Specjaliści ds. danych nie zawsze mogą korzystać z baz danych o optymalnym projekcie. Czasami rzeczy, które sprawiają, że płaczesz, to rzeczy, które sami sobie zrobiliśmy, ponieważ wtedy wydawały się dobrymi pomysłami. Czasami wynikają z aplikacji innych firm. Czasami po prostu wyprzedzają cię.
To, o czym myślę w tym poście, to sytuacja, w której kolumna datetime (lub datetime2, lub jeszcze lepiej datetimeoffset) to w rzeczywistości dwie kolumny – jedna dla daty, a druga dla godziny. (Jeżeli znowu masz osobną kolumnę dla przesunięcia, to następnym razem cię uściskam, ponieważ prawdopodobnie musiałeś radzić sobie z wszelkiego rodzaju bólami.)
Przeprowadziłem ankietę na Twitterze i stwierdziłem, że jest to bardzo realny problem, z którym około połowa z was musi od czasu do czasu radzić sobie z datą i godziną.
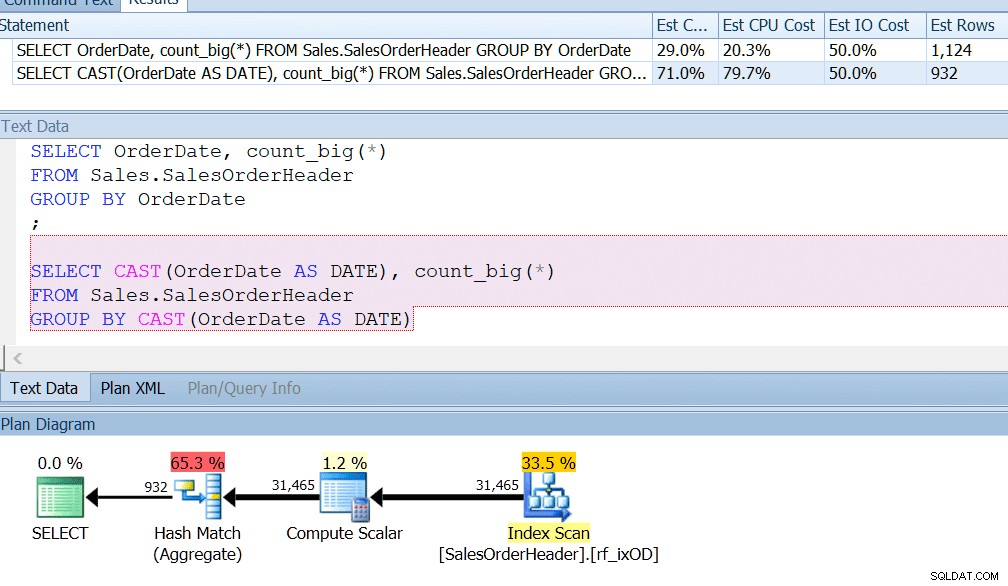
AdventureWorks prawie to robi — jeśli zajrzysz do tabeli Sales.SalesOrderHeader, zobaczysz kolumnę daty i godziny o nazwie OrderDate, która zawsze zawiera dokładne daty. Założę się, że jeśli jesteś programistą raportów w AdventureWorks, prawdopodobnie napisałeś zapytania, które wyszukują liczbę zamówień w danym dniu, używając funkcji GROUP BY OrderDate lub czegoś podobnego. Nawet jeśli wiesz, że jest to kolumna daty i godziny i istnieje możliwość przechowywania w niej godziny innej niż północ, nadal możesz powiedzieć GROUP BY OrderDate tylko ze względu na prawidłowe użycie indeksu. GROUP BY CAST (OrderDate AS DATE) po prostu go nie ogranicza.
Mam indeks na OrderDate, tak jak gdybyś regularnie odpytywał tę kolumnę, i widzę, że grupowanie według CAST (OrderDate AS DATE) jest około cztery razy gorsze z punktu widzenia procesora.
