Problem
W tym artykule skupimy się na demonstracji partycjonowania tabel. Najprostsze wyjaśnienie partycjonowania tabel można nazwać dzieleniem dużych tabel na małe. Ten temat zapewnia skalowalność i łatwość zarządzania.
Co to jest partycjonowanie tabel w SQL Server?
Załóżmy, że mamy stół i z dnia na dzień rośnie. W takim przypadku tabela może powodować pewne problemy, które należy rozwiązać, wykonując poniższe czynności:
- Utrzymuj ten stół. Zajmie to dużo czasu i zużyje więcej zasobów (procesor, IO itp.).
- Utwórz kopię zapasową.
- Problemy z blokadą.
Z wyżej wymienionych powodów potrzebujemy partycjonowania tabeli. Takie podejście ma następujące zalety:
- Możliwości zarządzania:Jeśli podzielimy tabelę, możemy zarządzać każdą partycją tabeli. Na przykład możemy utworzyć tylko jedną partycję tabeli.
- Możliwość archiwizacji:Niektóre partycje tabeli są używane tylko z tego powodu. Nie musimy tworzyć kopii zapasowej tej partycji tabeli. Możemy użyć kopii zapasowej grupy plików i wykonać kopię zapasową tylko poprzez zmianę partycji tabeli.
- Wydajność zapytań:Optymalizator zapytań SQL Server decyduje się na użycie eliminacji partycji. Oznacza to, że SQL Server nie szuka niepowiązanej partycji tabeli.
Pionowe i poziome partycjonowanie tabel w SQL Server
Partycjonowanie tabel to ogólna koncepcja. Istnieje kilka typów partycjonowania, które działają w określonych przypadkach. Najbardziej istotne i powszechnie stosowane są dwa podejścia:partycjonowanie pionowe i partycjonowanie poziome.
Specyfika każdego typu odzwierciedla istotę tabeli jako struktury składającej się z kolumn i wierszy:
• Partycjonowanie pionowe dzieli tabelę na kolumny.
• Podział poziomy dzieli tabelę na rzędy.
Najbardziej typowym przykładem podziału tabeli pionowej jest tabela pracowników z ich danymi — nazwiskami, e-mailami, numerami telefonów, adresami, datami urodzin, zawodami, pensjami i wszystkimi innymi informacjami, które mogą być potrzebne. Część takich danych jest poufna. Poza tym w większości przypadków operatorzy potrzebują tylko podstawowych danych, takich jak nazwiska i adresy e-mail.
Podział pionowy tworzy kilka „węższych” tabel z niezbędnymi danymi. Zapytania dotyczą tylko określonej części. W ten sposób firmy zmniejszają obciążenie, przyspieszają zadania i zapewniają, że poufne dane nie zostaną ujawnione.
Podział tabeli poziomej powoduje podzielenie jednej ogólnej tabeli na kilka mniejszych, gdzie każda tabela cząstek ma taką samą liczbę kolumn, ale liczbę wierszy jest mniej. Jest to standardowe podejście do nadmiernych tabel z danymi chronologicznymi.
Na przykład tabelę z danymi za cały rok można podzielić na mniejsze sekcje dla każdego miesiąca lub tygodnia. Wówczas zapytanie będzie dotyczyło tylko jednej określonej mniejszej tabeli. Partycjonowanie poziome poprawia skalowalność wolumenów danych wraz z ich wzrostem. Podzielone na partycje tabele pozostaną mniejsze i łatwe do przetworzenia.
Wszelkie partycjonowanie tabel w serwerze SQL należy traktować z ostrożnością. Czasami musisz zażądać danych z kilku podzielonych na partycje tabel naraz, a następnie będziesz potrzebować JOIN w zapytaniach. Poza tym podział pionowy może nadal skutkować dużymi tabelami i będziesz musiał je bardziej podzielić. W swojej pracy powinieneś polegać na decyzjach dotyczących konkretnych celów biznesowych.
Teraz, gdy wyjaśniliśmy koncepcję partycjonowania tabel w SQL Server, nadszedł czas, aby przejść do demonstracji.
Zamierzamy uniknąć wszelkich skryptów T-SQL i obsłużymy wszystkie etapy partycjonowania tabeli za pomocą kreatora partycjonowania SQL Server.
Czego potrzebujesz do tworzenia partycji bazy danych SQL?
- Przykładowa baza danych WideWorldImporters
- SQL Server 2017 Developer Edition
Poniższy obraz pokazuje nam, jak zaprojektować partycję tabeli. Utworzymy partycję tabeli według lat i zlokalizujemy różne grupy plików.

