W naszych poprzednich blogach na temat chmury hybrydowej często wspominaliśmy, że jedną z podstawowych opcji korzystania z konfiguracji topologii chmury hybrydowej jest użycie jej jako celu odzyskiwania po awarii. Często zdarza się, że w strukturze organizacyjnej plan odzyskiwania po awarii (DRP) jest zawsze rozpatrywany przed wdrożeniem architektury konfiguracji bazy danych, zarówno w chmurze, jak i lokalnie. Możesz pomyśleć, że wszystko zawiedzie w nieprzewidywalny sposób i może wpłynąć tragicznie na Twój biznes, jeśli nie zostanie odpowiednio zaadresowane i zrozumiane. Pokonanie tych wyzwań wymaga skutecznego planu DRP (Disaster Recovery Plan), dla którego system jest dobrze skonfigurowany zgodnie z wymaganiami aplikacji, infrastruktury i firmy. Kluczem do sukcesu w tego typu sytuacjach jest szybkość, z jaką możemy naprawić lub usunąć problem.
Podczas gdy DRP zajmuje się okolicznościami katastrofy, ciągłość biznesowa zapewnia, że DRP jest testowane i działa przez cały czas, gdy jest to konieczne. Opcje odzyskiwania po awarii dla baz danych muszą zapewniać ciągłość działania i ograniczać oczekiwania. Musi być zgodny z żądanym RTO i RPO. Konieczne jest zapewnienie dostępności produkcyjnych baz danych dla aplikacji nawet podczas awarii; w przeciwnym razie może to być kosztowna transakcja. Administratorzy baz danych, architekci, muszą zapewnić, że środowiska baz danych są w stanie wytrzymać awarie i są zgodne z umową SLA odzyskiwania po awarii. Wdrożenia baz danych muszą być poprawnie skonfigurowane, aby zapewnić, że awarie nie wpłyną na dostępność bazy danych i ciągłość biznesową.
Opcje odzyskiwania po awarii
Twój klaster PostgreSQL musi być skonfigurowany w sposób systematyczny, zgodny z najlepszymi praktykami i zgodny ze standardami branżowymi. Wraz z systematycznymi podejściami, następujące procesy lub mechanizmy pomagają zapewnić, że Twój PostgreSQL wdrożony w chmurze hybrydowej ma następujące elementy:
-
Przełączanie awaryjne/przełączanie
-
Automatyczna kopia zapasowa
-
Wysoce dostępne
-
Równoważenie obciążenia
-
Wysoce rozproszone środowisko
Przełączanie awaryjne/przełączanie
Przełączanie awaryjne to zautomatyzowany proces na wypadek awarii głównego urządzenia; albo serwer gorącej rezerwy, albo serwer gorącej rezerwy jest promowany do roli serwera podstawowego/nadrzędnego. Najlepszym rozwiązaniem, które zapewnia środowisku o wysokiej dostępności, jest posiadanie co najmniej drugiego węzła, który będzie działał jako kandydat na węzeł awaryjny. Gdy serwer główny ulegnie awarii, serwer rezerwowy powinien rozpocząć procedury przełączania awaryjnego, a następnie serwer pomocniczy lub serwer rezerwowy przejmie rolę serwera głównego. System przełączania awaryjnego w powszechnej praktyce wykorzystuje co najmniej dwa serwery, które służą jako serwer podstawowy i rezerwowy. Sprawdzanie łączności jest wspomagane przez mechanizm pulsu, który wykonuje ciągłe kontrole i weryfikuje, czy oba są w dobrym stanie, a komunikacja jest aktywna. Jednak w niektórych przypadkach łączność może wywołać fałszywy alarm. Dlatego w niektórych konfiguracjach i środowiskach obecność trzeciego systemu, takiego jak węzeł monitorowania, znajduje się w oddzielnej sieci lub centrum danych. Jest to niezawodna opcja zapobiegająca niewłaściwemu lub niechcianemu przełączaniu awaryjnemu. Niezawodny węzeł weryfikacyjny może posiadać dodatkowe funkcje i kontrole, co zwiększa złożoność. Ta konfiguracja wymaga pełnego i rygorystycznego testowania, aby upewnić się, że przełączanie awaryjne jest wykonywane prawidłowo, gdy nastąpi zmiana w implementacji. Jest to również ważne, aby zapobiec pogorszeniu się PostgreSQL
Załóżmy, że masz klaster pomocniczy lub rezerwowy w innym centrum danych z inną konfiguracją sprzętu; możesz nie chcieć nagle przełączać się w tryb awaryjny, zwłaszcza jeśli nie jest to idealny przypadek z powodu fałszywego alarmu. Jednak w tym scenariuszu węzeł lub klaster docelowy odzyskiwania danych musi mieć te same zasoby i specyfikacje, co węzeł lub klaster podstawowy. Jeśli Twój cel odzyskiwania danych znajduje się w chmurze publicznej, a podstawowy jest lokalny, upewnij się, że został już uwzględniony w planowaniu pojemności, a zasoby mają prawie takie same specyfikacje, aby uniknąć niepożądanych wyników.
