Skalowalność to właściwość systemu umożliwiająca obsługę rosnącej liczby żądań poprzez dodawanie zasobów. Przyczyny takiej ilości żądań mogą być tymczasowe, na przykład, jeśli wprowadzasz zniżkę na wyprzedaż, lub stałe, w celu zwiększenia liczby klientów lub pracowników. W każdym razie powinieneś być w stanie dodawać lub usuwać zasoby, aby zarządzać tymi zmianami w zależności od zapotrzebowania lub wzrostu ruchu.
Dostępne są różne podejścia do skalowania bazy danych. W tym blogu przyjrzymy się, czym są te podejścia i jak skalować bazę danych PostgreSQL za pomocą puli połączeń i systemów równoważenia obciążenia.
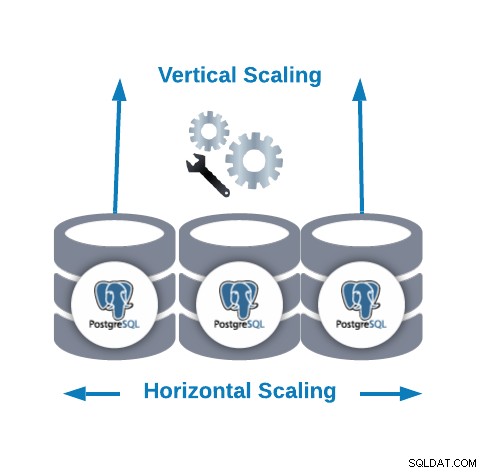
Skalowanie w poziomie i w pionie
Istnieją dwa główne sposoby skalowania bazy danych.
- Skalowanie poziome (skalowanie w poziomie):Jest to realizowane przez dodanie większej liczby węzłów bazy danych tworzących lub powiększających klaster bazy danych. Może pomóc poprawić wydajność odczytu, równoważąc ruch między węzłami.
- Skalowanie w pionie (skalowanie w górę):Jest to realizowane przez dodanie większej ilości zasobów sprzętowych (procesor, pamięć, dysk) do istniejącego węzła bazy danych. Może być konieczna zmiana niektórych parametrów konfiguracyjnych, aby umożliwić PostgreSQL korzystanie z nowego lub lepszego zasobu sprzętowego.
Połączenia i systemy równoważenia obciążenia
W skalowaniu poziomym i pionowym przydatne może być dodanie zewnętrznego narzędzia w celu zmniejszenia obciążenia bazy danych, co poprawi wydajność. Może to za mało, ale to dobry punkt wyjścia. W tym celu dobrym pomysłem jest zaimplementowanie puli połączeń i równoważenia obciążenia. Powiedziałem „i”, ponieważ są przeznaczone do różnych ról.
Zestawienie połączeń to metoda tworzenia puli połączeń i ponownego ich wykorzystywania, unikając nieustannego otwierania nowych połączeń do bazy danych, co znacznie zwiększy wydajność Twoich aplikacji. PgBouncer to popularny puler połączeń zaprojektowany dla PostgreSQL.
Korzystanie z Load Balancera to sposób na zapewnienie wysokiej dostępności w topologii bazy danych, a także zwiększenie wydajności poprzez równoważenie ruchu między dostępnymi węzłami. W tym celu HAProxy jest dobrą opcją dla PostgreSQL, ponieważ jest to proxy typu open source, którego można użyć do implementacji wysokiej dostępności, równoważenia obciążenia i proxy dla aplikacji opartych na protokołach TCP i HTTP.
