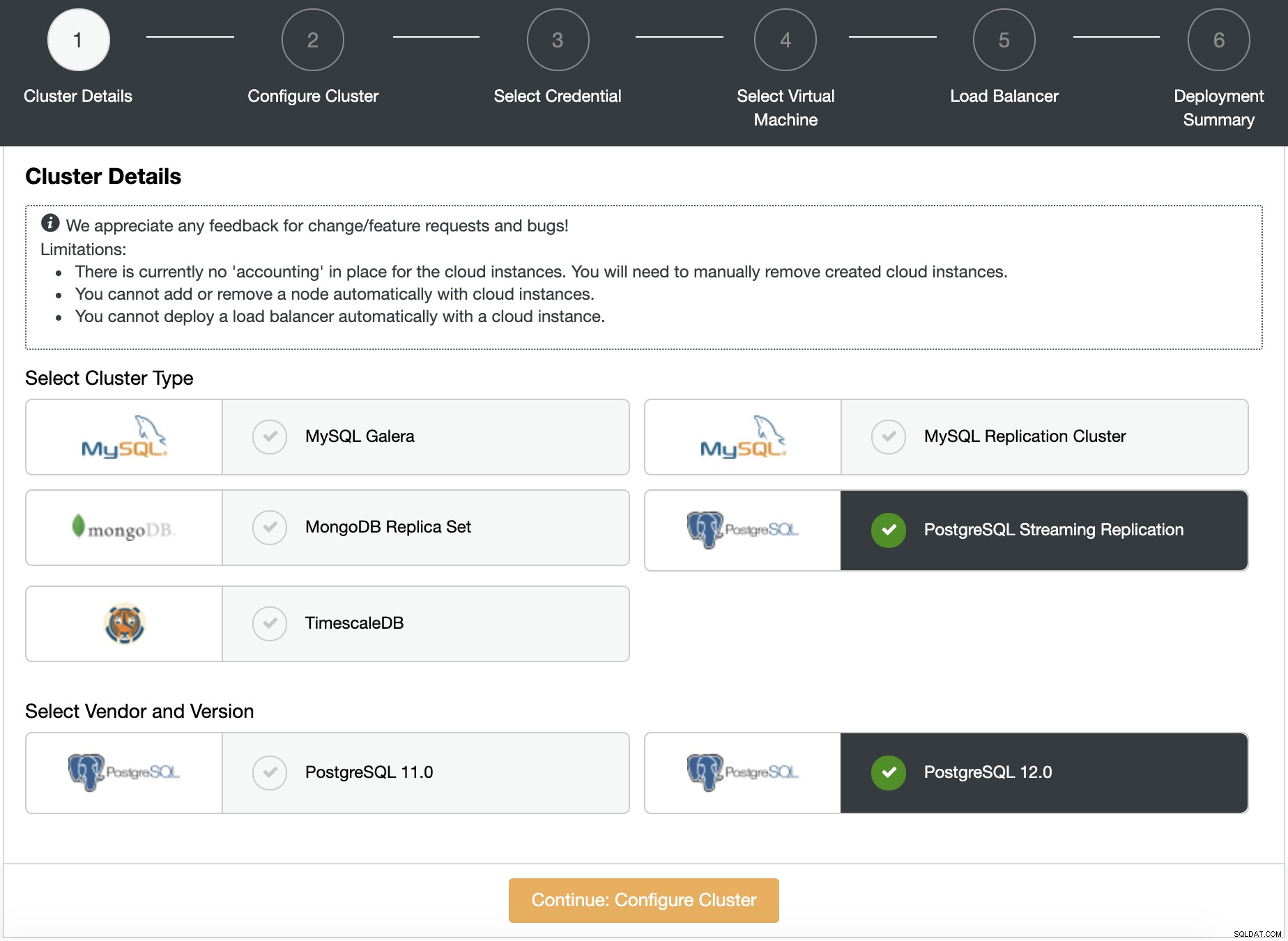
Dodaj liczbę węzłów, nazwę klastra i informacje o bazie danych, takie jak poświadczenia i port serwera.
