Przełączanie awaryjne to zdolność systemu do kontynuowania pracy, nawet jeśli wystąpi jakaś awaria. Sugeruje to, że funkcje systemu przejmują komponenty drugorzędne, jeśli główne komponenty ulegną awarii lub jeśli jest to potrzebne. Tak więc, jeśli przetłumaczysz to na środowisko wielochmurowe PostgreSQL, oznacza to, że gdy twój węzeł podstawowy ulegnie awarii (lub z innego powodu, o którym wspomnimy w następnej sekcji) u głównego dostawcy chmury, musisz być w stanie promować węzeł zapasowy w drugim, aby utrzymać działanie systemów.
Ogólnie rzecz biorąc, wszyscy dostawcy chmury oferują opcję przełączania awaryjnego u tego samego dostawcy chmury, ale może być konieczne przełączenie awaryjne na innego dostawcę chmury. Oczywiście możesz to zrobić ręcznie, ale możesz również użyć niektórych funkcji ClusterControl, takich jak automatyczne przełączanie awaryjne lub promowanie akcji podrzędnej, aby zrobić to w przyjazny i łatwy sposób.
W tym blogu dowiesz się, dlaczego przełączenie awaryjne powinno być potrzebne, jak to zrobić ręcznie i jak używać ClusterControl do tego zadania. Założymy, że masz uruchomioną instalację ClusterControl i masz już utworzony klaster bazy danych u dwóch różnych dostawców chmury.
Do czego służy przełączanie awaryjne?
Istnieje kilka możliwych zastosowań przełączania awaryjnego.
Główna awaria
Jeśli Twój węzeł główny nie działa lub nawet jeśli Twój główny dostawca chmury ma jakieś problemy, musisz przełączyć się w tryb awaryjny, aby zapewnić dostępność systemu. W takim przypadku automatyczny sposób na zrobienie tego może być konieczny, aby skrócić czas przestoju.
Migracja
Jeśli chcesz migrować swoje systemy od jednego dostawcy chmury do innego, minimalizując przestoje, możesz użyć przełączania awaryjnego. Możesz utworzyć replikę w dodatkowym dostawcy chmury, a po jej zsynchronizowaniu musisz zatrzymać system, promować replikę i przełączać awaryjnie, zanim skierujesz system do nowego węzła głównego w dodatkowym dostawcy chmury.
Konserwacja
Jeśli musisz wykonać jakiekolwiek zadanie konserwacyjne na węźle podstawowym PostgreSQL, możesz promować swoją replikę, wykonać zadanie i odbudować stary węzeł podstawowy jako węzeł rezerwowy.
Po tym możesz promować stary podstawowy i powtórzyć proces odbudowy w węźle gotowości, wracając do stanu początkowego.
W ten sposób możesz pracować na swoim serwerze bez narażania się na brak połączenia lub utratę informacji podczas wykonywania jakichkolwiek zadań konserwacyjnych.
Aktualizacje
Możliwe jest uaktualnienie wersji PostgreSQL (od PostgreSQL 10) lub nawet uaktualnienie systemu operacyjnego przy użyciu replikacji logicznej bez przestojów, tak jak można to zrobić w przypadku innych silników.
Kroki byłyby takie same, jak w przypadku migracji do nowego dostawcy chmury, z tą różnicą, że twoja replika byłaby w nowszej wersji PostgreSQL lub systemu operacyjnego i musisz użyć replikacji logicznej, ponieważ nie możesz używać przesyłania strumieniowego replikacja między różnymi wersjami.
Przełączanie awaryjne to nie tylko baza danych, ale także aplikacja. Skąd wiedzą, z którą bazą danych mają się połączyć? Prawdopodobnie nie chcesz modyfikować swojej aplikacji, ponieważ wydłuży to tylko czas przestoju, więc możesz skonfigurować Load Balancer, aby w przypadku awarii głównego węzła automatycznie wskazywał serwer, który był promowany.
Posiadanie pojedynczej instancji Load Balancer nie jest najlepszą opcją, ponieważ może stać się pojedynczym punktem awarii. W związku z tym można również zaimplementować tryb failover dla Load Balancer przy użyciu usługi takiej jak Keepalived. W ten sposób, jeśli masz problem z podstawowym Load Balancerem, Keepalived przeniesie wirtualny adres IP do dodatkowego Load Balancera i wszystko będzie nadal działać transparentnie.
