Podczas poprawiania postgresql.conf , być może zauważyłeś, że istnieje opcja o nazwie full_page_writes . Komentarz obok mówi coś o częściowym zapisie strony, a ludzie zazwyczaj zostawiają to ustawione na on – co jest dobrą rzeczą, jak wyjaśnię w dalszej części tego postu. Warto jednak zrozumieć, co robią zapisy całej strony, ponieważ wpływ na wydajność może być dość znaczący.
W przeciwieństwie do mojego poprzedniego postu na temat tuningu punktów kontrolnych, nie jest to poradnik jak dostroić serwer. Niewiele można zmienić, naprawdę, ale pokażę ci, jak niektóre decyzje na poziomie aplikacji (np. wybór typów danych) mogą wchodzić w interakcje z zapisem całej strony.
Częściowe zapisy / podarte strony
Więc o czym pisze cała strona? Jako komentarz w postgresql.conf mówi, że jest to sposób na odzyskanie częściowego zapisu strony – PostgreSQL używa stron 8kB (domyślnie), ale inne części stosu używają różnych rozmiarów porcji. Linuxowe systemy plików zazwyczaj używają 4kB stron (możliwe jest użycie mniejszych stron, ale 4kB to maksimum na x86), a na poziomie sprzętowym stare dyski używały 512B sektorów, podczas gdy nowe urządzenia często zapisują dane w większych porcjach (często 4kB lub nawet 8kB) .
Tak więc, gdy PostgreSQL zapisuje stronę o wielkości 8kB, inne warstwy stosu pamięci masowej mogą podzielić ją na mniejsze kawałki, zarządzane oddzielnie. Stanowi to problem dotyczący atomowości zapisu. Strona 8kB PostgreSQL może zostać podzielona na dwie 4kB strony systemu plików, a następnie na 512B sektorów. A co jeśli serwer ulegnie awarii (awaria zasilania, błąd jądra, …)?
Nawet jeśli serwer korzysta z systemu pamięci masowej zaprojektowanego do radzenia sobie z takimi awariami (dyski SSD z kondensatorami, kontrolery RAID z bateriami,…), jądro już podzieliło dane na 4kB strony. Możliwe więc, że baza danych zapisała stronę danych 8kB, ale tylko jej część trafiła na dysk przed awarią.
W tym momencie prawdopodobnie myślisz, że właśnie dlatego mamy dziennik transakcji (WAL) i masz rację! Tak więc po uruchomieniu serwera baza danych odczyta WAL (od ostatniego ukończonego punktu kontrolnego) i ponownie zastosuje zmiany, aby upewnić się, że pliki danych są kompletne. Proste.
Ale jest pewien haczyk – odzyskiwanie nie stosuje zmian na ślepo, często musi czytać strony z danymi itp. Co zakłada, że strona nie jest już w jakiś sposób zakorkowana, na przykład z powodu częściowego zapisu. Co wydaje się nieco wewnętrznie sprzeczne, ponieważ aby naprawić uszkodzenie danych, zakładamy, że nie ma uszkodzenia danych.
Zapisywanie całej strony jest sposobem na obejście tej zagadki – podczas modyfikowania strony po raz pierwszy po punkcie kontrolnym, cała strona jest zapisywana w WAL. Gwarantuje to, że podczas odzyskiwania pierwszy rekord WAL dotykający strony zawiera całą stronę, eliminując potrzebę odczytywania – prawdopodobnie uszkodzonej – strony z pliku danych.
Wzmocnienie zapisu
Oczywiście negatywną konsekwencją tego jest zwiększony rozmiar WAL-a – zmiana pojedynczego bajtu na stronie 8kB spowoduje zalogowanie całości do WAL-a. Zapis całej strony ma miejsce tylko przy pierwszym zapisie po punkcie kontrolnym, więc zmniejszenie częstotliwości punktów kontrolnych jest jednym ze sposobów na poprawę sytuacji — zazwyczaj następuje krótki „wybuch” zapisów całej strony po punkcie kontrolnym, a następnie stosunkowo niewiele zapisów na całej stronie do końca punktu kontrolnego.