Kiedy wykorzystujesz i przygotowujesz się do swojego mechanizmu przełączania awaryjnego w klastrze PostgreSQL w chmurze hybrydowej, musisz upewnić się, że Twoje narzędzie jest idealnie dopasowane do wykonania zadania, które ma osiągnąć. Istnieją narzędzia innych firm, które nie są dołączone do PostgreSQL w odniesieniu do zaawansowanego przełączania awaryjnego. Na przykład jest ClusterControl, pg_auto_failover firmy CitusData (c/o Microsoft), Pgpool-II, Bucardo i inne. Te zaawansowane narzędzia użytkowe zapewniają ogrodzenie węzłów lub znane jako STONITH (strzelanie drugiego węzła w głowę). Gwarantuje to, że uszkodzony węzeł główny lub główny będzie unikać przyjmowania zapisów lub powrotu online do poprzedniego stanu w celu obsługi normalnych transakcji. Ten problem jest powszechnie znany jako scenariusz z rozszczepionym mózgiem. Traci synchronizację danych z powodu awarii (na poziomie sprzętu lub zasobów), ale nadal serwery główne, które podobno są tylko jednym serwerem głównym, działają tak, jak gdyby normalni odbiorcy żądali zapisu danych, powodując uszkodzenie danych w całym klastrze.
Automatyczna kopia zapasowa
Kopie zapasowe zawsze zapewniają wysoki poziom pewności i zabezpieczenia przed utratą danych. Kopia zapasowa maksymalizuje RPO, ponieważ pomaga zminimalizować utratę danych w przypadku awarii. Rzeczy, które należy wziąć pod uwagę i przygotować do automatycznego tworzenia kopii zapasowych, obejmują urządzenie/sprzęt do tworzenia kopii zapasowych, nadmiarowość danych kopii zapasowej, bezpieczeństwo, wydajność, szybkość i przechowywanie danych.
Urządzenie do tworzenia kopii zapasowych
Tutaj musisz mieć najlepszy wybór dla swojego urządzenia do tworzenia kopii zapasowych. Szybkość, znaczna pojemność pamięci i wysoka dostępność mogą być Twoim pożądanym wyborem. Niektórzy polegają na pamięci masowej SAN lub NAS lub rozpowszechniają swoje dane innym zewnętrznym dostawcom przechowywania kopii zapasowych. Bardzo ważne jest, aby urządzenie do tworzenia kopii zapasowych zapewniało szybkość zapisu i odczytu danych, zwłaszcza jeśli stosujesz kompresję i szyfrowanie danych w spoczynku. Dekompresja i deszyfrowanie wymagają zasobów, więc musisz rozważyć, kiedy musisz skorzystać z odzyskiwania danych. W tym stanie musisz ustalić, że musisz osiągnąć maksymalny RPO i przekazać swoim klientom osiągalną SLA (Umowę dotyczącą poziomu usług). Idealnym rozwiązaniem może być również odizolowanie kopii zapasowej od sieci lokalnej lub przechowywanie jej w lokalizacji zdalnej. Alternatywnym podejściem jest nawiązanie współpracy z dostawcami zewnętrznymi. Na przykład przechowywanie kopii zapasowej w chmurze może być opcją, a ich obiekt jest bardzo wyrafinowany i spełnia Twoje wymagania.
Nadmiarowość danych kopii zapasowych
Rozpowszechnianie danych w wielu lokalizacjach to idealne rozwiązanie. Zwiększa to szanse na odzyskanie danych, na przykład błąd ludzki lub błąd logiczny oprogramowania powodujący usunięcie starych kopii zapasowych, ale omyłkowo usunięcie wszystkich kluczowych kopii zapasowych. W niektórych wyrafinowanych środowiskach, takich jak przechowywanie w środowisku chmurowym, takim jak Amazon S3, Cloud Storage firmy Google lub Azure Blob Storage, oferuje replikację przechowywanych plików. Zapewnia to większą redundancję i może być konfigurowane w elastyczny sposób, który pasuje do Twoich wymagań.
