PostgreSQL to niesamowity projekt, który rozwija się w niesamowitym tempie. Skoncentrujemy się na ewolucji możliwości odporności na awarie w PostgreSQL we wszystkich jego wersjach w serii wpisów na blogu. To jest trzeci post z serii. Porozmawiamy o problemach z osią czasu i ich wpływie na odporność na błędy i niezawodność PostgreSQL.
Jeśli chcesz być świadkiem postępu ewolucji od samego początku, zapoznaj się z dwoma pierwszymi wpisami na blogu z tej serii:
- Ewolucja tolerancji błędów w PostgreSQL
- Ewolucja tolerancji błędów w PostgreSQL:faza replikacji

Osie czasu
Możliwość przywrócenia bazy danych do poprzedniego punktu w czasie stwarza pewne komplikacje, które omówimy w niektórych przypadkach, wyjaśniając przełączanie awaryjne (rys. 1), przełączenie (rys. 2) i pg_rewind (Rys. 3) przypadki w dalszej części tego tematu.
Na przykład w oryginalnej historii bazy danych załóżmy, że upuściłeś krytyczną tabelę o 17:15 we wtorek wieczorem, ale nie zauważyłeś swojego błędu aż do środy w południe. Niezrażony, wyjmujesz kopię zapasową, przywracasz do punktu w czasie o 17:14 we wtorek wieczorem i działasz. W tej historii wszechświata baz danych nigdy nie upuściłeś tabeli. Ale przypuśćmy, że później zdasz sobie sprawę, że to nie był taki świetny pomysł, i chciałbyś wrócić do pewnego środowego poranka w oryginalnej historii. Nie będziesz w stanie tego zrobić, jeśli podczas gdy Twoja baza danych była uruchomiona, nadpisała niektóre pliki segmentowe WAL, które doprowadziły do czasu, do którego chciałbyś wrócić.
Dlatego, aby tego uniknąć, musisz odróżnić serię rekordów WAL wygenerowanych po wykonaniu odzyskiwania do określonego momentu od tych, które zostały wygenerowane w oryginalnej historii bazy danych.
Aby poradzić sobie z tym problemem, PostgreSQL ma pojęcie osi czasu. Po zakończeniu odzyskiwania archiwum tworzona jest nowa oś czasu w celu zidentyfikowania serii rekordów WAL wygenerowanych po tym odzyskaniu. Numer identyfikacyjny osi czasu jest częścią nazw plików segmentu WAL, więc nowa oś czasu nie zastępuje danych WAL wygenerowanych przez poprzednie osie czasu. W rzeczywistości możliwe jest archiwizowanie wielu różnych osi czasu.
Rozważ sytuację, w której nie jesteś do końca pewien, do którego punktu w czasie chcesz odzyskać, i musisz wykonać kilka odzyskiwania do określonego momentu metodą prób i błędów, aż znajdziesz najlepsze miejsce do odejścia od starej historii. Bez terminów proces ten wkrótce wytworzy niemożliwy do opanowania bałagan. Dzięki osiom czasu możesz przywrócić dowolny wcześniejszy stan, w tym stany w gałęziach osi czasu, które wcześniej porzuciłeś.
Za każdym razem, gdy tworzona jest nowa oś czasu, PostgreSQL tworzy plik „historii osi czasu”, który pokazuje, z której osi czasu się rozgałęziło i kiedy. Te pliki historii są niezbędne, aby system mógł wybrać właściwe pliki segmentowe WAL podczas odzyskiwania z archiwum zawierającego wiele osi czasu. Dlatego są one archiwizowane w obszarze archiwum WAL, podobnie jak pliki segmentowe WAL. Pliki historii to tylko małe pliki tekstowe, więc tanie i odpowiednie jest ich przechowywanie w nieskończoność (w przeciwieństwie do plików segmentowych, które są duże). Jeśli chcesz, możesz dodać komentarze do pliku historii, aby zapisać własne notatki dotyczące tego, jak i dlaczego utworzono tę konkretną oś czasu. Takie komentarze będą szczególnie cenne, gdy w wyniku eksperymentów masz gąszcz różnych osi czasu.
