PostgreSQL, czwarta najpopularniejsza baza danych i DBMS roku 2017, zyskała na popularności wśród społeczności programistów i baz danych na całym świecie. Kradnąc udział w rynku od liderów Oracle, MySQL i Microsoft SQL Server, hosting PostgreSQL jest również w dużym stopniu wykorzystywany przez nowe firmy w ekscytujących obszarach, takich jak IoT, e-commerce, SaaS, analityka i nie tylko.
Co zatem zyskuje popularność w zarządzaniu PostgreSQL?
W zeszłym miesiącu wzięliśmy udział w PostgresOpen w San Francisco, aby odkryć najnowsze trendy od samych ekspertów.
Najbardziej czasochłonne zadania zarządzania PostgreSQL
Co więc pochłania Twój czas na froncie zarządzania PostgreSQL? Chociaż zarządzanie wdrożeniami produkcyjnymi PostgreSQL wiąże się z tysiącami zadań, zarządzanie zapytaniami było silnym liderem z ponad 30% respondentów.
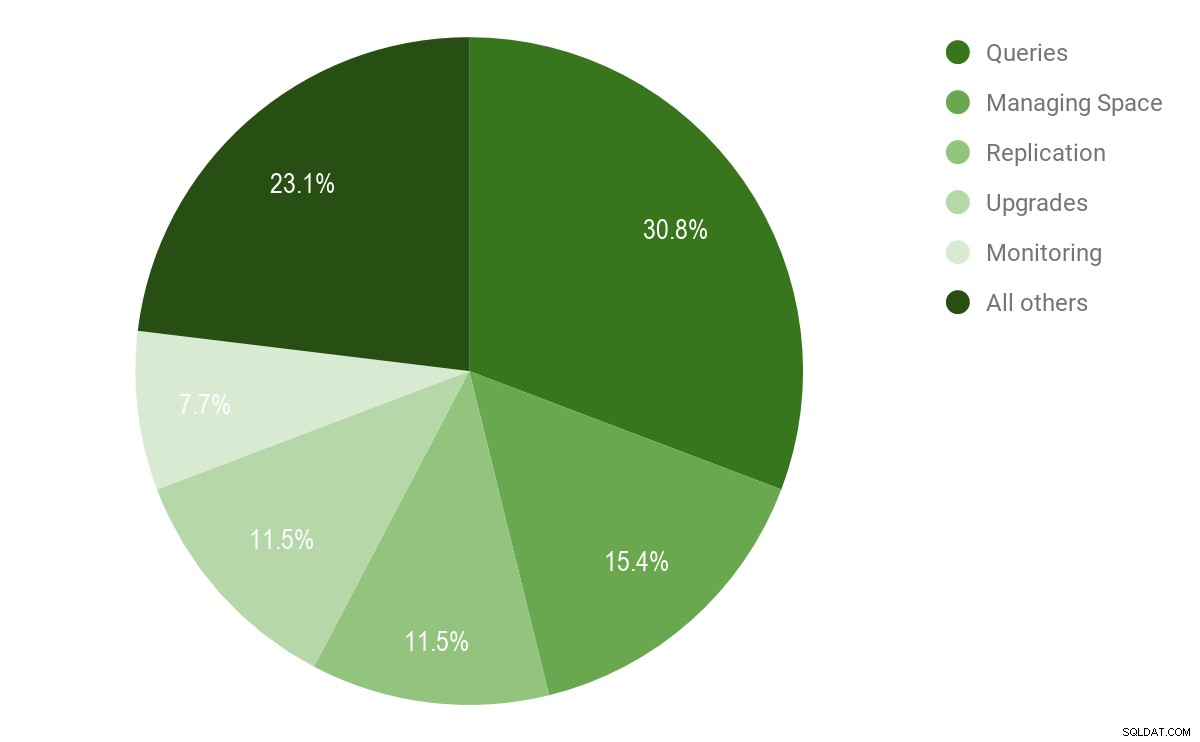
Zarządzanie przestrzenią było odległą sekundą, a 15% użytkowników PostgreSQL uznało to za najtrudniejsze zadanie, a następnie replikację, aktualizacje i monitorowanie. 23% użytkowników PostgreSQL znalazło się w kategorii „Wszyscy inni”, na którą składają się zadania takie jak łatanie, odzyskiwanie, partycjonowanie i migracje.
Zarządzanie podziałem zapytań PostgreSQL
Z dużą przewagą w zarządzaniu zapytaniami PostgreSQL, zagłębiliśmy się, aby zobaczyć, jakie konkretne zadania pochłaniały ich czas. Wyniki rozłożone są na cały proces zarządzania zapytaniami, od strukturyzacji podczas konfiguracji po optymalizację po analizie.

Aby wyjaśnić to dokładniej, zacznijmy od początku procesu zarządzania zapytaniami:
Struktura zapytania
Najmniejszy segment, zarządzający strukturami zapytań, stanowił 22% odpowiedzi od użytkowników PostgreSQL, którzy wybrali zapytania jako swoje najbardziej czasochłonne zadanie zarządzania.
Przed rozpoczęciem należy utworzyć plan zapytań PostgreSQL wokół klastrów, aby dopasować strukturę zapytań do właściwości danych. Składają się one z węzłów, począwszy od węzłów skanowania na dolnym poziomie w celu uzyskania zwrotów nieprzetworzonych wierszy, a także wierszy niebędących tabelami, takich jak wartości.