Wysoce dostępne
Wysoce dostępny klaster PostgreSQL w chmurze hybrydowej zawsze zapewnia, że komunikacja z bazą danych zapewnia nieprzerwaną pracę. Idealny przypadek wysokiej dostępności zależy od pomiaru Twojej dostępności. W takim przypadku typową konfiguracją dla PostgreSQL wdrożonego w chmurze hybrydowej może być baza danych hostowana w chmurze publicznej lub klaster drugorzędny działający jako klaster odzyskiwania danych w przypadku awarii klastra podstawowego lub awarii sieci i może trwać dużo przestojów. W niektórych konfiguracjach możliwe jest, że klaster dodatkowy znajdujący się w chmurze publicznej może nie być dokładnie tak wyrafinowany jak podstawowy, powiedzmy, że jest to Twoja chmura lokalna lub prywatna. Twoja aplikacja może się bawić, aby ograniczyć odwiedzających lub ruch, który może łączyć się z Twoją bazą danych. Ten typ scenariusza może obniżyć koszty instalacji, ale oczywiście zależy to tylko od twoich wymagań. Jeśli typ Twojej aplikacji jest ogromny i musi nieprzerwanie otrzymywać od normalnych do zajętych sytuacji ruchu, upewnij się, że zasoby klastra dodatkowego muszą być tak samo wydajne, jak podstawowe, aby zapewnić wysoką dostępność, tj. 99,9999999%.
Aby uzyskać wysoce dostępny klaster PostgreSQL w środowisku chmury hybrydowej, musisz mieć mechanizm przełączania awaryjnego. W przypadku awarii i awarii głównego klastra lub serwera głównego, serwer pomocniczy lub rezerwowy może przejąć rolę mastera, niezależnie od jego lokalizacji. Najważniejszą rzeczą jest funkcjonalność, a wydajność, zwłaszcza z punktu widzenia aplikacji lub klienta, nie ma żadnego wpływu lub przynajmniej jest bardzo minimalna.
Równoważenie obciążenia
Mechanizm równoważenia obciążenia dla klastra PostgreSQL pomaga w konfiguracji chmury hybrydowej, która jest łatwiejsza w zarządzaniu i mniej ryzykowna, zwłaszcza gdy występuje duże obciążenie ruchem. W wielu sytuacjach serwer otrzymuje bardzo duże obciążenie, powodując panikę serwera. Prowadzi to do stanu bezużytecznego serwera z powodu zajętych zasobów zużywanych przez wiele wątków działających w tle. Sytuację tę można poprawić, naprawiając złe zapytania i architekturę projektu Twojej bazy danych. Powinno to obejmować sposób rozkładania odczytu na obciążenie zapisu i dogłębne zrozumienie wymagań aplikacji, takich jak konfiguracja master-master lub tylko jeden master, ale skalowanie go w pionie w celu zapewnienia większych zasobów obliczeniowych i pamięci. Dostępny jest również szeroki wybór narzędzi innych firm, takich jak pgbouncer i Pgpool II, które pomogą we wdrożeniu PostgreSQL w środowisku chmury hybrydowej.
Wysoce rozproszone środowisko
Pod względem skalowalności, wysoka dystrybucja w wielu lokalizacjach lub różnych dostawcach chmury (chmura lokalna lub prywatna i publiczna) zapewnia większą elastyczność i tolerancję w środowisku chmury hybrydowej, co doskonale nadaje się do odzyskiwania po awarii. Jest elastyczny, gdy konieczne jest przełączenie awaryjne w określonej lokalizacji w chmurze sprzyjającej klęskom żywiołowym lub katastrofie, zwłaszcza jeśli wyznaczony region, w którym znajduje się klaster podstawowy, jest obecnie zdewastowany lub dotknięty przyczyną naturalną. Jest to nieunikniona przyczyna, którą musisz zrozumieć i być wiarygodnym w obecnej sytuacji. Twoja aplikacja i klienci muszą być obsługiwani bez przerwy. Służy to temu, aby być publicznie dostępnym w chmurze, a jednocześnie służyć w środowisku prywatnym lub lokalnym. Taka konfiguracja zwiększa złożoność i wymaga zaawansowanej wiedzy po stronie bazy danych oraz bezpieczeństwa i sieci. Optymalizacja i dostrajanie są tutaj kluczowe dla sukcesu, ponieważ bardzo ważne jest, aby zapewniając zaostrzone zabezpieczenia w celu enkapsulacji danych podczas podróży w Internecie, należy udowodnić, że wydajność się stabilizuje i nie ma na nią wpływu wdrożona konfiguracja.
Ze względu na złożoność konfiguracji posiadanie narzędzia jest idealne do zarządzania wdrożeniem i ułatwienia ogólnego stanu baz danych, nadzorując jeden aspekt klastra, ale na całym poziomie z lokalnej chmury prywatnej, oraz w aspekcie chmury publicznej. Wszystkie konfiguracje muszą być utrzymywane na łatwym do zarządzania i prostym poziomie, aby w przypadku alarmów i alertów łatwo było naprawić i rozwiązać problem prawidłowo i na czas.
