Ansible jest po prostu świetny, a PostgreSQL z pewnością jest niesamowity, zobaczmy, jak wspaniale współpracują!

====================Ogłoszenie o premierze! ====================
PGConf Europe 2015 odbędzie się 27-30 października tego roku w Wiedniu.
Zakładam, że prawdopodobnie interesuje Cię zarządzanie konfiguracją, orkiestracja serwerów, automatyczne wdrażanie (dlatego właśnie czytasz ten wpis na blogu, prawda?) i lubisz pracować z PostgreSQL (na pewno) na AWS (opcjonalnie), to możesz dołączyć do mojego wykładu „Managing PostgreSQL with Ansible” 28 października, 15-15:50.
Sprawdź niesamowity harmonogram i nie przegap szansy na udział w największym wydarzeniu PostgreSQL w Europie!
Mam nadzieję, że cię tam zobaczymy, tak, lubię pić kawę po rozmowach 🙂
====================Ogłoszenie o premierze ! =============
Co to jest Ansible i jak to działa?
Motto Ansible to „prosta, bezagentowa i potężna automatyzacja IT o otwartym kodzie źródłowym ” cytując dokumenty Ansible.
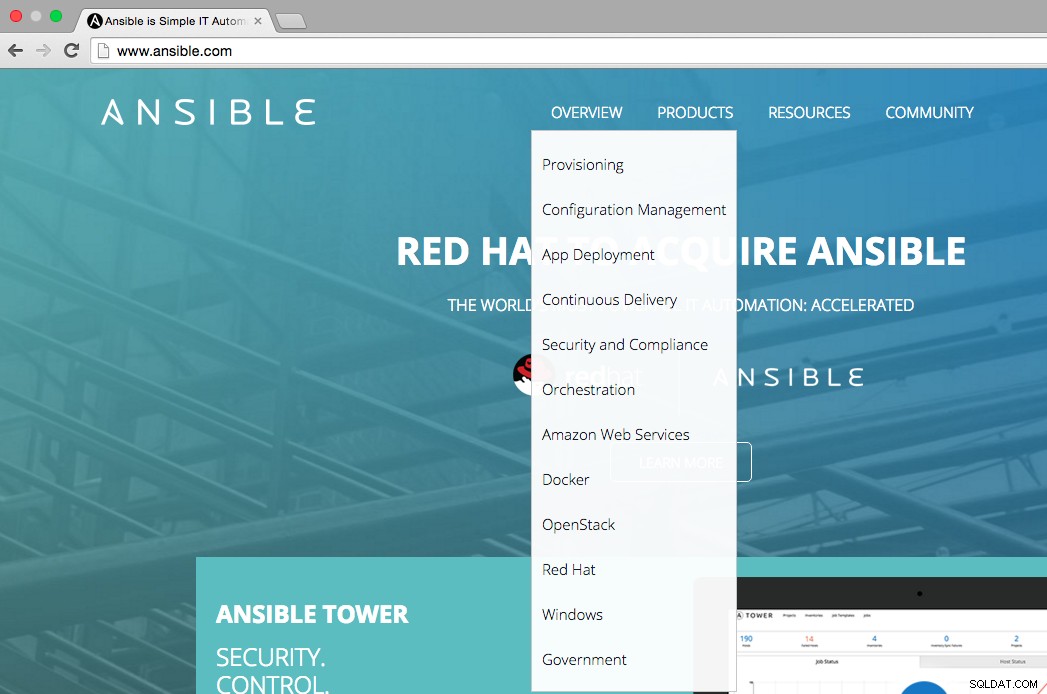
Jak widać na poniższym rysunku, strona główna Ansible stwierdza, że główne obszary użytkowania Ansible to:udostępnianie, zarządzanie konfiguracją, wdrażanie aplikacji, ciągłe dostarczanie, bezpieczeństwo i zgodność, orkiestracja. Menu przeglądu pokazuje również, na których platformach możemy zintegrować Ansible, tj. AWS, Docker, OpenStack, Red Hat, Windows.
Sprawdźmy główne przypadki użycia Ansible, aby zrozumieć, jak działa i jak bardzo jest pomocny w środowiskach IT.
