Ten artykuł zawiera przewodnik krok po kroku dotyczący wykorzystania możliwości uczenia maszynowego z 2UDA. W artykule użyjemy przykładu Zwierząt, aby przewidzieć, czy są to ssaki, ptaki, ryby czy owady.
Wersje oprogramowania
Do implementacji modelu uczenia maszynowego użyjemy wersji 2UDA 11.6-1. 2UDA w wersji 11.6-1 łączy:
- PostgreSQL 11.6
- Pomarańczowy 3.23.0
Najnowszą wersję 2UDA znajdziesz tutaj.
Krok 1:Załaduj treningowy zestaw danych do PostgreSQL
Przykładowy zestaw danych używany do trenowania naszego modelu jest dostępny w oficjalnym repozytorium Orange GitHub tutaj.
Wykonaj poniższe czynności, aby załadować dane treningowe do tabel PostgreSQL:
- Połącz się z PostgreSQL przez psql, OmniDB lub inne narzędzie, które znasz.
- Utwórz tabelę do przechowywania naszych danych treningowych . Tutaj nazywa się to training_data.
CREATE TABLE training_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Wstaw dane treningowe do tabeli za pomocą zapytania COPY. Przed wykonaniem zapytania COPY upewnij się, że PostgreSQL wymaga uprawnień do odczytu pliku danych, w przeciwnym razie operacja COPY nie powiedzie się.
UWAGA: Upewnij się, że wpisujesz kartę spacja między pojedynczymi cudzysłowami po ograniczniku słowo kluczowe.
COPY training_data FROM 'Path_to_training_data_file’ with delimiter ' ' csv header;
Zrzut ekranu zestawu danych treningowych znajduje się poniżej
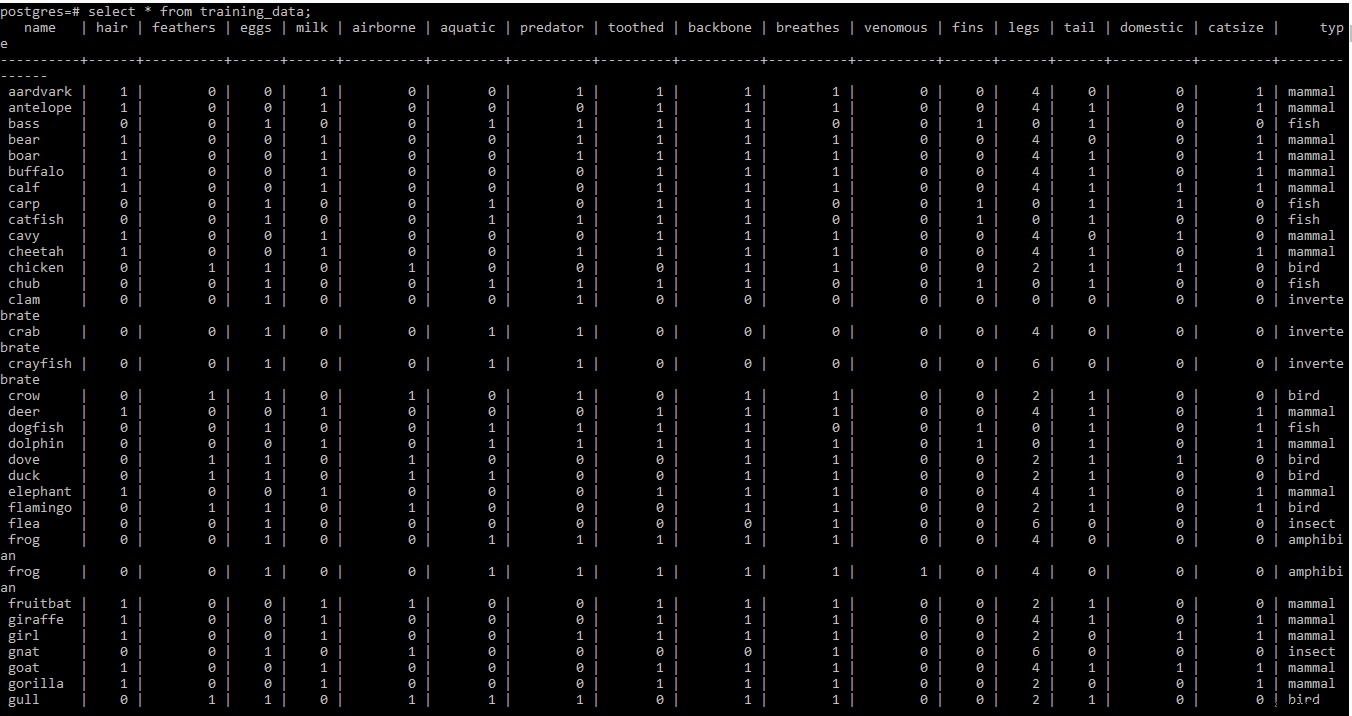
UWAGA: Drugi i trzeci wiersz treningowego zbioru danych w .tab plik zawiera pewne informacje meta. Ponieważ w tym momencie nie jest potrzebny, został usunięty z pliku.
Krok 2:Utwórz przepływ pracy w Orange
- Przejdź do pulpitu i kliknij dwukrotnie pomarańczową ikonę.