Analiza powolnych zapytań
Po ustaleniu struktury następnym krokiem jest analiza zapytań w celu zidentyfikowania wolno działających zapytań, które mogą mieć wpływ na wydajność aplikacji. Domyślnie „wolne zapytania” są definiowane jako zapytania, które trwają dłużej niż 100 ms.
Optymalizacja zapytań
Teraz, gdy już zidentyfikowałeś swoje wolne zapytania, zaczyna się prawdziwa praca – optymalizacja zapytań PostgreSQL. Dostrajanie wydajności Postgresa może być makabrycznym zadaniem, ale przy odpowiedniej identyfikacji i analizie możesz skupić się na wąskich gardłach i wprowadzić niezbędne zmiany w zapytaniach oraz dodać indeksy w razie potrzeby, aby poprawić wykonanie. Oto świetny artykuł na temat zapytań dostrajających wydajność w PostgreSQL.
Najnowsze trendy PostgreSQL:najbardziej czasochłonne zadania i ważne dane do śledzenia, kliknij, aby tweetować
Najważniejsze wskaźniki do śledzenia wydajności PostgreSQL
Teraz, gdy zidentyfikowaliśmy najbardziej czasochłonne zadanie zarządzania PostgreSQL, przyjrzyjmy się bliżej ważnym metrykom śledzonym przez użytkowników PostgreSQL w celu optymalizacji ich wydajności.
Najważniejsze wyniki metryk PostgreSQL były znacznie bardziej wyrównane niż zadania zarządzania, co spowodowało czterokierunkowy związek między statystykami replikacji, wykorzystaniem procesora i pamięci RAM oraz transakcjami na sekundę (TPS) i powolne zapytania:

Statystyki replikacji
Monitorowanie stanu replikacji PostgreSQL jest kluczowym zadaniem zapewniającym prawidłowe wykonanie replikacji i wysoką dostępność wdrożeń produkcyjnych. Proces replikacji powinien być dostosowany do potrzeb aplikacji, a ciągłe monitorowanie punktów końcowych to najlepszy sposób na zapewnienie bezpieczeństwa danych i gotowości do odzyskania.
Ważne jest śledzenie metryk zarówno na serwerach rezerwowych, jak i serwerach głównych. Serwery rezerwowe powinny być monitorowane pod kątem przychodzącej replikacji i stanu odzyskiwania, a serwery główne powinny być monitorowane pod kątem wychodzących replikacji i gniazd replikacji. Jeśli używasz replikacji strumieniowej PostgreSQL, gniazda replikacji nie zawsze są wymagane. Replikacja strumieniowa zapewnia natychmiastową dostępność danych na serwerach rezerwowych i jest idealna dla serwerów o niskim TPS.
Wykorzystanie procesora i pamięci RAM
Śledzenie wykorzystania procesora i pamięci RAM (pamięci) to kluczowe wskaźniki do monitorowania, aby zapewnić stan serwerów PostgreSQL. Jeśli użycie procesora jest zbyt wysokie, Twoja aplikacja będzie spowalniać, co ucierpi na użytkownikach. Często jest to wynikiem źle zoptymalizowanych zapytań, a nawet dużej równoległości zapytań. Monitorowanie pamięci RAM jest bardzo ważne, aby zapewnić wystarczającą ilość miejsca na dysku i dokładnie zrozumieć, do czego jest używana pamięć RAM. Zaleca się, aby około 25% pamięci zostało przydzielone na shared_buffers. PostgreSQL domyślnie ustawia również rozmiar bufora pamięci roboczej na 4 MB, co często jest zbyt małe i skutkuje długimi czasami wykonania.
Transakcje na sekundę
Monitorowanie liczby transakcji na sekundę pozwala określić obciążenie systemu i aktualną przepustowość. Analizując tę metrykę, można zdecydować się na odpowiednie skalowanie systemu, aby osiągnąć pożądaną przepustowość. Możesz także określić, w jaki sposób zmiana ustawień konfiguracyjnych lub zasobów systemowych wpływa na przepustowość.
Powolne zapytania
Nieefektywne zapytania mogą spowolnić wydajność PostgreSQL, nawet jeśli system jest skonfigurowany z odpowiednimi zasobami. Zawsze dobrą praktyką jest analizowanie tych nieefektywnych zapytań i ich naprawianie. PostgreSQL udostępnia parametr o nazwie log_min_duration_statement . Ustawienie tej opcji powoduje, że czas trwania każdej ukończonej instrukcji jest rejestrowany, jeśli instrukcja była wykonywana przez co najmniej określoną liczbę milisekund. Po uzyskaniu powolnych zapytań możesz uruchomić ANALIZĘ WYJAŚNIJ, aby zrozumieć plan wykonania. Umożliwi to śledzenie problemu i odpowiednią optymalizację zapytania. Dlatego regularne monitorowanie powolnych zapytań pozwoli uniknąć spadku wydajności.
Znajdź nas w przyszłym tygodniu na wydarzeniu PostgresConf Silicon Valley 2018, gdzie mamy nadzieję odkryć więcej informacji na temat trendów w przestrzeni zarządzania PostgreSQL. Jeśli masz jakieś pytania lub komentarze, podziel się nimi z nami tutaj w naszych komentarzach lub na Twitterze pod adresem @scalegridio.