Jak zaimplementować kombinację HAProxy, PgBouncer i PostgreSQL
Połączenie obu technologii, HAProxy i PgBouncer, jest prawdopodobnie najlepszym sposobem na skalowanie i poprawę wydajności w środowisku PostgreSQL. Zobaczymy więc, jak to zaimplementować przy użyciu następującej architektury:
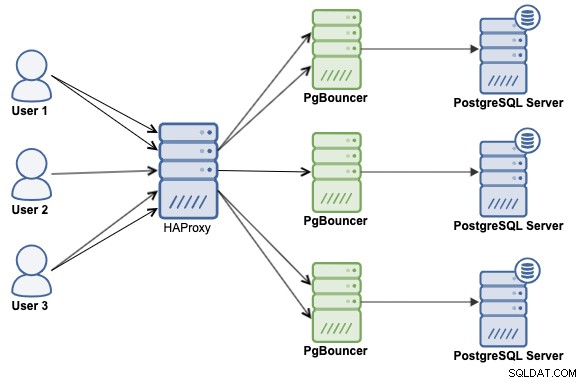
Założymy, że masz zainstalowany ClusterControl, jeśli nie, możesz przejść do oficjalnej stronie, a nawet zapoznaj się z oficjalną dokumentacją, aby ją zainstalować.
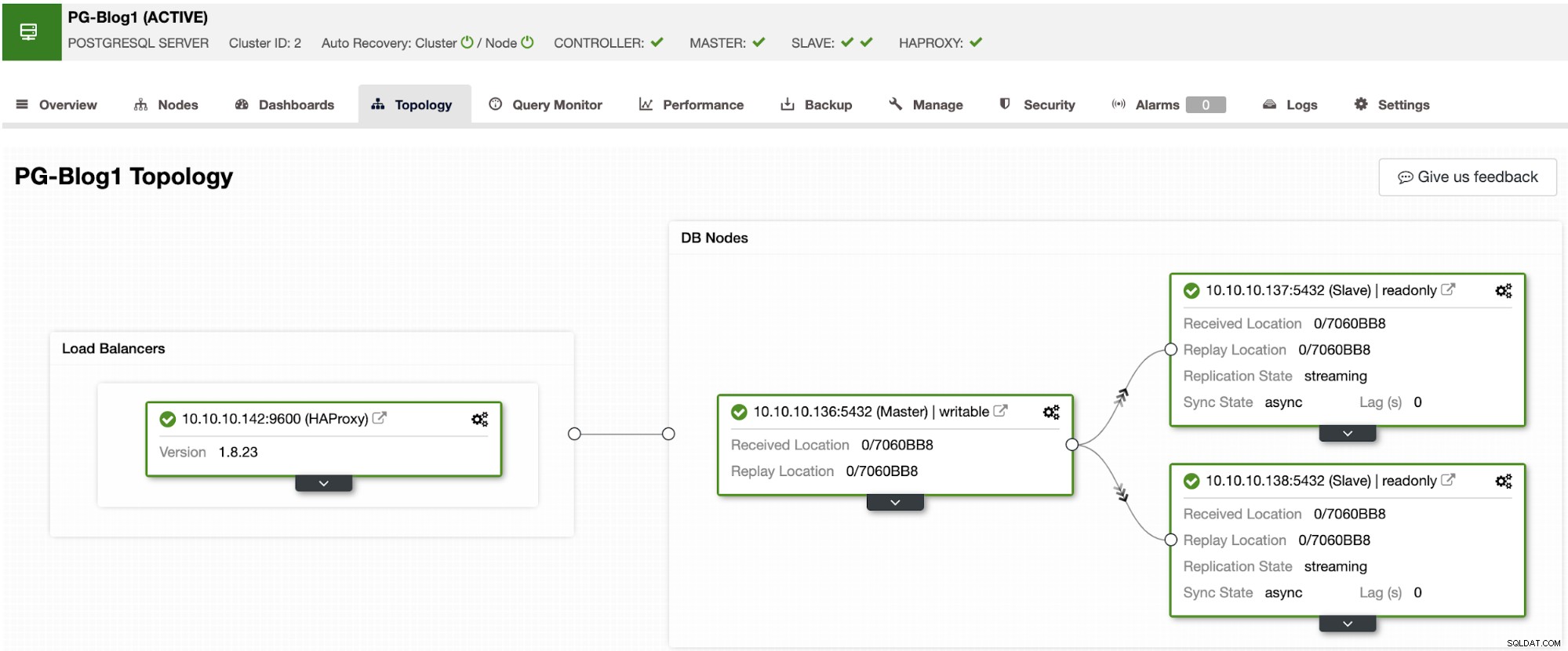
Najpierw musisz wdrożyć swój klaster PostgreSQL z HAProxy na jego czele. W tym celu wykonaj kroki opisane w tym poście na blogu, aby wdrożyć zarówno PostgreSQL, jak i HAProxy przy użyciu ClusterControl.
