Jak mogłeś zauważyć na moim poprzednim blogu, ostatnie kilka miesięcy było zajęte aktualizowaniem Postgres-XL do najnowszej wersji PostgreSQL 9.5. Gdy mieliśmy już dość stabilną wersję Postgres-XL 9.5, skierowaliśmy naszą uwagę na pomiar wydajności tej nowej wersji Postgres-XL. Na nasz wybór benchmarku duży wpływ mają trwające prace nad projektem AXLE, finansowanym przez Unię Europejską w ramach umowy o dotację 318633. Ponieważ używamy TPC BENCHMARK™ H do pomiaru wydajności wszystkich innych prac wykonywanych w ramach tego projektu, postanowiliśmy użyj tego samego testu porównawczego do oceny Postgres-XL. Pasuje również do Postgres-XL, ponieważ TPC-H próbuje mierzyć obciążenia OLAP, co Postgres-XL powinien robić dobrze.
1. Konfiguracja klastra Postgres-XL
Po ustaleniu testu porównawczego kolejnym dużym wyzwaniem było znalezienie odpowiednich zasobów do testowania. Nie mieliśmy dostępu do dużego klastra maszyn fizycznych. Więc zrobiliśmy to, co większość by zrobiła. Zdecydowaliśmy się użyć Amazon AWS do konfiguracji klastra Postgres-XL. AWS oferuje szeroką gamę instancji, z których każdy typ oferuje inną moc obliczeniową lub we/wy.
Ta strona w AWS pokazuje różne dostępne typy instancji, dostępne zasoby i ich ceny dla różnych regionów. Należy zauważyć, że ceny i dostępność mogą się różnić w zależności od regionu, dlatego ważne jest, aby sprawdzić wszystkie regiony. Ponieważ Postgres-XL wymaga małych opóźnień i dużej przepustowości między swoimi komponentami, ważne jest również, aby tworzyć instancje w tym samym regionie. W przypadku naszego 3TB TPC-H zdecydowaliśmy się na 16-węzłowy klaster instancji i2.xlarge AWS. Te instancje mają 4 vCPU, 30 GB pamięci RAM i 800 GB dysku SSD, wystarczającą ilość miejsca na przechowywanie wszystkich rozproszonych tabel, zreplikowanych tabel (które zajmują więcej miejsca wraz ze wzrostem rozmiaru klastra), indeksów na nich i nadal pozostawiają wystarczającą ilość wolnego miejsca w tymczasowej przestrzeni tabel dla CREATE INDEX i innych zapytań.
2. Konfiguracja testu porównawczego
2.1 TPC Benchmark™ H
Benchmark zawiera 22 zapytania, których celem jest badanie dużych ilości danych, wykonywanie zapytań o wysokim stopniu złożoności oraz udzielanie odpowiedzi na krytyczne pytania biznesowe. Chcielibyśmy zauważyć, że pełna specyfikacja TPC Benchmark™ H dotyczy różnych testów, takich jak obciążenie, moc i przepustowość testy. Do naszych testów uruchomiliśmy tylko pojedyncze zapytania, a nie kompletny zestaw testów. TPC Benchmark™ H składa się z zestawu zapytań biznesowych zaprojektowanych do wykonywania funkcjonalności systemu w sposób reprezentatywny dla złożonych aplikacji do analizy biznesowej. Zapytaniom tym nadano realistyczny kontekst, przedstawiający działalność dostawcy hurtowego, aby pomóc czytelnikowi intuicyjnie odnieść się do elementów benchmarku.