Obsługa administracyjna
Ansible jest Twoim lojalnym przyjacielem, gdy chcesz zautomatyzować wszystko w swoim systemie. Jest bezagentowy i możesz po prostu zarządzać swoimi rzeczami (tj. serwerami, systemami równoważenia obciążenia, przełącznikami, zaporami ogniowymi) przez SSH. Niezależnie od tego, czy Twoje systemy działające na serwerach bare-metal, czy w chmurze, Ansible będzie tam i pomagał w udostępnianiu instancji. Jego idempotentne cechy zapewniają, że zawsze będziesz w stanie, którego pragniesz (i oczekiwałeś).
Zarządzanie konfiguracją
Jedną z najtrudniejszych rzeczy jest nie powtarzanie się w powtarzalnych zadaniach operacyjnych i tutaj Ansible znów przychodzi na myśl jako zbawca. W dawnych dobrych czasach, gdy czasy były złe, administratorzy pisali wiele skryptów i łączyli się z wieloma serwerami, aby je zastosować, i oczywiście nie była to najlepsza rzecz w ich życiu. Jak wszyscy wiemy, ręczne zadania są podatne na błędy i prowadzą do heterogenicznego środowiska zamiast jednorodnego i łatwiejszego w zarządzaniu, co zdecydowanie sprawia, że nasze życie jest bardziej stresujące.
Z Ansible możesz pisać proste playbooki (przy pomocy bardzo pouczającej dokumentacji i przy wsparciu ogromnej społeczności), a kiedy już napiszesz swoje zadania, możesz wywołać szeroką gamę modułów (tj. AWS, Nagios, PostgreSQL, SSH, APT, File moduły). W rezultacie możesz skupić się na bardziej kreatywnych działaniach niż ręczne zarządzanie konfiguracjami.
Wdrażanie aplikacji
Mając gotowe artefakty, bardzo łatwo jest je wdrożyć na wielu serwerach. Ponieważ Ansible komunikuje się przez SSH, nie ma potrzeby pobierania danych z repozytorium na każdym serwerze ani kłopotów ze starymi metodami, takimi jak kopiowanie plików przez FTP. Ansible może synchronizować artefakty i zapewniać przesyłanie tylko nowych lub zaktualizowanych plików oraz usuwanie przestarzałych plików. Przyspiesza to również przesyłanie plików i oszczędza dużo przepustowości.
Oprócz przesyłania plików, Ansible pomaga również w przygotowaniu serwerów do użytku produkcyjnego. Przed przeniesieniem może wstrzymać monitorowanie, usunąć serwery z systemów równoważenia obciążenia i zatrzymać usługi. Po wdrożeniu może uruchamiać usługi, dodawać serwery do systemów równoważenia obciążenia i wznawiać monitorowanie.
To wszystko nie musi zachodzić od razu dla wszystkich serwerów. Ansible może jednocześnie pracować na podzbiorze serwerów, aby zapewnić wdrożenia bez przestojów. Na przykład za jednym razem może wdrożyć 5 serwerów naraz, a po ich zakończeniu może wdrożyć na kolejnych 5 serwerach.
Po wdrożeniu tego scenariusza można go wykonać w dowolnym miejscu. Deweloperzy lub członkowie zespołu QA mogą przeprowadzać wdrożenia na własnych komputerach w celach testowych. Ponadto, aby wycofać wdrożenie z dowolnego powodu, wszystkie potrzeby programu Ansible to lokalizacja ostatnich znanych artefaktów roboczych. Następnie może je łatwo ponownie wdrożyć na serwerach produkcyjnych, aby przywrócić system do stabilnego stanu.
Ciągła dostawa
Ciągłe dostarczanie oznacza przyjęcie szybkiego i prostego podejścia do wydań. Aby osiągnąć ten cel, kluczowe jest korzystanie z najlepszych narzędzi, które umożliwiają częste wydania bez przestojów i wymagają jak najmniejszej interwencji człowieka. Ponieważ dowiedzieliśmy się o możliwościach wdrażania aplikacji Ansible powyżej, dość łatwo jest przeprowadzać wdrożenia bez przestojów. Drugim wymogiem ciągłego dostarczania jest mniej procesów ręcznych, a to oznacza automatyzację. Ansible może zautomatyzować każde zadanie, od udostępniania serwerów po konfigurowanie usług, aby były gotowe do produkcji. Po utworzeniu i przetestowaniu scenariuszy w Ansible banalne staje się umieszczenie ich przed systemem ciągłej integracji i pozwolenie Ansible na wykonanie swojej pracy.