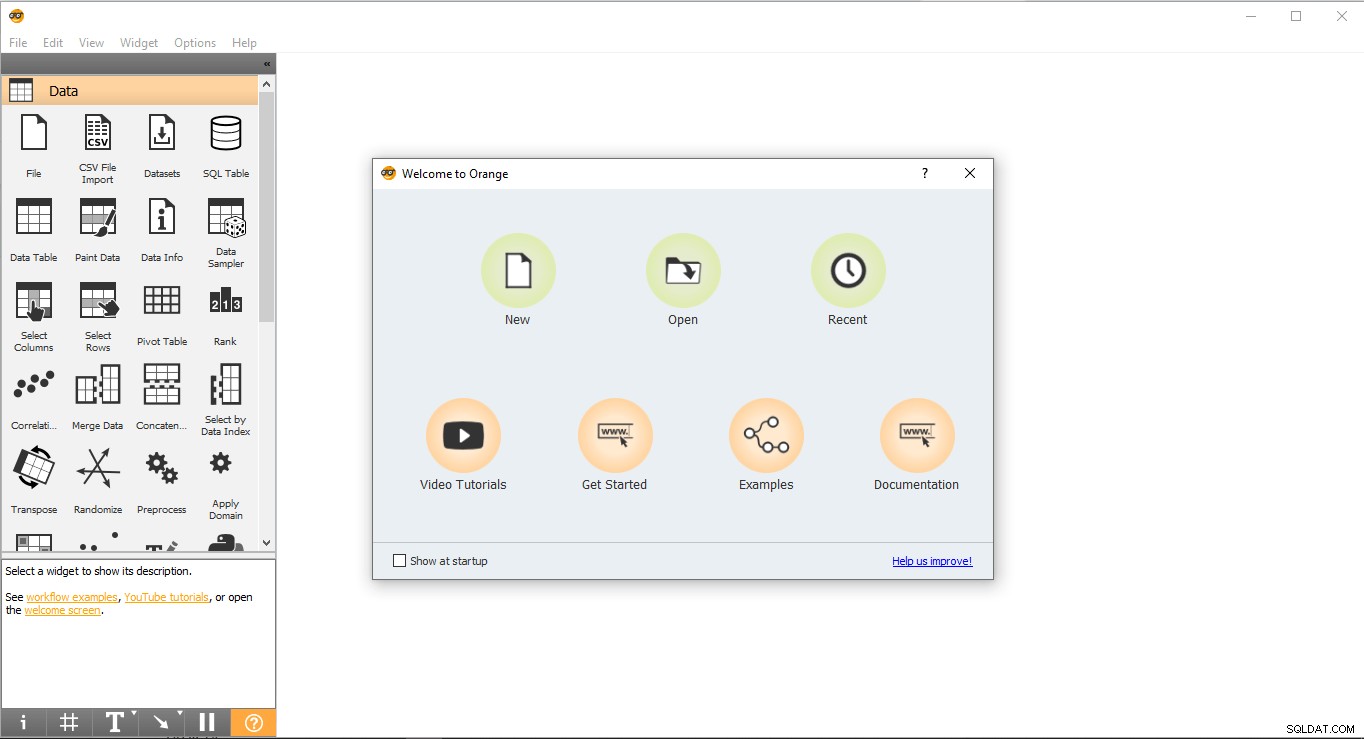
- Tak wygląda strona startowa. Wybierz Nowy opcja i utworzy pusty projekt.

Teraz możesz zastosować model uczenia maszynowego w zestawie danych.
Krok 3:Wybierz model uczenia maszynowego do trenowania danych
W tym artykule k-najbliższe sąsiedzi (KNN) Model uczenia maszynowego służy do trenowania danych. Po zakończeniu procesu uczenia danych, w następnym kroku dane testowe są przekazywane do Prognozy widget, aby sprawdzić dokładność prognoz.
Krok 4:Importuj dane treningowe z PostgreSQL do Orange
Ten treningowy zbiór danych będzie używany do trenowania modelu uczenia maszynowego.
- Przeciągnij i upuść tablicę SQL widżet z Danych menu.
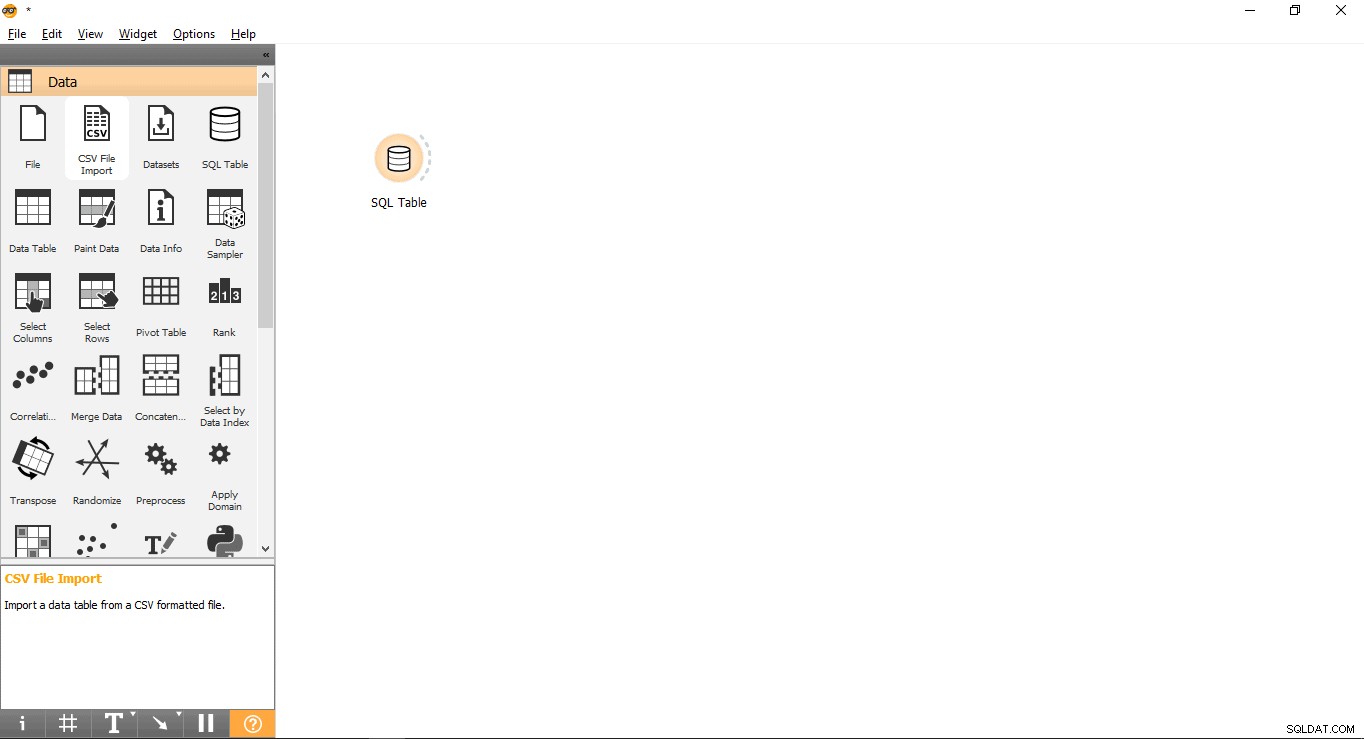
- Zmień nazwę widżetu (opcjonalnie)
- Kliknij prawym przyciskiem myszy Tabelę SQL widget.
- Wybierz Zmień nazwę .