Rozumiem więc, dlaczego z przyjemnością zapytasz swoją kolumnę tak, jakby była to data, po prostu wiedząc, że będziesz miał świat bólu, jeśli zmieni się użycie tej kolumny. Może rozwiążesz to, mając na stole ograniczenie. Może po prostu schowałeś głowę w piasek.
A kiedy ktoś przychodzi i mówi „Wiesz, powinniśmy również przechowywać czas, w którym zdarzają się zamówienia”, cóż, myślisz o całym kodzie, który zakłada, czasu, proszę) będzie najrozsądniejszą opcją. Rozumiem. To nie jest idealne, ale działa bez łamania zbyt wielu rzeczy.
W tym momencie zalecam również utworzenie OrderDateTime, który byłby obliczoną kolumną łączącą te dwa (co należy zrobić, dodając liczbę dni od dnia 0 do CAST (OrderDate jako datetime2), zamiast próbować dodawać czas do data, która jest na ogół dużo bardziej nieuporządkowana). A następnie zindeksuj OrderDateTime, ponieważ byłoby to rozsądne.
Ale dość często znajdziesz datę i godzinę w oddzielnych kolumnach, w zasadzie nic nie możesz z tym zrobić. Nie możesz dodać kolumny wyliczanej, ponieważ jest to aplikacja innej firmy i nie wiesz, co może się zepsuć. Czy na pewno nigdy nie robią WYBIERZ *? Mam nadzieję, że pewnego dnia pozwolą nam dodać kolumny i ukryć je, ale na razie z pewnością ryzykujesz zepsucie rzeczy.
I wiesz, nawet msdb to robi. Obie są liczbami całkowitymi. I to z powodu wstecznej kompatybilności, jak zakładam. Ale wątpię, czy rozważasz dodanie kolumny obliczeniowej do tabeli w msdb.
Więc jak to kwerendy? Załóżmy, że chcemy znaleźć wpisy, które znajdowały się w określonym zakresie dat i godzin?
Poeksperymentujmy.
Najpierw utwórzmy tabelę z 3 milionami wierszy i zindeksujmy kolumny, na których nam zależy.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Mogłem utworzyć indeks klastrowy, ale doszedłem do wniosku, że indeks nieklastrowy jest bardziej typowy dla twojego środowiska.)
Nasze dane wyglądają tak i chcę znaleźć wiersze między, powiedzmy, 2 sierpnia 2011 o 8:30 a 5 sierpnia 2011 o 21:30.
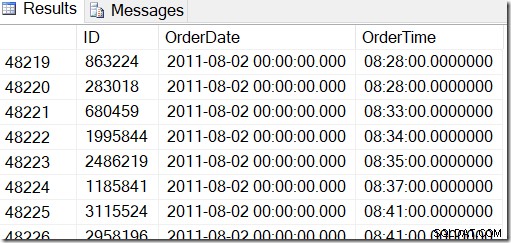
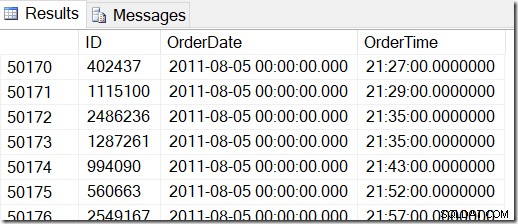
Przeglądając dane, widzę, że chcę mieć wszystkie wiersze z przedziału od 48221 do 50171. To jest 50171-48221+1=1951 wierszy (+1 oznacza, że jest to zakres włącznie). Dzięki temu mam pewność, że moje wyniki są prawidłowe. Prawdopodobnie miałbyś podobny na swoim komputerze, ale nie dokładny, ponieważ użyłem losowych wartości podczas generowania tabeli.
Wiem, że nie mogę po prostu zrobić czegoś takiego:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…ponieważ nie obejmowałoby to czegoś, co wydarzyło się z dnia na dzień 4 lutego. To daje mi 1268 wierszy – wyraźnie nie tak.