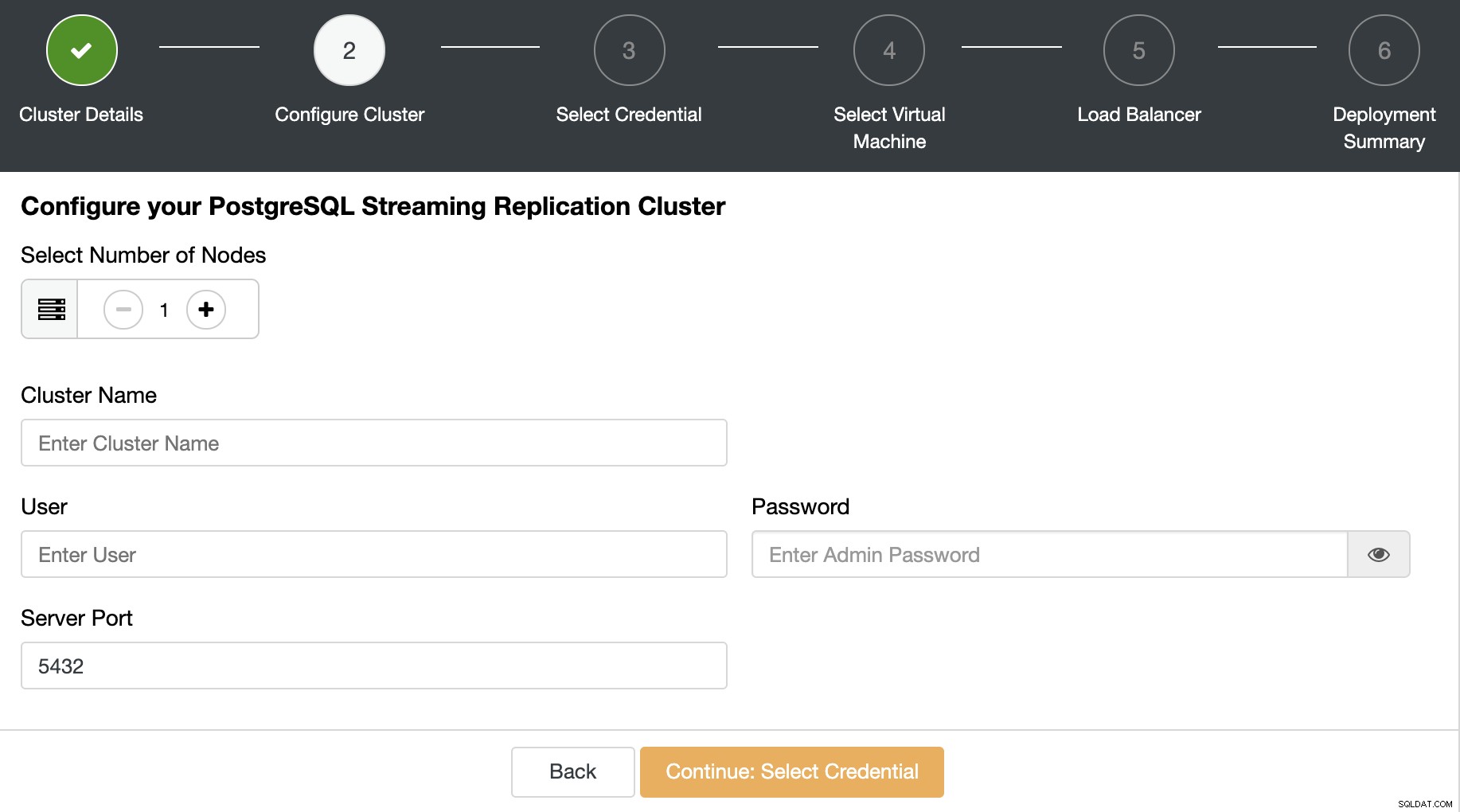
Wybierz poświadczenia chmury, w tym przypadku użyjemy AWS rachunek. Jeśli nie masz jeszcze konta dodanego do ClusterControl, możesz postępować zgodnie z naszą dokumentacją dotyczącą tego zadania.
