PostgreSQL to niesamowity projekt, który rozwija się w niesamowitym tempie. Skoncentrujemy się na ewolucji możliwości odporności na awarie w PostgreSQL we wszystkich jego wersjach w serii wpisów na blogu. To jest drugi post z serii. Porozmawiamy o replikacji i jej znaczeniu dla odporności na błędy i niezawodności PostgreSQL.
Jeśli chcesz być świadkiem postępu ewolucji od samego początku, sprawdź pierwszy wpis na blogu z serii:Evolution of Fault Tolerance in PostgreSQL
Replikacja PostgreSQL
Replikacja bazy danych to termin, którego używamy do opisania technologii używanej do utrzymywania kopii zestawu danych na pilocie system. Utrzymywanie niezawodnej kopii działającego systemu jest jednym z największych problemów związanych z redundancją i wszyscy lubimy konserwowalne, łatwe w użyciu i stabilne kopie naszych danych.
Przyjrzyjmy się podstawowej architekturze. Zazwyczaj poszczególne serwery baz danych są określane jako węzły . Cała grupa serwerów baz danych zaangażowanych w replikację jest znana jako klaster . Serwer bazy danych, który umożliwia użytkownikowi wprowadzanie zmian, jest znany jako master lub podstawowy lub może być opisana jako źródło zmian. Serwer bazy danych, który tylko umożliwia dostęp tylko do odczytu jest znany jako Hot Standby . (Termin gorącej gotowości jest szczegółowo wyjaśniony pod tytułem Tryby gotowości. )
Kluczowym aspektem replikacji jest to, że zmiany danych są przechwytywane na urządzeniu głównym, a następnie przesyłane do innych węzłów. W niektórych przypadkach węzeł może wysyłać zmiany danych do innych węzłów, co jest procesem znanym jako kaskadowe lub przekaźnik . Zatem master jest węzłem wysyłającym, ale nie wszystkie węzły wysyłające muszą być masterami. Replikacja jest często klasyfikowana według tego, czy dozwolony jest więcej niż jeden węzeł nadrzędny, w którym to przypadku będzie nazywana replikacją wielorzędową .
Zobaczmy, jak PostgreSQL obsługuje replikację w czasie i jaki jest stan wiedzy w zakresie odporności na błędy w warunkach replikacji.
Historia replikacji PostgreSQL
Historycznie (około 2000-2005), Postgres koncentrował się tylko na tolerancji/naprawianiu błędów pojedynczego węzła, co jest w większości osiągane przez WAL, dziennik transakcji. Odporność na awarie jest częściowo obsługiwana przez MVCC (system współbieżności wielu wersji), ale jest to głównie optymalizacja.
Rejestrowanie z wyprzedzeniem było i nadal jest największą metodą odporności na błędy w PostgreSQL. Zasadniczo wystarczy mieć pliki WAL, w których zapisujesz wszystko i można je odzyskać pod względem awarii, odtwarzając je. To wystarczyło w przypadku architektur z jednym węzłem, a replikacja jest uważana za najlepsze rozwiązanie do osiągnięcia odporności na awarie z wieloma węzłami.
Społeczność Postgres od dawna wierzyła, że replikacja jest czymś, czego Postgres nie powinien zapewniać i powinna być obsługiwana przez narzędzia zewnętrzne, dlatego też pojawiły się narzędzia takie jak Slony i Londiste. (Rozwiązania replikacji oparte na wyzwalaczach omówimy w kolejnych wpisach na blogu z tej serii).
W końcu stało się jasne, że jedna tolerancja serwera to za mało i więcej osób domagało się odpowiedniej odporności na awarie sprzętu i właściwego sposobu przełączania, co jest wbudowane w Postgres. To wtedy ożyła replikacja fizyczna (a następnie fizyczna transmisja strumieniowa).