Jedną z opcji jest połączenie kolumn:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Daje to prawidłowe wyniki. To robi. Po prostu jest to całkowicie nieargable i daje nam skanowanie we wszystkich wierszach w naszej tabeli. W naszych 3 milionach wierszy uruchomienie tego może zająć kilka sekund.
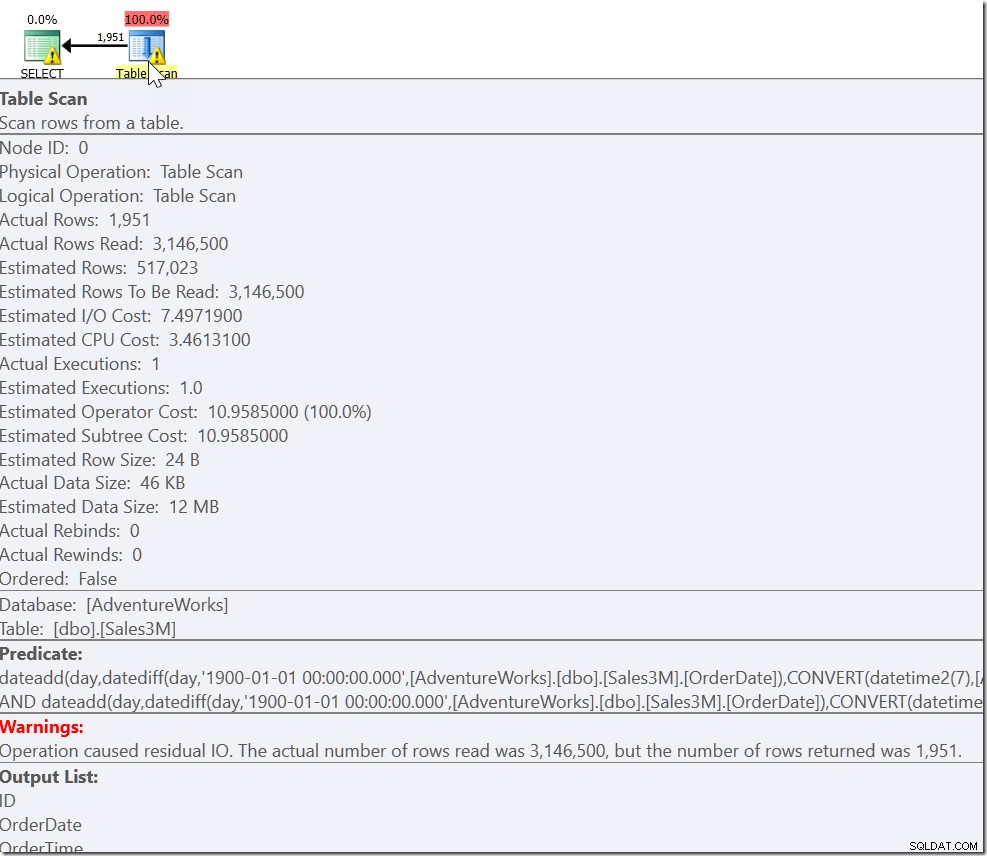
Naszym problemem jest to, że mamy zwykły przypadek i dwa przypadki specjalne. Wiemy, że każdy wiersz, który spełnia OrderDate> „20110802” ORAZ OrderDate <„20110805” jest tym, który chcemy. Ale potrzebujemy również każdego wiersza, który przypada 8:30 w dniu 20110802 lub po 8:30 oraz w dniu lub przed 21:30 w dniu 20110805. A to prowadzi nas do:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
Wiem, że OR jest okropne. Może również prowadzić do Skanów, choć niekoniecznie. Tutaj widzę trzy wyszukiwania indeksu, które są łączone, a następnie sprawdzane pod kątem unikalności. Optymalizator zapytań zdaje sobie oczywiście sprawę, że nie powinien zwracać tego samego wiersza dwa razy, ale nie zdaje sobie sprawy, że te trzy warunki wzajemnie się wykluczają. I właściwie, jeśli robisz to w zakresie w ciągu jednego dnia, otrzymasz złe wyniki.
