Odczytywanie z pamięci zawsze będzie wydajniejsze niż korzystanie z dysku, więc w przypadku wszystkich technologii baz danych chciałbyś używać jak największej ilości pamięci. Jeśli nie masz pewności co do konfiguracji lub wystąpił błąd, może to generować wysokie wykorzystanie pamięci, a nawet problem z brakiem pamięci.
W tym blogu przyjrzymy się, jak sprawdzić wykorzystanie pamięci PostgreSQL i jaki parametr należy wziąć pod uwagę, aby ją dostroić. W tym celu zacznijmy od przeglądu architektury PostgreSQL.
Architektura PostgreSQL
Architektura PostgreSQL opiera się na trzech podstawowych częściach:Procesach, pamięci i dysku.
Pamięć można podzielić na dwie kategorie:
- Pamięć lokalna :Jest ładowany przez każdy proces backendu na własny użytek do przetwarzania zapytań. Jest podzielony na podobszary:
- Pamięć robocza:Pamięć robocza służy do sortowania krotek według operacji ORDER BY i DISTINCT oraz do łączenia tabel.
- Prace konserwacyjne mem:Niektóre rodzaje operacji konserwacyjnych wykorzystują ten obszar. Na przykład VACUUM, jeśli nie określasz autovacuum_work_mem.
- Bufory tymczasowe:Służy do przechowywania tabel tymczasowych.
- Pamięć współdzielona :Jest przydzielany przez serwer PostgreSQL po uruchomieniu i jest używany przez wszystkie procesy. Jest podzielony na podobszary:
- Wspólna pula buforów:gdzie PostgreSQL ładuje strony z tabelami i indeksami z dysku, aby pracować bezpośrednio z pamięci, zmniejszając dostęp do dysku.
- Bufor WAL:Dane WAL są dziennikiem transakcji w PostgreSQL i zawierają zmiany w bazie danych. Bufor WAL to obszar, w którym dane WAL są tymczasowo przechowywane przed zapisaniem ich na dysku w plikach WAL. Odbywa się to co pewien określony czas zwany punktem kontrolnym. Jest to bardzo ważne, aby uniknąć utraty informacji w przypadku awarii serwera.
- Dziennik zatwierdzenia:Zapisuje stan wszystkich transakcji w celu kontroli współbieżności.
Jak wiedzieć, co się dzieje
Jeśli masz wysokie wykorzystanie pamięci, najpierw powinieneś potwierdzić, który proces generuje zużycie.
Korzystanie z „najlepszego” polecenia systemu Linux
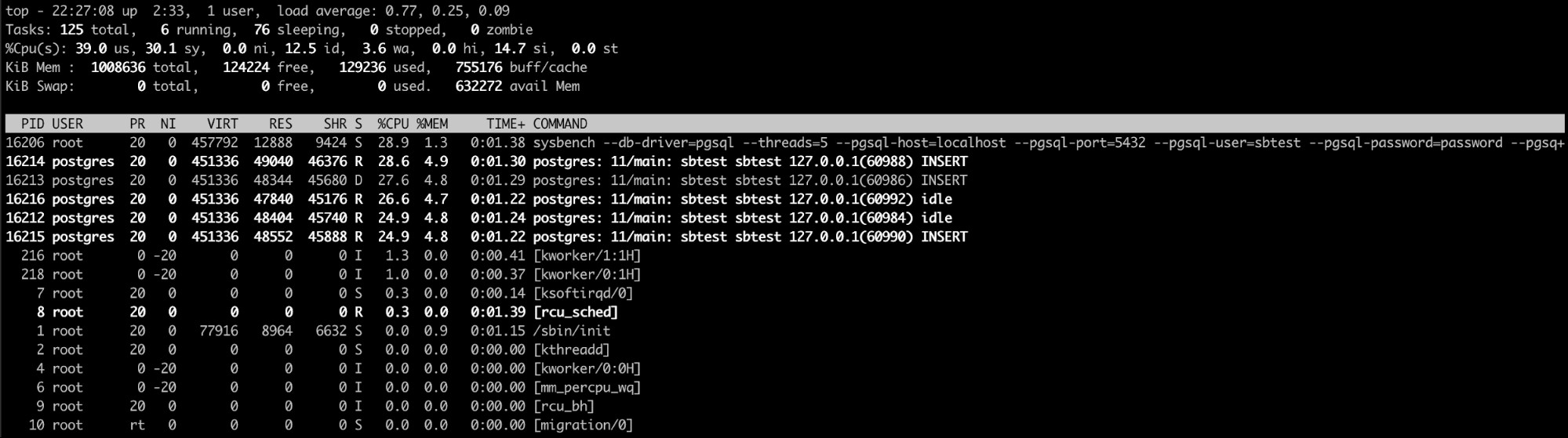
Najlepsze polecenie linuksowe jest tutaj prawdopodobnie najlepszą opcją (lub nawet podobną taki jak htop). Za pomocą tego polecenia możesz zobaczyć proces/procesy, które zużywają zbyt dużo pamięci.