W dalszej części posta omówimy wszystkie metody replikacji, ale zobaczmy chronologicznie wydarzenia z historii replikacji PostgreSQL według głównych wydań:
- PostgreSQL 7.x (~2000)
- Replikacja nie powinna być częścią podstawowego Postgresa
- Londiste – Slony (replikacja logiczna oparta na wyzwalaczach)
- PostgreSQL 8.0 (2005)
- Odzyskiwanie do określonego momentu (WAL)
- PostgreSQL 9.0 (2010)
- Replikacja strumieniowa (fizyczna)
- PostgreSQL 9.4 (2014)
- Dekodowanie logiczne (wyodrębnianie zestawu zmian)
Replikacja fizyczna
PostgreSQL rozwiązał podstawową potrzebę replikacji za pomocą tego, co robi większość relacyjnych baz danych; przejął WAL i umożliwił przesyłanie go przez sieć. Następnie te pliki WAL są stosowane do oddzielnej instancji Postgres, która działa tylko do odczytu.
Instancja rezerwowa tylko do odczytu po prostu stosuje zmiany (przez WAL) i jedyne operacje zapisu przyjdź ponownie z tego samego dziennika WAL. Oto jak replikacja strumieniowa mechanizm działa. Na początku replikacja początkowo wysyłała wszystkie pliki –wysyłka dziennika- , ale później przekształcił się w streaming.
Podczas wysyłania logów wysyłaliśmy całe pliki za pomocą archive_command . Logika jest tutaj dość prosta:po prostu wysyłasz archiwum i dziennik go gdzieś – jak cały 16MB plik WAL – a następnie zastosuj gdzieś, a potem pobierasz następny i zastosuj tamten i to idzie tak. Później stało się przesyłaniem strumieniowym przez sieć przy użyciu protokołu libpq w PostgreSQL w wersji 9.0.
Istniejąca replikacja jest lepiej znana jako Fizyczna replikacja strumieniowa, ponieważ przesyłamy strumieniowo serię fizycznych zmian z jednego węzła do drugiego. Oznacza to, że kiedy wstawiamy wiersz do tabeli generujemy rekordy zmian dla wstawki plus wszystkie wpisy indeksu .
Kiedy VACUUM tabelę, w której generujemy również rekordy zmian.
