Chociaż istnieją różne sposoby na odzyskanie bazy danych PostgreSQL, jedno z najwygodniejszych sposobów przywracania danych z logicznej kopii zapasowej. Logiczne kopie zapasowe odgrywają istotną rolę w planowaniu awarii i odzyskiwania (DRP). Kopie zapasowe logiczne to kopie zapasowe wykonywane na przykład przy użyciu pg_dump lub pg_dumpall, które generują instrukcje SQL w celu uzyskania wszystkich danych z tabeli zapisanych w pliku binarnym.
Zaleca się również uruchamianie okresowych logicznych kopii zapasowych na wypadek awarii lub braku fizycznych kopii zapasowych. W przypadku PostgreSQL przywracanie może być problematyczne, jeśli nie masz pewności, jakich narzędzi użyć. Narzędzie do tworzenia kopii zapasowych pg_dump jest zwykle sparowane z narzędziem przywracania pg_restore.
pg_dump i pg_restore działają jednocześnie w przypadku awarii i konieczności odzyskania danych. Chociaż służą one głównym celom zrzutu i przywracania, wymagają wykonania dodatkowych zadań, gdy trzeba odzyskać klaster i wykonać przełączanie awaryjne (jeśli aktywny serwer główny lub główny umrze z powodu awarii sprzętu lub uszkodzenia systemu maszyny wirtualnej). W końcu znajdziesz i wykorzystasz narzędzia innych firm, które poradzą sobie z przełączaniem awaryjnym lub automatycznym odzyskiwaniem klastra.
W tym blogu przyjrzymy się, jak działa pg_restore i porównamy to, jak ClusterControl obsługuje tworzenie kopii zapasowych i przywracanie danych w przypadku awarii.
Mechanizmy pg_restore
pg_restore jest przydatny podczas uzyskiwania następujących zadań:
- sparowany z pg_dump do generowania plików generowanych przez SQL zawierających dane, role dostępu, definicje baz danych i tabel
- przywróć bazę danych PostgreSQL z archiwum utworzonego przez pg_dump w jednym z formatów innych niż zwykły tekst.
- Wyda polecenia niezbędne do zrekonstruowania bazy danych do stanu, w jakim była w momencie jej zapisania.
- może być selektywny, a nawet zmieniać kolejność elementów przed przywróceniem na podstawie pliku archiwum
- Pliki archiwum są zaprojektowane tak, aby można je było przenosić między różnymi architekturami.
- pg_restore może działać w dwóch trybach.
- Jeśli określono nazwę bazy danych, pg_restore łączy się z tą bazą danych i przywraca zawartość archiwum bezpośrednio do bazy danych.
- lub skrypt zawierający polecenia SQL niezbędne do odbudowania bazy danych jest tworzony i zapisywany do pliku lub na standardowe wyjście. Jego wyjście skryptu jest równoważne z formatem wygenerowanym przez pg_dump
- Niektóre opcje kontrolujące wyjście są zatem analogiczne do opcji pg_dump.
Po przywróceniu danych najlepiej i zaleca się uruchomić ANALIZA na każdej przywróconej tabeli, aby optymalizator dysponował przydatnymi statystykami. Chociaż uzyskuje BLOKADĘ ODCZYTU, może być konieczne uruchomienie go podczas małego ruchu lub podczas okresu konserwacji.
Zalety pg_restore
pg_dump i pg_restore w tandemie mają możliwości, które są wygodne w użyciu dla administratora.
- pg_dump i pg_restore mogą działać równolegle poprzez określenie opcji -j. Użycie opcji -j/--jobs
umożliwia określenie liczby uruchomionych równolegle zadań, szczególnie w celu ładowania danych, tworzenia indeksów lub tworzenia ograniczeń przy użyciu wielu współbieżnych zadań. - Jest cichy w użyciu, możesz selektywnie zrzucać lub ładować konkretną bazę danych lub tabele
- Pozwala i zapewnia użytkownikowi elastyczność w zakresie konkretnej bazy danych, schematu lub zmiany kolejności procedur do wykonania na podstawie listy. Możesz nawet generować i ładować sekwencję SQL luźno, na przykład zapobiegać acls lub przywilejom, zgodnie z własnymi potrzebami. Istnieje wiele opcji dostosowanych do Twoich potrzeb.
