Ten blog jest drugą częścią artykułu Implementacja konfiguracji wielu centrów danych dla PostgreSQL. W tym ciosie pokażemy, jak wdrożyć PostgreSQL w tego typu środowisku i jak przełączać się awaryjnie w przypadku awarii głównej za pomocą funkcji automatycznego odzyskiwania ClusterControl.
W tym momencie założymy, że masz łączność między centrami danych (jak widzieliśmy w pierwszej części tego bloga) i masz serwery niezbędne do tego zadania (jak wspomnieliśmy również w poprzednia część).
Wdróż klaster PostgreSQL
Wykorzystamy ClusterControl do tego zadania, więc założymy, że masz go zainstalowany (może być zainstalowany na tym samym serwerze Load Balancer, ale jeśli możesz użyć innego, jeszcze lepiej).
/P>
Przejdź do serwera ClusterControl i wybierz opcję „Wdróż”. Jeśli masz już uruchomioną instancję PostgreSQL, musisz zamiast tego wybrać opcję „Importuj istniejący serwer/bazę danych”.
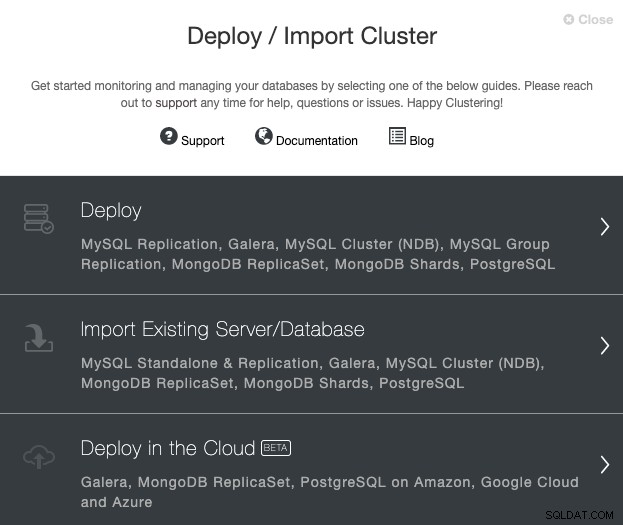
Wybierając PostgreSQL, musisz określić Użytkownika, Klucz lub Hasło i port do połącz się przez SSH z naszymi hostami PostgreSQL. Potrzebna jest również nazwa nowego klastra i jeśli chcesz, aby ClusterControl zainstalował dla Ciebie odpowiednie oprogramowanie i konfiguracje.
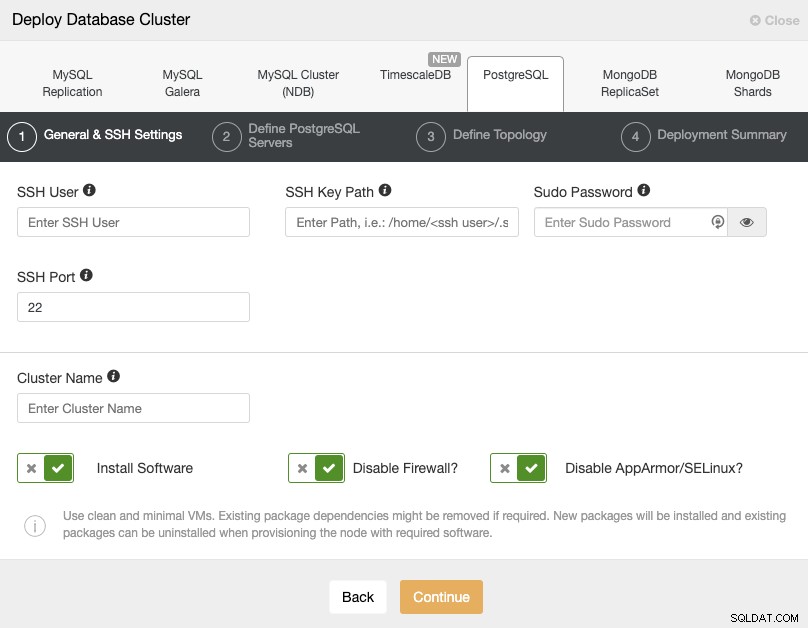
Sprawdź tutaj wymagania użytkownika ClusterControl dla tego zadania, ale jeśli wykonałeś W poprzednim blogu powinieneś użyć tutaj „zdalnego” użytkownika i prawidłowego portu SSH (jak wspomnieliśmy, zaleca się użycie innego, jeśli korzystasz z publicznego adresu IP, aby uzyskać do niego dostęp zamiast VPN).