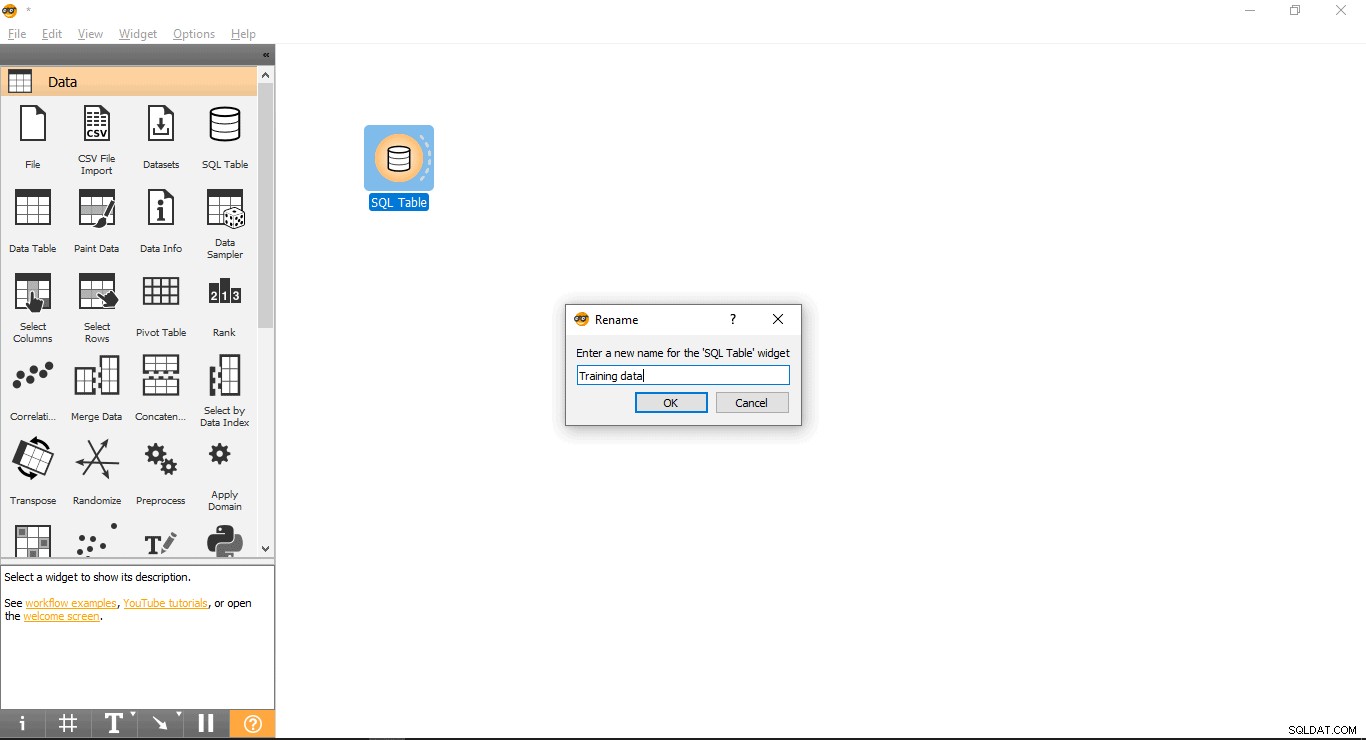
- Połącz się z PostgreSQL, aby załadować treningowy zestaw danych:
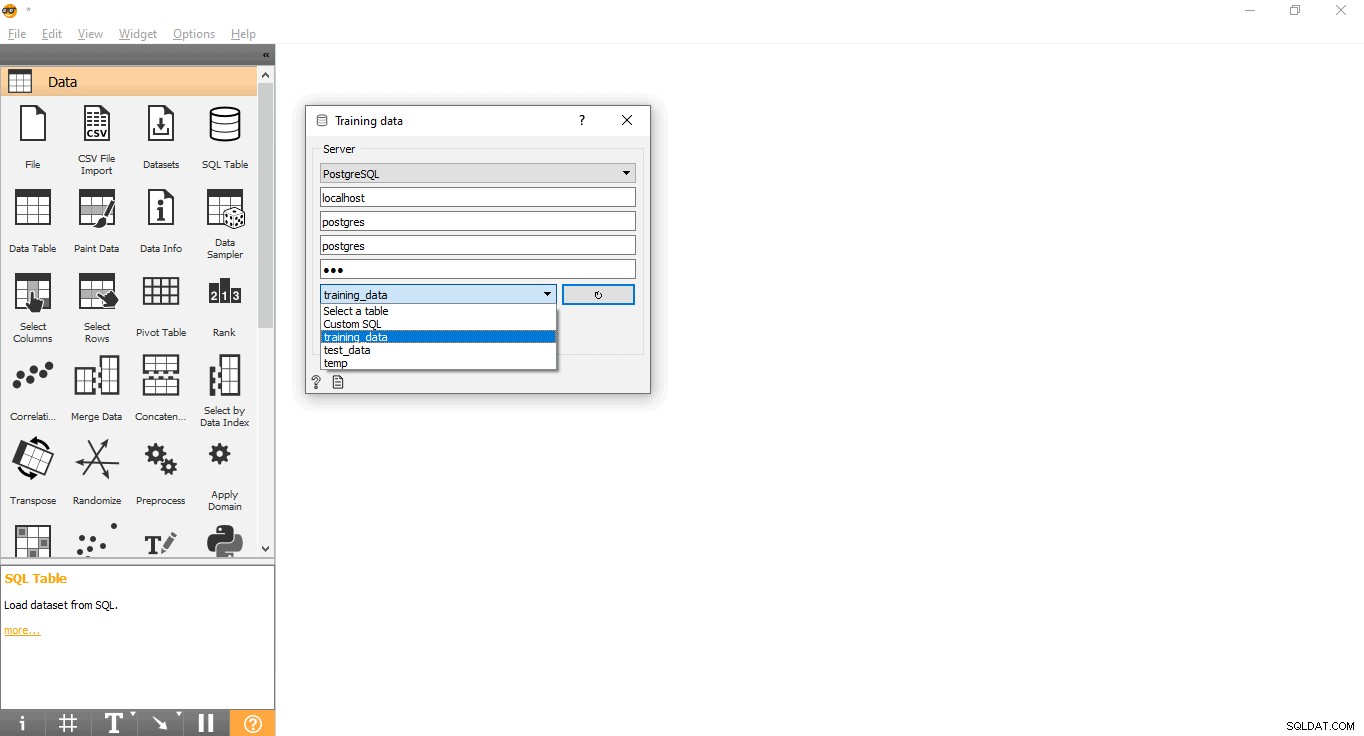
- Kliknij dwukrotnie Dane treningowe widget.
- Wprowadź dane uwierzytelniające, aby połączyć się z bazą danych PostgreSQL.
- Naciśnij przycisk przeładowania, aby załadować wszystkie dostępne tabele z podanej bazy danych.
- Wybierz tabelę training_data z menu rozwijanego i zamknij wyskakujące okienko.