Gdy potwierdzisz, że PostgreSQL jest odpowiedzialny za ten problem, następnym krokiem jest sprawdzenie, dlaczego.
Korzystanie z dziennika PostgreSQL
Sprawdzanie logów PostgreSQL i systemowych to zdecydowanie dobry sposób na uzyskanie większej ilości informacji o tym, co dzieje się w Twojej bazie danych/systemie. Możesz zobaczyć wiadomości takie jak:
Resource temporarily unavailable
Out of memory: Kill process 1161 (postgres) score 366 or sacrifice childJeśli nie masz wystarczającej ilości wolnej pamięci.
Lub nawet wiele błędów wiadomości z bazy danych, takich jak:
FATAL: password authentication failed for user "username"
ERROR: duplicate key value violates unique constraint "sbtest21_pkey"
ERROR: deadlock detectedGdy masz nieoczekiwane zachowanie po stronie bazy danych. Dzienniki są więc przydatne do wykrywania tego rodzaju problemów, a nawet więcej. Możesz zautomatyzować to monitorowanie, analizując pliki dziennika w poszukiwaniu prac takich jak „KRYTYCZNY”, „BŁĄD” lub „Zabij”, dzięki czemu otrzymasz alert, gdy to się stanie.
Korzystanie z Pg_top
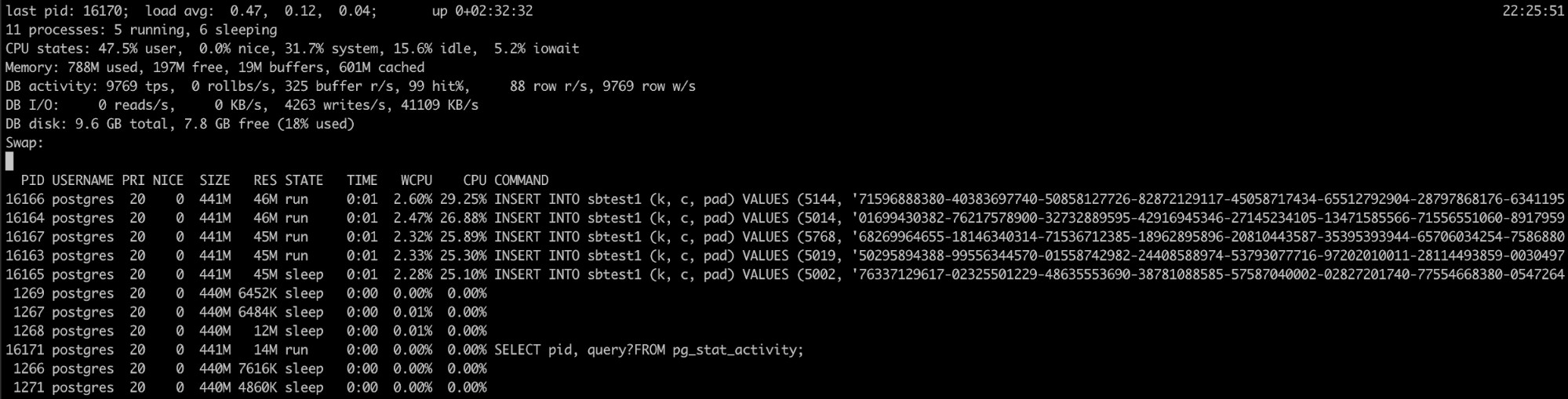
Jeśli wiesz, że proces PostgreSQL ma wysokie wykorzystanie pamięci, ale dzienniki nie pomogły, masz inne narzędzie, które może być tutaj przydatne, pg_top.