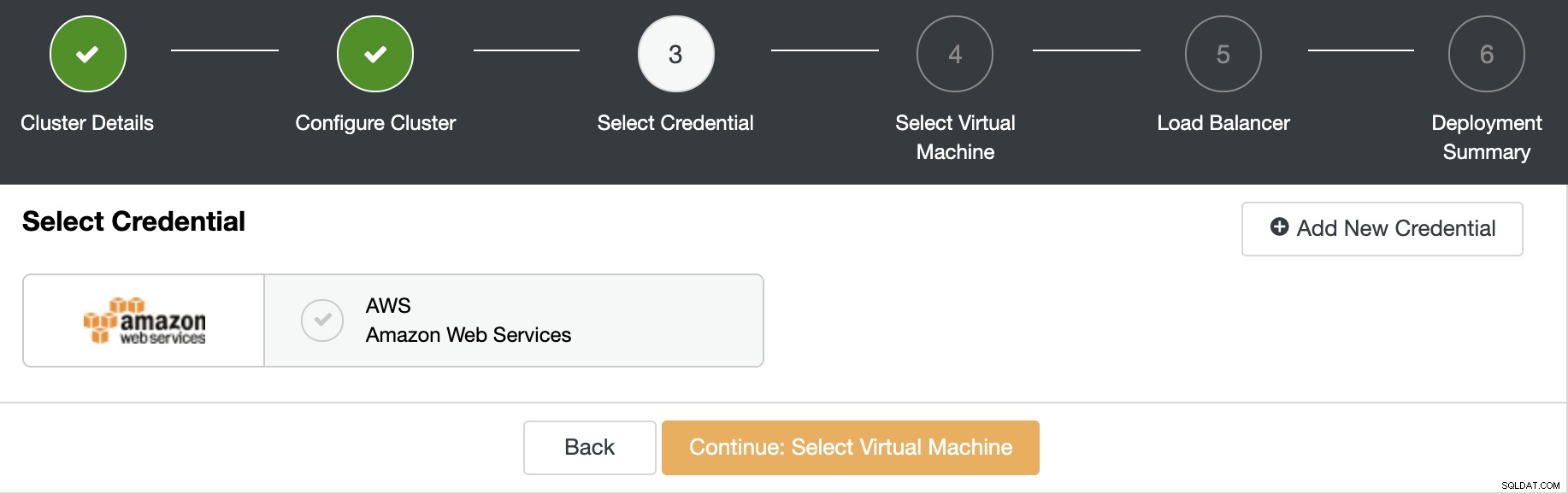
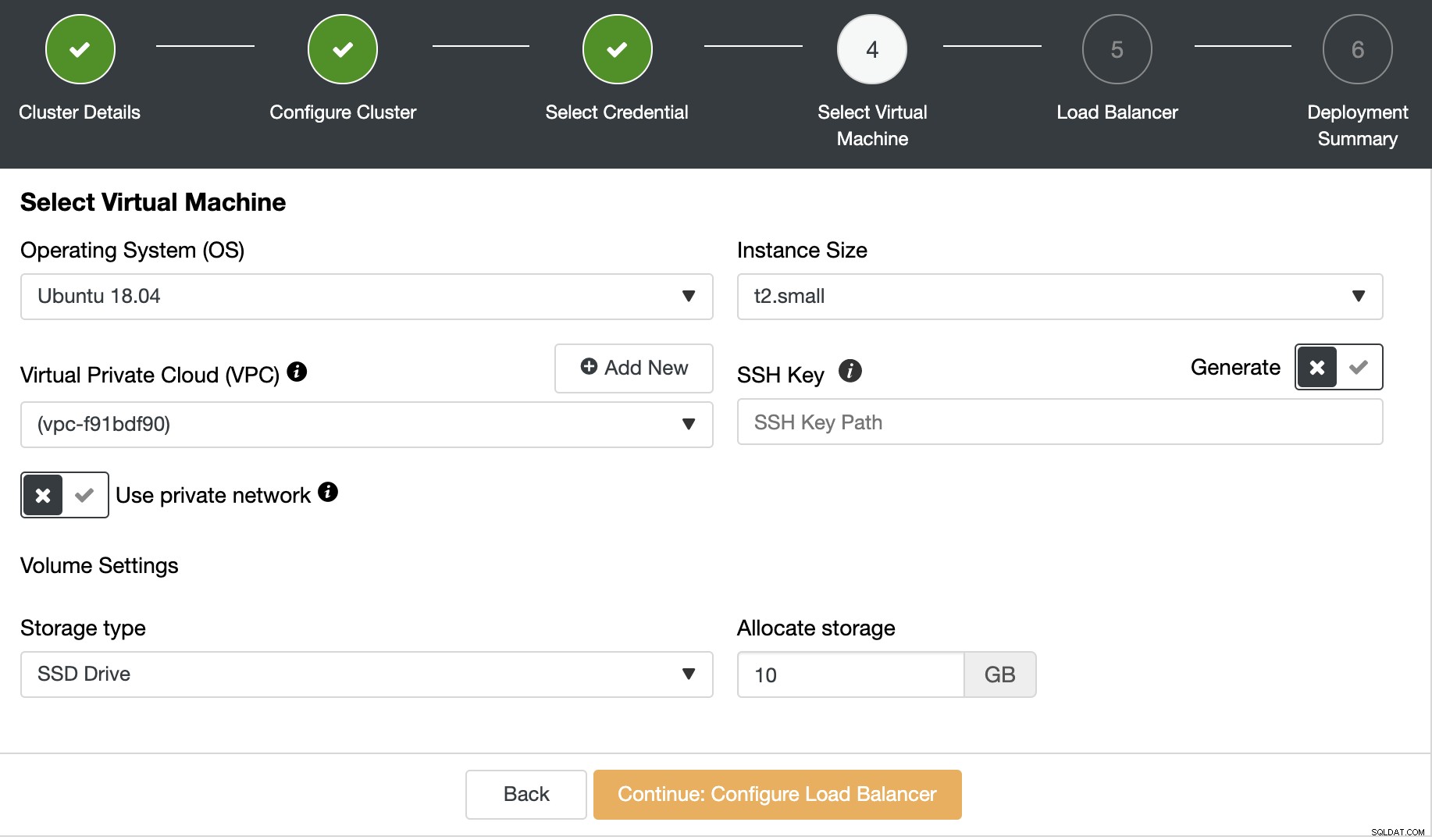
Teraz musisz określić konfigurację maszyny wirtualnej, np. system operacyjny, rozmiar, i region.