Bezpieczeństwo i zgodność
Bezpieczeństwo jest zawsze uważane za najważniejszą rzecz, ale utrzymanie bezpieczeństwa systemów jest jedną z najtrudniejszych rzeczy do osiągnięcia. Musisz mieć pewność co do bezpieczeństwa swoich danych, a także bezpieczeństwa danych Twojego klienta. Aby mieć pewność, że Twoje systemy są bezpieczne, samo zdefiniowanie zabezpieczeń nie wystarczy, musisz mieć możliwość stosowania tych zabezpieczeń i ciągłego monitorowania systemów, aby zapewnić ich zgodność z tymi zabezpieczeniami.
Ansible jest łatwy w użyciu, niezależnie od tego, czy chodzi o konfigurowanie reguł zapory, blokowanie użytkowników i grup, czy stosowanie niestandardowych zasad bezpieczeństwa. Jest bezpieczny ze względu na swoją naturę, ponieważ możesz wielokrotnie stosować tę samą konfigurację i wprowadzi tylko niezbędne zmiany, aby przywrócić zgodność systemu.
Orkiestracja
Ansible zapewnia, że wszystkie zadania są w odpowiedniej kolejności i ustanawia harmonię pomiędzy wszystkimi zasobami, którymi zarządza. Organizowanie złożonych wdrożeń wielowarstwowych jest łatwiejsze dzięki zarządzaniu konfiguracją i możliwościom wdrażania Ansible. Na przykład, biorąc pod uwagę wdrożenie stosu oprogramowania, kwestie takie jak upewnienie się, że wszystkie serwery baz danych są gotowe przed aktywacją serwerów aplikacji lub skonfigurowanie sieci przed dodaniem serwerów do systemu równoważenia obciążenia, nie są już skomplikowanymi problemami.
Ansible pomaga również w orkiestracji innych narzędzi do orkiestracji, takich jak Amazon’s CloudFormation, OpenStack’s Heat, Docker’s Swarm itp. W ten sposób, zamiast uczyć się różnych platform, języków i zasad; użytkownicy mogą skoncentrować się tylko na składni YAML i potężnych modułach Ansible.
Co to jest moduł Ansible?
Moduły lub biblioteki modułów zapewniają Ansible środki do kontrolowania lub zarządzania zasobami na lokalnych lub zdalnych serwerach. Pełnią różnorodne funkcje. Na przykład moduł może być odpowiedzialny za ponowne uruchomienie komputera lub może po prostu wyświetlić komunikat na ekranie.
Ansible pozwala użytkownikom pisać własne moduły, a także zapewnia gotowe moduły podstawowe lub dodatkowe.
A co z podręcznikami Ansible?
Ansible pozwala nam organizować naszą pracę na różne sposoby. W najbardziej bezpośredniej formie możemy pracować z modułami Ansible za pomocą „ansible ” narzędzie wiersza poleceń i plik ekwipunku.
Inwentarz
Jednym z najważniejszych pojęć jest inwentarz . Potrzebujemy pliku inwentaryzacji, aby poinformować Ansible, z którymi serwerami musi się połączyć za pomocą SSH, jakich informacji o połączeniu wymaga i opcjonalnie, które zmienne są powiązane z tymi serwerami.
Plik inwentarzowy ma format podobny do INI. W pliku inwentarza możemy określić więcej niż jednego hosta i pogrupować je w więcej niż jedną grupę hostów.
Nasz przykładowy plik inwentaryzacji hosts.ini wygląda następująco:
[dbservers]
db.example.com
Tutaj mamy pojedynczy host o nazwie „db.example.com” w grupie hostów o nazwie „dbservers”. W pliku inwentarza możemy również uwzględnić niestandardowe porty SSH, nazwy użytkowników SSH, klucze SSH, informacje o proxy, zmienne itp.
Ponieważ mamy gotowy plik inwentaryzacji, aby sprawdzić czas pracy naszych serwerów baz danych, możemy wywołać „polecenie firmy Ansible ” i uruchom „czas pracy ” polecenie na tych serwerach:
ansible dbservers -i hosts.ini -m command -a "uptime"
Tutaj poinstruowaliśmy Ansible, aby odczytał hosty z pliku hosts.ini, łączył je za pomocą SSH, wykonywał „czas pracy ” na każdym z nich, a następnie wypisz ich dane wyjściowe na ekranie. Ten typ wykonania modułu nazywa się poleceniem ad-hoc .