Krok 5:Dodaj kolumnę docelową
Ten krok jest ważny, ponieważ model uczenia maszynowego spróbuje przewidzieć dane dla tej zmiennej/kolumny docelowej:
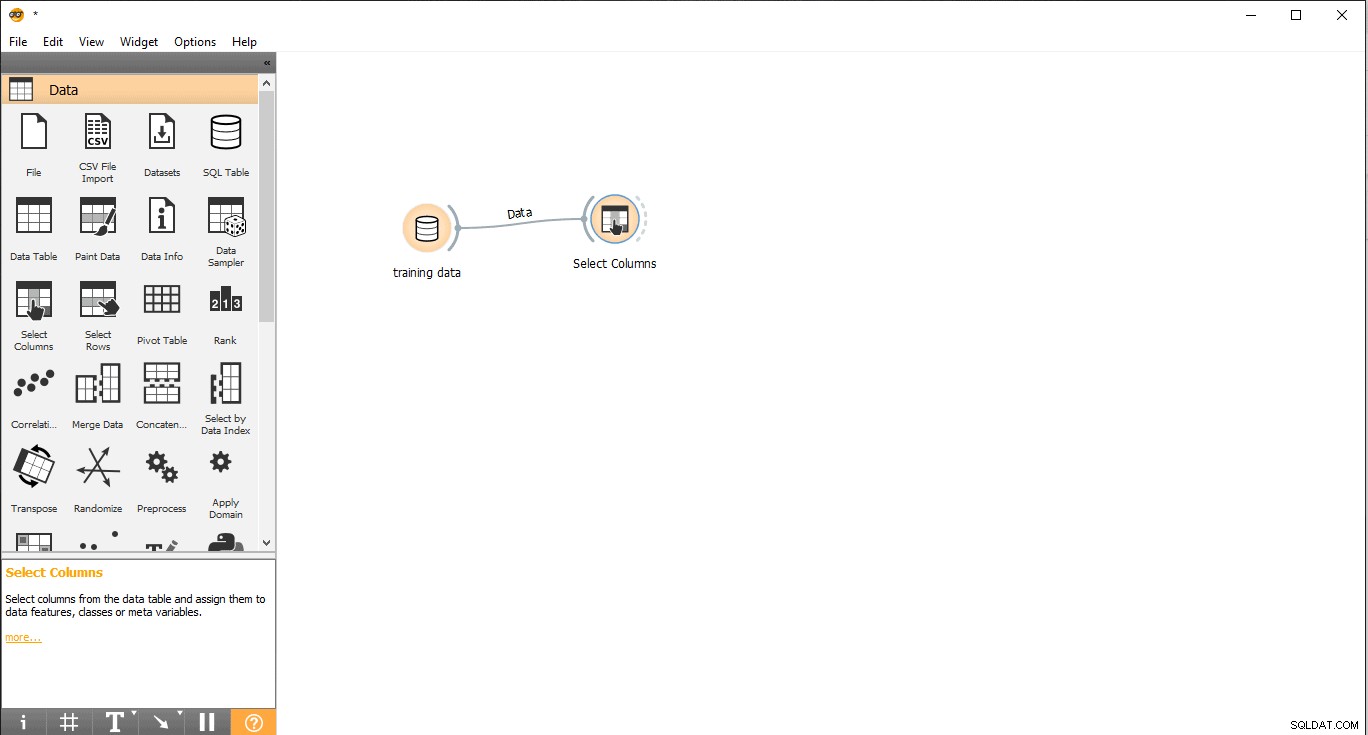
- Przeciągnij i upuść Wybierz kolumny widżet z danych menu.
- Kliknij dwukrotnie Wybierz kolumny widget.
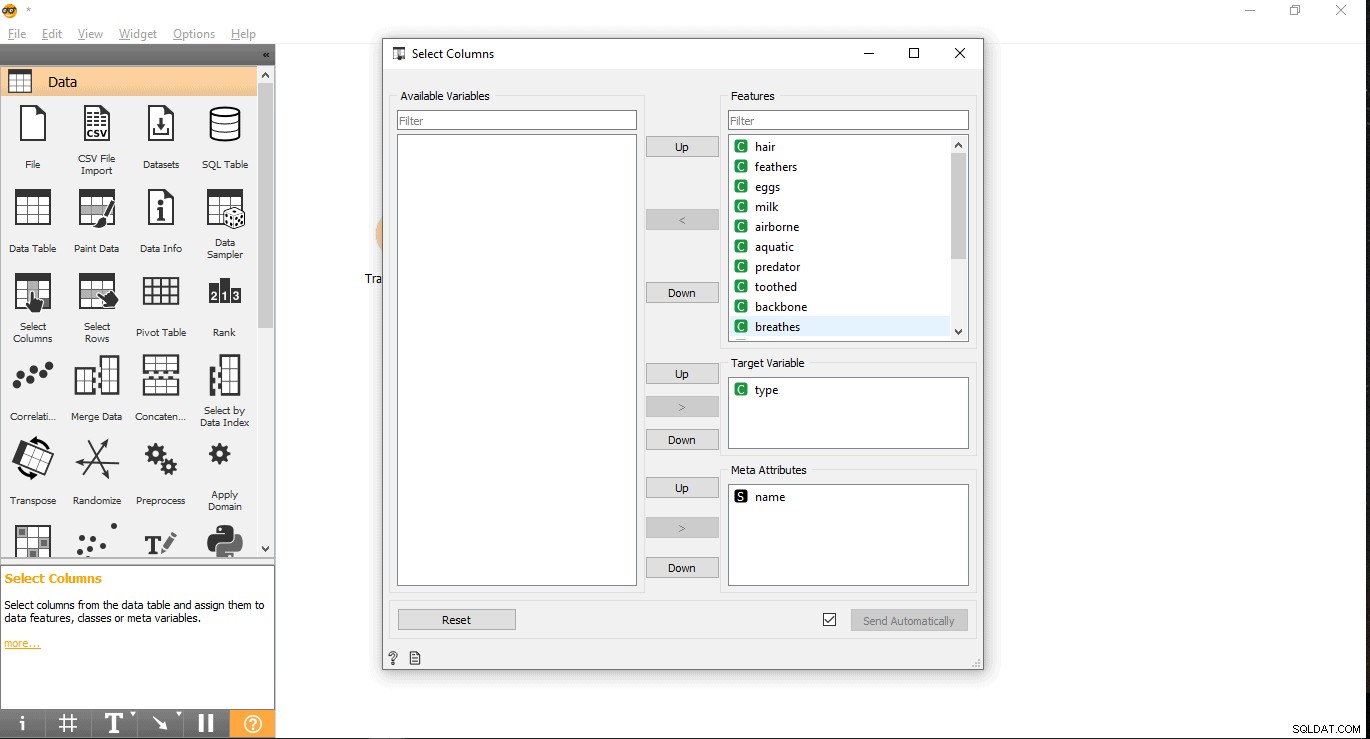
- Przeszukaj kolumnę docelową pod etykietą Funkcje. Tutaj używany jest typ jako zmienną docelową, ponieważ musimy zobaczyć, jakiego typu jest dane zwierzę.