W następnym kroku możesz dodać Load Balancer do swojego klastra bazy danych. W przypadku PostgreSQL ClusterControl obsługuje HAProxy jako Load Balancer. Musisz wybrać liczbę węzłów Load Balancer, rozmiar wystąpienia i informacje Load Balancer.
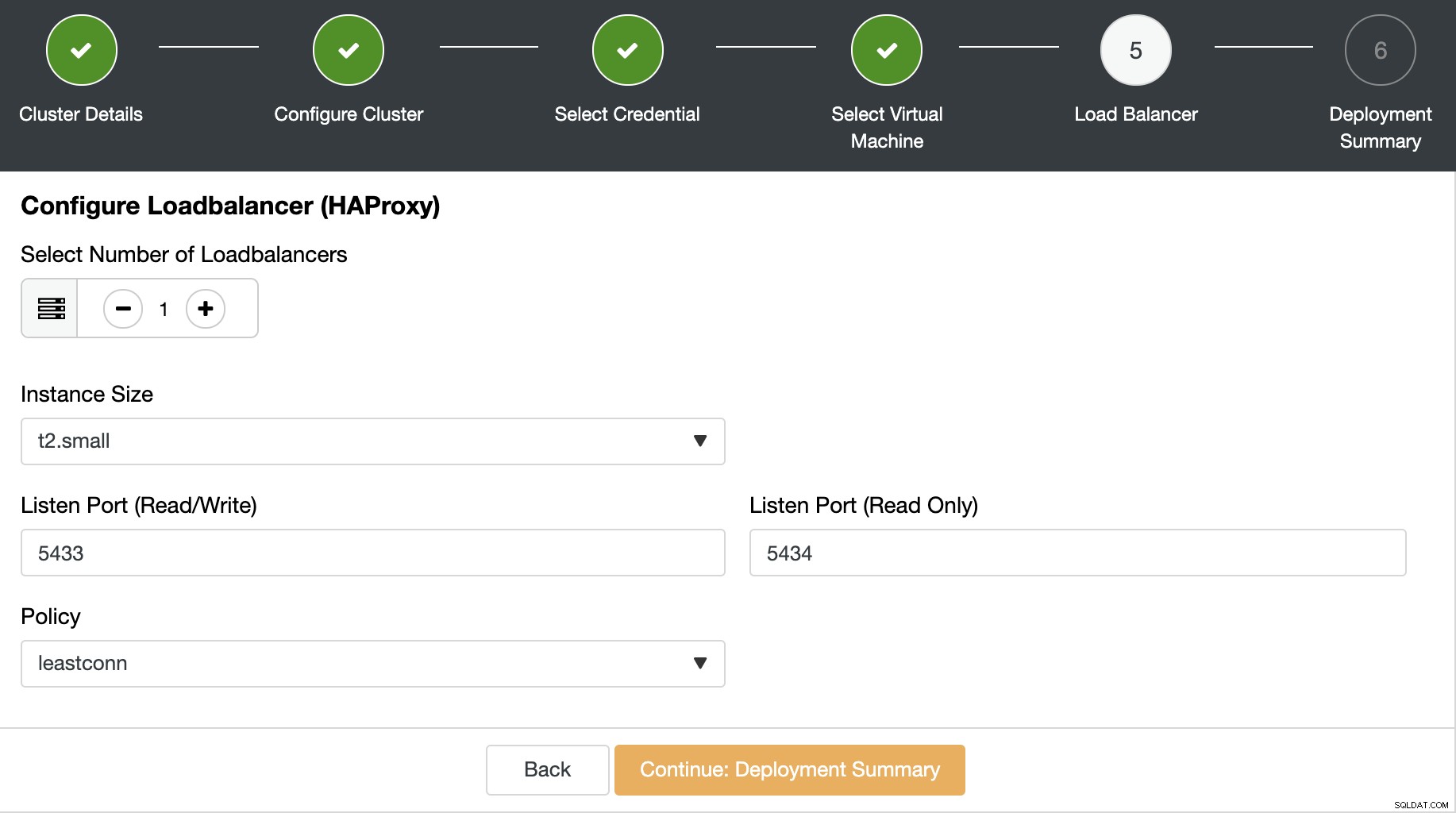
Te informacje dotyczące systemu równoważenia obciążenia to:
- Port nasłuchiwania (odczyt/zapis):port dla ruchu odczytu/zapisu.