Domyślnym zachowaniem odzyskiwania jest odzyskiwanie według tej samej osi czasu, która była aktualna podczas wykonywania podstawowej kopii zapasowej. Jeśli chcesz odzyskać do jakiejś podrzędnej osi czasu (to znaczy, że chcesz powrócić do stanu, który sam został wygenerowany po próbie odzyskania), musisz określić identyfikator docelowej osi czasu w pliku recovery.conf. Nie można odzyskać do osi czasu, które rozgałęziły się wcześniej niż podstawowa kopia zapasowa.
Aby uprościć koncepcję osi czasu w PostgreSQL, problemy związane z osią czasu w przypadku przełączenia awaryjnego , przełączenie i pg_rewind są podsumowane i wyjaśnione na rys.1, rys.2 i rys.3.
Scenariusz pracy awaryjnej:
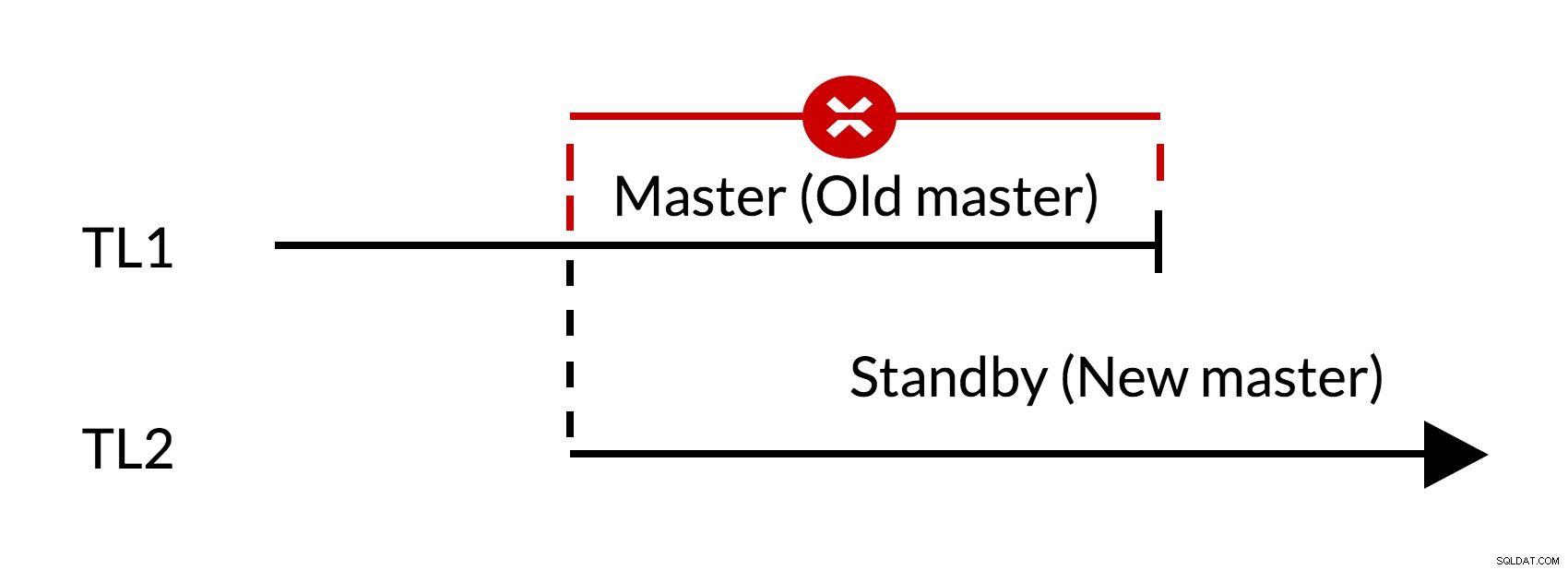
Rys.1 Przełączanie awaryjne
- Istnieją zaległe zmiany w starym wzorcu (TL1)
- Wzrost osi czasu reprezentuje nową historię zmian (TL2)
- Zmiany ze starej osi czasu nie mogą być odtwarzane na serwerach, które przeszły na nową oś czasu
- Stary mistrz nie może podążać za nowym mistrzem
Scenariusz przełączania:
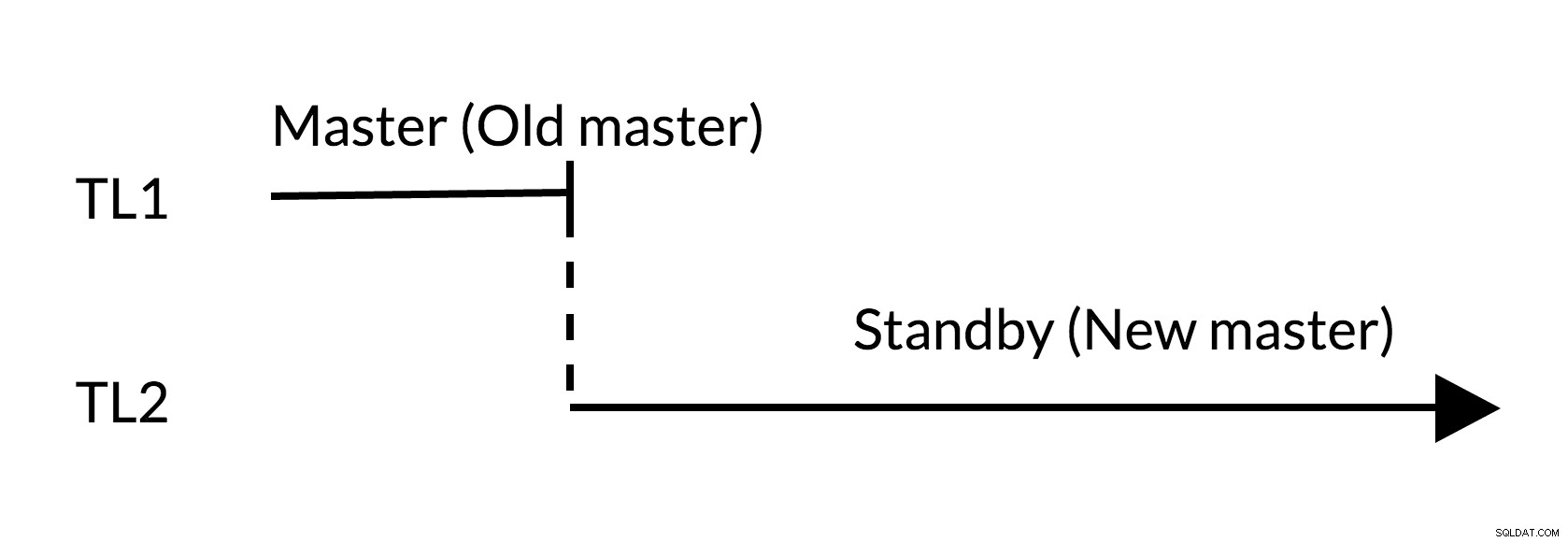 Rys.2 Przełączanie
Rys.2 Przełączanie
- Nie ma zaległych zmian w starym wzorcu (TL1)
- Wzrost na osi czasu reprezentuje nową historię zmian (TL2)
- Stary wzorzec może stać się w stanie gotowości dla nowego wzorca
pg_rewind scenariusz:
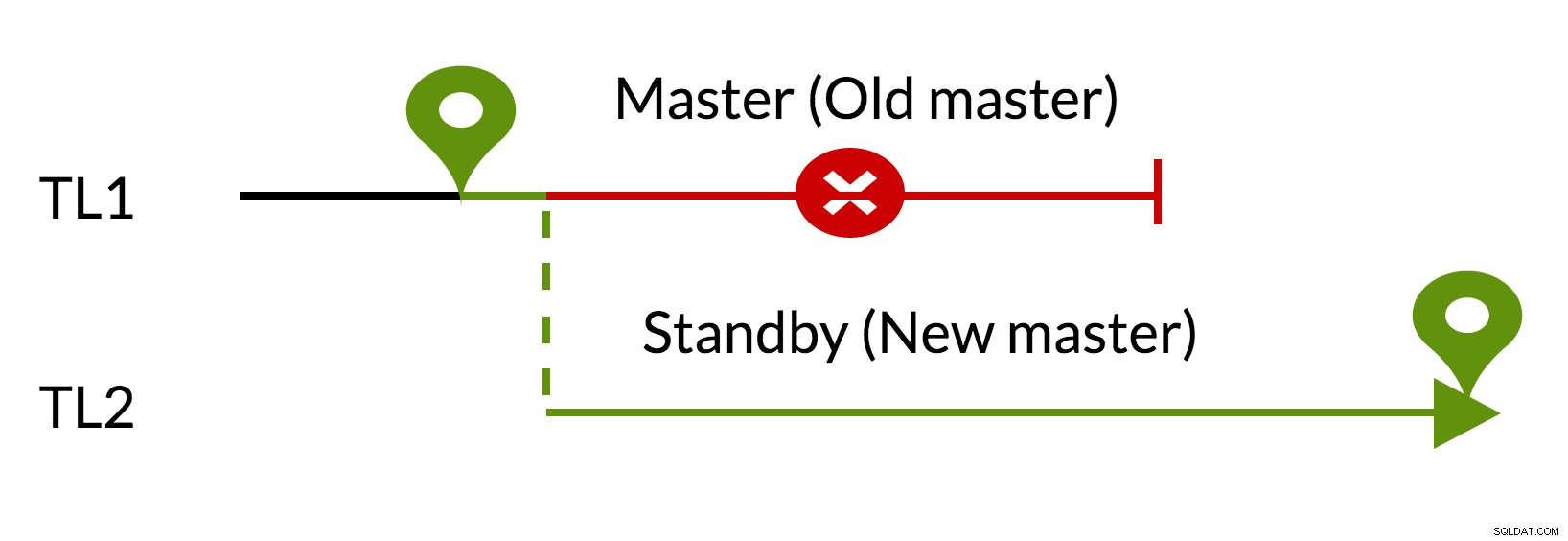 Rys. 3 pg_rewind
Rys. 3 pg_rewind
- Zaległe zmiany są usuwane przy użyciu danych z nowego wzorca (TL1)
- Stary mistrz może podążać za nowym mistrzem (TL2)
pg_rewind
pg_rewind to narzędzie do synchronizowania klastra PostgreSQL z inną kopią tego samego klastra, po rozbieżności osi czasu klastrów. Typowym scenariuszem jest przywrócenie starego serwera głównego do trybu online po przełączeniu awaryjnym, jako rezerwy, która następuje po nowym serwerze głównym.
Wynik jest równoznaczny z zastąpieniem docelowego katalogu danych katalogiem źródłowym. Kopiowane są wszystkie pliki, w tym pliki konfiguracyjne. Zaletą pg_rewind nad pobieraniem nowej podstawowej kopii zapasowej lub narzędzi takich jak rsync jest to, że pg_rewind nie wymaga odczytywania wszystkich niezmienionych plików w klastrze. To znacznie przyspiesza, gdy baza danych jest duża i tylko niewielka jej część różni się między klastrami.
Jak to działa?
Podstawowym pomysłem jest skopiowanie wszystkiego z nowego klastra do starego klastra, z wyjątkiem bloków, o których wiemy, że są takie same.
- Skanuj dziennik WAL starego klastra, zaczynając od ostatniego punktu kontrolnego przed punktem, w którym historia osi czasu nowego klastra oddzieliła się od starego klastra. Dla każdego rekordu WAL zanotuj bloki danych, które zostały dotknięte. Daje to listę wszystkich bloków danych, które zostały zmienione w starym klastrze po rozwidleniu nowego klastra.
