Korzystanie ze środowiska multi-cloud lub multi-datacenter jest przydatne w przypadku topologii rozproszonych geograficznie, a nawet dla planu odzyskiwania po awarii, a obecnie staje się coraz bardziej popularne, dlatego koncepcja split-brain nabiera również znaczenia, ponieważ ryzyko jego wzrostu w tego rodzaju scenariuszu. Musisz zapobiec rozszczepieniu mózgu, aby uniknąć potencjalnej utraty danych lub niespójności danych, co może być dużym problemem dla firmy.
W tym blogu zobaczymy, czym jest podzielony mózg i jak ClusterControl może pomóc Ci uniknąć tego ważnego problemu.
Czym jest podzielony mózg?
W świecie PostgreSQL, split-brain występuje, gdy więcej niż jeden węzeł podstawowy jest dostępny w tym samym czasie (bez żadnego narzędzia innej firmy, aby mieć środowisko multi-master), które pozwala aplikacji na pisanie w obu węzłach. W takim przypadku będziesz mieć różne informacje na każdym węźle, co generuje niespójność danych w klastrze. Naprawienie tego problemu może być trudne, ponieważ musisz scalić dane, co czasami nie jest możliwe.
Podział mózgu PostgreSQL w topologii wielu chmur
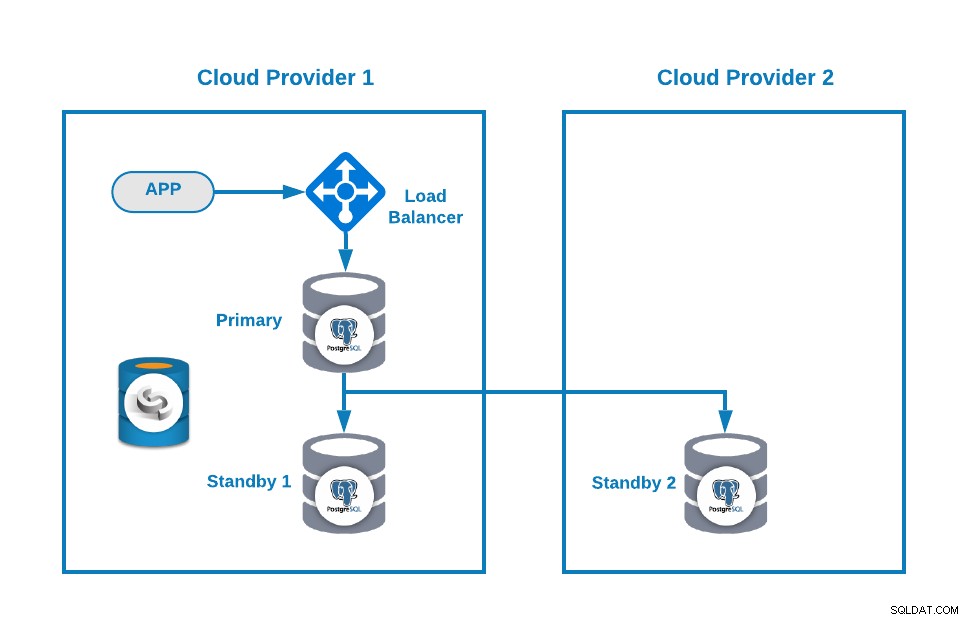
Załóżmy, że masz następującą topologię wielochmurową dla PostgreSQL (co jest obecnie dość powszechną topologią):
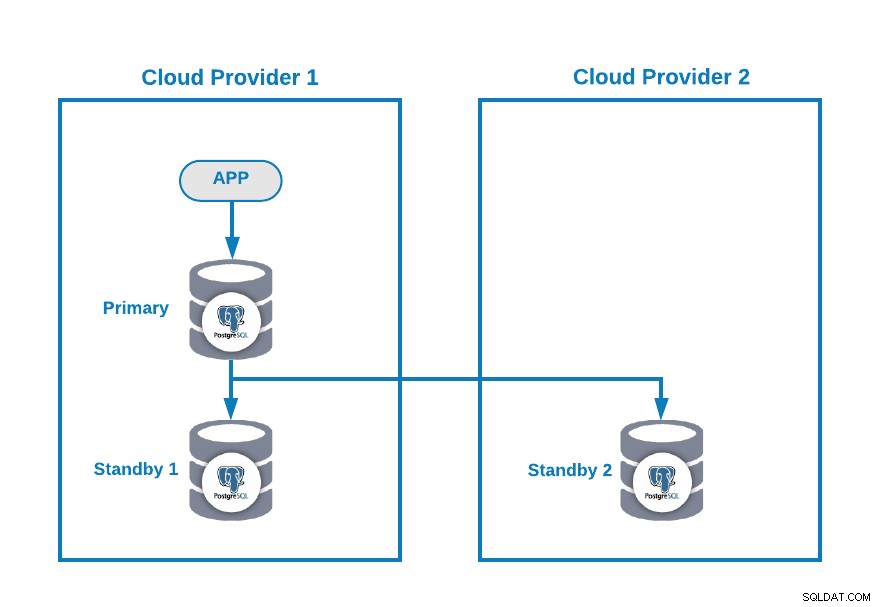
Oczywiście możesz ulepszyć to środowisko, na przykład dodając Serwer aplikacji w Cloud Provider 2, ale w tym przypadku użyjmy tej podstawowej konfiguracji.