Inną opcją jest użycie DNS. Promując węzeł rezerwowy w dodatkowym dostawcy chmury, bezpośrednio modyfikujesz adres IP nazwy hosta, który wskazuje na węzeł podstawowy. W ten sposób unikniesz konieczności modyfikowania aplikacji i chociaż nie można tego zrobić automatycznie, jest to alternatywa, jeśli nie chcesz wdrażać Load Balancera.
Jak ręcznie przełączać PostgreSQL w tryb awaryjny
Przed wykonaniem ręcznego przełączania awaryjnego należy sprawdzić stan replikacji. Może się zdarzyć, że w przypadku konieczności przełączenia awaryjnego węzeł rezerwowy nie jest aktualny z powodu awarii sieci, dużego obciążenia lub innego problemu, dlatego należy upewnić się, że w węźle rezerwowym są wszystkie (lub prawie wszystkie informacje. Jeśli masz więcej niż jeden węzeł gotowości, powinieneś również sprawdzić, który z nich jest najbardziej zaawansowany i wybrać go do przełączenia awaryjnego.
postgres=# SELECT CASE WHEN pg_last_wal_receive_lsn()=pg_last_wal_replay_lsn()
postgres-# THEN 0
postgres-# ELSE EXTRACT (EPOCH FROM now() - pg_last_xact_replay_timestamp())
postgres-# END AS log_delay;
log_delay
-----------
0
(1 row)Gdy wybierzesz nowy węzeł podstawowy, najpierw możesz uruchomić polecenie pg_lsclusters, aby uzyskać informacje o klastrze:
$ pg_lsclusters
Ver Cluster Port Status Owner Data directory Log file
12 main 5432 online,recovery postgres /var/lib/postgresql/12/main log/postgresql-%Y-%m-%d_%H%M%S.logNastępnie wystarczy uruchomić polecenie pg_ctlcluster z akcją promującą:
$ pg_ctlcluster 12 main promoteZamiast poprzedniego polecenia możesz uruchomić polecenie pg_ctl w ten sposób:
$ /usr/lib/postgresql/12/bin/pg_ctl promote -D /var/lib/postgresql/12/main/
waiting for server to promote.... done
server promotedWtedy Twój węzeł zapasowy zostanie promowany do podstawowego i możesz go zweryfikować, uruchamiając następujące zapytanie w nowym węźle podstawowym:
postgres=# select pg_is_in_recovery();
pg_is_in_recovery
-------------------
f
(1 row)Jeśli wynik to „f”, jest to Twój nowy węzeł główny.
Teraz musisz zmienić adres IP podstawowej bazy danych w swojej aplikacji, Load Balancer, DNS lub implementacji, z której korzystasz, której, jak wspomnieliśmy, ręczna zmiana zwiększy czas przestoju. Musisz również upewnić się, że połączenie między dostawcami puszki działa prawidłowo, aplikacja może uzyskać dostęp do nowego węzła podstawowego, użytkownik aplikacji ma uprawnienia dostępu do niego od innego dostawcy chmury i należy odbudować węzły rezerwowe w zdalnego lub nawet lokalnego dostawcy chmury, aby replikować z nowego podstawowego, w przeciwnym razie nie będziesz mieć nowej opcji przełączania awaryjnego, jeśli zajdzie taka potrzeba.
Jak przełączyć PostgreSQL w tryb failover za pomocą ClusterControl
ClusterControl ma wiele funkcji związanych z replikacją PostgreSQL i automatycznym przełączaniem awaryjnym. Zakładamy, że masz zainstalowany serwer ClusterControl i zarządza on środowiskiem Multi-Cloud PostgreSQL.
Dzięki ClusterControl możesz dodać dowolną liczbę węzłów gotowości lub węzłów Load Balancer bez żadnych ograniczeń sieci IP. Oznacza to, że nie jest konieczne, aby węzeł rezerwowy znajdował się w tej samej sieci węzła podstawowego lub nawet u tego samego dostawcy chmury. Jeśli chodzi o przełączanie awaryjne, ClusterControl pozwala zrobić to ręcznie lub automatycznie.
