Przestrzeń dyskowa jest obecnie wymagającym zasobem. Zwykle będziesz chciał przechowywać dane tak długo, jak to możliwe, ale może to stanowić problem, jeśli nie podejmiesz niezbędnych działań, aby zapobiec potencjalnemu problemowi „braku miejsca na dysku”.
W tym blogu zobaczymy, jak możemy wykryć ten problem dla PostgreSQL, zapobiec mu, a jeśli będzie za późno, kilka opcji, które prawdopodobnie pomogą Ci go naprawić.
Jak zidentyfikować problemy z miejscem na dysku PostgreSQL
Jeśli niestety znajdziesz się w sytuacji braku miejsca na dysku, będziesz mógł zobaczyć błędy w logach bazy danych PostgreSQL:
2020-02-20 19:18:18.131 UTC [4400] LOG: could not close temporary statistics file "pg_stat_tmp/global.tmp": No space left on devicelub nawet w dzienniku systemowym:
Feb 20 19:29:26 blog-pg1 rsyslogd: imjournal: fclose() failed for path: '/var/lib/rsyslog/imjournal.state.tmp': No space left on device [v8.24.0-41.el7_7.2 try https://www.rsyslog.com/e/2027 ]PostgreSQL może przez jakiś czas kontynuować pracę, uruchamiając zapytania tylko do odczytu, ale ostatecznie nie powiedzie się próba zapisu na dysku, wtedy zobaczysz coś takiego w sesji klienta:
WARNING: terminating connection because of crash of another server process
DETAIL: The postmaster has commanded this server process to roll back the current transaction and exit, because another server process exited abnormally and possibly corrupted shared memory.