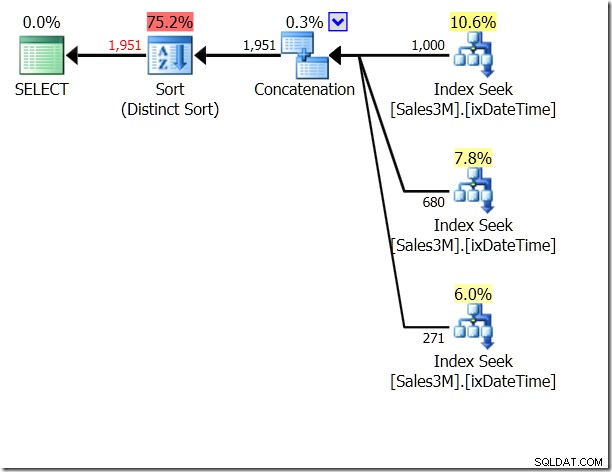
Moglibyśmy użyć w tym celu UNION ALL, co oznaczałoby, że QO nie dbałoby o to, czy warunki wzajemnie się wykluczają. To daje nam trzy Seeki, które są połączone – to całkiem nieźle.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Ale to wciąż trzy próby. Statystyki IO mówią mi, że na moim komputerze jest 20 odczytów.

Teraz, kiedy myślę o sargability, nie myślę tylko o unikaniu umieszczania kolumn indeksów wewnątrz wyrażeń, myślę również o tym, co może pomóc coś wydawać się sargowalny.
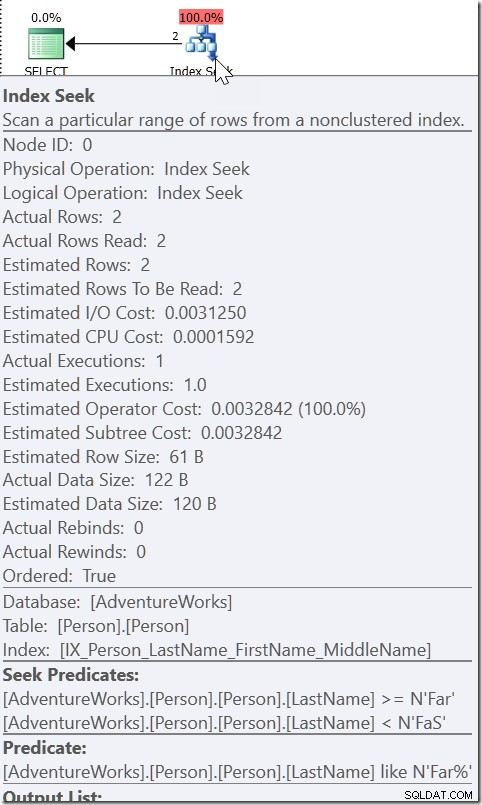
Weźmy na przykład WHERE LastName LIKE 'Far%'. Kiedy patrzę na plan na to, widzę Seek, z Predykatem Seek szukającym dowolnej nazwy od Dalekiego do (ale nie włączając) FaS. A potem jest predykat rezydualny sprawdzający warunek LIKE. Nie dzieje się tak dlatego, że QO uważa, że LIKE jest sargable. Gdyby tak było, mógłby użyć LIKE w predykacie Seek. To dlatego, że wie, że wszystko, co jest spełnione przez ten warunek LIKE, musi mieścić się w tym zakresie.