Ręczne przełączanie awaryjne
Aby wykonać ręczne przełączanie awaryjne, przejdź do ClusterControl -> Wybierz Cluster -> Węzły i w Akcjach węzła jednego z węzłów rezerwowych wybierz opcję „Promuj urządzenie podrzędne”.
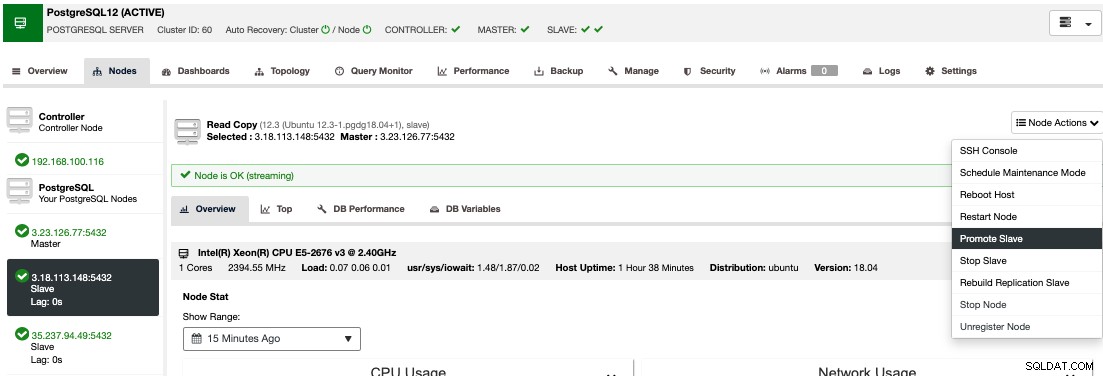
W ten sposób po kilku sekundach węzeł gotowości staje się podstawowym, a to, co było wcześniej twoim podstawowym, zamienia się w tryb gotowości. Tak więc, jeśli twoja replika była u innego dostawcy chmury, twój nowy węzeł główny będzie tam działał.
Automatyczne przełączanie awaryjne
W przypadku automatycznego przełączania awaryjnego, ClusterControl wykrywa awarie w węźle podstawowym i promuje węzeł rezerwowy z najbardziej aktualnymi danymi jako nowy węzeł główny. Działa również na pozostałych węzłach w trybie gotowości, aby były replikowane z nowej wersji podstawowej.

Po włączeniu opcji „Autoodzyskiwanie” ClusterControl wykona automatyczne przełączanie awaryjne jako jak również powiadomić Cię o problemie. W ten sposób Twoje systemy mogą zostać przywrócone w ciągu kilku sekund i bez Twojej interwencji.
ClusterControl oferuje możliwość skonfigurowania białej/czarnej listy, aby określić, w jaki sposób serwery mają być brane (lub nie) pod uwagę przy podejmowaniu decyzji o głównym kandydacie.
ClusterControl wykonuje również kilka kontroli procesu przełączania awaryjnego, na przykład domyślnie, jeśli uda Ci się odzyskać stary uszkodzony węzeł podstawowy, nie zostanie on automatycznie ponownie wprowadzony do klastra, ani jako podstawowy, ani w trybie gotowości będziesz musiał to zrobić ręcznie. Pozwoli to uniknąć utraty danych lub niespójności w przypadku, gdy Twój stan gotowości (który promowałeś) był opóźniony w momencie awarii. Możesz również szczegółowo przeanalizować problem, ale po dodaniu go do klastra prawdopodobnie utracisz informacje diagnostyczne.
Systemy równoważenia obciążenia
Jak wspomnieliśmy wcześniej, Load Balancer jest ważnym narzędziem do rozważenia podczas przełączania awaryjnego, zwłaszcza jeśli chcesz użyć automatycznego przełączania awaryjnego w topologii bazy danych.
Aby przełączanie awaryjne było niewidoczne zarówno dla użytkownika, jak i dla aplikacji, potrzebny jest komponent pośredni, ponieważ nie wystarczy wypromowanie nowego węzła podstawowego. W tym celu możesz użyć HAProxy + Keepalived.