2.2 Jednostki bazy danych, relacje i cechy
Elementy składowe bazy danych TPC-H są zdefiniowane tak, aby składały się z ośmiu oddzielnych i indywidualnych tabel (Tabele Bazowe). Relacje między kolumnami tych tabel zilustrowano na poniższym diagramie. 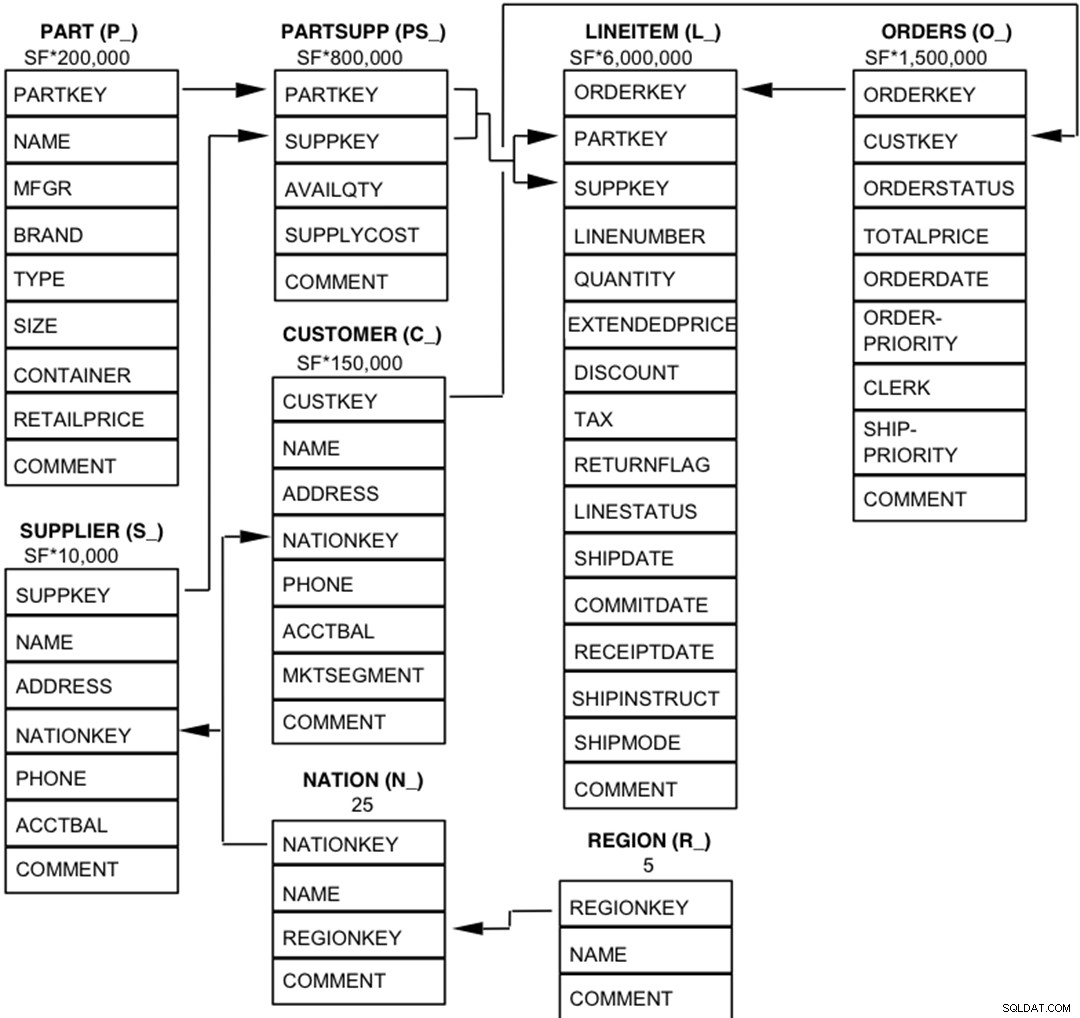 Legenda :
Legenda :
- Nawiasy po każdej nazwie tabeli zawierają prefiks nazw kolumn dla tej tabeli;
- Strzałki wskazują kierunek relacji jeden-do-wielu między tabelami
- Liczba/wzór pod nazwą każdej tabeli reprezentuje liczność (liczbę wierszy) tabeli. Niektóre z nich są rozkładane na czynniki przez SF, współczynnik skali, aby uzyskać wybrany rozmiar bazy danych. Liczność tabeli LINEITEM jest przybliżona
2.3 Dystrybucja danych dla Postgres-XL
Przeanalizowaliśmy wszystkie 22 zapytania w benchmarku i opracowaliśmy następującą strategię dystrybucji danych dla różnych tabel w benchmarku.
