Miałem przyjemność uczestniczyć w PGDay UK w zeszłym tygodniu – bardzo fajne wydarzenie, mam nadzieję, że będę miał okazję wrócić w przyszłym roku. Było wiele ciekawych prelekcji, ale ta, która szczególnie przykuła moją uwagę, to Performace dla zapytań z grupowaniem Aleksieja Basztanowa.
Wygłosiłem w przeszłości sporo podobnych rozmów nastawionych na wydajność, więc wiem, jak trudno jest przedstawić wyniki benchmarków w zrozumiały i interesujący sposób, a Alexey wykonał całkiem niezłą robotę. Więc jeśli masz do czynienia z agregacją danych (tj. BI, analityką lub podobnymi obciążeniami), polecam przejrzenie slajdów, a jeśli masz szansę wziąć udział w wystąpieniu na innej konferencji, gorąco to polecam.
Ale jest jeden punkt, w którym nie zgadzam się z przemówieniem. W wielu miejscach rozmowa sugerowała, że generalnie powinieneś preferować HashAggregate, ponieważ sortowanie jest powolne.
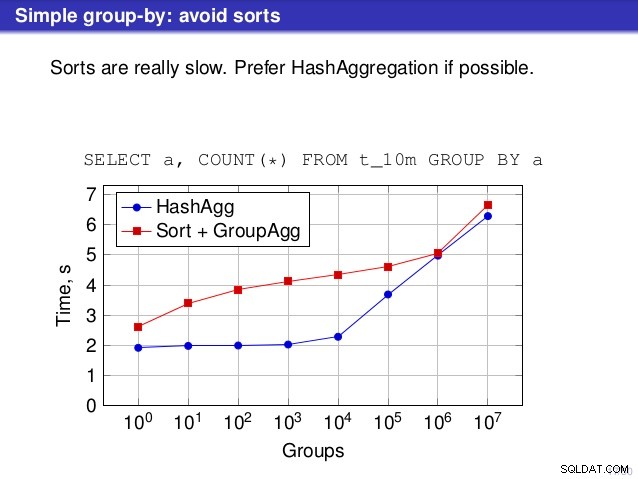
Uważam to za nieco mylące, ponieważ alternatywą dla HashAggregate jest GroupAggregate, a nie Sort. Tak więc zalecenie zakłada, że każda grupa GroupAggregate ma zagnieżdżone sortowanie, ale to nie do końca prawda. GroupAggregate wymaga posortowanych danych wejściowych, a jawne sortowanie nie jest jedynym sposobem na to – mamy również węzły IndexScan i IndexOnlyScan, które eliminują koszty sortowania i zachowują inne korzyści związane z posortowanymi ścieżkami (zwłaszcza IndexOnlyScan).
Pozwolę sobie zademonstrować, jak działa (IndexOnlyScan+GroupAggregate) w porównaniu z HashAggregate i (Sort+GroupAggregate) – skrypt, którego użyłem do pomiarów, jest tutaj. Buduje cztery proste tabele, każda z 100 milionami wierszy i różną liczbą grup w kolumnie „branch_id” (określającą rozmiar tablicy haszującej). Najmniejszy ma 10 tys. grup
-- table with 10k groups create table t_10000 (branch_id bigint, amount numeric); insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
a trzy dodatkowe stoły mają grupy 100k, 1M i 5M. Uruchommy to proste zapytanie agregujące dane:
SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1
a następnie przekonaj bazę danych do korzystania z trzech różnych planów:
1) HashAggregat
SET enable_sort = off;
SET enable_hashagg = on;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
----------------------------------------------------------------------------
HashAggregate (cost=2136943.00..2137067.99 rows=9999 width=40)
Group Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 width=19)
(3 rows) 2) GroupAggregate (z sortowaniem)
SET enable_sort = on;
SET enable_hashagg = off;
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
-------------------------------------------------------------------------------
GroupAggregate (cost=16975438.38..17725563.37 rows=9999 width=40)
Group Key: branch_id
-> Sort (cost=16975438.38..17225438.38 rows=100000000 width=19)
Sort Key: branch_id
-> Seq Scan on t_10000 (cost=0.00..1636943.00 rows=100000000 ...)