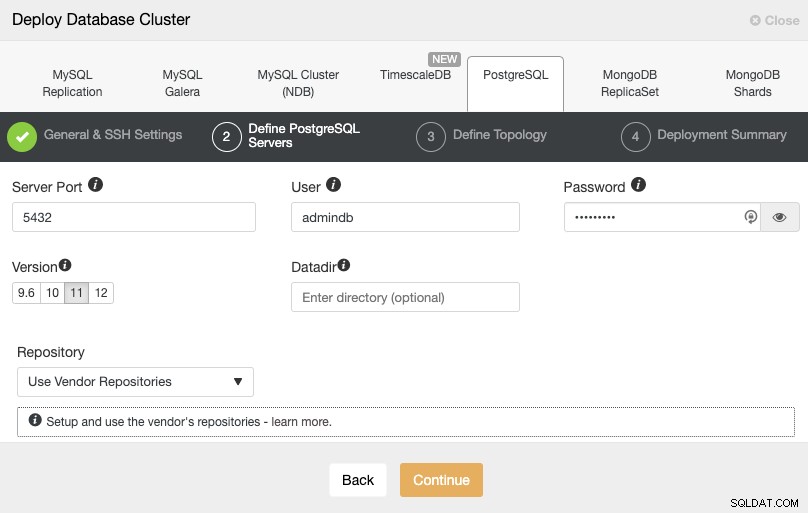
Po skonfigurowaniu informacji dostępowych SSH należy zdefiniować użytkownika bazy danych, wersja i katalog danych (opcjonalnie). Możesz również określić, którego repozytorium chcesz użyć. W następnym kroku musisz dodać swoje serwery do klastra, który zamierzasz utworzyć.
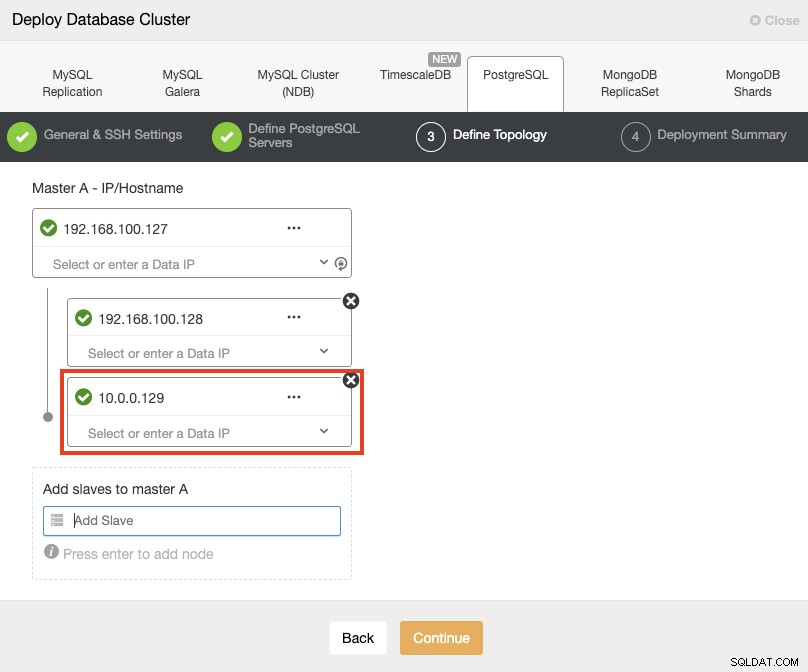
Podczas dodawania serwerów możesz podać adres IP lub nazwę hosta. W tej części użyjesz publicznych adresów IP swoich serwerów, a jak widać w czerwonym polu, używam innej sieci dla drugiego węzła gotowości. ClusterControl nie ma żadnych ograniczeń dotyczących używanej sieci. Jedynym wymaganiem jest posiadanie dostępu SSH do węzła.