- Zapewnia możliwość generowania plików SQL, podobnie jak pg_dump z archiwum. Jest to bardzo wygodne, jeśli chcesz załadować do innej bazy danych lub hosta, aby zapewnić oddzielne środowisko.
- Łatwe do zrozumienia na podstawie wygenerowanej sekwencji procedur SQL.
- Jest to wygodny sposób ładowania danych w środowisku replikacji. Nie musisz ponownie uruchamiać repliki, ponieważ instrukcje są w języku SQL, które zostały zreplikowane do węzłów gotowości i odzyskiwania.
Ograniczenia pg_restore
W przypadku logicznych kopii zapasowych oczywistymi ograniczeniami pg_restore wraz z pg_dump są wydajność i szybkość korzystania z narzędzi. Może to być przydatne, gdy chcesz udostępnić testowe lub programistyczne środowisko bazy danych i załadować dane, ale nie ma zastosowania, gdy zestaw danych jest ogromny. PostgreSQL musi zrzucać dane jeden po drugim lub uruchamiać i stosować je sekwencyjnie przez silnik bazy danych. Chociaż możesz uczynić to luźno elastycznym, aby przyspieszyć, na przykład podając -j lub używając --single-transaction, aby uniknąć wpływu na bazę danych, ładowanie za pomocą SQL nadal musi być analizowane przez silnik.
Dodatkowo, dokumentacja PostgreSQL podaje następujące ograniczenia, z naszymi dodatkami, gdy zaobserwowaliśmy te narzędzia (pg_dump i pg_restore):
- Podczas przywracania danych do istniejącej tabeli i użycia opcji --disable-triggers, pg_restore emituje polecenia wyłączające wyzwalacze w tabelach użytkownika przed wstawieniem danych, a następnie emituje polecenia, aby je ponownie włączyć po wprowadzeniu danych. Jeśli przywracanie zostanie zatrzymane w trakcie, katalogi systemowe mogą pozostać w złym stanie.
- pg_restore nie może selektywnie przywracać dużych obiektów; na przykład tylko te dla określonej tabeli. Jeśli archiwum zawiera duże obiekty, wszystkie duże obiekty zostaną przywrócone lub żaden z nich, jeśli zostaną wykluczone przez -L, -t lub inne opcje.
- Oczekuje się, że oba narzędzia będą generować ogromne ilości rozmiaru (pliki, katalog lub archiwum tar), szczególnie w przypadku ogromnej bazy danych.
- W przypadku pg_dump, podczas zrzucania pojedynczej tabeli lub zwykłego tekstu, pg_dump nie obsługuje dużych obiektów. Duże obiekty należy zrzucić wraz z całą bazą danych przy użyciu jednego z nietekstowych formatów archiwum.
- Jeśli masz archiwa tar wygenerowane przez te narzędzia, pamiętaj, że archiwa tar są ograniczone do rozmiaru mniejszego niż 8 GB. Jest to nieodłączne ograniczenie formatu pliku tar. Dlatego ten format nie może być używany, jeśli tekstowa reprezentacja tabeli przekracza ten rozmiar. Całkowity rozmiar archiwum tar i innych formatów wyjściowych nie jest ograniczony, chyba że przez system operacyjny.
Korzystanie z pg_restore
Korzystanie z pg_restore jest bardzo przydatne i łatwe w użyciu. Ponieważ jest sparowany z pg_dump, oba te narzędzia działają wystarczająco dobrze, o ile docelowe wyjście pasuje do drugiego. Na przykład poniższy pg_dump nie będzie przydatny w przypadku pg_restore,
[example@sqldat.com ~]# pg_dump --format=p --create -U dbapgadmin -W -d paultest -f plain.sql
Password: Ten wynik będzie zgodny z psql, który wygląda następująco:
[example@sqldat.com ~]# less plain.sql
--
-- PostgreSQL database dump
--
-- Dumped from database version 12.2
-- Dumped by pg_dump version 12.2
SET statement_timeout = 0;
SET lock_timeout = 0;
SET idle_in_transaction_session_timeout = 0;
SET client_encoding = 'UTF8';
SET standard_conforming_strings = on;
SELECT pg_catalog.set_config('search_path', '', false);
SET check_function_bodies = false;
SET xmloption = content;
SET client_min_messages = warning;
SET row_security = off;
--
-- Name: paultest; Type: DATABASE; Schema: -; Owner: postgres
--
CREATE DATABASE paultest WITH TEMPLATE = template0 ENCODING = 'UTF8' LC_COLLATE = 'en_US.UTF-8' LC_CTYPE = 'en_US.UTF-8';
ALTER DATABASE paultest OWNER TO postgres;Ale to się nie powiedzie w przypadku pg_restore, ponieważ nie ma zwykłego formatu do naśladowania:
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=p -C -W -d postgres plain.sql
pg_restore: error: unrecognized archive format "p"; please specify "c", "d", or "t"
[example@sqldat.com ~]# pg_restore -U dbapgadmin --format=c -C -W -d postgres plain.sql
pg_restore: error: did not find magic string in file headerTeraz przejdźmy do bardziej przydatnych terminów dotyczących pg_restore.