- Przeciągnij i upuść pod zmienną docelową i zamknij wyskakujące okienko.
Krok 6:Ranking kolumn
Możesz oceniać lub oceniać zmienną/kolumny treningowe zgodnie z ich korelacją z kolumną docelową.
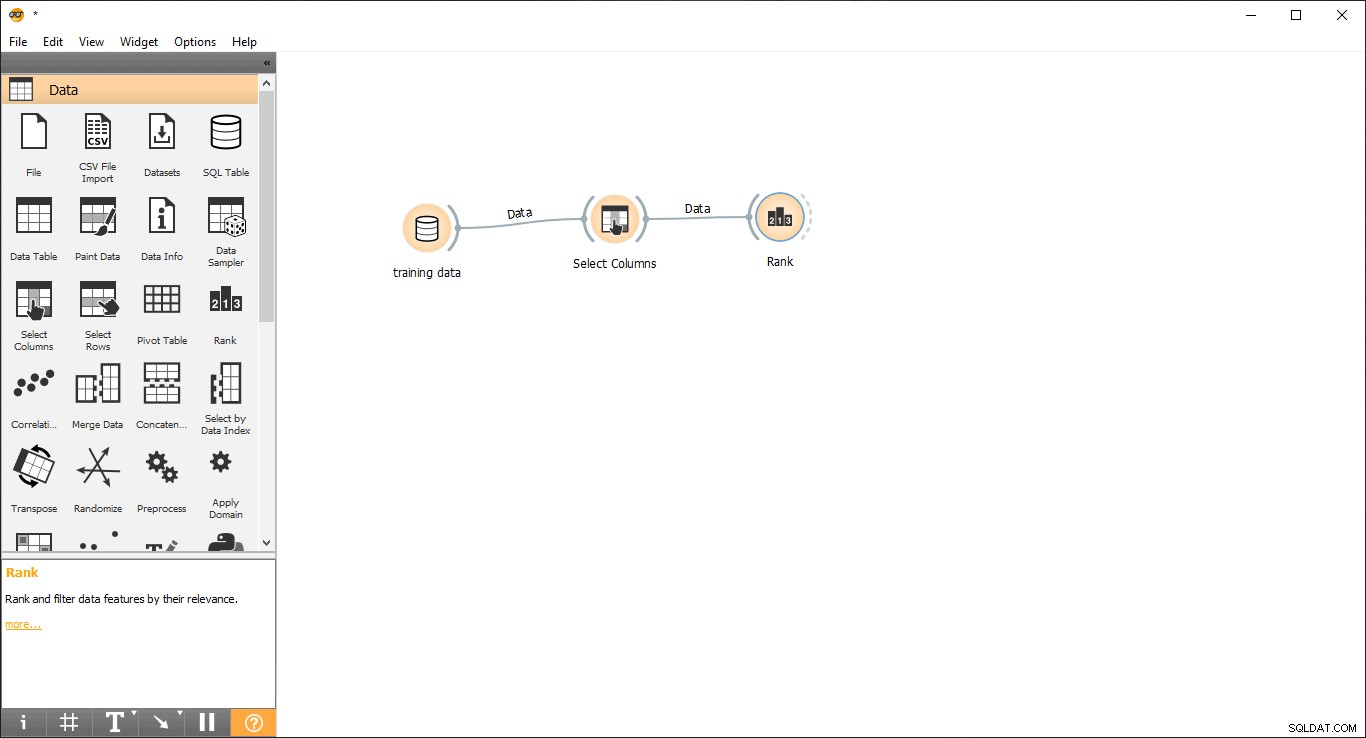
- Przeciągnij i upuść ranking widżet z danych menu.
- Narysuj linię linku z Wybierz kolumny widżet do rankingu widżet .
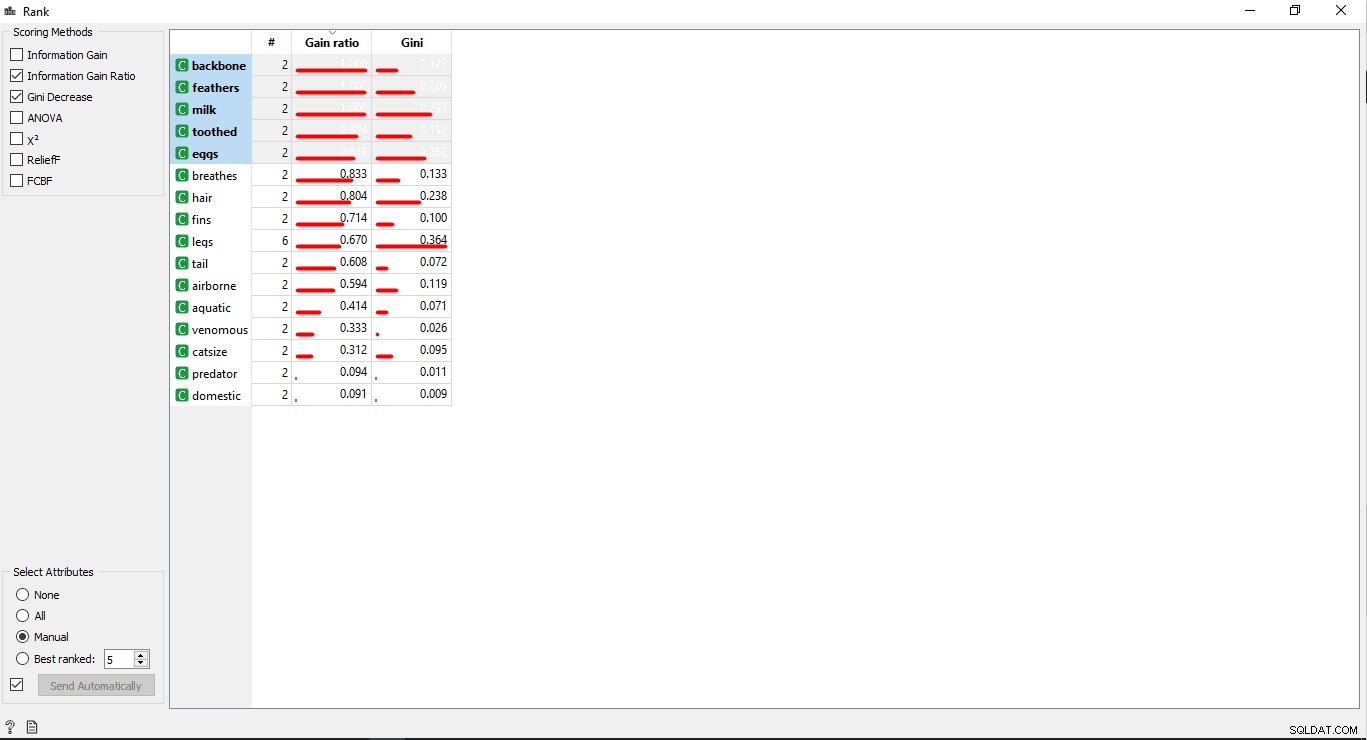
- Kliknij dwukrotnie ranking widget, aby wyświetlić najbardziej powiązane kolumny w tabeli danych treningowych. Będzie on domyślnie wybierał 5 najlepszych kolumn.