Na tym etapie utworzymy dwie grupy plików (FG_2013, FG_2014). Kliknij prawym przyciskiem myszy bazę danych, a następnie kliknij kartę Grupy plików.

Teraz połączymy grupy plików z nowymi plikami pdf.

Nasza struktura przechowywania bazy danych jest gotowa do partycjonowania tabel. Zlokalizujemy tabelę, którą chcemy podzielić na partycje i uruchomimy kreatora tworzenia partycji.


Na poniższym zrzucie ekranu wybierzemy kolumnę, na której chcemy zastosować funkcję partycji. Wybrana kolumna to „Data faktury”.

Na następnych dwóch ekranach nazwiemy funkcję partycji i schemat partycji.
Funkcja partycjonowania określi sposób podziału wierszy [Sprzedaż].[Faktury] na podstawie kolumny Data faktury.

Schemat partycji zdefiniuje mapowanie wierszy Sales.Invoices na grupy plików.

Przypisz partycje do grup plików i ustaw granice.
Lewa/prawa granica określa stronę każdego przedziału wartości granicznej, która może być lewa lub prawa. Ustawimy takie granice i klikniemy Oszacuj pamięć. Ta opcja dostarcza nam informacji o liczbie wierszy, które mają znajdować się w granicach.

I na koniec wybierzemy Uruchom natychmiast, a następnie klikniemy Dalej.

Gdy operacja się powiedzie, kliknij Zamknij.

Jak widać, nasza tabela Sales.Invoices została podzielona na partycje. To zapytanie pokaże szczegóły partycjonowanej tabeli.
SELECT
OBJECT_SCHEMA_NAME(pstats.object_id) AS SchemaName
,OBJECT_NAME(pstats.object_id) AS TableName
,ps.name AS PartitionSchemeName
,ds.name AS PartitionFilegroupName
,pf.name AS PartitionFunctionName
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Range Left' ELSE 'Range Right' END AS PartitionFunctionRange
,CASE pf.boundary_value_on_right WHEN 0 THEN 'Upper Boundary' ELSE 'Lower Boundary' END AS PartitionBoundary
,prv.value AS PartitionBoundaryValue
,c.name AS PartitionKey
,CASE
WHEN pf.boundary_value_on_right = 0
THEN c.name + ' > ' + CAST(ISNULL(LAG(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' <= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100))
ELSE c.name + ' >= ' + CAST(ISNULL(prv.value, 'Infinity') AS VARCHAR(100)) + ' and ' + c.name + ' < ' + CAST(ISNULL(LEAD(prv.value) OVER(PARTITION BY pstats.object_id ORDER BY pstats.object_id, pstats.partition_number), 'Infinity') AS VARCHAR(100))
END AS PartitionRange
,pstats.partition_number AS PartitionNumber
,pstats.row_count AS PartitionRowCount
,p.data_compression_desc AS DataCompression
FROM sys.dm_db_partition_stats AS pstats
INNER JOIN sys.partitions AS p ON pstats.partition_id = p.partition_id
INNER JOIN sys.destination_data_spaces AS dds ON pstats.partition_number = dds.destination_id
INNER JOIN sys.data_spaces AS ds ON dds.data_space_id = ds.data_space_id
INNER JOIN sys.partition_schemes AS ps ON dds.partition_scheme_id = ps.data_space_id
INNER JOIN sys.partition_functions AS pf ON ps.function_id = pf.function_id
INNER JOIN sys.indexes AS i ON pstats.object_id = i.object_id AND pstats.index_id = i.index_id AND dds.partition_scheme_id = i.data_space_id AND i.type <= 1 /* Heap or Clustered Index */
INNER JOIN sys.index_columns AS ic ON i.index_id = ic.index_id AND i.object_id = ic.object_id AND ic.partition_ordinal > 0
INNER JOIN sys.columns AS c ON pstats.object_id = c.object_id AND ic.column_id = c.column_id
LEFT JOIN sys.partition_range_values AS prv ON pf.function_id = prv.function_id AND pstats.partition_number = (CASE pf.boundary_value_on_right WHEN 0 THEN prv.boundary_id ELSE (prv.boundary_id+1) END)
WHERE pstats.object_id = OBJECT_ID('Sales.Invoices')
ORDER BY TableName, PartitionNumber;