pg_restore:Usuń i przywróć
Rozważ proste użycie pg_restore, które upuściłeś bazę danych, np.
postgres=# drop database maxtest;
DROP DATABASE
postgres=# \l+
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
-----------+----------+----------+-------------+-------------+-----------------------+---------+------------+--------------------------------------------
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 83 MB | pg_default |
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8209 kB | pg_default | default administrative connection database
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +| 8049 kB | pg_default | unmodifiable empty database
| | | | | postgres=CTc/postgres | | |
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | postgres=CTc/postgres+| 8193 kB | pg_default | default template for new databases
| | | | | =c/postgres | | |
(4 rows)Przywracanie go za pomocą pg_restore jest bardzo proste,
[example@sqldat.com ~]# sudo -iu postgres pg_restore -C -d postgres /opt/pg-files/dump/f.dump Karta -C/--create tutaj określa, że tworzy bazę danych, gdy zostanie napotkana w nagłówku. -d postgres wskazuje na bazę danych postgres, ale nie oznacza to, że utworzy tabele do bazy postgres. Wymaga to istnienia bazy danych. Jeśli nie podano opcji -C, tabele i rekordy będą przechowywane w bazie danych, do której odwołuje się argument -d.
Przywracanie selektywne według tabeli
Przywracanie tabeli za pomocą pg_restore jest łatwe i proste. Na przykład masz dwie tabele, a mianowicie tabele „b” i „d”. Załóżmy, że uruchamiasz następujące polecenie pg_dump poniżej,
[example@sqldat.com ~]# pg_dump --format=d --create -U dbapgadmin -W -d paultest -f pgdump_inserts
Password:Gdzie zawartość tego katalogu będzie wyglądać następująco,
[example@sqldat.com ~]# ls -alth pgdump_inserts/
total 16M
-rw-r--r--. 1 root root 14M May 15 20:27 3696.dat.gz
drwx------. 2 root root 59 May 15 20:27 .
-rw-r--r--. 1 root root 2.5M May 15 20:27 3694.dat.gz
-rw-r--r--. 1 root root 4.0K May 15 20:27 toc.dat
dr-xr-x---. 5 root root 275 May 15 20:27 ..Jeśli chcesz przywrócić tabelę (w tym przykładzie „d”),
[example@sqldat.com ~]# pg_restore -U postgres -Fd -d paultest -t d pgdump_inserts/Musi mieć,
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)pg_restore:Kopiowanie tabel bazy danych do innej bazy danych
Możesz nawet skopiować zawartość istniejącej bazy danych i umieścić ją w docelowej bazie danych. Na przykład mam następujące bazy danych,
paultest=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+---------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 84 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 8273 kB | pg_default |
(2 rows)Baza danych paultest jest pustą bazą danych, podczas gdy zamierzamy skopiować zawartość bazy danych maxtest,
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | d | table | postgres | 51 MB |
(1 row)
maxtest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Aby go skopiować, musimy zrzucić dane z bazy danych maxtest w następujący sposób,
[example@sqldat.com ~]# pg_dump --format=t --create -U dbapgadmin -W -d maxtest -f pgdump_data.tar
Password: Następnie załaduj lub przywróć go w następujący sposób,
Teraz mamy dane w bazie danych paultest, a tabele zostały odpowiednio zapisane.