Wynik polecenia będzie wyglądał następująco:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible dbservers -i hosts.ini -m command -a "uptime"
db.example.com | success | rc=0 >>
21:16:24 up 93 days, 9:17, 4 users, load average: 0.08, 0.03, 0.05
Jeśli jednak nasze rozwiązanie zawiera więcej niż jeden krok, zarządzanie nimi tylko za pomocą poleceń ad-hoc staje się trudne.
Oto poradniki firmy Ansible. Pozwala nam zorganizować nasze rozwiązanie w pliku playbook, integrując wszystkie kroki za pomocą zadań, zmiennych, ról, szablonów, programów obsługi i ekwipunku.
Rzućmy okiem na niektóre z tych terminów, aby zrozumieć, w jaki sposób mogą nam pomóc.
Zadania
Inną ważną koncepcją są zadania. Każde zadanie Ansible zawiera nazwę, moduł do wywołania, parametry modułu i opcjonalnie warunki wstępne i końcowe. Pozwalają nam wywoływać moduły Ansible i przekazywać informacje do kolejnych zadań.
Zmienne
Są też zmienne. Są bardzo przydatne do ponownego wykorzystania dostarczonych lub zebranych przez nas informacji. Możemy je zdefiniować w ekwipunku, w zewnętrznych plikach YAML lub w playbookach.
Poradnik
Poradniki Ansible są pisane przy użyciu składni YAML. Może zawierać więcej niż jedną sztukę. Każda gra zawiera nazwę grup hostów, z którymi można się połączyć, oraz zadania, które musi wykonać. Może również zawierać zmienne/role/programy obsługi, jeśli są zdefiniowane.
Teraz możemy spojrzeć na bardzo prosty podręcznik, aby zobaczyć, jak można go skonstruować:
---
- hosts: dbservers
gather_facts: no
vars:
who: World
tasks:
- name: say hello
debug: msg="Hello {{ who }}"
- name: retrieve the uptime
command: uptimeW tym bardzo prostym podręczniku powiedzieliśmy Ansible, że powinien działać na serwerach zdefiniowanych w grupie hostów „dbservers”. Stworzyliśmy zmienną o nazwie „kto”, a następnie zdefiniowaliśmy nasze zadania. Zauważ, że w pierwszym zadaniu, w którym drukujemy komunikat debugowania, użyliśmy zmiennej „who” i spowodowaliśmy, że Ansible wypisał na ekranie „Hello World”. W drugim zadaniu powiedzieliśmy Ansible, aby łączył się z każdym hostem, a następnie wykonał tam polecenie „uptime”.
Moduły Ansible PostgreSQL
Ansible dostarcza wiele modułów dla PostgreSQL. Niektóre z nich znajdują się pod modułami podstawowymi, podczas gdy inne można znaleźć pod modułami dodatkowymi.
Wszystkie moduły PostgreSQL wymagają zainstalowania pakietu Python psycopg2 na tej samej maszynie z serwerem PostgreSQL. Psycopg2 to adapter bazy danych PostgreSQL w języku programowania Python.
W systemach Debian/Ubuntu pakiet psycopg2 można zainstalować za pomocą następującego polecenia:
apt-get install python-psycopg2
Teraz przyjrzymy się szczegółowo tym modułom. Na przykład będziemy pracować na serwerze PostgreSQL na hoście db.example.com na porcie 5432 z postgresem użytkownika i puste hasło.
postgresql_db
Ten podstawowy moduł tworzy lub usuwa daną bazę danych PostgreSQL. W terminologii Ansible zapewnia, że dana baza danych PostgreSQL jest obecna lub nieobecna.
Najważniejszą opcją jest wymagany parametr „nazwa ”. Reprezentuje nazwę bazy danych na serwerze PostgreSQL. Innym ważnym parametrem jest „stan ”. Wymaga jednej z dwóch wartości:obecny lub nieobecny . To pozwala nam stworzyć lub usunąć bazę danych, która jest identyfikowana przez wartość podaną w nazwa parametr.
Niektóre przepływy pracy mogą również wymagać określenia parametrów połączenia, takich jak login_host , port , login_user i login_password .
Stwórzmy bazę danych o nazwie „module_test ” na naszym serwerze PostgreSQL, dodając poniższe wiersze do naszego pliku playbook:
- postgresql_db: name=module_test
state=present
login_host=db.example.com
port=5432
login_user=postgres
Tutaj połączyliśmy się z naszym testowym serwerem bazy danych pod adresem db.example.com z użytkownikiem; postgres . Jednak nie musi to być postgres użytkownik jako nazwa użytkownika może być dowolna.