Klucze UUID kontra BIGSERIAL
Ale są pewne nieoczekiwane interakcje z decyzjami projektowymi podejmowanymi na poziomie aplikacji. Załóżmy, że mamy prostą tabelę z kluczem podstawowym, albo BIGSERIAL lub UUID i wstawiamy do niego dane. Czy będzie różnica w ilości wygenerowanego WAL (zakładając, że wstawimy taką samą liczbę wierszy)?
Rozsądne wydaje się oczekiwanie, że oba przypadki wygenerują mniej więcej taką samą ilość WAL, ale jak pokazują poniższe wykresy, w praktyce istnieje ogromna różnica.
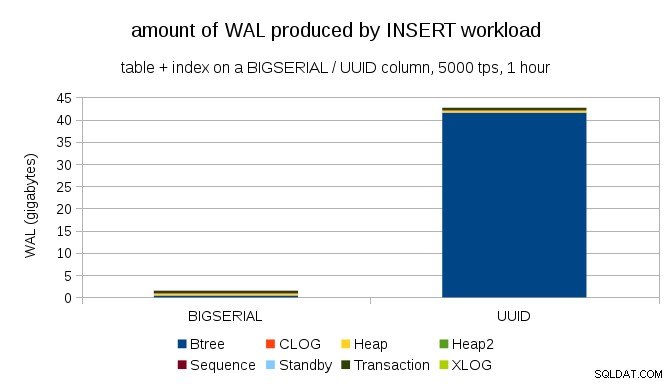
Pokazuje to ilość WAL wyprodukowanego podczas 1-godzinnego testu porównawczego, zdławionego do 5000 wkładek na sekundę. Z BIGSERIAL klucz podstawowy, który daje ~2 GB WAL, podczas gdy z UUID to ponad 40 GB. To dość znacząca różnica i wyraźnie większość WAL jest związana z indeksem wspierającym klucz podstawowy. Spójrzmy na typy rekordów WAL.
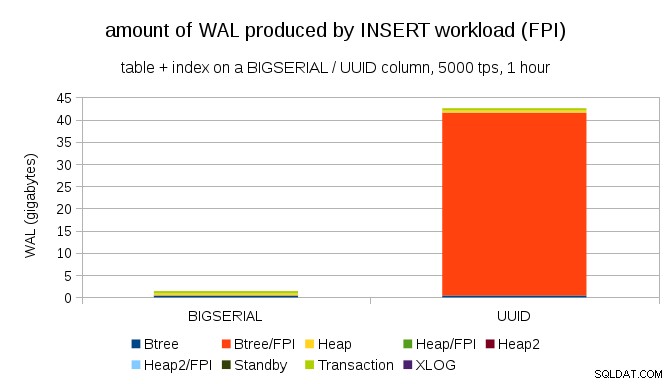
Oczywiście zdecydowana większość rekordów to obrazy całostronicowe (FPI), czyli wynik zapisów całostronicowych. Ale dlaczego tak się dzieje?
Oczywiście wynika to z nieodłącznego UUID losowość. Z BIGSERIAL nowe są sekwencyjne, a więc są wstawiane do tych samych stron liści w indeksie btree. Ponieważ tylko pierwsza modyfikacja strony wyzwala zapis całej strony, tylko niewielka część rekordów WAL to FPI. Z UUID jest to oczywiście zupełnie inny przypadek – wartości w ogóle nie są sekwencyjne, w rzeczywistości każda wstawka prawdopodobnie dotknie zupełnie nowej strony liścia indeksu liścia (zakładając, że indeks jest wystarczająco duży).
Baza danych niewiele może zrobić – obciążenie ma po prostu charakter losowy, co powoduje wiele zapisów na całej stronie.