Więc podążając za naszym poprzednim przykładem, te adresy IP powinny wyglądać następująco:
Primary Node: 35.166.37.12
Standby 1 Node: 35.166.37.13
Standby 2 Node: 18.197.23.14 (red box)W ostatnim kroku możesz wybrać, czy twoja replikacja będzie synchroniczna czy asynchroniczna.
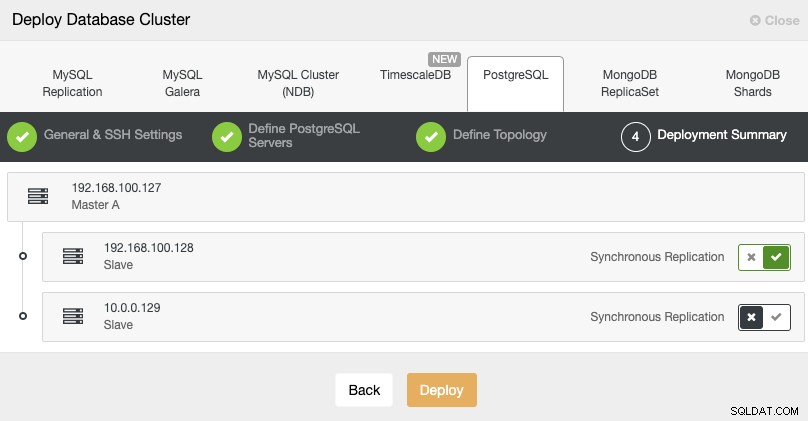
W takim przypadku ważne jest, aby użyć replikacji asynchronicznej dla zdalnego węzła , jeśli nie, na klaster mogą mieć wpływ opóźnienia lub problemy z siecią.
Możesz monitorować stan tworzenia nowego klastra za pomocą monitora aktywności ClusterControl.
Po zakończeniu zadania możesz zobaczyć swój nowy klaster PostgreSQL w główny ekran ClusterControl.

Dodawanie równoważnika obciążenia PostgreSQL (HAProxy)
Po utworzeniu klastra możesz wykonać na nim kilka zadań, takich jak dodanie systemu równoważenia obciążenia (HAProxy) lub nowej repliki.
Idąc za naszym poprzednim przykładem, dodajmy load balancer, który, jak wspomnieliśmy, pomoże Ci zarządzać środowiskiem HA. W tym celu przejdź do ClusterControl -> Wybierz Klaster PostgreSQL -> Akcje klastra -> Dodaj Load Balancer.
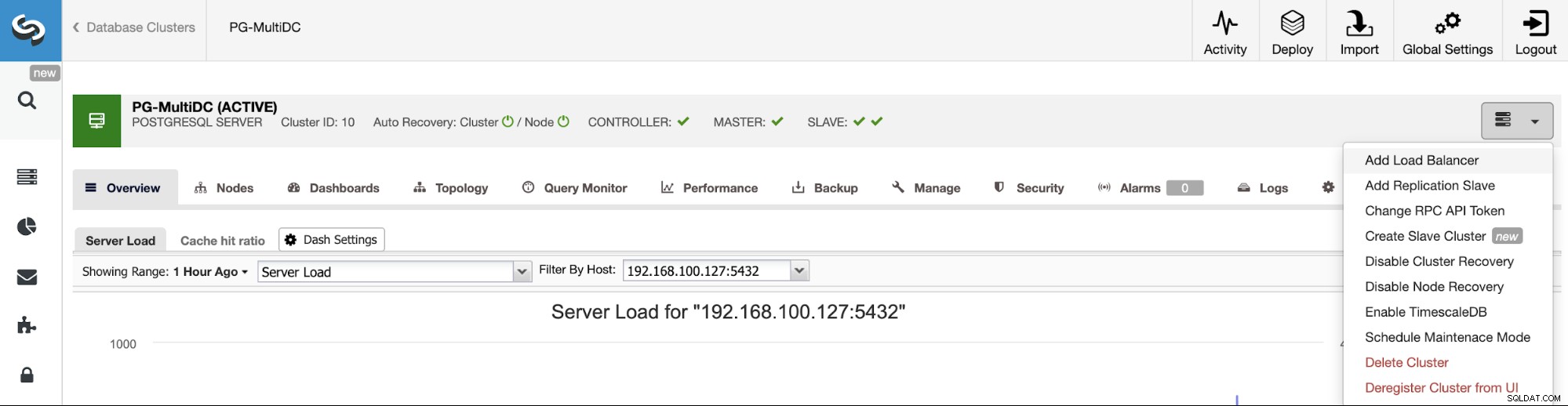
Tutaj należy dodać informacje, których ClusterControl będzie używać do instalacji i konfiguracji System równoważenia obciążenia HAProxy. Ten Load Balancer można zainstalować na tym samym serwerze ClusterControl, ale jeśli możesz użyć innego, to jeszcze lepiej.