HINT: In a moment you should be able to reconnect to the database and repeat your command.
server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
The connection to the server was lost. Attempting reset: Failed.W takim razie, jeśli spojrzysz na miejsce na dysku, otrzymasz niechciane wyjście…
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/pve-vm--125--disk--0 30G 30G 0 100% /Jak zapobiegać problemom z miejscem na dysku PostgreSQL
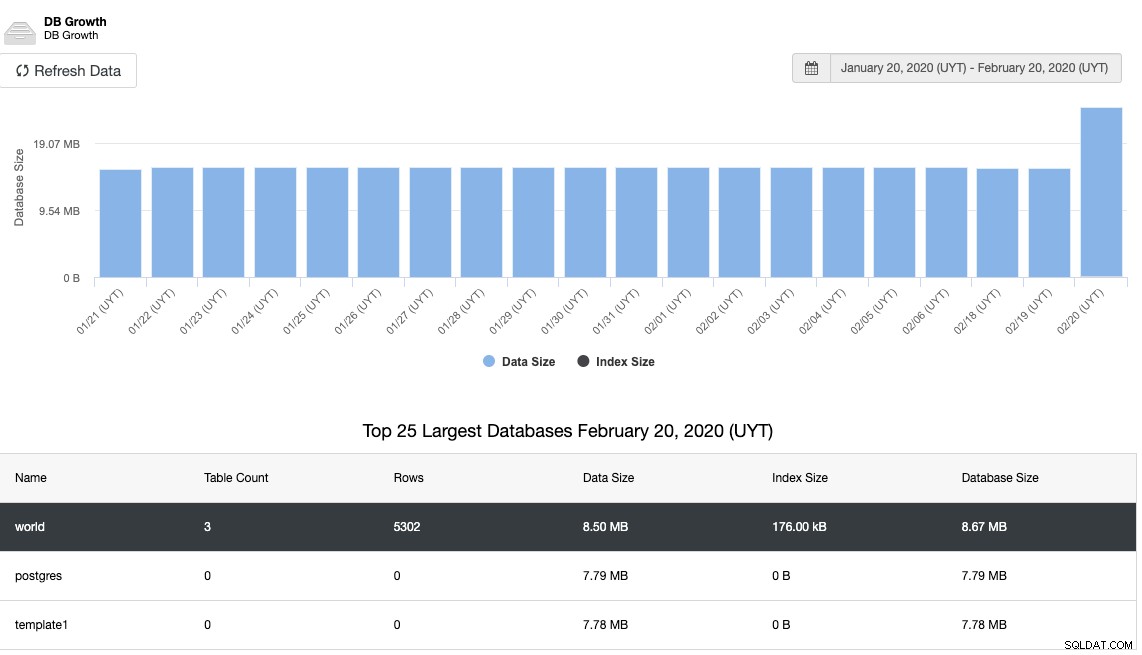
Głównym sposobem zapobiegania tego rodzaju problemom jest monitorowanie wykorzystania miejsca na dysku oraz wzrostu wykorzystania bazy danych lub dysku. W tym celu wykres powinien być przyjaznym sposobem monitorowania przyrostu miejsca na dysku:

I to samo w przypadku wzrostu bazy danych:
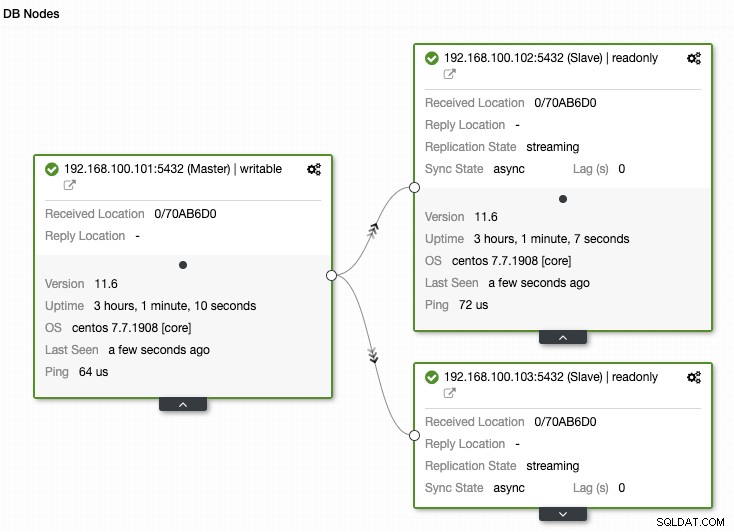
Kolejną ważną rzeczą do monitorowania jest stan replikacji. Jeśli masz replikę i z jakiegoś powodu przestaje ona działać, w zależności od konfiguracji, możliwe jest, że PostgreSQL przechowuje wszystkie pliki WAL, aby przywrócić replikę po jej powrocie.
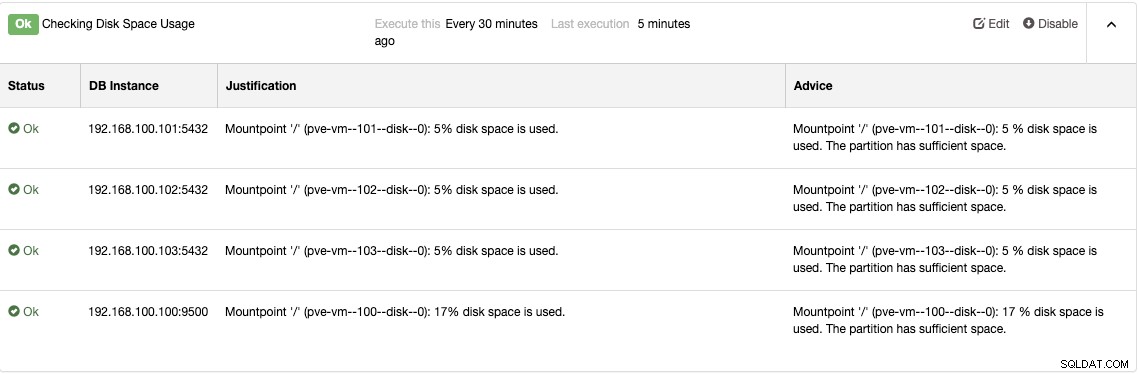
Cały ten system monitorowania nie ma sensu bez systemu ostrzegania kiedy musisz podjąć działania:
Jak naprawić problemy z miejscem na dysku PostgreSQL
Cóż, jeśli masz do czynienia z problemem braku miejsca na dysku, nawet z zaimplementowanym (lub nie) systemem monitorowania i ostrzegania, istnieje wiele opcji, aby spróbować rozwiązać ten problem bez utraty danych (lub mniej jak to możliwe).