- Port nasłuchiwania (tylko do odczytu):Port dla ruchu tylko do odczytu.
- Zasady:Może to być:
- leastconn:serwer z najmniejszą liczbą połączeń odbiera połączenie
- roundrobin:każdy serwer jest używany po kolei, zgodnie z ich wagami
- źródło:źródłowy adres IP jest haszowany i dzielony przez całkowitą wagę działających serwerów w celu wyznaczenia, który serwer otrzyma żądanie
Teraz możesz przejrzeć podsumowanie i wdrożyć je.
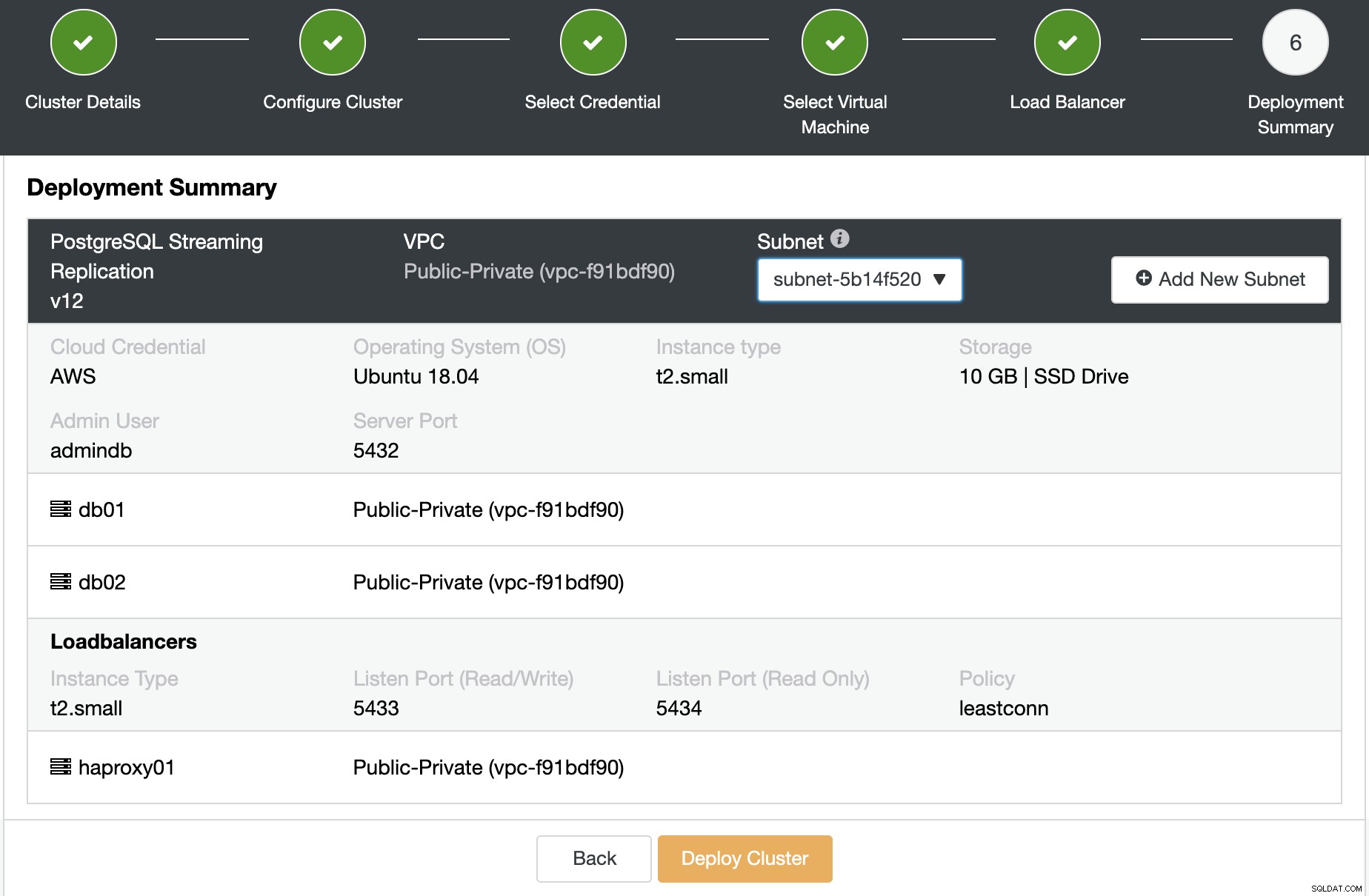
ClusterControl utworzy maszyny wirtualne, zainstaluje oprogramowanie i je skonfiguruje, wszystko w tej samej pracy i bez nadzoru.