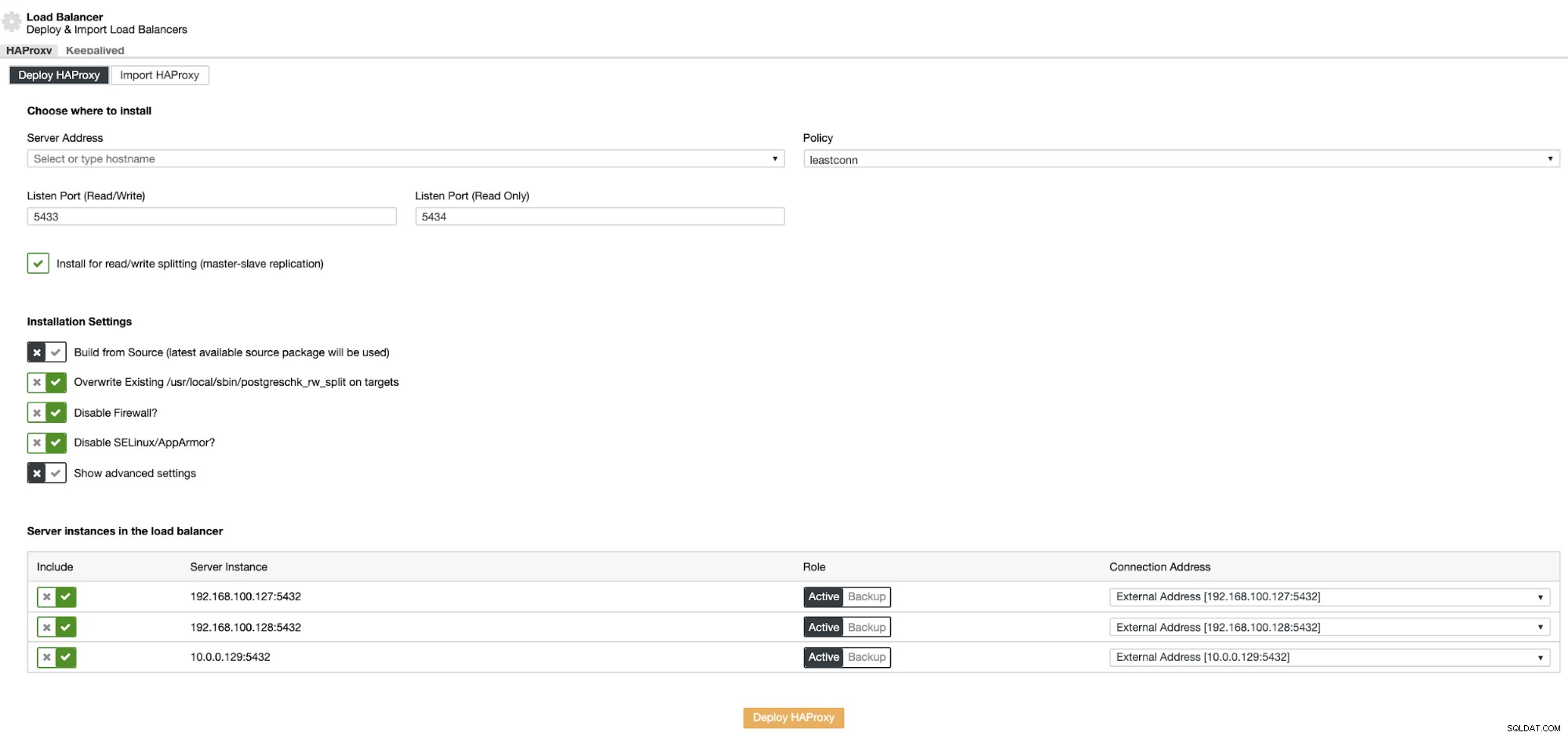
Informacje, które należy wprowadzić to:
Czynność:Wdróż lub zaimportuj.