Jeśli Twój węzeł główny nie działa, jeden z węzłów rezerwowych powinien być promowany jako nowy główny i powinieneś zmienić adres IP w swojej aplikacji, aby używać tego nowego węzła podstawowego.
Istnieją różne sposoby na zrobienie tego w sposób automatyczny. Na przykład możesz użyć wirtualnego adresu IP przypisanego do głównego węzła i monitorować go. Jeśli to się nie powiedzie, promuj jeden z węzłów rezerwowych i przenieś wirtualny adres IP do nowego węzła podstawowego, aby nie trzeba było niczego zmieniać w swojej aplikacji, a można to zrobić za pomocą własnego skryptu lub narzędzia.
W tej chwili nie masz żadnego problemu, ale… jeśli twój stary węzeł podstawowy powróci, musisz upewnić się, że nie będziesz mieć dwóch węzłów głównych w tym samym klastrze w tym samym czasie .
Najczęstsze metody uniknięcia tej sytuacji to:
- STONITH:Strzelaj do drugiego węzła w głowę.
- SMITH:Strzel sobie w głowę.
PostgreSQL nie zapewnia żadnego sposobu na zautomatyzowanie tego procesu. Musisz zrobić to sam.
Jak uniknąć podziału mózgu w PostgreSQL za pomocą ClusterControl
Teraz zobaczmy, jak ClusterControl może Ci pomóc w tym zadaniu.
Po pierwsze, możesz go użyć do wdrożenia lub zaimportowania środowiska PostgreSQL Multi-Cloud w łatwy sposób, jak możesz zobaczyć w tym poście na blogu.
Następnie możesz ulepszyć swoją topologię, dodając Load Balancer (HAProxy), co możesz również zrobić za pomocą ClusterControl, śledząc ten blog. Więc będziesz miał coś takiego:
ClusterControl ma funkcję automatycznego przełączania awaryjnego, która wykrywa awarie urządzenia głównego i promuje stan wstrzymania węzeł z najbardziej aktualnymi danymi jako nowy podstawowy. Replikacja z pozostałych węzłów rezerwowych z nowego węzła podstawowego jest również błędna.
HAProxy jest domyślnie konfigurowane przez ClusterControl z dwoma różnymi portami, jednym do odczytu-zapisu i jednym tylko do odczytu. Na porcie do odczytu i zapisu masz węzeł główny w trybie online, a pozostałe węzły w trybie offline, a na porcie tylko do odczytu masz w trybie online węzły podstawowy i zapasowy. W ten sposób możesz zrównoważyć ruch odczytu między twoimi węzłami, ale upewnij się, że w momencie pisania używany będzie port odczytu-zapisu, pisząc w węźle podstawowym, czyli serwerze, który jest online.