Krok 7:Trening danych
W tym kroku model uczenia maszynowego (KNN) zostanie przeszkolony przy użyciu zestawu danych szkoleniowych. Wykonaj następujące kroki:
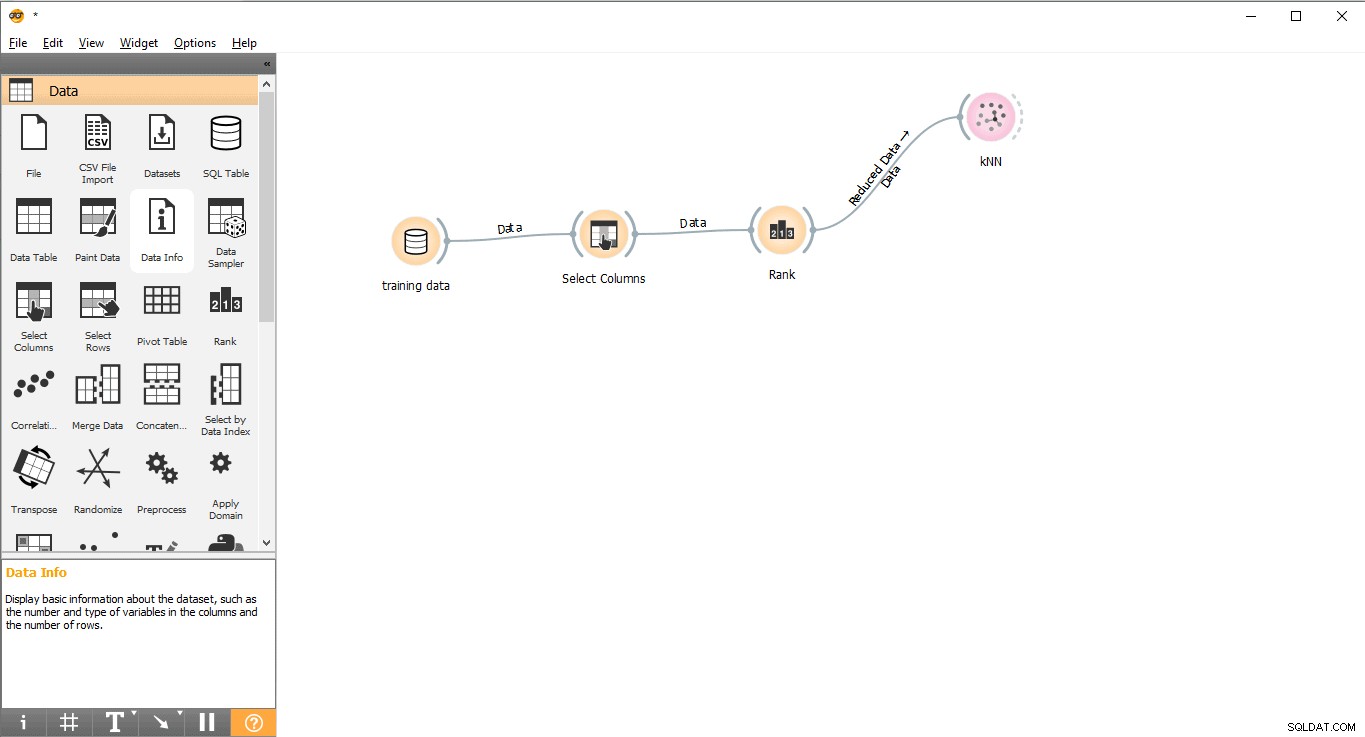
- Przeciągnij i upuść KNN widżet z Modelu menu.
- Narysuj linię linku z Rankingu widżet do KNN widget.
Krok 8:Załaduj testowy zestaw danych do PostgreSQL
Tworzony jest osobny testowy zestaw danych do wykonywania prognoz. Postępuj zgodnie z instrukcjami, aby załadować testowy zestaw danych do tabeli PostgreSQL.
- Utwórz tabelę do przechowywania naszych danych testowych . Tutaj nazywa się to test_data.
CREATE TABLE test_data( name VARCHAR (100), hair integer, feathers integer, eggs integer, milk integer, airborne integer, aquatic integer, predator integer, toothed integer, backbone integer, breathes integer, venomous integer, fins integer, legs integer, tail integer, domestic integer, catsize integer, type VARCHAR (100) );
- Wstaw dane testowe do tabeli testowej za pomocą KOPIUJ zapytanie. Przed wykonaniem KOPIUJ zapytanie, upewnij się, że PostgreSQL wymaga uprawnień do odczytu pliku danych, w przeciwnym razie operacja COPY nie powiedzie się.
UWAGA: Upewnij się, że wpisujesz kartę spacja między pojedynczymi cudzysłowami po ograniczniku słowo kluczowe. Znak zapytania jest celowo umieszczany w typie kolumny testowego zbioru danych, ponieważ musimy określić typ danego zwierzęcia za pomocą naszego modelu uczenia maszynowego.
COPY test_data FROM 'Path_to_test_data_file’ with delimiter ' ' csv header;
Zrzut ekranu zestawu danych testowych znajduje się poniżej

Krok 9:Importuj dane testowe z PostgreSQL do Orange
Aby zastosować prognozy, wykonaj następujące kroki.
- Przeciągnij i upuść Tabelę SQL widżet z danych menu.