Adres serwera:Adres IP serwera HAProxy (może to być ten sam adres IP ClusterControl).
Port nasłuchiwania (odczyt/zapis):port dla trybu odczytu/zapisu.
Port nasłuchiwania (tylko do odczytu):port w trybie tylko do odczytu.
Zasady:Może to być:
- leastconn:serwer z najmniejszą liczbą połączeń odbiera połączenie.
- roundrobin:każdy serwer jest używany na zmianę, zgodnie z ich wagą.
- źródło:źródłowy adres IP jest haszowany i dzielony przez całkowitą wagę działających serwerów w celu wyznaczenia, który serwer otrzyma żądanie.
Zainstaluj do dzielenia odczytu/zapisu:Do replikacji master-slave.
Buduj ze źródła:możesz wybrać opcję Zainstaluj z menedżera pakietów lub kompiluj ze źródła.
I musisz wybrać serwery, które chcesz dodać do konfiguracji HAProxy.
Możesz także skonfigurować ustawienia zaawansowane, takie jak użytkownik administratora, nazwa zaplecza, limity czasu i inne.
Po zakończeniu konfiguracji i potwierdzeniu wdrożenia możesz śledzić postęp w sekcji Aktywność w interfejsie ClusterControl.
A kiedy to się skończy, możesz przejść do ClusterControl -> Nodes -> HAProxy i sprawdź aktualny stan.
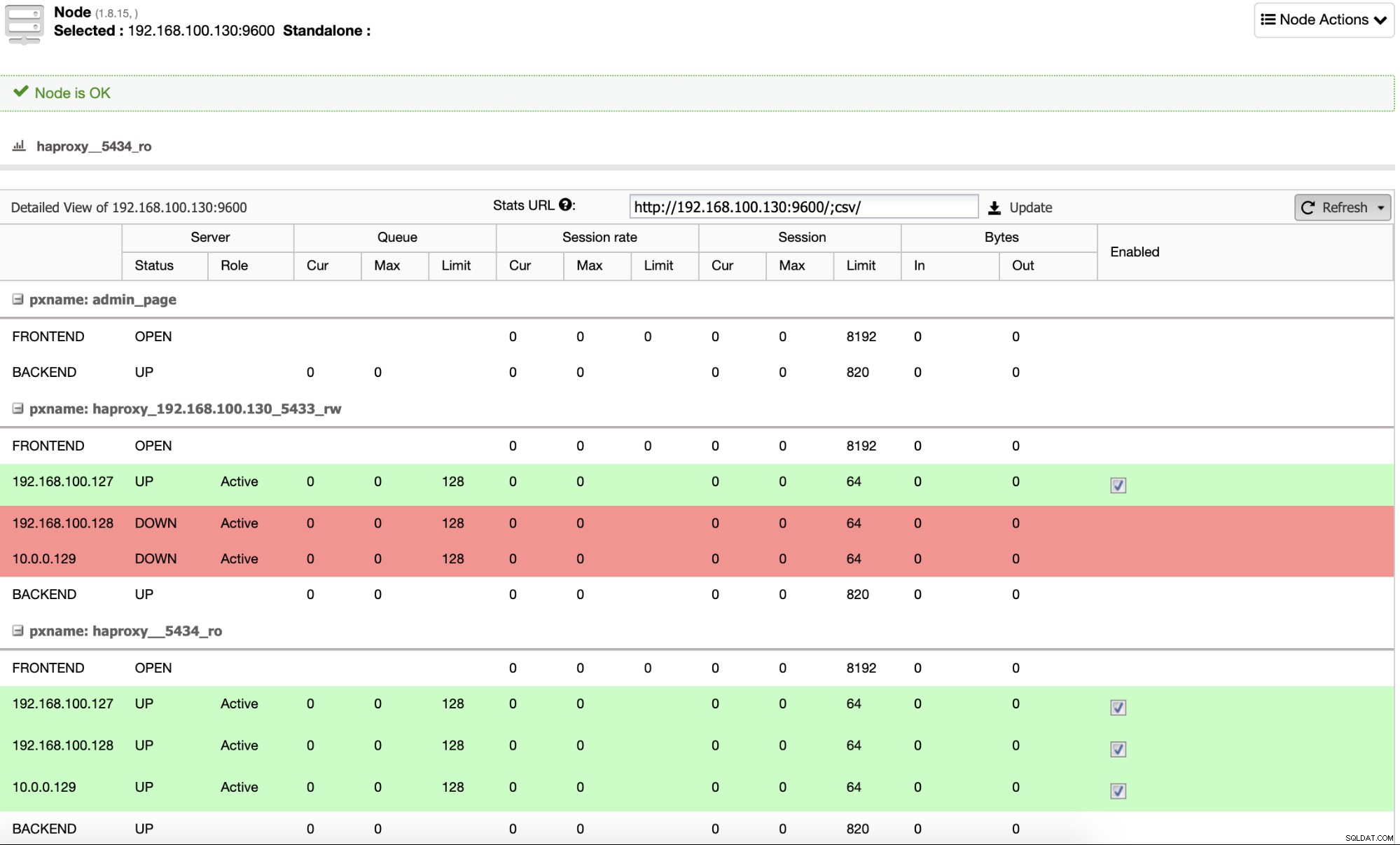
Domyślnie ClusterControl konfiguruje HAProxy z dwoma różnymi portami, jeden do odczytu Write, który będzie używany przez aplikację lub użytkownika do zapisu (i odczytu) danych, a drugi dla Read-Only, który będzie używany do równoważenia ruchu odczytu między wszystkimi węzłami. W porcie do odczytu-zapisu włączony jest tylko węzeł nadrzędny, aw przypadku awarii urządzenia nadrzędnego, ClusterControl promuje najbardziej zaawansowane urządzenie podrzędne do nadrzędnego i rekonfiguruje ten port, aby wyłączyć stary nadrzędny i włączyć nowy. W ten sposób Twoja aplikacja może nadal działać w przypadku awarii głównej bazy danych, ponieważ ruch jest przekierowywany przez Load Balancer do właściwego węzła.
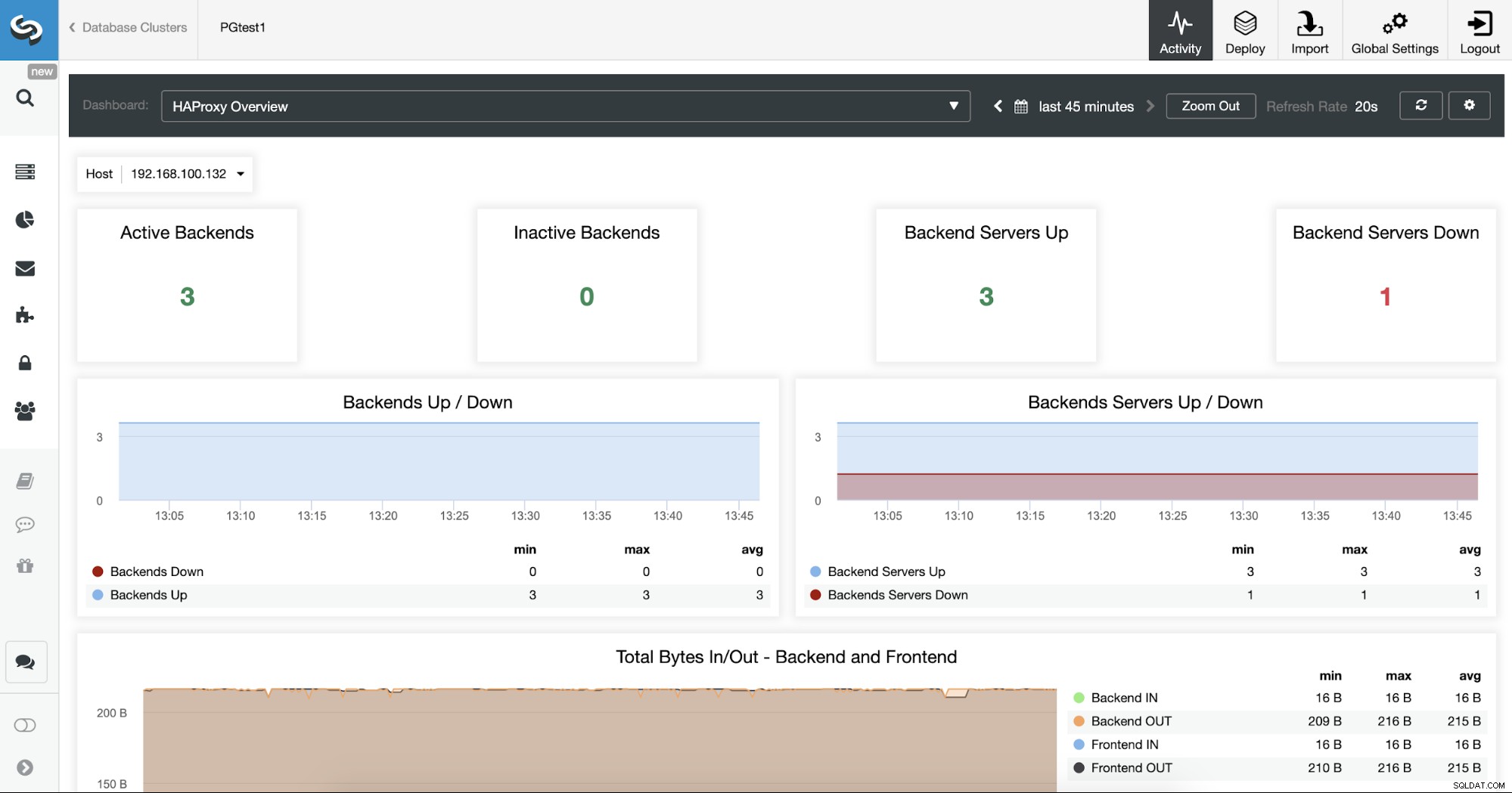
Możesz także monitorować swoje serwery HAProxy, sprawdzając sekcję Dashboard.