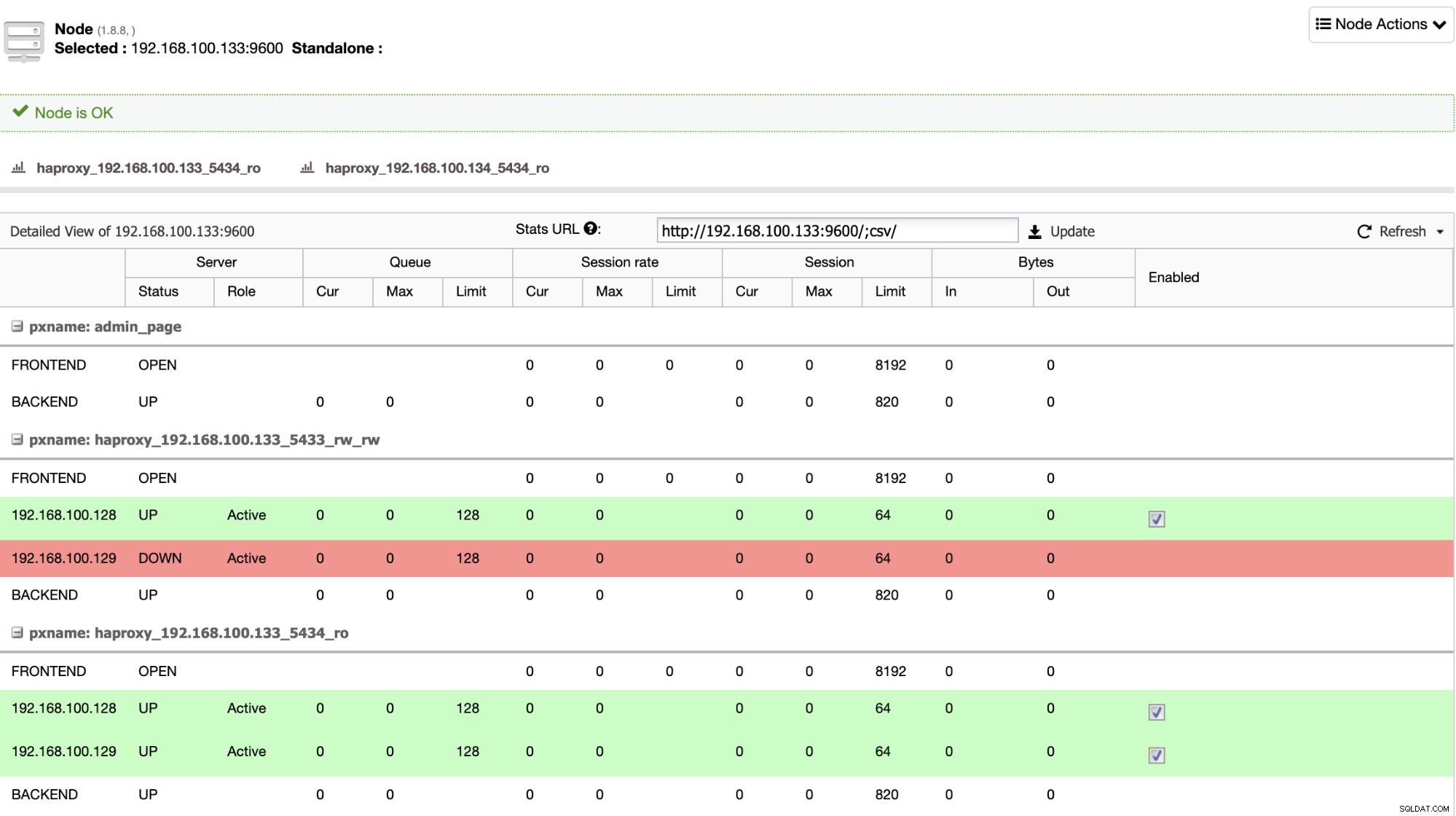
Gdy HAProxy wykryje, że jeden z węzłów, podstawowy lub rezerwowy, jest niedostępny, automatycznie oznacza go jako offline i nie bierze pod uwagę przy wysyłaniu do niego ruchu. To sprawdzenie jest wykonywane przez skrypty sprawdzania kondycji, które są konfigurowane przez ClusterControl w czasie wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Jeśli twój stary węzeł podstawowy powróci, ClusterControl również uniknie jego uruchamiania, aby zapobiec potencjalnemu rozszczepieniu mózgu w przypadku bezpośredniego połączenia, które nie korzysta z Load Balancera, ale możesz je dodać do klastra jako węzła rezerwowego w sposób automatyczny lub ręczny za pomocą interfejsu użytkownika lub CLI ClusterControl, a następnie można go promować tak, aby miał tę samą topologię, co przed problemem.
Wnioski
Po włączeniu opcji „Autoodzyskiwanie”, ClusterControl wykona automatyczne przełączanie awaryjne i powiadomi Cię o problemie. W ten sposób Twoje systemy mogą odzyskać sprawność w ciągu kilku sekund bez Twojej interwencji, a Ty unikniesz rozszczepienia mózgu w środowisku PostgreSQL Multi-Cloud.
Możesz również ulepszyć swoje środowisko wysokiej dostępności, dodając więcej węzłów ClusterControl za pomocą funkcji CMON HA opisanej w tym blogu.