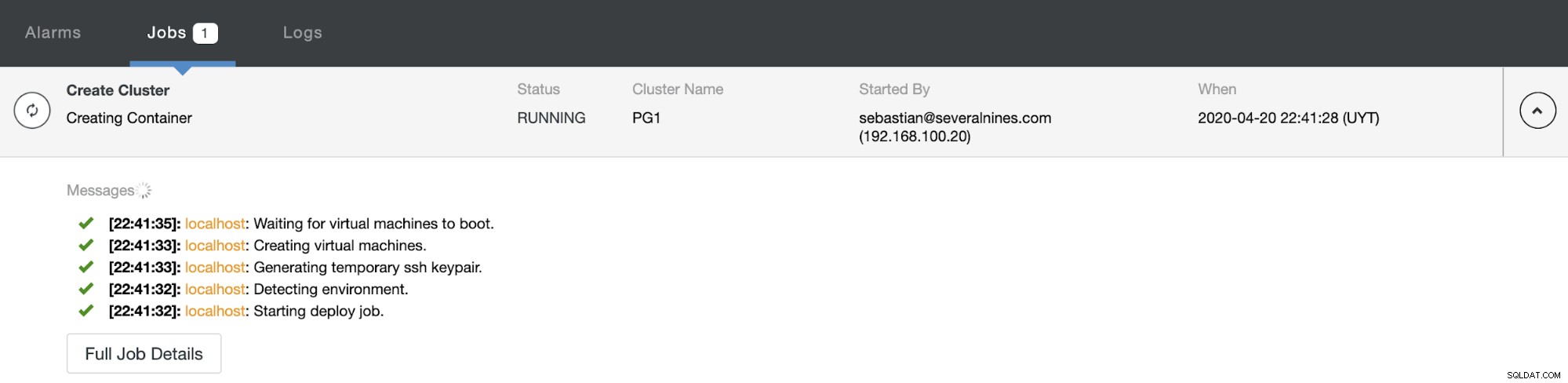
Proces tworzenia można monitorować w sekcji aktywności ClusterControl. Po zakończeniu zobaczysz swój nowy klaster na głównym ekranie ClusterControl.

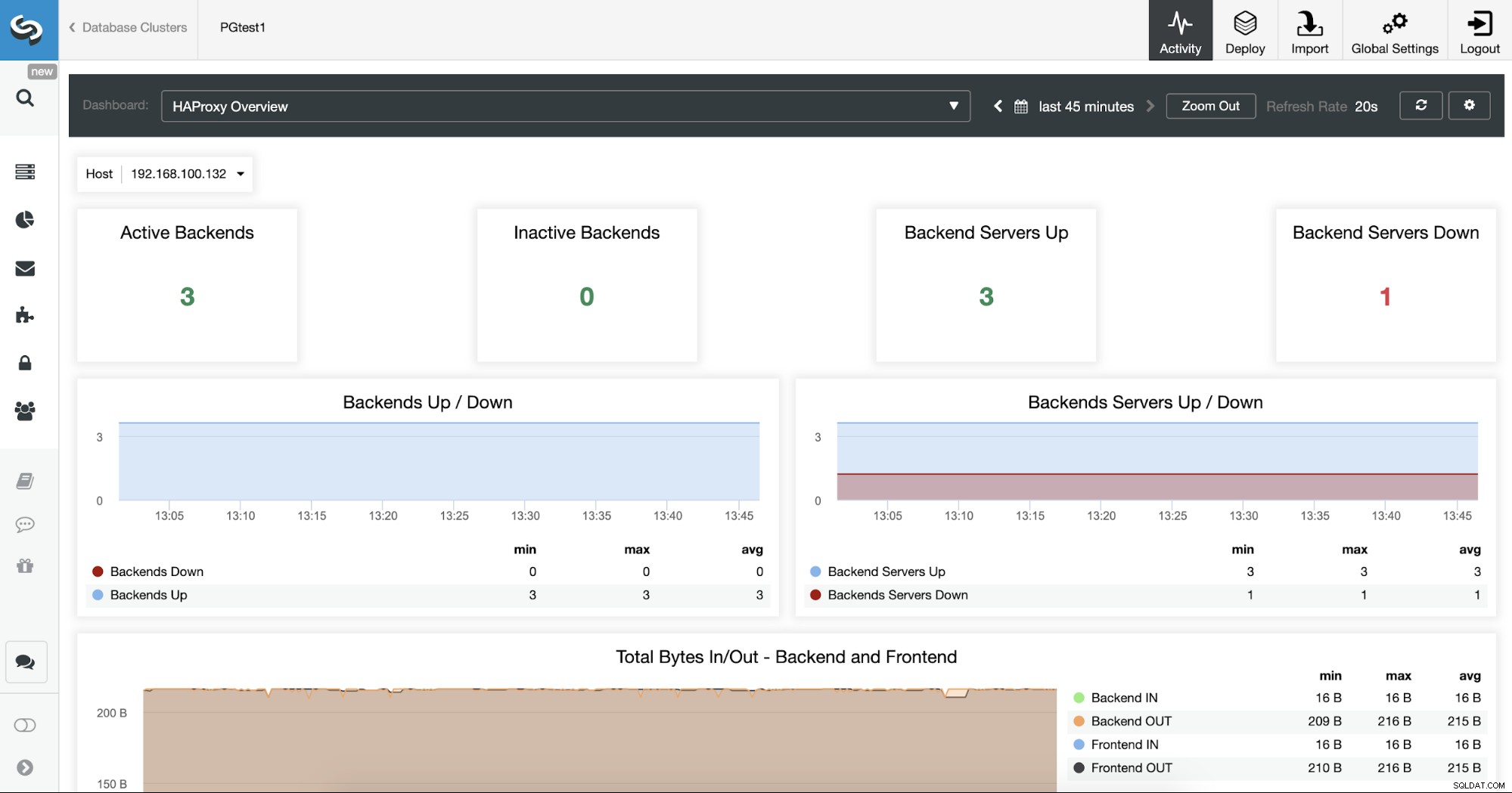
Jeśli chcesz sprawdzić węzły Load Balancers, możesz przejść do ClusterControl -> Węzły -> węzeł HAProxy i sprawdź aktualny stan.