MS Wydajność partycjonowania SQL Server
Porównamy wydajność tabel partycjonowanych i niepartycjonowanych dla tej samej tabeli. Aby to zrobić, użyj poniższego zapytania i aktywuj Dołącz rzeczywisty plan wykonania.
DECLARE @Dt as date = '20131231'
SELECT COUNT(InvoiceDate)
FROM [Sales].[Invoices]
where InvoiceDate < @Dt


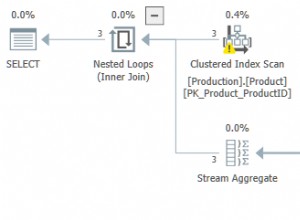
Kiedy badamy plan wykonania, dowiadujemy się, że zawiera on właściwości „Podział na partycje”, „Rzeczywista liczba partycji” i „Rzeczywisty dostęp do partycji”.
Właściwość partycjonowana wskazuje, że ta tabela jest włączona dla partycji.
Rzeczywista liczba partycji właściwość to całkowita liczba partycji, które są odczytywane przez silnik SQL Server.
Rzeczywisty dostęp do partycji właściwość to numery partycji oceniane przez silnik SQL Server. SQL Server eliminuje dostęp do innych partycji, ponieważ nazywa się to eliminacją partycji i zyskuje przewagę pod względem wydajności zapytań.
Teraz spójrz na plan wykonania tabeli bez partycji.

Główna różnica między tymi dwoma planami wykonania to Liczba odczytanych wierszy ponieważ ta właściwość wskazuje, ile wierszy jest odczytywanych dla tego zapytania. Jak widać na poniższym wykresie kompresji, wartości tabeli partycjonowanej są zbyt niskie. Z tego powodu będzie zużywać niskie IO.

Następnie uruchom zapytanie i sprawdź plan wykonania.
DECLARE @DtBeg as date = '20140502'
DECLARE @DtEnd as date = '20140701'
SELECT COUNT(InvoiceDate)
FROM [Sales].[Invoices]
where InvoiceDate between @DtBeg and @DtEnd

Eskalacja blokady na poziomie partycji
Eskalacja blokady to mechanizm używany przez SQL Server Lock Manager. Organizuje blokowanie poziomu obiektów. Gdy liczba wierszy do zablokowania wzrasta, menedżer blokad zmienia obiekt blokujący. Jest to poziom hierarchii eskalacji blokad „Wiersz -> Strona -> Tabela -> Baza danych”. Ale w tabeli partycjonowanej możemy zablokować jedną partycję, ponieważ zwiększa to współbieżność i wydajność. Domyślny poziom eskalacji blokady to „TABELA” w SQL Server.
Wykonaj zapytanie za pomocą poniższej instrukcji UPDATE.
BEGIN TRAN
DECLARE @Dt as date = '20131221'
UPDATE [Sales].[Invoices] SET CreditNoteReason = 'xxx' where InvoiceDate < @Dt
SP_LOCK

Czerwone pole definiuje blokadę na wyłączność, która zapewnia, że nie można jednocześnie dokonać wielu aktualizacji tego samego zasobu. Występuje w tabeli Faktury.
Teraz ustawimy tryb eskalacji dla tabeli Sales.Invoices, aby ją zautomatyzować i ponownie uruchomić zapytanie.
ALTER TABLE Sales.Invoices SET (LOCK_ESCALATION = AUTO)
Teraz czerwone pole definiuje wcięcie blokady na wyłączność, która chroni żądane lub nabyte blokady na wyłączność na niektórych zasobach znajdujących się niżej w hierarchii. Krótko mówiąc, ten poziom blokady pozwala nam aktualizować lub usuwać inne partycje tabel. Oznacza to, że możemy rozpocząć kolejną aktualizację lub wstawić inną partycję tabeli.
W poprzednich postach zbadaliśmy również kwestię przełączania między partycjonowaniem tabel i udostępniliśmy przewodnik. Informacje te mogą być dla Ciebie pomocne, jeśli zajmujesz się takimi przypadkami. Zapoznaj się z artykułem, aby uzyskać więcej informacji.
Referencje
- Tryby blokady
- Tabele i indeksy partycjonowane