(5 rows) 3) GroupAggregate (z IndexOnlyScan)
SET enable_sort = on;
SET enable_hashagg = off;
CREATE INDEX ON t_10000 (branch_id, amount);
EXPLAIN SELECT branch_id, SUM(amount) FROM t_10000 GROUP BY 1;
QUERY PLAN
--------------------------------------------------------------------------
GroupAggregate (cost=0.57..3983129.56 rows=9999 width=40)
Group Key: branch_id
-> Index Only Scan using t_10000_branch_id_amount_idx on t_10000
(cost=0.57..3483004.57 rows=100000000 width=19)
(3 rows) Wyniki
Po zmierzeniu czasów dla każdego planu na wszystkich stołach wyniki wyglądają tak:
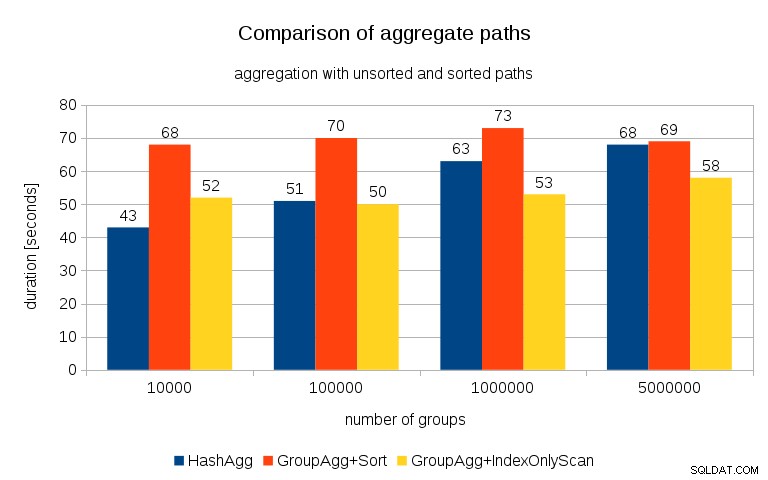
W przypadku małych tablic mieszających (pasujących do pamięci podręcznej L3, która w tym przypadku wynosi 16 MB), ścieżka HashAggregate jest wyraźnie szybsza niż obie posortowane ścieżki. Ale wkrótce GroupAgg+IndexOnlyScan będzie równie szybki, a nawet szybszy – wynika to z wydajności pamięci podręcznej, głównej zalety GroupAggregate. Podczas gdy HashAggregate musi jednocześnie przechowywać w pamięci całą tabelę skrótów, GroupAggregate musi przechowywać tylko ostatnią grupę. A im mniej pamięci używasz, tym bardziej prawdopodobne jest, że zmieści się ją w pamięci podręcznej L3, która jest mniej więcej o rząd wielkości szybsza w porównaniu ze zwykłą pamięcią RAM (w przypadku pamięci podręcznych L1/L2 różnica jest jeszcze większa).
Tak więc, mimo że IndexOnlyScan wiąże się ze znacznym obciążeniem (w przypadku 10 tys. jest o około 20% wolniejszy niż ścieżka HashAggregate), w miarę wzrostu tabeli haszowania współczynnik trafień w pamięci podręcznej L3 szybko spada, a różnica ostatecznie sprawia, że GroupAggregate jest szybszy. I ostatecznie nawet GroupAggregate+Sort staje się na równi ze ścieżką HashAggregate.