ClusterControl do odzyskiwania po awarii w hybrydowym środowisku chmury
ClusterControl umożliwia organizacji lub firmom elastyczne zarządzanie bazą danych i zmniejszenie ogólnej złożoności konfiguracji. ClusterControl oferuje przełączanie awaryjne, automatyczne tworzenie kopii zapasowych, zapewnia wysoce dostępną konfigurację, równoważenie obciążenia i obsługuje wdrażanie środowiska rozproszonego, ułatwiając dodawanie węzłów w chmurze publicznej, prywatnej lub lokalnej.
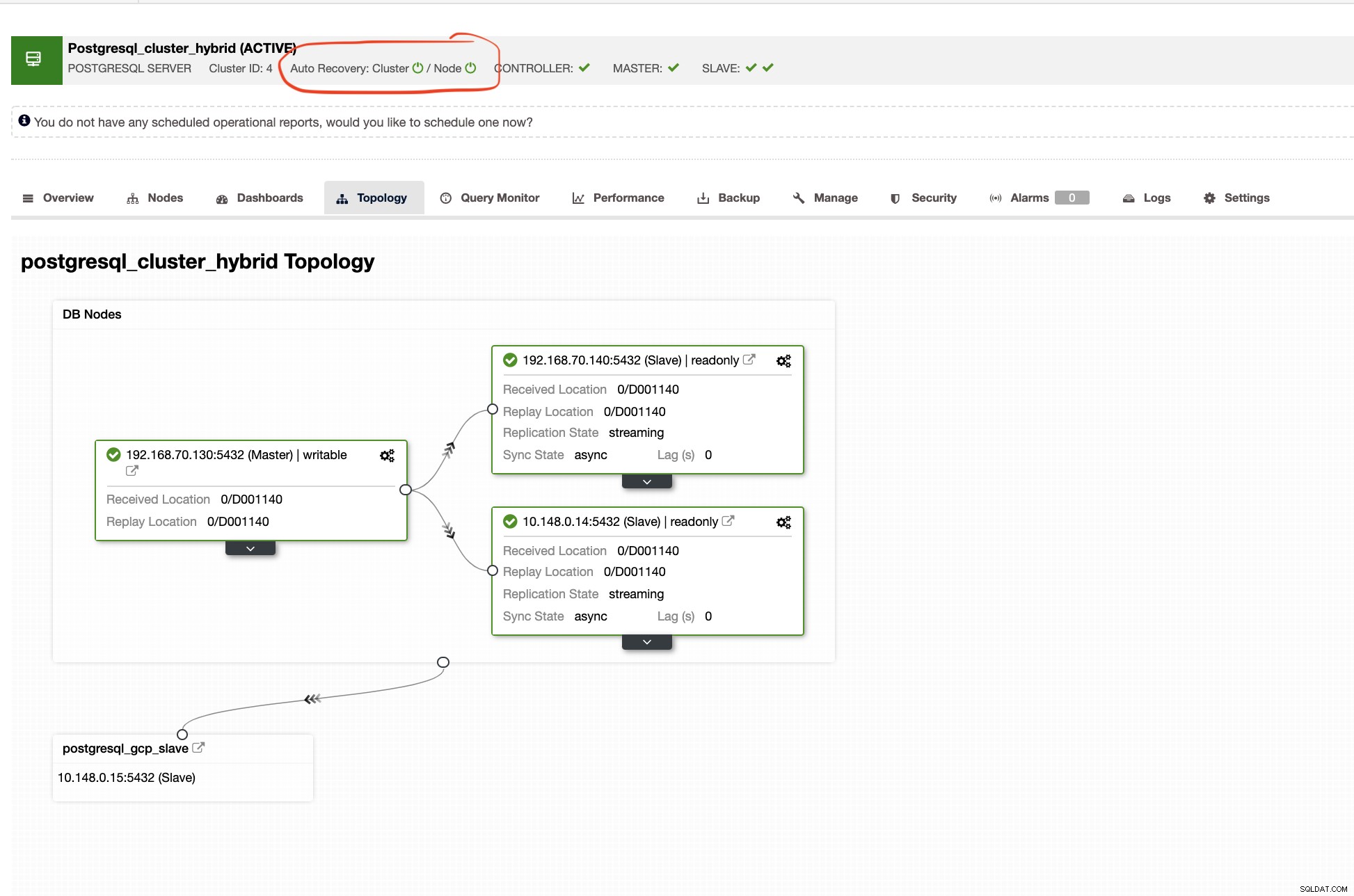
Automatyczne przywracanie programu ClusterControl
Automatyczne przywracanie ClusterControl reprezentuje mnóstwo mechanizmów przełączania awaryjnego i charakterystyk przywracania, zwłaszcza gdy węzeł przestaje działać lub klaster przechodzi w stan zdegradowany. Można to łatwo zrobić, jak pokazano na poniższym zrzucie ekranu:
Kopia zapasowa i przywracanie
ClusterControl ma również funkcję tworzenia kopii zapasowych i przywracania, która umożliwia zarządzanie kopią zapasową, tworzenie kopii zapasowej, planowanie tworzenia kopii zapasowej i przywracanie kopii zapasowej. Zarządzanie kopią zapasową jest bardzo proste, a tworzenie lub planowanie kopii zapasowej jest proste, ale oferuje również zaawansowane opcje. Oferuje również opcje tworzenia kopii zapasowych w chmurze, które zapewniają nadmiarowość danych kopii zapasowych, wzmacniając opcje odzyskiwania po awarii. Zobacz poniżej:
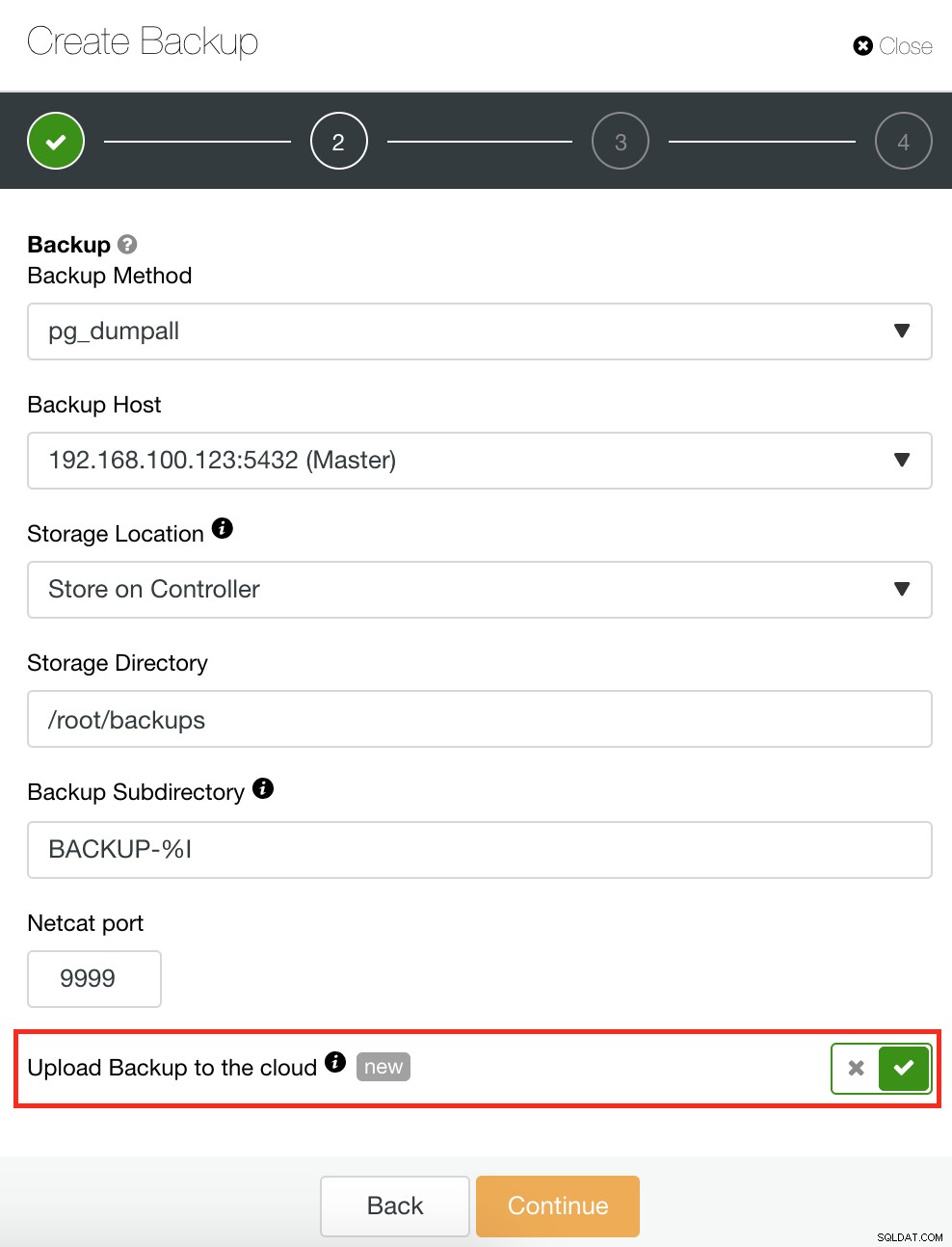