Weź WHERE CAST (Data zamówienia jako data) =„20110805”
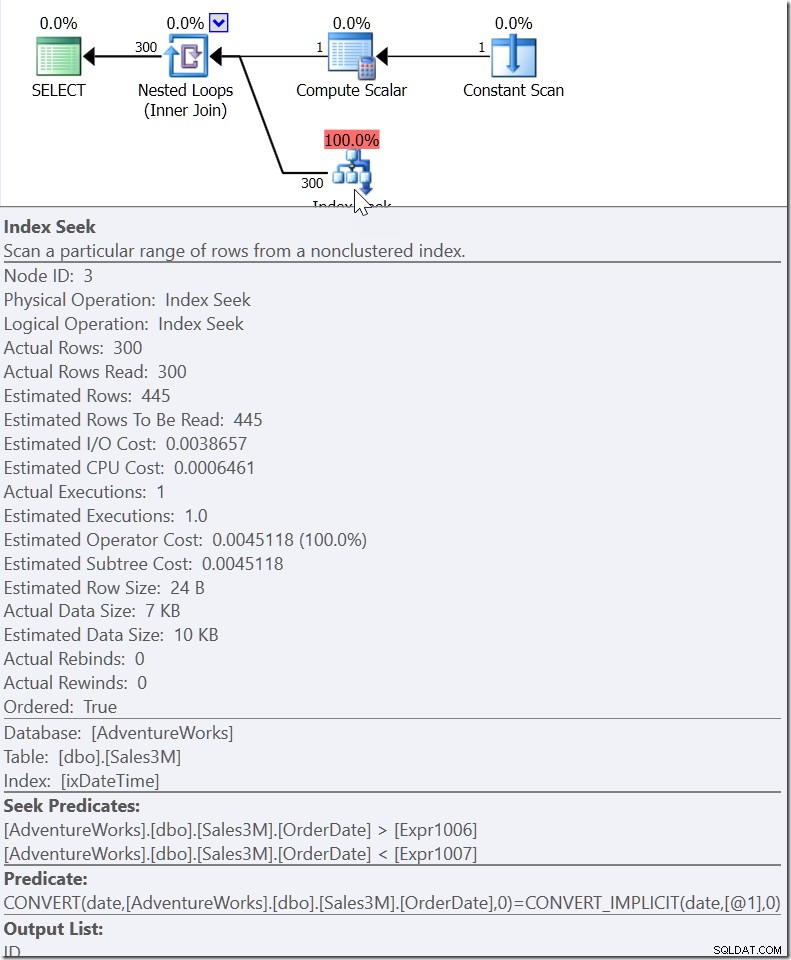
Tutaj widzimy Predykat Seek, który szuka wartości OrderDate między dwiema wartościami, które zostały opracowane w innym miejscu planu, ale tworzy zakres, w którym muszą istnieć właściwe wartości. To nie jest>=20110805 00:00 i <20110806 00:00 (tak bym to zrobił), to coś innego. Wartość początku tego zakresu musi być mniejsza niż 20110805 00:00, ponieważ jest to>, a nie>=. Wszystko, co możemy naprawdę powiedzieć, to to, że kiedy ktoś w Microsoft wdrożył sposób, w jaki QO powinien reagować na tego rodzaju predykat, podał mu wystarczającą ilość informacji, aby wymyślić coś, co nazywam „predykatem pomocniczym”.
Teraz chciałbym, aby Microsoft udostępnił więcej funkcji, ale to konkretne żądanie zostało zamknięte na długo przed wycofaniem Connect.
Ale może chodzi mi o to, żeby tworzyli więcej predykatów pomocniczych.
Problem z predykatami pomocniczymi polega na tym, że prawie na pewno czytają one więcej wierszy, niż chcesz. Ale i tak jest to o wiele lepsze niż przeglądanie całego indeksu.
Wiem, że wszystkie wiersze, które chcę zwrócić, będą miały datę zamówienia od 20110802 do 20110805. Po prostu są takie, których nie chcę.
Mógłbym je po prostu usunąć i byłoby to ważne:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
Ale wydaje mi się, że jest to rozwiązanie, które wymaga pewnego wysiłku myślenia. Mniej wysiłku ze strony programistów polega po prostu na zapewnieniu predykatu pomocniczego dla naszej poprawnej, ale wolnej wersji.