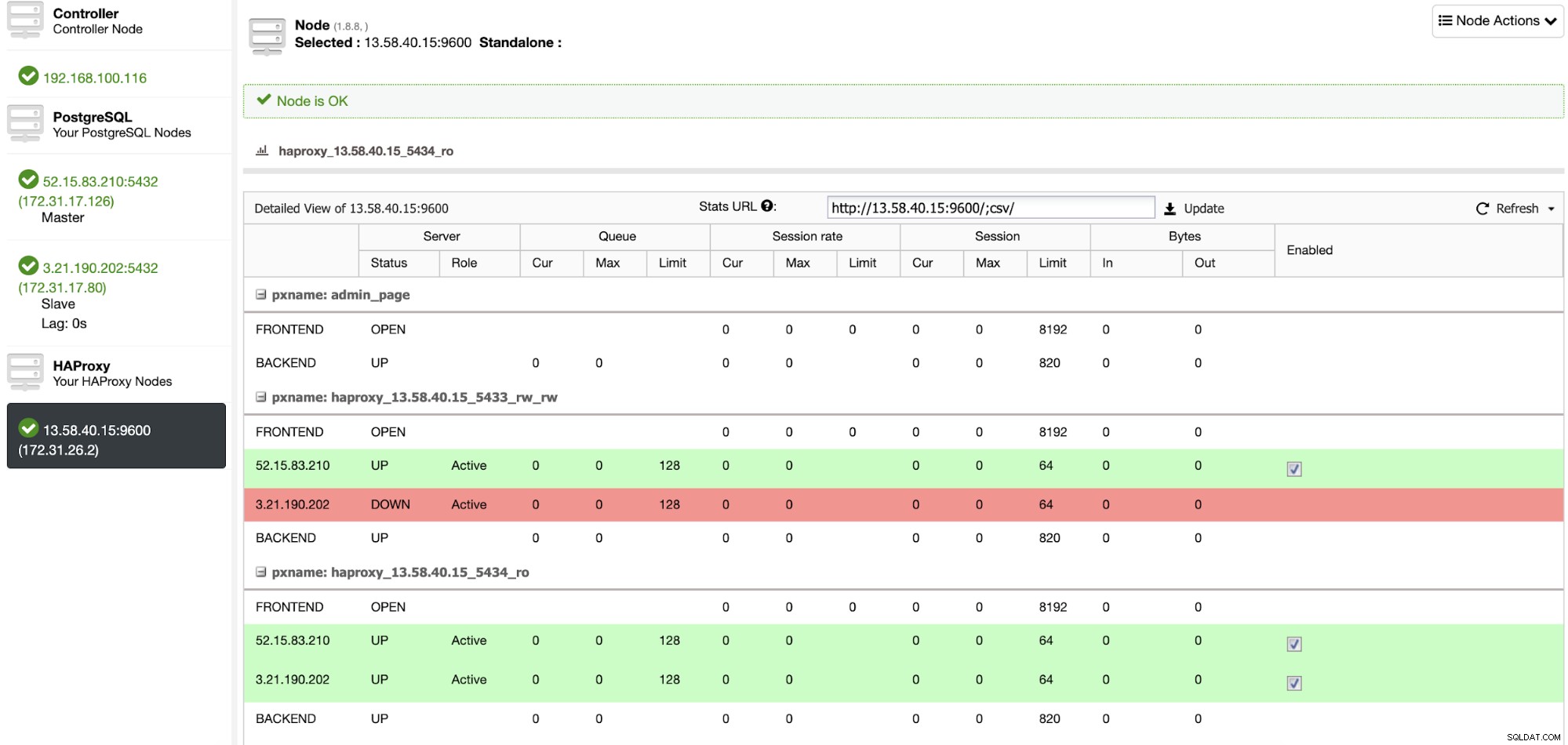
Możesz także monitorować swoje serwery HAProxy z ClusterControl, sprawdzając sekcję Pulpit nawigacyjny.
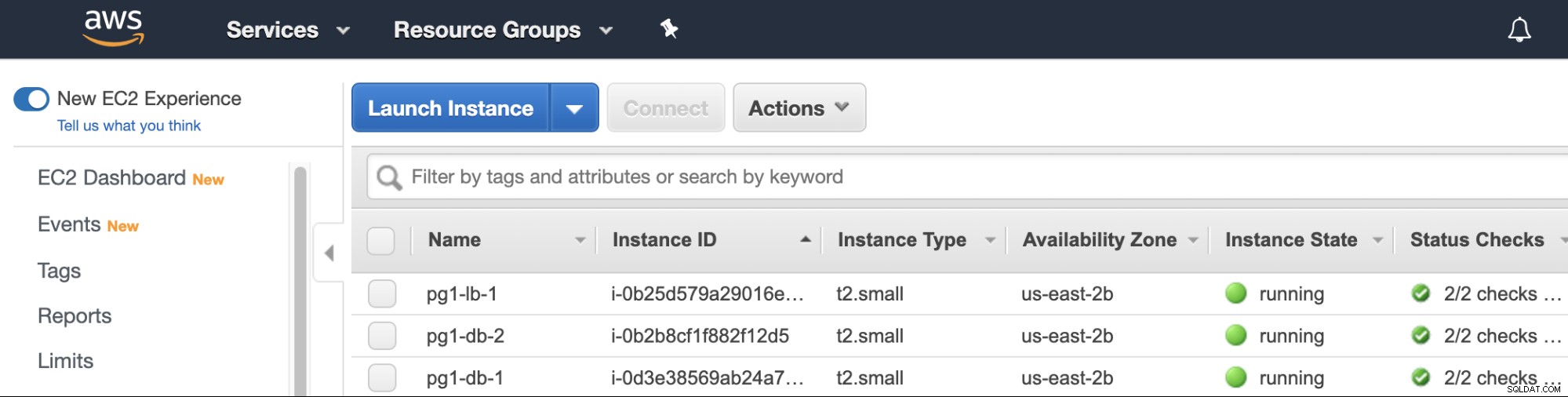
Teraz możesz sprawdzić konsolę zarządzania dostawcą chmury, gdzie znajdziesz maszyny wirtualne utworzone zgodnie z wybranymi opcjami zadania ClusterControl.
Wnioski
Jak widać, posiadanie Load Balancera przed klastrem PostgreSQL w chmurze jest naprawdę łatwe dzięki nowej funkcji ClusterControl „Wdrażanie w chmurze”, w której możesz wdrażać bazy danych i węzły Load Balancer w tym samym zadaniu.