Co zużywa miejsce na dysku?
Pierwszym krokiem powinno być określenie, gdzie jest moje miejsce na dysku. Najlepszą praktyką jest posiadanie oddzielnych partycji, co najmniej jednej oddzielnej partycji do przechowywania bazy danych, dzięki czemu można łatwo sprawdzić, czy baza danych lub system zużywa zbyt dużo miejsca na dysku. Kolejną zaletą tego jest zminimalizowanie uszkodzeń. Jeśli twoja partycja główna jest pełna, twoja baza danych może nadal bez problemów pisać na swojej własnej partycji.
Wykorzystanie przestrzeni w bazie danych
Zobaczmy teraz kilka przydatnych poleceń, aby sprawdzić wykorzystanie miejsca na dysku bazy danych.
Podstawowym sposobem sprawdzenia wykorzystania miejsca w bazie danych jest sprawdzenie katalogu danych w systemie plików:
$ du -sh /var/lib/pgsql/11/data/
819M /var/lib/pgsql/11/data/Lub, jeśli masz oddzielną partycję dla swojego katalogu danych, możesz bezpośrednio użyć df -h.
Polecenie PostgreSQL „\l+” wyświetla bazy danych dodając informacje o rozmiarze:
$ postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace
| Description
-----------+----------+-----------+---------+-------+-----------------------+---------+------------
+--------------------------------------------
postgres | postgres | SQL_ASCII | C | C | | 7965 kB | pg_default
| default administrative connection database
template0 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| unmodifiable empty database
| | | | | postgres=CTc/postgres | |
|
template1 | postgres | SQL_ASCII | C | C | =c/postgres +| 7817 kB | pg_default
| default template for new databases
| | | | | postgres=CTc/postgres | |
|
world | postgres | SQL_ASCII | C | C | | 8629 kB | pg_default
|
(4 rows)Używając pg_database_size i nazwy bazy danych możesz zobaczyć rozmiar bazy danych:
postgres=# SELECT pg_database_size('world');
pg_database_size
------------------
8835743
(1 row)A użycie pg_size_pretty, aby zobaczyć tę wartość w sposób czytelny dla człowieka, mogłoby być jeszcze lepsze:
postgres=# SELECT pg_size_pretty(pg_database_size('world'));
pg_size_pretty
----------------
8629 kB
(1 row)Kiedy wiesz, gdzie jest miejsce, możesz podjąć odpowiednią akcję, aby to naprawić. Pamiętaj, że samo usunięcie wierszy nie wystarczy do odzyskania miejsca na dysku, będziesz musiał uruchomić PRÓŻNIĘ lub PRÓŻNIĘ PEŁNĄ, aby zakończyć zadanie.
Pliki dziennika
Najłatwiejszym sposobem odzyskania miejsca na dysku jest usunięcie plików dziennika. Możesz sprawdzić katalog dzienników PostgreSQL, a nawet dzienniki systemowe, aby sprawdzić, czy możesz stamtąd zdobyć trochę miejsca. Jeśli masz coś takiego:
$ du -sh /var/lib/pgsql/11/data/log/
18G /var/lib/pgsql/11/data/log/Powinieneś sprawdzić zawartość katalogu, aby zobaczyć, czy występuje problem z rotacją/przechowywaniem dziennika lub coś się dzieje w Twojej bazie danych i zapisuje to w dziennikach.
$ ls -lah /var/lib/pgsql/11/data/log/
total 18G
drwx------ 2 postgres postgres 4.0K Feb 21 00:00 .
drwx------ 21 postgres postgres 4.0K Feb 21 00:00 ..
-rw------- 1 postgres postgres 18G Feb 21 14:46 postgresql-Fri.log
-rw------- 1 postgres postgres 9.3K Feb 20 22:52 postgresql-Thu.log
-rw------- 1 postgres postgres 3.3K Feb 19 22:36 postgresql-Wed.logPrzed usunięciem dzienników, jeśli masz duży, dobrą praktyką jest zachowanie ostatnich 100 wierszy, a następnie ich usunięcie. Możesz więc sprawdzić, co się dzieje po wygenerowaniu wolnego miejsca.