postgres=# \l+ (paultest|maxtest)
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges | Size | Tablespace | Description
----------+----------+----------+-------------+-------------+-------------------+--------+------------+-------------
maxtest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 153 MB | pg_default |
paultest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | | 154 MB | pg_default |
(2 rows)
paultest=# \dt+
List of relations
Schema | Name | Type | Owner | Size | Description
--------+------+-------+----------+-------+-------------
public | b | table | postgres | 69 MB |
public | d | table | postgres | 51 MB |
(2 rows)Generuj plik SQL z funkcją zmiany kolejności
Widziałem wiele zastosowań z pg_restore, ale wydaje się, że ta funkcja nie jest zwykle prezentowana. Uważam, że to podejście jest bardzo interesujące, ponieważ umożliwia zamawianie na podstawie tego, czego nie chcesz uwzględniać, a następnie generowanie pliku SQL z zamówienia, które chcesz kontynuować.
Na przykład użyjemy przykładowego pliku pgdump_data.tar, który wygenerowaliśmy wcześniej i utworzymy listę. Aby to zrobić, uruchom następujące polecenie:
[example@sqldat.com ~]# pg_restore -l pgdump_data.tar > my.listSpowoduje to wygenerowanie pliku, jak pokazano poniżej:
[example@sqldat.com ~]# cat my.list
;
; Archive created at 2020-05-15 20:48:24 UTC
; dbname: maxtest
; TOC Entries: 13
; Compression: 0
; Dump Version: 1.14-0
; Format: TAR
; Integer: 4 bytes
; Offset: 8 bytes
; Dumped from database version: 12.2
; Dumped by pg_dump version: 12.2
;
;
; Selected TOC Entries:
;
204; 1259 24811 TABLE public b postgres
202; 1259 24757 TABLE public d postgres
203; 1259 24760 SEQUENCE public d_id_seq postgres
3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
3560; 2604 24762 DEFAULT public d id postgres
3691; 0 24811 TABLE DATA public b postgres
3689; 0 24757 TABLE DATA public d postgres
3699; 0 0 SEQUENCE SET public d_id_seq postgres
3562; 2606 24764 CONSTRAINT public d d_pkey postgresTeraz zmieńmy kolejność lub powiedzmy, że usunąłem tworzenie SEKWENCJI, a także tworzenie ograniczenia. Wyglądałoby to następująco,
TL;DR
...
;203; 1259 24760 SEQUENCE public d_id_seq postgres
;3698; 0 0 SEQUENCE OWNED BY public d_id_seq postgres
TL;DR
….
;3562; 2606 24764 CONSTRAINT public d d_pkey postgresAby wygenerować plik w formacie SQL, wykonaj następujące czynności:
[example@sqldat.com ~]# pg_restore -L my.list --file /tmp/selective_data.out pgdump_data.tar Teraz plik /tmp/selective_data.out będzie plikiem wygenerowanym przez SQL i można go odczytać, jeśli używasz psql, ale nie pg_restore. Wspaniałe w tym jest to, że możesz wygenerować plik SQL zgodnie ze swoim szablonem, na którym dane można przywrócić tylko z istniejącego archiwum lub kopii zapasowej wykonanej za pomocą pg_dump za pomocą pg_restore.
Przywracanie PostgreSQL za pomocą ClusterControl
ClusterControl nie wykorzystuje pg_restore ani pg_dump jako części swojego zestawu funkcji. Używamy pg_dumpall do generowania logicznych kopii zapasowych i niestety dane wyjściowe nie są kompatybilne z pg_restore.
Istnieje kilka innych sposobów generowania kopii zapasowej w PostgreSQL, jak pokazano poniżej.