Ponadto fizyczna replikacja strumieniowania rejestruje wszystkie zmiany na poziomie bajta/bloku , co bardzo utrudnia robienie czegokolwiek innego niż tylko odtwarzanie wszystkiego
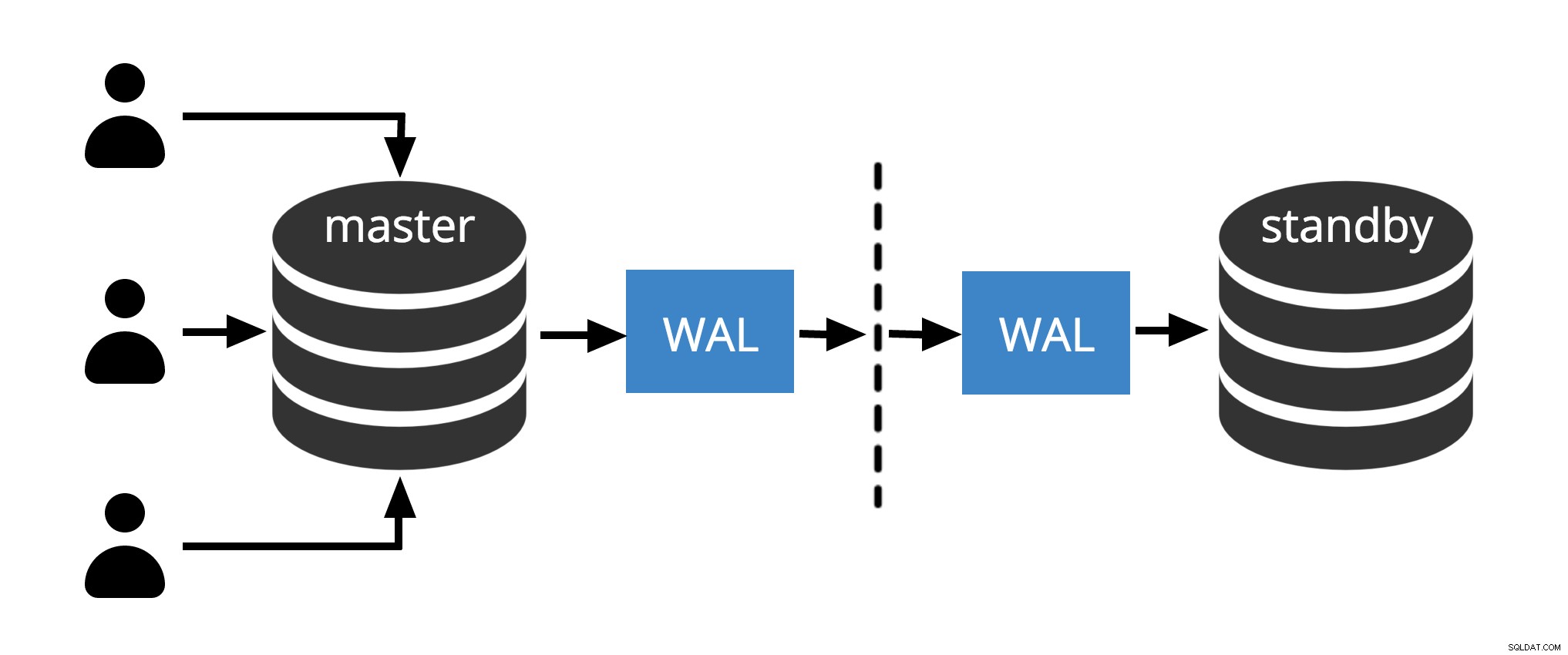
Rys.1 Fizyczna replikacja
Rys. 1 pokazuje, jak replikacja fizyczna działa tylko z dwoma węzłami. Klient wykonuje zapytania w węźle głównym, zmiany są zapisywane w dzienniku transakcji (WAL) i kopiowane przez sieć do WAL w węźle rezerwowym. Następnie proces odzyskiwania w węźle gotowości odczytuje zmiany z WAL i stosuje je do plików danych, tak jak podczas odzyskiwania po awarii. Jeśli tryb gotowości jest w trybie gorącej gotowości w trybie, klienci mogą wysyłać zapytania tylko do odczytu w węźle, gdy to się dzieje.
Uwaga: Replikacja fizyczna oznacza po prostu wysyłanie plików WAL przez sieć od węzła głównego do węzła rezerwowego. Pliki mogą być wysyłane przez różne protokoły, takie jak scp, rsync, ftp… Różnica między replikacją fizyczną i Fizyczna replikacja strumieniowania czy Streaming Replication używa wewnętrznego protokołu do wysyłania plików WAL (nadawca i procesy odbiorcy )
Tryby gotowości
Wiele węzłów zapewnia wysoką dostępność. Z tego powodu nowoczesne architektury mają zwykle węzły rezerwowe. Istnieją różne tryby dla węzłów gotowości (tryb gotowości ciepłej i gotowości gorącej). Poniższa lista wyjaśnia podstawowe różnice między różnymi trybami gotowości, a także pokazuje przypadek architektury multi-master.
Ciepły tryb gotowości
Można aktywować natychmiast, ale nie można wykonywać użytecznej pracy, dopóki nie zostanie aktywowana. Jeśli nieprzerwanie przesyłamy serie plików WAL do innej maszyny, która została załadowana tym samym podstawowym plikiem kopii zapasowej, mamy system ciepłej gotowości:w dowolnym momencie możemy uruchomić drugą maszynę i będzie ona miała prawie aktualną kopię baza danych. Ciepłe czuwanie nie pozwala na zapytania tylko do odczytu, rys. 2 po prostu przedstawia ten fakt.