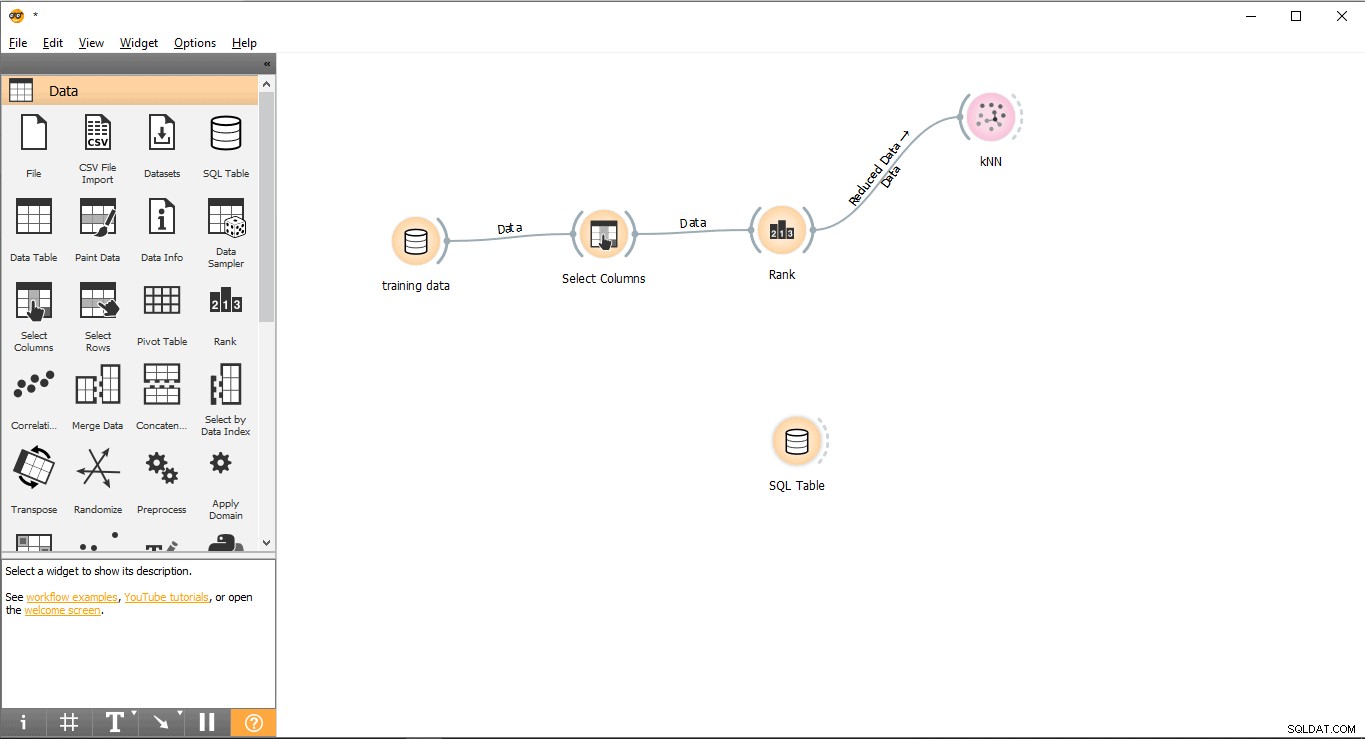
- Zmień nazwę widżetu (opcjonalnie)
- Kliknij prawym przyciskiem myszy Tabelę SQL widget.
- Wybierz Zmień nazwę .
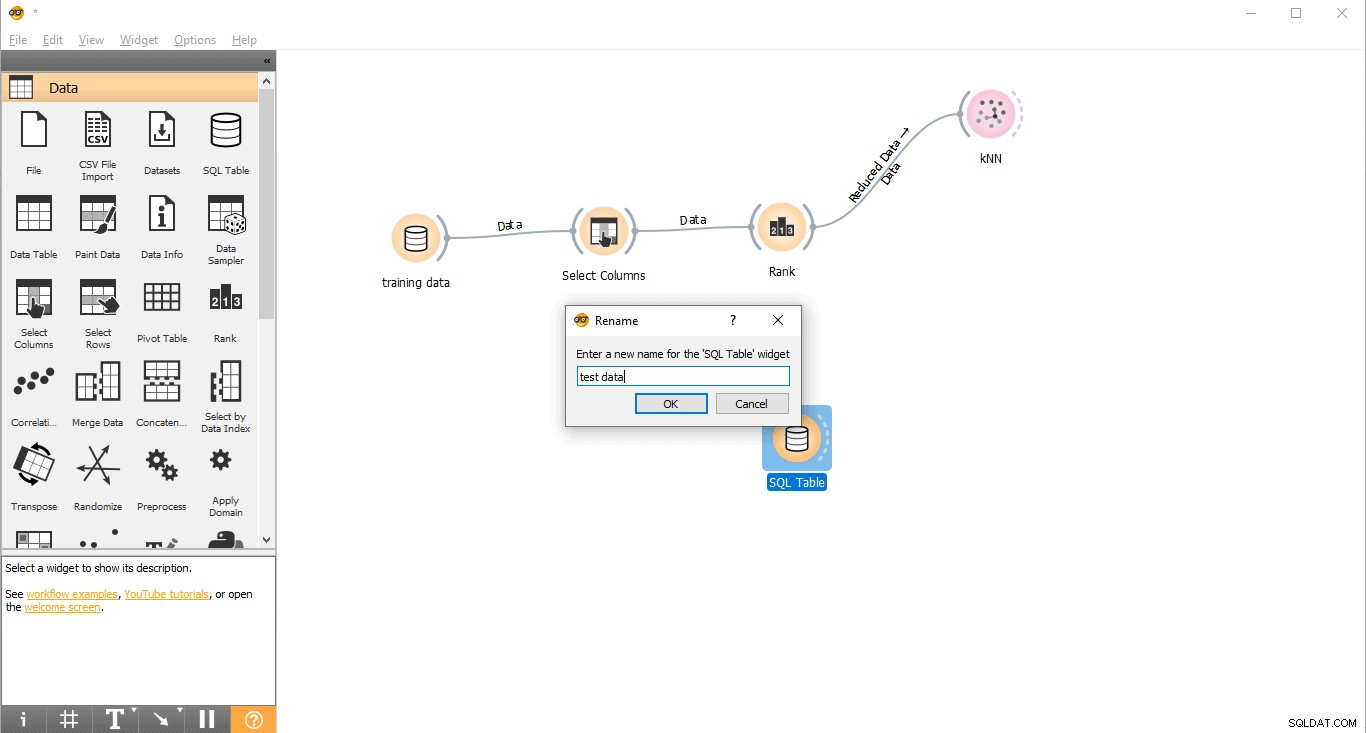
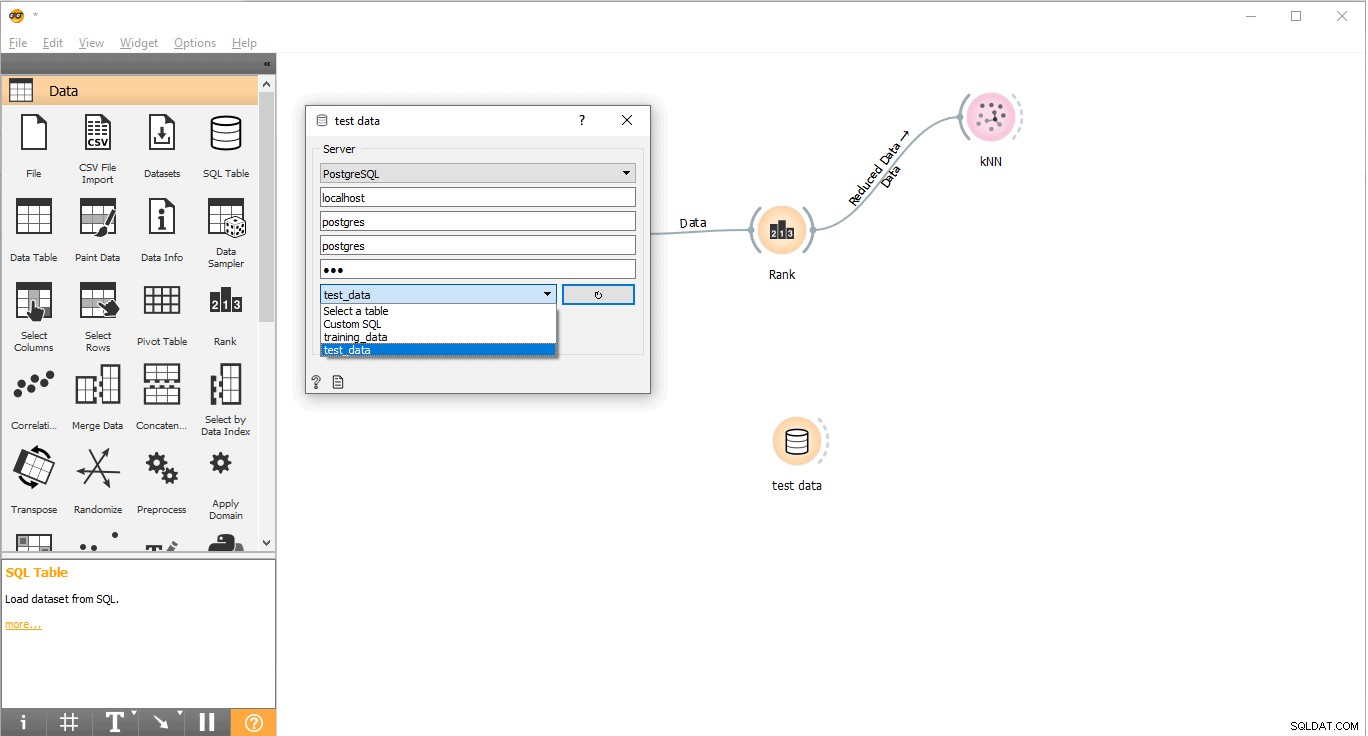
- Połącz się z PostgreSQL, aby załadować dane testowe.
- Kliknij dwukrotnie Dane testowe widget.
- Połącz go z danymi testowymi tabela z PostgreSQL.
Teraz jesteśmy gotowi do prognozowania.