Nie jest trudno uzyskać podobne wzmocnienie zapisu nawet z BIGSERIAL klucze, oczywiście. Wymaga tylko innego obciążenia – na przykład z UPDATE obciążenie pracą, losowe aktualizowanie rekordów z równomiernym rozkładem, wykres wygląda tak:
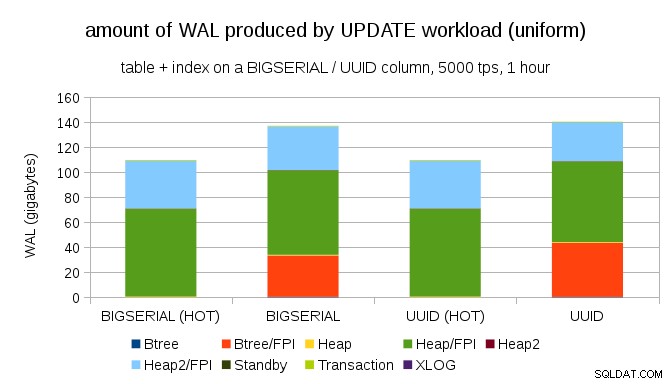
Nagle znikają różnice między typami danych – dostęp jest losowy w obu przypadkach, co skutkuje prawie taką samą ilością wyprodukowanego WAL-a. Kolejna różnica polega na tym, że większość WAL jest powiązana ze „stertą”, tj. tabelami, a nie indeksami. Przypadki „HOT” zostały zaprojektowane tak, aby umożliwić optymalizację HOT UPDATE (tj. aktualizację bez konieczności dotykania indeksu), co praktycznie eliminuje cały ruch WAL związany z indeksem.
Ale możesz argumentować, że większość aplikacji nie aktualizuje całego zestawu danych. Zwykle tylko niewielki podzbiór danych jest „aktywny” – ludzie uzyskują dostęp tylko do postów z ostatnich kilku dni na forum dyskusyjnym, nierozwiązanych zamówień w sklepie internetowym itp. Jak to zmienia wyniki?
Na szczęście pgbench obsługuje rozkłady niejednolite i na przykład w przypadku rozkładu wykładniczego dotykającego 1% podzbioru danych ~25% czasu wykres wygląda tak:
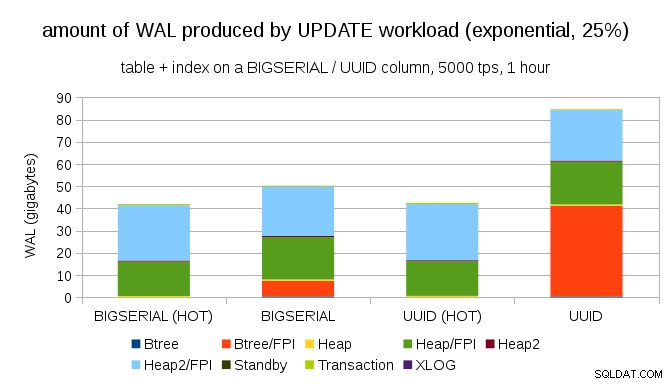
A po jeszcze bardziej przekrzywionym rozkładzie, dotykając podzbioru 1% w ~75% przypadków:
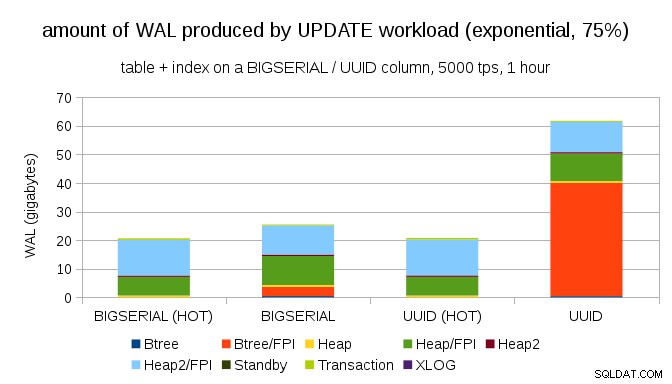
To ponownie pokazuje, jak dużą różnicę może mieć wybór typów danych, a także znaczenie strojenia pod kątem aktualizacji HOT.