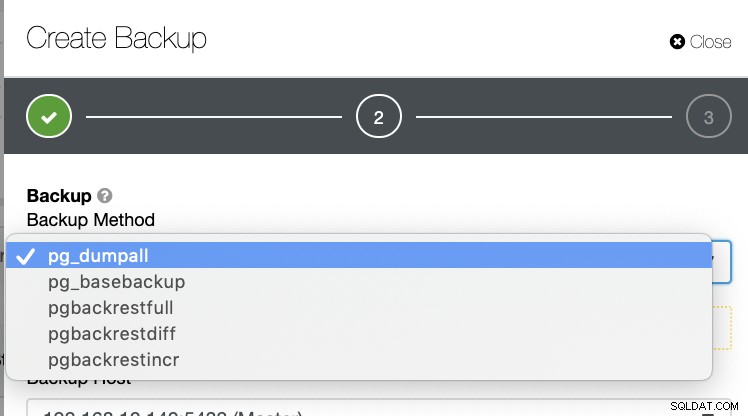
Nie ma takiego mechanizmu, w którym można selektywnie przechowywać tabelę, bazę danych, lub skopiuj z jednej bazy danych do innej bazy danych.
ClusterControl obsługuje przywracanie do punktu w czasie (PITR), ale nie pozwala to na zarządzanie przywracaniem danych tak elastyczne, jak w przypadku pg_restore. W przypadku wszystkich metod tworzenia kopii zapasowych tylko pg_basebackup i pgbackrest obsługują PITR.
Sposób, w jaki ClusterControl obsługuje przywracanie, polega na tym, że ma on możliwość odzyskania uszkodzonego klastra, o ile włączone jest automatyczne odzyskiwanie, jak pokazano poniżej.

Gdy master ulegnie awarii, slave może automatycznie odzyskać klaster podczas działania ClusterControl przełączenie awaryjne (co odbywa się automatycznie). W przypadku części odzyskiwania danych jedyną opcją jest odzyskanie całego klastra, co oznacza, że pochodzi z pełnej kopii zapasowej. Nie ma możliwości selektywnego przywracania docelowej bazy danych lub tabeli, którą chciałeś tylko przywrócić. Jeśli chcesz to zrobić, przywróć pełną kopię zapasową, jest to łatwe dzięki ClusterControl. Możesz przejść do zakładek Kopia zapasowa, tak jak pokazano poniżej,