Jak pokazano poniżej, zarządzanie kopią zapasową zapewnia prosty interfejs użytkownika umożliwiający wybór kopii zapasowej, którą chcesz przywrócić lub którą możesz usunąć. Kopia zapasowa ClusterControl pozwala wybrać okres przechowywania, więc w przypadku długiej listy niektóre z nich można usunąć po osiągnięciu okresu przechowywania. 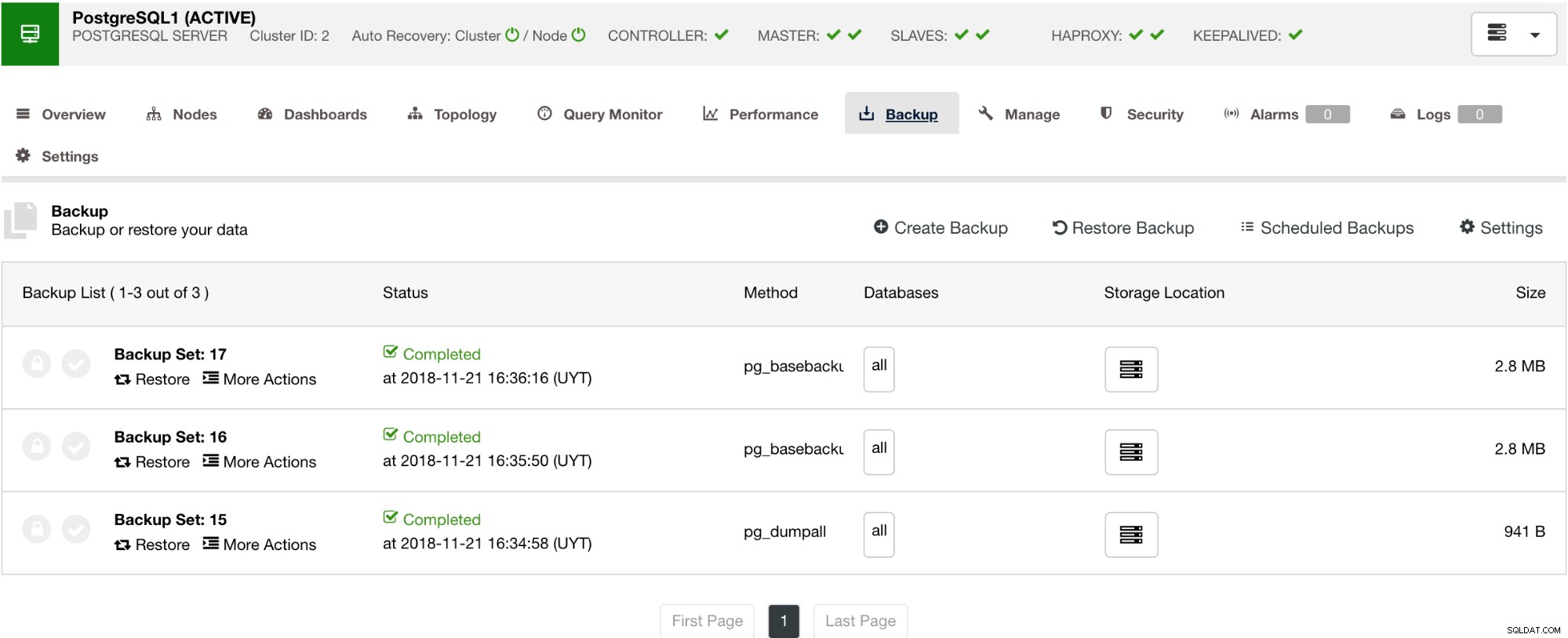
Obsługuje mechanizmy wysokiej dostępności (HA) i równoważenia obciążenia (LB)
Nie musisz konfigurować ręcznie ani nawet szukać sposobów na dodanie wysokiej dostępności w swoim klastrze PostgreSQL. ClusterControl zapewnia łatwy i wygodny sposób na wykonanie pracy. Jeśli widzisz przykładowy zrzut ekranu, ma on konfigurację HAProxy i Keepalive. Zobacz zrzut ekranu poniżej:
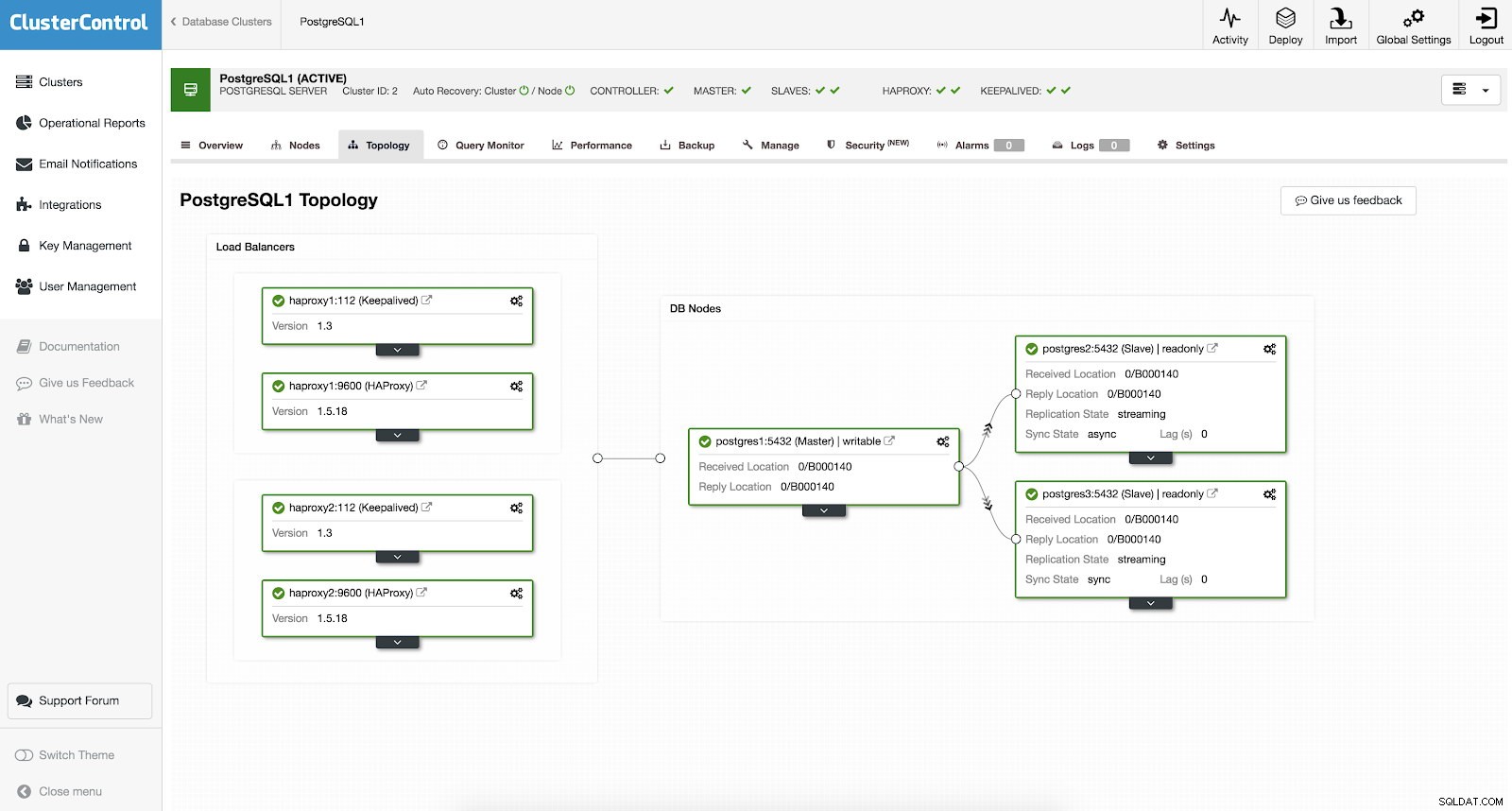