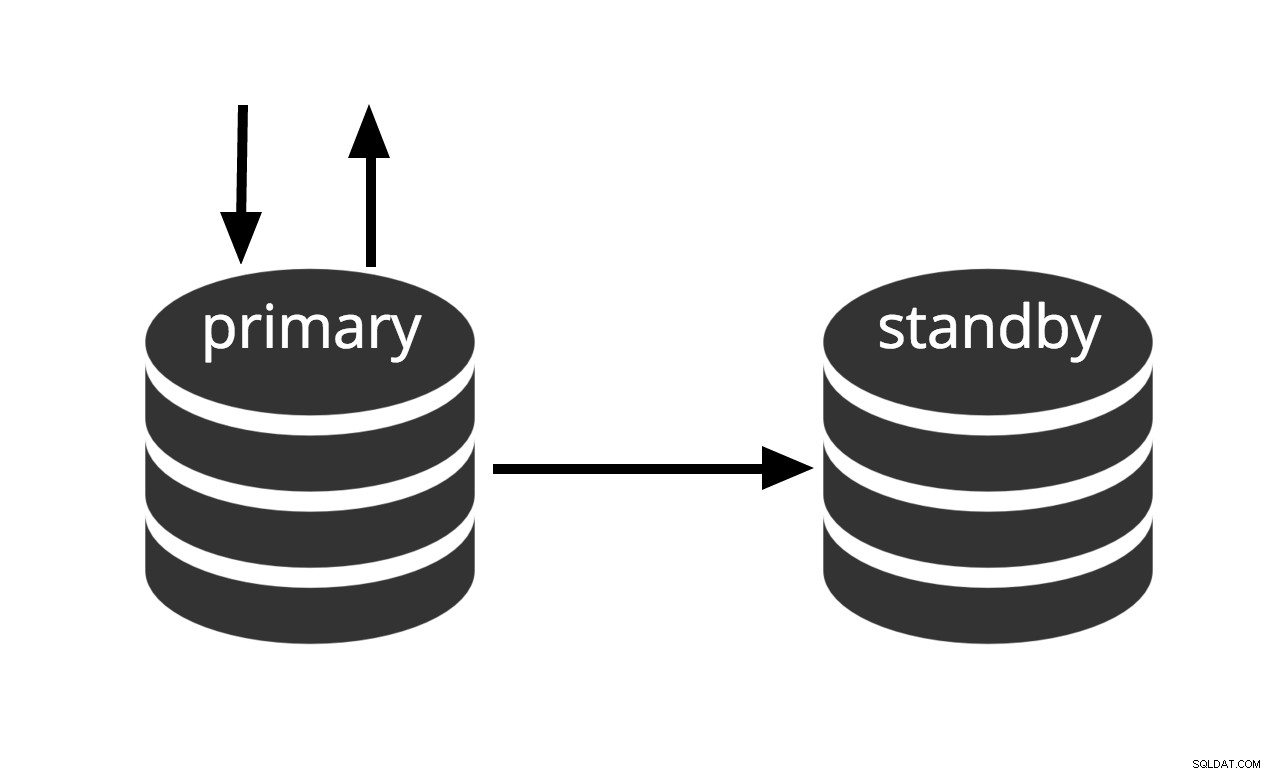
Rys. 2 Ciepły tryb czuwania
Wydajność przywracania ciepłego czuwania jest wystarczająco dobra, aby stan czuwania był zwykle oddalony od pełnej dostępności zaledwie kilka chwil po aktywacji. W rezultacie nazywa się to konfiguracją ciepłego czuwania, która zapewnia wysoką dostępność.
Gorące czuwanie
Hot standby to termin używany do opisania możliwości łączenia się z serwerem i uruchamiania zapytań tylko do odczytu, gdy serwer znajduje się w trybie odzyskiwania archiwów lub w trybie gotowości. Jest to przydatne zarówno do celów replikacji, jak i przywracania kopii zapasowej do pożądanego stanu z dużą precyzją.
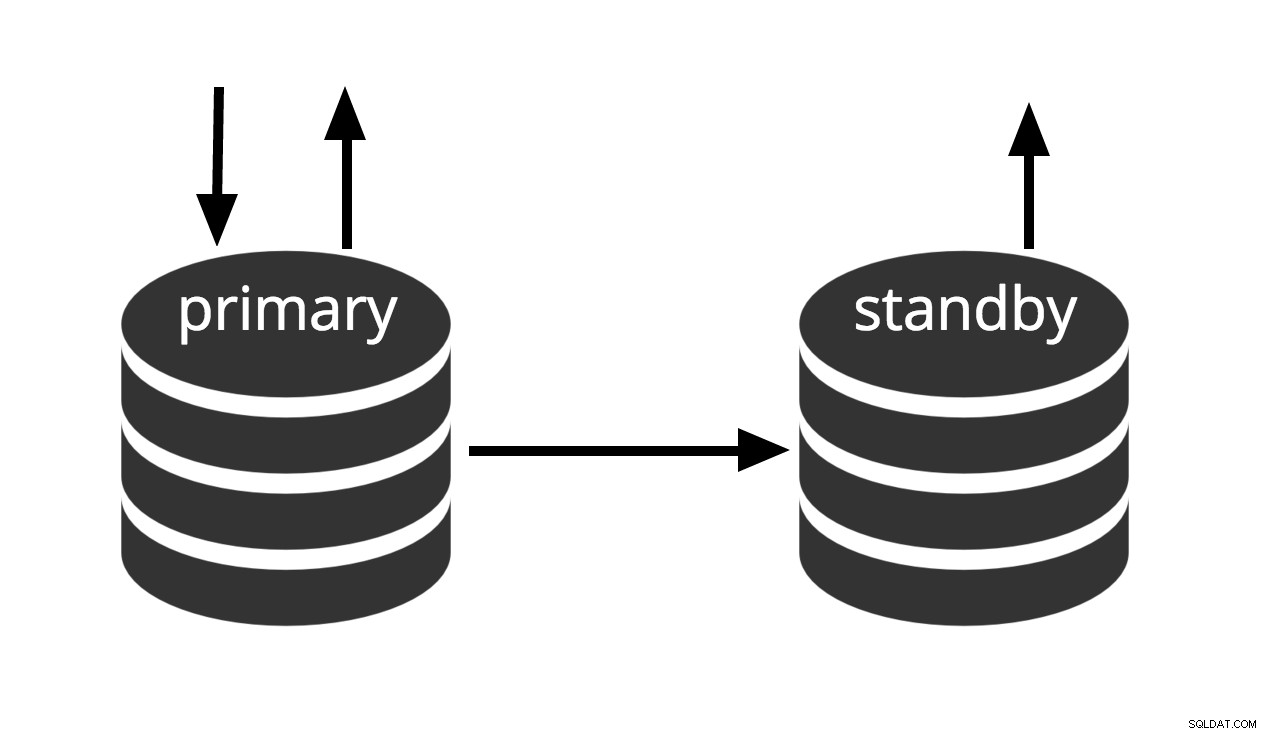 Rys. 3 Hot Standby
Rys. 3 Hot Standby
Termin hot standby odnosi się również do zdolności serwera do przejścia od odzyskiwania do normalnego działania, podczas gdy użytkownicy kontynuują wykonywanie zapytań i/lub utrzymują otwarte połączenia. Rys. 3 pokazuje, że tryb gotowości umożliwia zapytania tylko do odczytu.
Multi-Master
Wszystkie węzły mogą wykonywać pracę odczytu/zapisu. (Architektury multi-master omówimy w kolejnych wpisach na blogu z tej serii).
Parametr poziomu WAL
Istnieje związek między konfiguracją wal_level parametr w pliku postgresql.conf i do czego to ustawienie jest odpowiednie. Stworzyłem tabelę do pokazania relacji dla PostgreSQL w wersji 9.6.