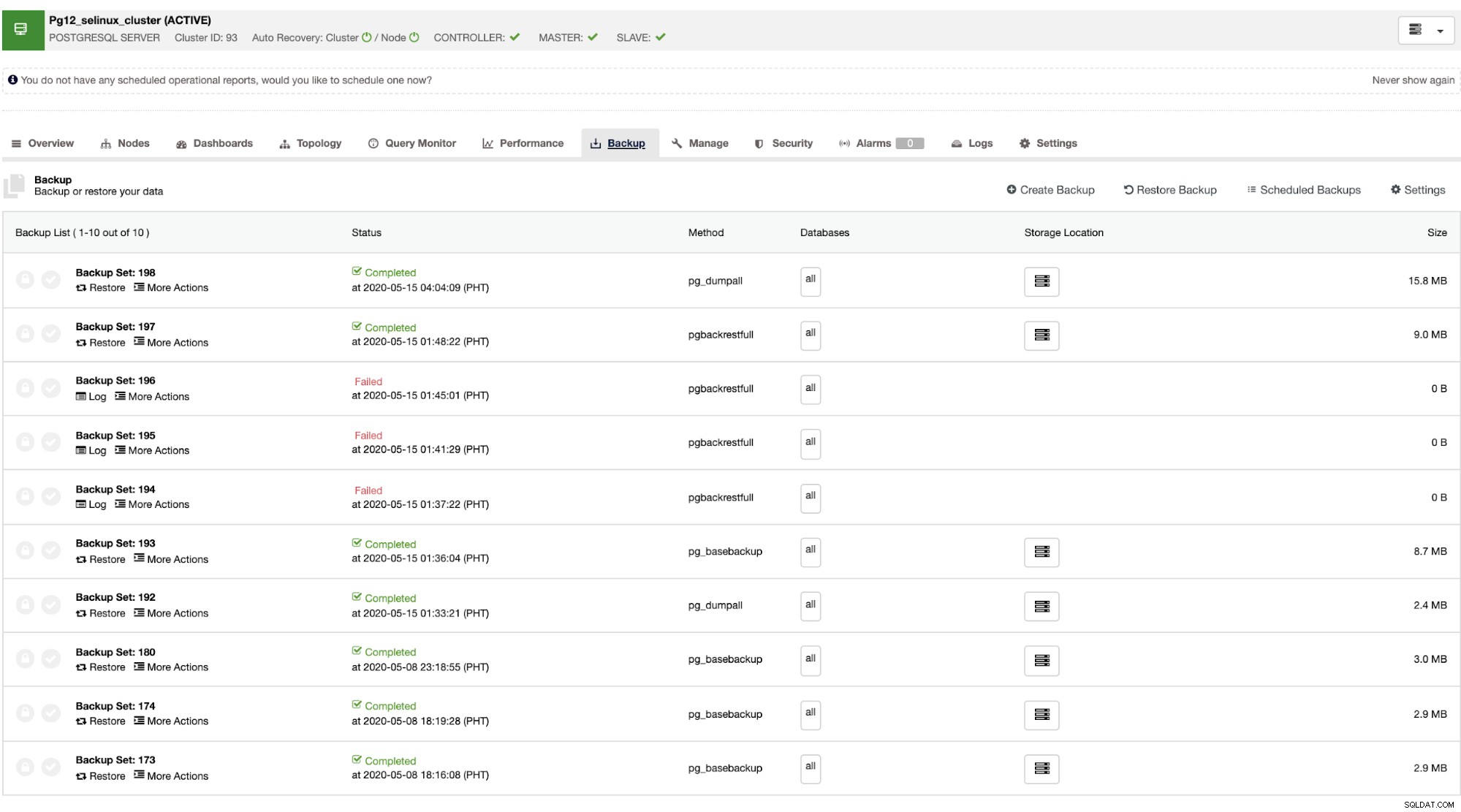
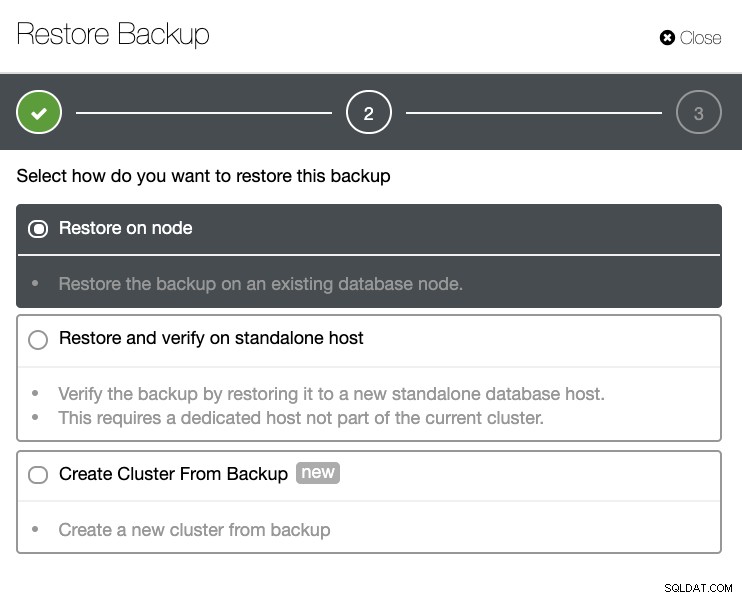
Będziesz mieć pełną listę udanych i nieudanych kopii zapasowych. Następnie można go przywrócić, wybierając docelową kopię zapasową i klikając przycisk „Przywróć”. Umożliwi to przywrócenie istniejącego węzła zarejestrowanego w ClusterControl, weryfikację na węźle samodzielnym lub utworzenie klastra z kopii zapasowej.
Wnioski
Korzystanie z pg_dump i pg_restore upraszcza podejście do tworzenia kopii zapasowych/zrzutów i przywracania. Jednak w przypadku środowiska bazy danych o dużej skali może to nie być idealny składnik do odzyskiwania po awarii. W przypadku minimalnej procedury wyboru i przywracania, użycie kombinacji pg_dump i pg_restore zapewnia możliwość zrzutu i załadowania danych zgodnie z własnymi potrzebami.
W środowiskach produkcyjnych (zwłaszcza w przypadku architektur korporacyjnych) można użyć podejścia ClusterControl do tworzenia kopii zapasowych i przywracania z automatycznym odzyskiwaniem.
Dobrym podejściem jest również kombinacja podejść. Pomaga to obniżyć RTO i RPO, a jednocześnie wykorzystać najbardziej elastyczny sposób przywracania danych w razie potrzeby.