Usunięcie bazy danych jest tak proste, jak jej utworzenie:
- postgresql_db: name=module_test
state=absent
login_host=db.example.com
port=5432
login_user=postgres
Zwróć uwagę na wartość „brak” w parametrze „stan”.
postgresql_ext
Wiadomo, że PostgreSQL ma bardzo przydatne i potężne rozszerzenia. Na przykład ostatnie rozszerzenie to tsm_system_rows co pomaga pobrać dokładną liczbę wierszy w próbkowaniu tabel. (Więcej informacji można znaleźć w moim poprzednim poście na temat metod próbkowania tabel.)
Ten moduł dodatków dodaje lub usuwa rozszerzenia PostgreSQL z bazy danych. Wymaga dwóch obowiązkowych parametrów:db i imię . db parametr odnosi się do nazwy bazy danych i nazwy parametr odnosi się do nazwy rozszerzenia. Mamy też stan parametr, który wymaga obecności lub nieobecny wartości i takie same parametry połączenia jak w module postgresql_db.
Zacznijmy od stworzenia rozszerzenia, o którym mówiliśmy:
- postgresql_ext: db=module_test
name=tsm_system_rows
state=present
login_host=db.example.com
port=5432
login_user=postgres
postgresql_user
Ten podstawowy moduł umożliwia dodawanie lub usuwanie użytkowników i ról z bazy danych PostgreSQL.
Jest to bardzo potężny moduł, ponieważ zapewniając obecność użytkownika w bazie danych, pozwala jednocześnie na modyfikację uprawnień lub ról.
Zacznijmy od przyjrzenia się parametrom. Jedynym wymaganym parametrem jest tutaj „nazwa ”, który odnosi się do nazwy użytkownika lub roli. Podobnie jak w większości modułów Ansible, „stan ” parametr jest ważny. Może mieć jeden z obecnych lub nieobecny wartości, a jego wartość domyślna to obecna .
Oprócz parametrów połączenia, jak w poprzednich modułach, niektóre inne ważne parametry opcjonalne to:
- db :Nazwa bazy danych, w której zostaną przyznane uprawnienia
- hasło :Hasło użytkownika
- prywat :Uprawnienia w „priv1/priv2” lub uprawnienia do tabeli w formacie „table:priv1,priv2,…”
- role_attr_flags :Atrybuty roli. Możliwe wartości to:
- [NIE]SUPERUSER
- [NIE]CREATEROLE
- [NO]CREATEUSER
- [NIE]UTWORZONEB
- [NIE]DZIEDZICZYĆ
- [NIE]LOGOWANIE
- [NIE]REPLIKACJI
Aby utworzyć nowego użytkownika o nazwie ada z hasłem lovelace i przywilej połączenia z bazą danych module_test , do naszego poradnika możemy dodać:
- postgresql_user: db=module_test
name=ada
password=lovelace
state=present
priv=CONNECT
login_host=db.example.com
port=5432
login_user=postgres
Teraz, gdy mamy gotowego użytkownika, możemy przypisać mu kilka ról. Aby umożliwić „ada” logowanie i tworzenie baz danych:
- postgresql_user: name=ada
role_attr_flags=LOGIN,CREATEDB
login_host=db.example.com
port=5432
login_user=postgres
Możemy również przyznać uprawnienia globalne lub oparte na tabeli, takie jak „WSTAW ”, „AKTUALIZUJ ”, „WYBIERZ ” i „USUŃ ” za pomocą priv parametr. Jedną z ważnych kwestii do rozważenia jest to, że użytkownika nie można usunąć, dopóki wszystkie przyznane uprawnienia nie zostaną najpierw cofnięte.
postgresql_privs
Ten moduł podstawowy nadaje lub odbiera uprawnienia do obiektów bazy danych PostgreSQL. Obsługiwane obiekty to:tabela , sekwencja , funkcja , baza danych , schemat , język , przestrzeń tabel i grupa .
Wymagane parametry to „baza danych”; nazwa bazy danych do nadawania/odbierania uprawnień oraz „role”; listę nazw ról oddzielonych przecinkami.
Najważniejsze parametry opcjonalne to:
- wpisz :Typ obiektu, dla którego chcesz ustawić uprawnienia. Może być jednym z:tabela, sekwencja, funkcja, baza danych, schemat, język, przestrzeń tabel, grupa . Wartość domyślna to tabela .