Przełączanie awaryjne i przełączanie
W przypadku replikacji jednego wzorca, jeśli mistrz umrze, jeden z rezerwowych musi zająć jego miejsce (promocja ). W przeciwnym razie nie będziemy mogli zaakceptować nowych transakcji zapisu. Zatem terminy, nadrzędny i rezerwowy, są tylko rolami, które każdy węzeł może w pewnym momencie przyjąć. Aby przenieść rolę główną do innego węzła, wykonujemy procedurę o nazwie Przełącznik .
Jeśli mistrz umrze i nie wyzdrowieje, poważniejsza zmiana ról jest znana jako przełączenie awaryjne . Pod wieloma względami mogą one być podobne, ale pomocne jest użycie różnych terminów dla każdego wydarzenia. (Znajomość warunków przełączania awaryjnego i przełączania pomoże nam zrozumieć problemy z osią czasu w następnym poście na blogu).
Wniosek
W tym poście na blogu omówiliśmy replikację PostgreSQL i jej znaczenie dla zapewnienia odporności na awarie i niezawodności. Omówiliśmy fizyczną replikację strumieniową i omówiliśmy tryby gotowości dla PostgreSQL. Wspomnieliśmy o przełączaniu awaryjnym i przełączaniu. Będziemy kontynuować z osiami czasu PostgreSQL w następnym poście na blogu.
Referencje
Dokumentacja PostgreSQL
Replikacja logiczna w PostgreSQL 5432… Prezentacja MeetUs autorstwa Petra Jelinka
Administracyjna książka kucharska PostgreSQL 9 – wydanie drugie