Możesz argumentować, że twoje dane mają zazwyczaj dość małą liczbę grup, a zatem tablica mieszająca zawsze zmieści się w pamięci podręcznej L3. Należy jednak wziąć pod uwagę, że pamięć podręczna L3 jest współdzielona przez wszystkie procesy działające na procesorze, a także przez wszystkie części planu zapytań. Więc chociaż obecnie mamy ~20 MB pamięci podręcznej L3 na gniazdo, twoje zapytanie otrzyma tylko część tego, a ten bit będzie współdzielony przez wszystkie węzły w twoim (prawdopodobnie dość złożonym) zapytaniu.
Aktualizacja 2016/07/26 :Jak wskazano w komentarzach Petera Geoghegana, sposób generowania danych prawdopodobnie prowadzi do korelacji – nie wartości (czy raczej skrótów wartości), ale alokacji pamięci. Powtórzyłem zapytania z odpowiednio dobranymi danymi, czyli robiąc
insert into t_10000 select (10000*random())::bigint, random() from generate_series(1,100000000) s(i);
zamiast
insert into t_10000 select mod(i, 10000), random() from generate_series(1,100000000) s(i);
a wyniki wyglądają tak:
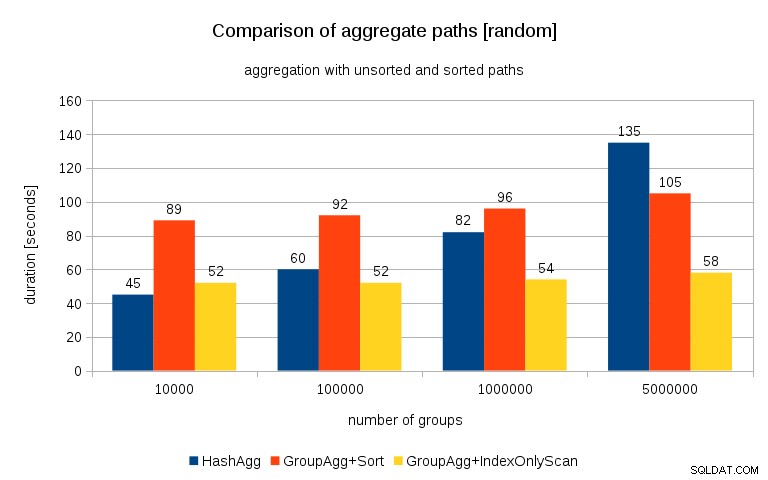
Porównując to z poprzednim wykresem, myślę, że jest całkiem jasne, że wyniki są jeszcze bardziej na korzyść posortowanych ścieżek, szczególnie dla zestawu danych z grupami 5M. Zestaw danych 5M pokazuje również, że GroupAgg z jawnym sortowaniem może być szybszy niż HashAgg.
Podsumowanie
Chociaż HashAggregate jest prawdopodobnie szybszy niż GroupAggregate z jawnym sortowaniem (choć waham się, czy tak jest zawsze), użycie GroupAggregate z IndexOnlyScan szybciej może z łatwością sprawić, że będzie on znacznie szybszy niż HashAggregate.
Oczywiście nie możesz bezpośrednio wybrać dokładnego planu – planista powinien to zrobić za Ciebie. Ale wpływasz na proces selekcji, (a) tworząc indeksy i (b) ustawiając work_mem . Dlatego czasami obniżamy wartość work_mem (i maintenance_work_mem ) wartości zapewniają lepszą wydajność.
Dodatkowe indeksy nie są jednak darmowe – kosztują zarówno czas procesora (przy wstawianiu nowych danych), jak i miejsce na dysku. W przypadku IndexOnlyScans wymagania dotyczące miejsca na dysku mogą być dość znaczące, ponieważ indeks musi zawierać wszystkie kolumny, do których odwołuje się zapytanie, a zwykły IndexScan nie zapewni takiej samej wydajności, ponieważ generuje wiele losowych operacji we/wy na tabeli (eliminując wszystkie potencjalne zyski).
Kolejną fajną cechą jest stabilność wydajności – zauważ, jak szanse na czasy HashAggregate zależą od liczby grup, podczas gdy ścieżki GroupAggregate działają w większości tak samo.