Strony 8kB i 4kB
Ciekawym pytaniem jest, ile ruchu WAL możemy zaoszczędzić, używając mniejszych stron w PostgreSQL (co wymaga kompilacji niestandardowego pakietu). W najlepszym przypadku może zaoszczędzić nawet 50% WAL, dzięki logowaniu tylko 4kB zamiast 8kB stron. W przypadku obciążenia z równomiernie rozłożonymi aktualizacjami wygląda to tak:
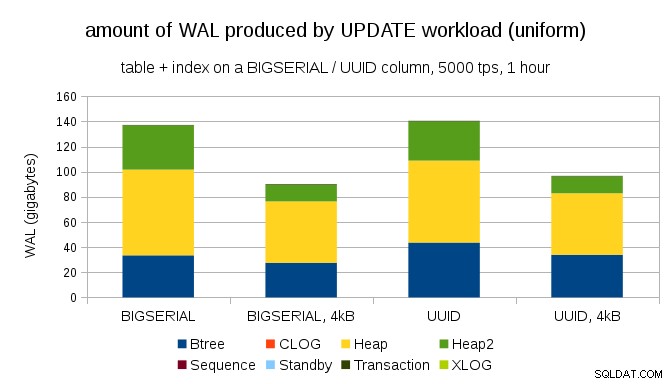
Tak więc oszczędność nie wynosi dokładnie 50%, ale zmniejszenie z ~140 GB do ~90 GB jest nadal dość znaczące.
Czy nadal potrzebujemy zapisów na całą stronę?
Może się to wydawać śmieszne po wyjaśnieniu niebezpieczeństwa częściowych zapisów, ale być może wyłączenie pełnego zapisu strony może być realną opcją, przynajmniej w niektórych przypadkach.
Po pierwsze, zastanawiam się, czy współczesne systemy plików Linux są nadal podatne na częściowe zapisy? Parametr został wprowadzony w PostgreSQL 8.1 wydanym w 2005 roku, więc być może niektóre z wielu ulepszeń systemu plików wprowadzonych od tego czasu sprawiają, że nie stanowi to problemu. Prawdopodobnie nie jest to uniwersalne dla dowolnych obciążeń, ale może wystarczyłoby założenie jakiegoś dodatkowego warunku (np. użycie rozmiaru strony 4kB w PostgreSQL)? Ponadto PostgreSQL nigdy nie nadpisuje tylko podzbioru strony 8kB – cała strona jest zawsze napisana.
Przeprowadziłem ostatnio wiele testów próbujących wywołać częściowy zapis i nie udało mi się jeszcze spowodować ani jednego przypadku. Oczywiście nie jest to tak naprawdę dowód na to, że problem nie istnieje. Ale nawet jeśli nadal jest to problem, sumy kontrolne danych mogą być wystarczającą ochroną (nie rozwiąże problemu, ale przynajmniej poinformuje Cię, że strona jest uszkodzona).
Po drugie, obecnie wiele systemów opiera się na przesyłaniu strumieniowym replik replikacji — zamiast czekać na ponowne uruchomienie serwera po problemie ze sprzętem (co może zająć dość dużo czasu), a następnie spędzać więcej czasu na odzyskiwaniu, systemy po prostu przełączają się w tryb gotowości. Jeśli baza danych z uszkodzonej bazy zostanie usunięta (a następnie sklonowana z nowej bazy), częściowe zapisy nie stanowią problemu.
Ale myślę, że gdybyśmy zaczęli to zalecać, to „Nie wiem, jak dane zostały uszkodzone, właśnie ustawiłem full_page_writes=off w systemach!” stanie się jednym z najczęstszych zdań tuż przed śmiercią dla administratorów baz danych (razem z „Widziałem tego węża na Reddicie, nie jest trujący”).
Podsumowanie
Niewiele można zrobić, aby bezpośrednio dostroić zapisy na całej stronie. W przypadku większości obciążeń większość zapisów na całej stronie ma miejsce zaraz po punkcie kontrolnym, a następnie znika do następnego punktu kontrolnego. Dlatego ważne jest, aby dostroić punkty kontrolne, aby nie zdarzały się zbyt często.
Niektóre decyzje na poziomie aplikacji mogą zwiększać losowość zapisów w tabelach i indeksach — na przykład wartości UUID są z natury losowe, zamieniając nawet proste obciążenie INSERT w losowe aktualizacje indeksu. Schemat użyty w przykładach był raczej banalny – w praktyce będą indeksy wtórne, klucze obce itp. Ale użycie kluczy głównych BIGSERIAL wewnętrznie (i zachowanie UUID jako kluczy zastępczych) przynajmniej zmniejszy wzmocnienie zapisu.
Jestem naprawdę zainteresowany dyskusją o potrzebie całostronicowych zapisów na aktualnych jądrach / systemach plików. Niestety nie znalazłem wielu zasobów, więc jeśli masz odpowiednie informacje, daj mi znać.