- obiekty :Obiekty bazy danych do ustawienia uprawnień. Może mieć wiele wartości. W takim przypadku obiekty oddziela się przecinkiem.
- uprawnienia :Oddzielona przecinkami lista uprawnień do nadawania lub odbierania. Możliwe wartości to:WSZYSTKO , WYBIERZ , AKTUALIZUJ , WSTAW .
Zobaczmy, jak to działa, przyznając wszystkie uprawnienia „publicznemu ” schemat do „ada ”:
- postgresql_privs: db=module_test
privs=ALL
type=schema
objs=public
role=ada
login_host=db.example.com
port=5432
login_user=postgres
postgresql_lang
Jedną z bardzo potężnych funkcji PostgreSQL jest obsługa praktycznie każdego języka, który może być używany jako język proceduralny. Ten moduł dodatków dodaje, usuwa lub zmienia języki proceduralne w bazie danych PostgreSQL.
Jedynym wymaganym parametrem jest „język ”; nazwa języka proceduralnego do dodania lub usunięcia. Inne ważne opcje to „db ”; nazwa bazy danych, do której język jest dodawany lub usuwany, oraz „zaufaj ”; opcja ustawienia języka jako zaufanego lub niezaufanego dla wybranej bazy danych.
Włączmy język PL/Python dla naszej bazy danych:
- postgresql_lang: db=module_test
lang=plpython2u
state=present
login_host=db.example.com
port=5432
login_user=postgres
Łączenie wszystkiego w całość
Teraz, gdy wiemy już, jak zbudowany jest podręcznik Ansible i jakie moduły PostgreSQL są dla nas dostępne, możemy teraz połączyć naszą wiedzę w podręczniku Ansible.
Ostateczna forma naszego podręcznika main.yml wygląda następująco:
---
- hosts: dbservers
sudo: yes
sudo_user: postgres
gather_facts: yes
vars:
dbname: module_test
dbuser: postgres
tasks:
- name: ensure the database is present
postgresql_db: >
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the tsm_system_rows extension is present
postgresql_ext: >
name=tsm_system_rows
state=present
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has access to database
postgresql_user: >
name=ada
password=lovelace
state=present
priv=CONNECT
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the user has necessary privileges
postgresql_user: >
name=ada
role_attr_flags=LOGIN,CREATEDB
login_user={{ dbuser }}
- name: ensure the user has schema privileges
postgresql_privs: >
privs=ALL
type=schema
objs=public
role=ada
db={{ dbname }}
login_user={{ dbuser }}
- name: ensure the postgresql-plpython-9.4 package is installed
apt: name=postgresql-plpython-9.4 state=latest
sudo_user: root
- name: ensure the PL/Python language is available
postgresql_lang: >
lang=plpython2u
state=present
db={{ dbname }}
login_user={{ dbuser }}
Teraz możemy uruchomić nasz playbook za pomocą polecenia „ansible-playbook”:
example@sqldat.com ~/blog/ansible-loves-postgresql # ansible-playbook -i hosts.ini main.yml
PLAY [dbservers] **************************************************************
GATHERING FACTS ***************************************************************
ok: [db.example.com]
TASK: [ensure the database is present] ****************************************
changed: [db.example.com]
TASK: [ensure the tsm_system_rows extension is present] ***********************
changed: [db.example.com]
TASK: [ensure the user has access to database] ********************************
changed: [db.example.com]
TASK: [ensure the user has necessary privileges] ******************************
changed: [db.example.com]
TASK: [ensure the user has schema privileges] *********************************
changed: [db.example.com]
TASK: [ensure the postgresql-plpython-9.4 package is installed] ***************
changed: [db.example.com]
TASK: [ensure the PL/Python language is available] ****************************
changed: [db.example.com]
PLAY RECAP ********************************************************************
db.example.com : ok=8 changed=7 unreachable=0 failed=0
Inwentarz i plik Playbook znajdziesz w moim repozytorium GitHub utworzonym dla tego posta na blogu. Istnieje również inny podręcznik o nazwie „remove.yml”, który cofa wszystko, co zrobiliśmy w głównym podręczniku.
Aby uzyskać więcej informacji o Ansible:
- Sprawdź ich dobrze napisane dokumenty.
- Obejrzyj krótki film o Ansible, który jest naprawdę pomocnym samouczkiem.
- Podążaj za ich harmonogramem webinarów, na liście jest kilka fajnych nadchodzących webinariów.