| Nazwa tabeli | Strategia dystrybucji |
| ELEMENT LINII | HASH (l_orderkey) |
| ZAmówienia | HASH (o_orderkey) |
| CZĘŚĆ | HASH (p_partkey) |
| PARTSUPP | HASH (ps_partkey) |
| KLIENT | REPLIKOWANE |
| DOSTAWCA | REPLIKOWANE |
| NAROD | REPLIKOWANE |
| REGION | REPLIKOWANE |
Zwróć uwagę, że LINEITEM i ORDERS, które są największymi tabelami w teście porównawczym, są często łączone w ORDERKEY. Dlatego bardzo sensowne jest umieszczanie tych tabel w ORDERKEY. Podobnie PART i PARTSUPP są często łączone w PARTKEY, a zatem są umieszczone w kolumnie PARTKEY. Pozostałe tabele są replikowane, aby zapewnić możliwość łączenia ich lokalnie w razie potrzeby.
3. Wyniki testu porównawczego
3.1 Test obciążenia
Porównaliśmy wyniki uzyskane przez uruchomienie 3TB testu obciążenia TPC-H na PostgreSQL 9.6 z 16-węzłowym klastrem Postgres-XL. Poniższe wykresy przedstawiają charakterystykę wydajności Postgres-XL.
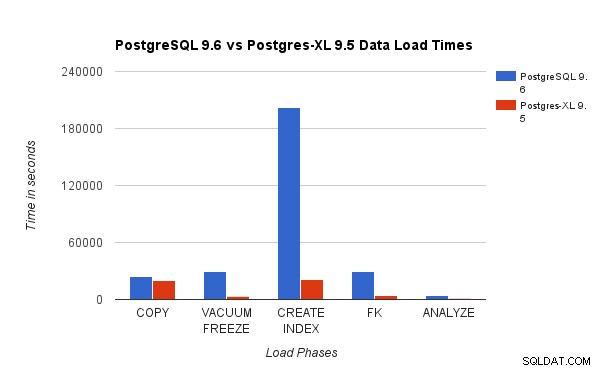 Powyższy wykres przedstawia czas potrzebny na ukończenie różnych faz testu obciążenia z użyciem PostgreSQL i Postgres-XL. Jak widać, Postgres-XL działa nieco lepiej w przypadku KOPIOWANIA i znacznie lepiej we wszystkich innych przypadkach. Uwaga :Zaobserwowaliśmy, że koordynator wymaga dużej mocy obliczeniowej podczas fazy COPY, zwłaszcza gdy więcej niż jeden strumieni COPY działa jednocześnie. Aby temu zaradzić, koordynator został uruchomiony na zoptymalizowanej obliczeniowo instancji AWS z 16 procesorami wirtualnymi. Alternatywnie moglibyśmy również uruchomić wielu koordynatorów i rozłożyć obciążenie obliczeniowe między nimi.
Powyższy wykres przedstawia czas potrzebny na ukończenie różnych faz testu obciążenia z użyciem PostgreSQL i Postgres-XL. Jak widać, Postgres-XL działa nieco lepiej w przypadku KOPIOWANIA i znacznie lepiej we wszystkich innych przypadkach. Uwaga :Zaobserwowaliśmy, że koordynator wymaga dużej mocy obliczeniowej podczas fazy COPY, zwłaszcza gdy więcej niż jeden strumieni COPY działa jednocześnie. Aby temu zaradzić, koordynator został uruchomiony na zoptymalizowanej obliczeniowo instancji AWS z 16 procesorami wirtualnymi. Alternatywnie moglibyśmy również uruchomić wielu koordynatorów i rozłożyć obciążenie obliczeniowe między nimi.
3.2 Test zasilania
Porównaliśmy również czasy wykonywania zapytań dla benchmarku 3TB na PostgreSQL 9.6 i Postgres-XL 9.5. Poniższy wykres przedstawia charakterystykę wydajności wykonywania zapytania w dwóch konfiguracjach.