To narzędzie jest podobne do najlepszego narzędzia linuksowego, ale jest przeznaczone specjalnie dla PostgreSQL. Używając go, będziesz mieć bardziej szczegółowe informacje o tym, co działa w Twojej bazie danych, a nawet możesz zabić zapytania lub uruchomić zadanie wyjaśniania, jeśli wykryjesz coś nie tak. Więcej informacji o tym narzędziu znajdziesz tutaj.
Ale co się stanie, jeśli nie wykryjesz żadnego błędu, a baza danych nadal używa dużo pamięci RAM. Więc prawdopodobnie będziesz musiał sprawdzić konfigurację bazy danych.
Które parametry konfiguracji należy wziąć pod uwagę
Jeśli wszystko wygląda dobrze, ale nadal masz problem z wysokim wykorzystaniem, powinieneś sprawdzić konfigurację, aby upewnić się, że jest poprawna. Oto parametry, które należy wziąć pod uwagę w tym przypadku.
shared_buffers
Jest to ilość pamięci używanej przez serwer bazy danych na bufory pamięci współdzielonej. Jeśli ta wartość jest zbyt niska, baza danych zużyłaby więcej dysku, co spowodowałoby spowolnienie, ale jeśli jest zbyt wysoka, może generować wysokie wykorzystanie pamięci. Zgodnie z dokumentacją, jeśli masz dedykowany serwer bazy danych z 1 GB lub więcej pamięci RAM, rozsądna wartość początkowa dla shared_buffers to 25% pamięci w twoim systemie.
work_mem
Określa ilość pamięci, która będzie używana przez ORDER BY, DISTINCT i JOIN przed zapisaniem do plików tymczasowych na dysku. Podobnie jak w przypadku shared_buffers, jeśli skonfigurujemy ten parametr zbyt nisko, możemy mieć więcej operacji na dysku, ale zbyt wysoki jest niebezpieczny dla wykorzystania pamięci. Domyślna wartość to 4 MB.
max_connections
Work_mem również idzie w parze z wartością max_connections, ponieważ każde połączenie będzie wykonywać te operacje w tym samym czasie, a każda operacja będzie mogła wykorzystać tyle pamięci, ile jest określone przez tę wartość przed nią zaczyna zapisywać dane w plikach tymczasowych. Ten parametr określa maksymalną liczbę jednoczesnych połączeń do naszej bazy danych, jeśli skonfigurujemy dużą liczbę połączeń i nie weźmiemy tego pod uwagę, możesz zacząć mieć problemy z zasobami. Domyślna wartość to 100.
temp_buffers
Bufory tymczasowe służą do przechowywania tabel tymczasowych używanych w każdej sesji. Ten parametr określa maksymalną ilość pamięci dla tego zadania. Domyślna wartość to 8 MB.
maintenance_work_mem
Jest to maksymalna pamięć, jaką może zajmować operacja taka jak Odkurzanie, dodawanie indeksów lub kluczy obcych. Dobrą rzeczą jest to, że tylko jedna operacja tego typu może być uruchomiona w sesji i nie jest to najczęstszą rzeczą, gdy uruchamia się kilka z nich jednocześnie w systemie. Domyślna wartość to 64 MB.
autovacuum_work_mem
Odkurzacz domyślnie używa pamięci_maintenance_work_mem, ale możemy ją oddzielić za pomocą tego parametru. Tutaj możemy określić maksymalną ilość pamięci, która ma być używana przez każdego pracownika autoodkurzania.
wal_buffers
Ilość pamięci współdzielonej używanej dla danych WAL, które nie zostały jeszcze zapisane na dysku. Domyślne ustawienie to 3% shared_buffers, ale nie mniej niż 64kB ani więcej niż rozmiar jednego segmentu WAL, zwykle 16MB.
Wnioski
Istnieją różne powody wysokiego wykorzystania pamięci, a wykrycie problemu głównego może być czasochłonnym zadaniem. W tym blogu wspomnieliśmy o różnych sposobach sprawdzania wykorzystania pamięci PostgreSQL i parametrach, które należy wziąć pod uwagę, aby je dostroić, aby uniknąć nadmiernego zużycia pamięci.