W tym momencie będziesz mieć coś takiego:
Teraz możesz zainstalować PgBouncer na każdym węźle bazy danych lub na komputerze zewnętrznym .
Aby pobrać oprogramowanie PgBouncer, możesz przejść do sekcji pobierania PgBouncer lub skorzystać z repozytoriów RPM lub DEB. W tym przykładzie użyjemy CentOS 8 i zainstalujemy go z oficjalnego repozytorium PostgreSQL.
Najpierw pobierz i zainstaluj odpowiednie repozytorium ze strony PostgreSQL (jeśli jeszcze go nie masz):
$ wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
$ rpm -Uvh pgdg-redhat-repo-latest.noarch.rpmNastępnie zainstaluj pakiet PgBouncer:
$ yum install pgbouncerPo zakończeniu będziesz miał nowy plik konfiguracyjny zlokalizowany w /etc/pgbouncer/pgbouncer.ini. Jako domyślny plik konfiguracyjny możesz użyć następującego przykładu:
$ cat /etc/pgbouncer/pgbouncer.ini
[databases]
world = host=127.0.0.1 port=5432 dbname=world
[pgbouncer]
logfile = /var/log/pgbouncer/pgbouncer.log
pidfile = /var/run/pgbouncer/pgbouncer.pid
listen_addr = *
listen_port = 6432
auth_type = md5
auth_file = /etc/pgbouncer/userlist.txt
admin_users = admindbI plik uwierzytelniający:
$ cat /etc/pgbouncer/userlist.txt
"admindb" "root123"To tylko podstawowy przykład. Aby uzyskać wszystkie dostępne parametry, możesz sprawdzić oficjalną dokumentację.
Więc w tym przypadku zainstalowałem PgBouncer w tym samym węźle bazy danych, nasłuchując wszystkich adresów IP i łączy się on z bazą danych PostgreSQL o nazwie „świat”. Zarządzam również dozwolonymi użytkownikami w pliku userlist.txt za pomocą hasła w postaci zwykłego tekstu, które w razie potrzeby można zaszyfrować.
Aby uruchomić usługę PgBouncer, wystarczy uruchomić następujące polecenie:
$ pgbouncer -d /etc/pgbouncer/pgbouncer.iniTeraz uruchom następujące polecenie, używając swoich lokalnych informacji (port, host, nazwa użytkownika i nazwa bazy danych), aby uzyskać dostęp do bazy danych PostgreSQL:
$ psql -p 6432 -h 127.0.0.1 -U admindb world
Password for user admindb:
psql (12.4)
Type "help" for help.
world=#To jest podstawowa topologia. Możesz go ulepszyć, na przykład, dodając dwa lub więcej węzłów równoważenia obciążenia, aby uniknąć pojedynczego punktu awarii, i używając narzędzia, takiego jak „Keepalived”, aby zapewnić dostępność. Można to również zrobić za pomocą ClusterControl.
Więcej informacji na temat PgBouncera i sposobu korzystania z niego można znaleźć w tym poście na blogu.
Wnioski
Jeśli potrzebujesz skalować swój klaster PostgreSQL, dodanie HAProxy i PgBouncer to dobry sposób na skalowanie w poziomie i w górę w tym samym czasie, ponieważ możesz dodać więcej węzłów gotowości w celu zrównoważenia ruchu i poprawisz wydajność ponownie wykorzystując otwarte połączenia.
ClusterControl zapewnia całą gamę funkcji, od monitorowania, alarmowania, automatycznego przełączania awaryjnego, tworzenia kopii zapasowych, przywracania do określonego punktu w czasie, weryfikacji kopii zapasowych, po skalowanie odczytanych replik. Może to pomóc w skalowaniu bazy danych PostgreSQL w sposób poziomy lub pionowy z przyjaznego i intuicyjnego interfejsu użytkownika.