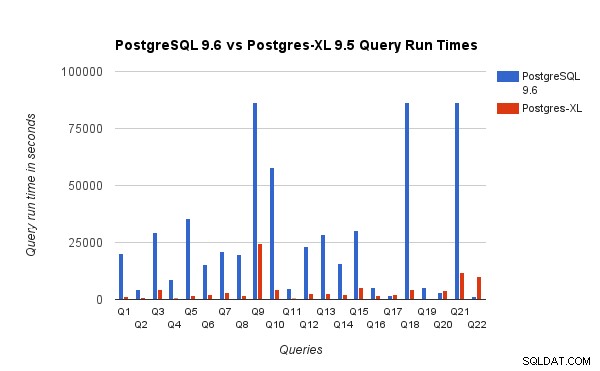 Zaobserwowaliśmy, że w Postgres-XL zapytania były średnio około 6,4 razy szybsze, a co najmniej 25% zapytań wykazały niemal liniową poprawę wydajności, innymi słowy, działały prawie 16 razy szybciej w tym 16-węzłowym klastrze Postgres-XL. Ponadto co najmniej 50% zapytań wykazało 10-krotną poprawę wydajności. Przeanalizowaliśmy dalej wydajność zapytań i doszliśmy do wniosku, że zapytania, które są dobrze podzielone na wszystkie dostępne węzły danych, tak że wymiana danych między węzłami jest minimalna i bez powtarzających się wywołań zdalnego wykonania, skalują się bardzo dobrze w Postgres-XL. Takie zapytania zazwyczaj mają węzeł Remote Subquery Scan na górze, a poddrzewo pod węzłem jest wykonywane na jednym lub większej liczbie węzłów równolegle. Często zdarza się również, że niektóre inne węzły, takie jak węzeł limitu lub węzeł agregacji, znajdują się nad węzłem zdalnego skanowania podzapytań. Nawet takie zapytania działają bardzo dobrze na Postgres-XL. Zapytanie Q1 jest przykładem zapytania, które powinno bardzo dobrze skalować się w Postgres-XL. Z drugiej strony zapytania, które wymagają dużej wymiany krotek między datanode-datanode i/lub koordynatorem-datanode, mogą nie działać dobrze w Postgres-XL. Podobnie zapytania, które wymagają wielu połączeń między węzłami, mogą również wykazywać niską wydajność. Na przykład zauważysz, że wydajność Q22 jest słaba w porównaniu z serwerem PostgreSQL z jednym węzłem. Kiedy przeanalizowaliśmy plan zapytań dla Q22, zauważyliśmy, że istnieją trzy poziomy zagnieżdżonych węzłów Remote Subquery Scan w planie zapytań, w których każdy węzeł otwiera równą liczbę połączeń do węzłów danych. Ponadto funkcja Nest Loop Anti Join ma wewnętrzną relację z węzłem zdalnego skanowania podzapytań najwyższego poziomu, a zatem dla każdej krotki zewnętrznej relacji musi wykonać zdalne podzapytanie. Powoduje to słabą wydajność wykonywania zapytań.
Zaobserwowaliśmy, że w Postgres-XL zapytania były średnio około 6,4 razy szybsze, a co najmniej 25% zapytań wykazały niemal liniową poprawę wydajności, innymi słowy, działały prawie 16 razy szybciej w tym 16-węzłowym klastrze Postgres-XL. Ponadto co najmniej 50% zapytań wykazało 10-krotną poprawę wydajności. Przeanalizowaliśmy dalej wydajność zapytań i doszliśmy do wniosku, że zapytania, które są dobrze podzielone na wszystkie dostępne węzły danych, tak że wymiana danych między węzłami jest minimalna i bez powtarzających się wywołań zdalnego wykonania, skalują się bardzo dobrze w Postgres-XL. Takie zapytania zazwyczaj mają węzeł Remote Subquery Scan na górze, a poddrzewo pod węzłem jest wykonywane na jednym lub większej liczbie węzłów równolegle. Często zdarza się również, że niektóre inne węzły, takie jak węzeł limitu lub węzeł agregacji, znajdują się nad węzłem zdalnego skanowania podzapytań. Nawet takie zapytania działają bardzo dobrze na Postgres-XL. Zapytanie Q1 jest przykładem zapytania, które powinno bardzo dobrze skalować się w Postgres-XL. Z drugiej strony zapytania, które wymagają dużej wymiany krotek między datanode-datanode i/lub koordynatorem-datanode, mogą nie działać dobrze w Postgres-XL. Podobnie zapytania, które wymagają wielu połączeń między węzłami, mogą również wykazywać niską wydajność. Na przykład zauważysz, że wydajność Q22 jest słaba w porównaniu z serwerem PostgreSQL z jednym węzłem. Kiedy przeanalizowaliśmy plan zapytań dla Q22, zauważyliśmy, że istnieją trzy poziomy zagnieżdżonych węzłów Remote Subquery Scan w planie zapytań, w których każdy węzeł otwiera równą liczbę połączeń do węzłów danych. Ponadto funkcja Nest Loop Anti Join ma wewnętrzną relację z węzłem zdalnego skanowania podzapytań najwyższego poziomu, a zatem dla każdej krotki zewnętrznej relacji musi wykonać zdalne podzapytanie. Powoduje to słabą wydajność wykonywania zapytań.