- Skopiuj wszystkie zmienione bloki z nowego klastra do starego klastra.
- Skopiuj wszystkie inne pliki, takie jak zatykanie i pliki konfiguracyjne, z nowego klastra do starego klastra, wszystko oprócz plików relacji.
- Zastosuj WAL z nowego klastra, zaczynając od punktu kontrolnego utworzonego podczas przełączania awaryjnego. (Ściśle mówiąc, pg_rewind nie stosuje WAL, po prostu tworzy plik etykiety kopii zapasowej wskazujący, że po uruchomieniu PostgreSQL rozpocznie odtwarzanie od tego punktu kontrolnego i zastosuje wszystkie wymagane WAL.)
Uwaga: wal_log_hints musi być ustawiony w postgresql.conf, aby pg_rewind mógł działać. Ten parametr można ustawić tylko podczas uruchamiania serwera. Wartość domyślna to wył .
Wniosek
W tym poście na blogu omówiliśmy ramy czasowe w Postgres oraz sposób, w jaki radzimy sobie z przypadkami przełączania awaryjnego i przełączania. Rozmawialiśmy również o tym, jak działa pg_rewind i jego zalety dla odporności na błędy i niezawodności Postgresa. Będziemy kontynuować zatwierdzanie synchroniczne w następnym poście na blogu.
Referencje
Dokumentacja PostgreSQL
Książka kucharska administracji PostgreSQL 9 – wydanie drugie
pg_rewind Prezentacja na Nordic PGDay autorstwa Heikki Linnakangasa