Aby wdrożyć to rozwiązanie z ClusterControl, przejdź do Akcje klastra -> Dodaj Load Balancer -> HAProxy w swoim klastrze PostgreSQL. W przypadku, gdy chcesz wdrożyć tryb failover dla swojego Load Balancera, musisz skonfigurować co najmniej dwie instancje HAProxy, a następnie skonfigurować Keepalived (Akcje klastra -> Dodaj Load Balancer -> Keepalived). Więcej informacji na temat tej implementacji można znaleźć w tym poście na blogu.
Po tym będziesz mieć następującą topologię:

HAProxy jest domyślnie skonfigurowany z dwoma różnymi portami, jednym do odczytu i zapisu oraz jeden tylko do odczytu.
W porcie do odczytu i zapisu masz swój węzeł główny w trybie online, a pozostałe węzły w trybie offline. W porcie tylko do odczytu masz w trybie online zarówno węzły podstawowy, jak i rezerwowy. W ten sposób możesz zrównoważyć ruch odczytu między węzłami. Podczas pisania zostanie użyty port do odczytu i zapisu, który będzie wskazywał na bieżący węzeł główny.

Gdy HAProxy wykryje, że jeden z węzłów, podstawowy lub rezerwowy, jest niedostępny, automatycznie oznacza go jako offline. HAProxy nie będzie do niego wysyłać żadnego ruchu. To sprawdzenie jest wykonywane przez skrypty sprawdzania kondycji, które są konfigurowane przez ClusterControl w czasie wdrażania. Sprawdzają one, czy instancje działają, czy są w trakcie odzyskiwania, czy są tylko do odczytu.
Gdy ClusterControl promuje nowy węzeł główny, HAProxy oznacza stary jako offline (dla obu portów) i umieszcza promowany węzeł online w porcie do odczytu i zapisu. W ten sposób Twoje systemy będą nadal działać normalnie.
Jeśli aktywny HAProxy (który przypisał wirtualny adres IP, z którym łączą się twoje systemy) ulegnie awarii, Keepalived automatycznie migruje ten wirtualny adres IP do pasywnego HAProxy. Oznacza to, że Twoje systemy będą mogły dalej normalnie funkcjonować.
Replikacja między klastrami w chmurze
Aby mieć środowisko Multi-Cloud, możesz użyć działania ClusterControl Add Slave na swoim klastrze PostgreSQL, ale także funkcji Cluster-to-Cluster Replication. W tej chwili ta funkcja ma ograniczenie dla PostgreSQL, które pozwala na posiadanie tylko jednego węzła zdalnego, ale pracujemy nad usunięciem tego ograniczenia wkrótce w przyszłej wersji.
Aby go wdrożyć, zapoznaj się z sekcją „Replikacja między klastrami w chmurze” w tym poście na blogu.

Gdy jest na miejscu, możesz promować zdalny klaster, który wygeneruje niezależny klaster PostgreSQL z węzłem podstawowym działającym na dodatkowym dostawcy chmury.

W razie potrzeby będziesz miał uruchomiony ten sam klaster w nowym dostawcy chmury w zaledwie kilka sekund.
Wnioski
Posiadanie automatycznego procesu przełączania awaryjnego jest obowiązkowe, jeśli chcesz skrócić czas przestoju, jak to tylko możliwe, a użycie różnych technologii, takich jak HAProxy i Keepalived, poprawi to przełączanie awaryjne.
Funkcje ClusterControl, o których wspomnieliśmy powyżej, umożliwiają szybkie przełączanie awaryjne między różnymi dostawcami chmury i zarządzanie konfiguracją w łatwy i przyjazny sposób.
Najważniejszą rzeczą, którą należy wziąć pod uwagę przed wykonaniem procesu przełączania awaryjnego między różnymi dostawcami chmury, jest łączność. Musisz upewnić się, że Twoja aplikacja lub połączenia z bazą danych będą działały normalnie, korzystając z głównego, ale także pomocniczego dostawcy chmury w przypadku awarii, a także ze względów bezpieczeństwa musisz ograniczyć ruch tylko ze znanych źródeł, a więc tylko między chmurą Dostawcy i nie zezwalaj na to z żadnego zewnętrznego źródła.