4. Kilka lekcji AWS
Podczas benchmarkingu Postgres-XL nauczyliśmy się kilku lekcji na temat korzystania z AWS. Pomyśleliśmy, że będą przydatne dla każdego, kto chce używać/testować Postgres-XL na AWS.
- AWS oferuje kilka różnych typów instancji. Musisz dokładnie ocenić obciążenie pracą i ilość wymaganej pamięci przed wyborem konkretnego typu instancji.
- Większość instancji zoptymalizowanych pod kątem przechowywania ma dołączone dyski efemeryczne. Za te dyski nie trzeba płacić żadnych dodatkowych opłat, są one podłączone do instancji i często działają lepiej niż EBS. Ale musisz je wyraźnie zamontować, aby móc z nich korzystać. Pamiętaj jednak, że dane przechowywane na tych dyskach nie są trwałe i zostaną usunięte, jeśli instancja zostanie zatrzymana. Upewnij się więc, że jesteś przygotowany na radzenie sobie z tą sytuacją. Ponieważ używaliśmy AWS głównie do testów porównawczych, zdecydowaliśmy się użyć tych dysków efemerycznych.
- Jeśli korzystasz z EBS, upewnij się, że wybrałeś odpowiednie aprowizowane IOPS. Zbyt niska wartość spowoduje bardzo powolne IO, ale bardzo wysoka wartość może znacznie zwiększyć rachunek za AWS, zwłaszcza gdy mamy do czynienia z dużą liczbą węzłów.
- Upewnij się, że uruchamiasz instancje w tej samej strefie, aby zmniejszyć opóźnienia i poprawić przepustowość połączeń między nimi.
- Upewnij się, że skonfigurowałeś instancje tak, aby używały sieci prywatnej do komunikowania się ze sobą.
- Spójrz na instancje spot. Są stosunkowo tańsze. Ponieważ AWS może dowolnie zamykać wystąpienia spot, na przykład jeśli cena spot będzie wyższa niż maksymalna cena oferty, przygotuj się na to. Postgres-XL może stać się częściowo lub całkowicie bezużyteczny w zależności od tego, które węzły są zakończone. AWS obsługuje koncepcję launch_group. Jeśli wiele instancji jest zgrupowanych w tej samej grupie_uruchamiania, jeśli AWS zdecyduje się zakończyć jedną instancję, wszystkie instancje zostaną zakończone.
5. Wniosek
Jesteśmy w stanie pokazać, poprzez różne testy porównawcze, że Postgres-XL może naprawdę dobrze skalować się dla dużego zestawu złożonych zapytań ze świata rzeczywistego. Testy te pomagają nam zademonstrować możliwości Postgres-XL jako skutecznego rozwiązania dla obciążeń OLAP. Nasze eksperymenty pokazują również, że Postgres-XL ma pewne problemy z wydajnością, szczególnie w przypadku bardzo dużych klastrów i gdy planista dokonuje złego wyboru planu. Zaobserwowaliśmy również, że gdy istnieje bardzo duża liczba jednoczesnych połączeń z węzłem danych, wydajność pogarsza się. Będziemy nadal pracować nad tymi problemami z wydajnością. Chcielibyśmy również przetestować możliwości Postgres-XL jako rozwiązania OLTP przy użyciu odpowiednich obciążeń.