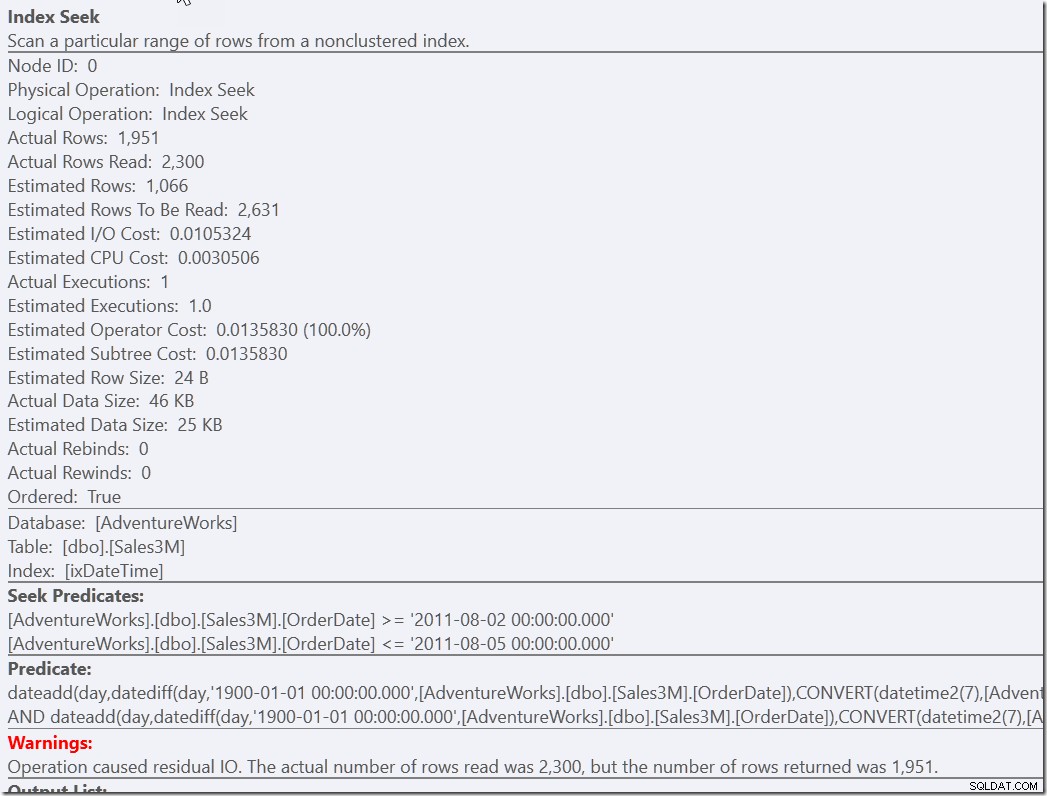
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Oba te zapytania znajdują 2300 wierszy we właściwych dniach, a następnie muszą sprawdzić wszystkie te wiersze z innymi predykatami. Jeden musi sprawdzić dwa warunki NIE, drugi musi wykonać konwersję typów i matematykę. Ale oba są znacznie szybsze niż to, co mieliśmy wcześniej, i wykonują jedną Seek (13 odczytów). Jasne, otrzymuję ostrzeżenia o nieefektywnym RangeScan, ale to moja preferencja w stosunku do trzech wydajnych.
W pewnym sensie największym problemem w tym ostatnim przykładzie jest to, że osoba mająca dobre intencje zobaczy, że predykat pomocniczy jest zbędny i może go usunąć. Tak jest w przypadku wszystkich predykatów pomocniczych. Więc wstaw komentarz.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Jeśli masz coś, co nie pasuje do ładnego sargable predykatu, wypracuj taki, a następnie zastanów się, co musisz z niego wykluczyć. Możesz po prostu wymyślić lepsze rozwiązanie.
@rob_farley