Teraz możesz ulepszyć swój projekt HA, dodając nowy węzeł HAProxy w zdalne centrum danych i konfigurowanie usługi Keepalived między nimi. Keepalived pozwoli Ci na użycie wirtualnego adresu IP, który jest przypisany do aktywnego węzła Load Balancer. Jeśli ten węzeł ulegnie awarii, ten wirtualny adres IP zostanie zmigrowany do pomocniczego węzła HAProxy, więc skonfigurowanie tego adresu IP w aplikacji pozwoli Ci zachować wszystko, co działa w przypadku problemu z Load Balancer.
Cała ta konfiguracja może być wykonana za pomocą ClusterControl.
Wnioski
Podążając za tym dwuczęściowym blogiem, możesz zaimplementować konfigurację wielu centrów danych dla PostgreSQL z wysoką dostępnością i łącznością SSH między centrum danych, aby uniknąć złożoności konfiguracji VPN.
Korzystając z replikacji asynchronicznej dla zdalnego węzła, unikniesz wszelkich problemów związanych z opóźnieniami i wydajnością sieci, a korzystając z ClusterControl, będziesz mieć automatyczne (lub ręczne) przełączanie awaryjne w przypadku awarii (między innymi kilkoma funkcjami). To może być najprostszy sposób na osiągnięcie tej topologii i mamy nadzieję, że będzie to dla Ciebie przydatne.