$ tail -100 postgresql-Fri.log > /tmp/log_temp.logA potem:
$ cat /dev/null > /var/lib/pgsql/11/data/log/postgresql-Fri.logJeśli po prostu usuniesz go za pomocą „rm”, a plik dziennika jest używany przez serwer PostgreSQL (lub inną usługę), przestrzeń nie zostanie zwolniona, więc powinieneś skrócić ten plik za pomocą tego cat / Zamiast tego polecenie dev/null.
Ta akcja dotyczy tylko plików PostgreSQL i logów systemowych. Nie usuwaj zawartości pg_wal ani innego pliku PostgreSQL, ponieważ może to spowodować krytyczne uszkodzenie bazy danych.
Wzdęcie
W normalnej operacji PostgreSQL krotki usunięte lub przestarzałe przez aktualizację nie są fizycznie usuwane z tabeli; są obecne do momentu wykonania PRÓŻNI. Dlatego konieczne jest okresowe odkurzanie (AUTOVACUUM), zwłaszcza w często aktualizowanych tabelach.
Problem polega na tym, że przestrzeń nie jest zwracana do systemu operacyjnego przy użyciu tylko PRÓŻNI, jest dostępna tylko do użytku w tej samej tabeli.
VACUUM FULL przepisuje tabelę do nowego pliku dyskowego, zwracając nieużywaną przestrzeń do systemu operacyjnego. Niestety wymaga wyłącznej blokady na każdym stole podczas działania.
Powinieneś sprawdzić tabele, aby zobaczyć, czy wymagany jest proces PRÓŻNIOWY (PEŁNY).
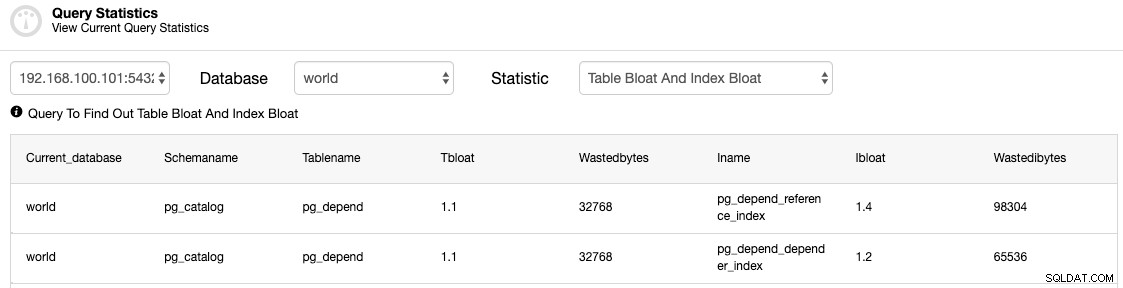
Gniazda replikacji
Jeśli używasz gniazd replikacji, które z jakiegoś powodu nie są aktywne:
postgres=# SELECT slot_name, slot_type, active FROM pg_replication_slots;
slot_name | slot_type | active
-----------+-----------+--------
slot1 | physical | f
(1 row)Może to być problem z miejscem na dysku, ponieważ będzie on przechowywać pliki WAL, dopóki nie zostaną odebrane przez wszystkie węzły rezerwowe.
Sposób na naprawę to odzyskanie repliki (jeśli to możliwe) lub usunięcie slotu:
postgres=# SELECT pg_drop_replication_slot('slot1');
pg_drop_replication_slot
--------------------------
(1 row)Więc miejsce używane przez pliki WAL zostanie zwolnione.
Wnioski
Jak wspomnieliśmy, systemy monitorowania i ostrzegania są kluczem do uniknięcia tego rodzaju problemów. W ten sposób ClusterControl może pomóc w uruchomieniu i uruchomieniu systemów, wysyłając alarmy w razie potrzeby, a nawet podejmując działania naprawcze, aby utrzymać działanie klastra bazy danych. Możesz także wdrożyć/importować różne technologie baz danych i w razie potrzeby skalować je.