Ustawienie wysokiej dostępności za pomocą ClusterControl można wykonać, przechodząc przez
Obsługuje środowisko rozproszone
Jeśli chcesz, aby dystrybucje były równomiernie rozprowadzane z chmury lokalnej lub prywatnej do chmury publicznej, ClusterControl obsługuje również wdrażanie w chmurze. Ale w przypadku klastra PostgreSQL i planujesz mieć drugorzędne urządzenie podrzędne znajdujące się w innej chmurze, możesz utworzyć klaster podrzędny, jak pokazano poniżej,
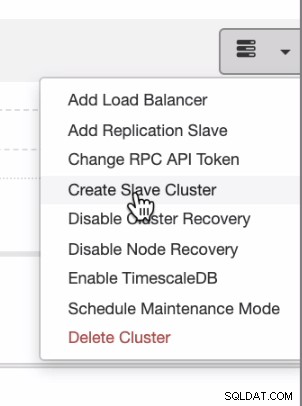
i możesz dotrzeć z wynikiem końcowym, jak pokazano poniżej,

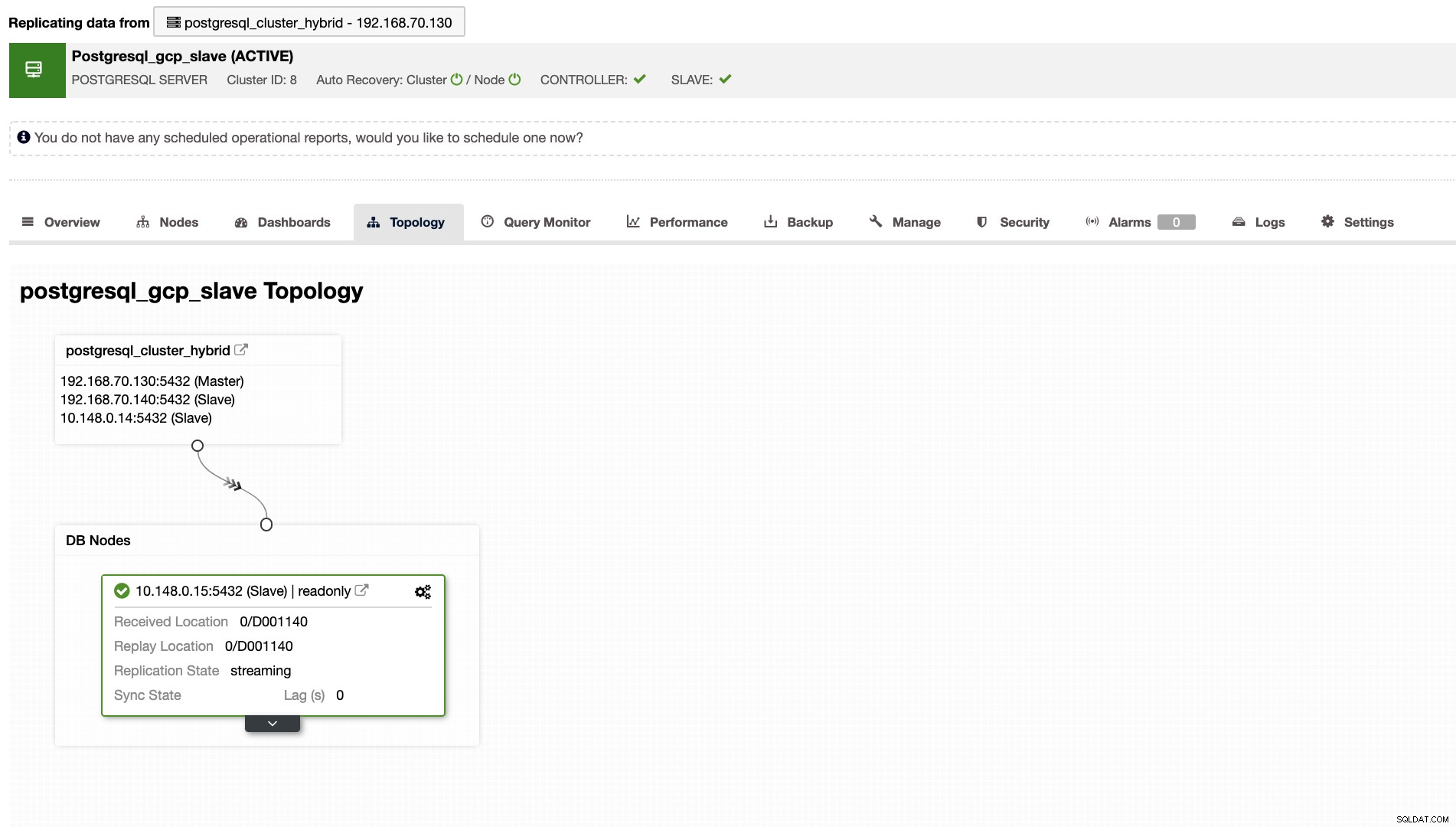
ClusterControl pokaże również właściwą topologię klastra zawsze, gdy masz skonfigurowane środowisko chmury hybrydowej. Zobacz poniżej,
Podczas gdy w klastrze podrzędnym topologia pokaże swoje drzewo pochodzenia, ujawniając swojego nadrzędnego. Tutaj urządzenie podrzędne pokazuje się, ponieważ znajduje się w oddzielnej sieci znajdującej się głównie w Google Cloud, podczas gdy urządzenie główne jest lokalne.
Wnioski
Dopuszcza się przyznanie, że konfiguracja chmury hybrydowej, zwłaszcza z klastrem PostgreSQL, zwiększa złożoność. Musisz mieć odpowiednie narzędzie z dostępnymi opcjami, aby wesprzeć planowanie odzyskiwania po awarii. Są one bardzo ważne, aby uratować i uniknąć potencjalnej katastrofy finansowej i utraty zaufania klientów. Zainwestuj w odpowiednie narzędzia i umiejętności swojej technologii, a uratujesz swoją firmę przed negatywnym wpływem.