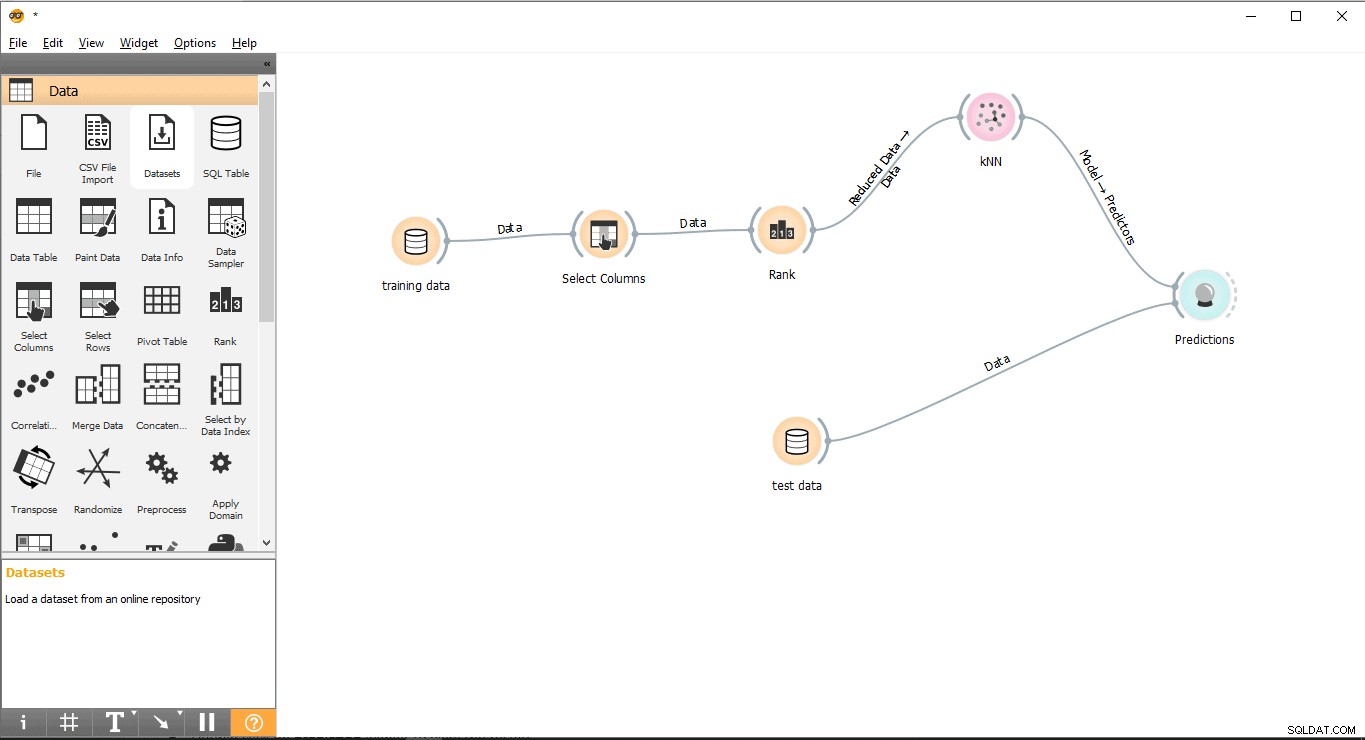
Krok 10:Prognozy
Prognoza widget spróbuje przewidzieć dane testowe na podstawie danych treningowych z KNN .
- Przeciągnij i upuść Prognoza widżet z Oceń menu.
- Narysuj linię linku w formularzu Testuj dane widżet do przewidywania widget.
- Narysuj linię łącza z KNN widżet do przewidywania widget.
Krok 11:Wyniki
Kliknij dwukrotnie Przewidywanie widget, aby wyświetlić wyniki.
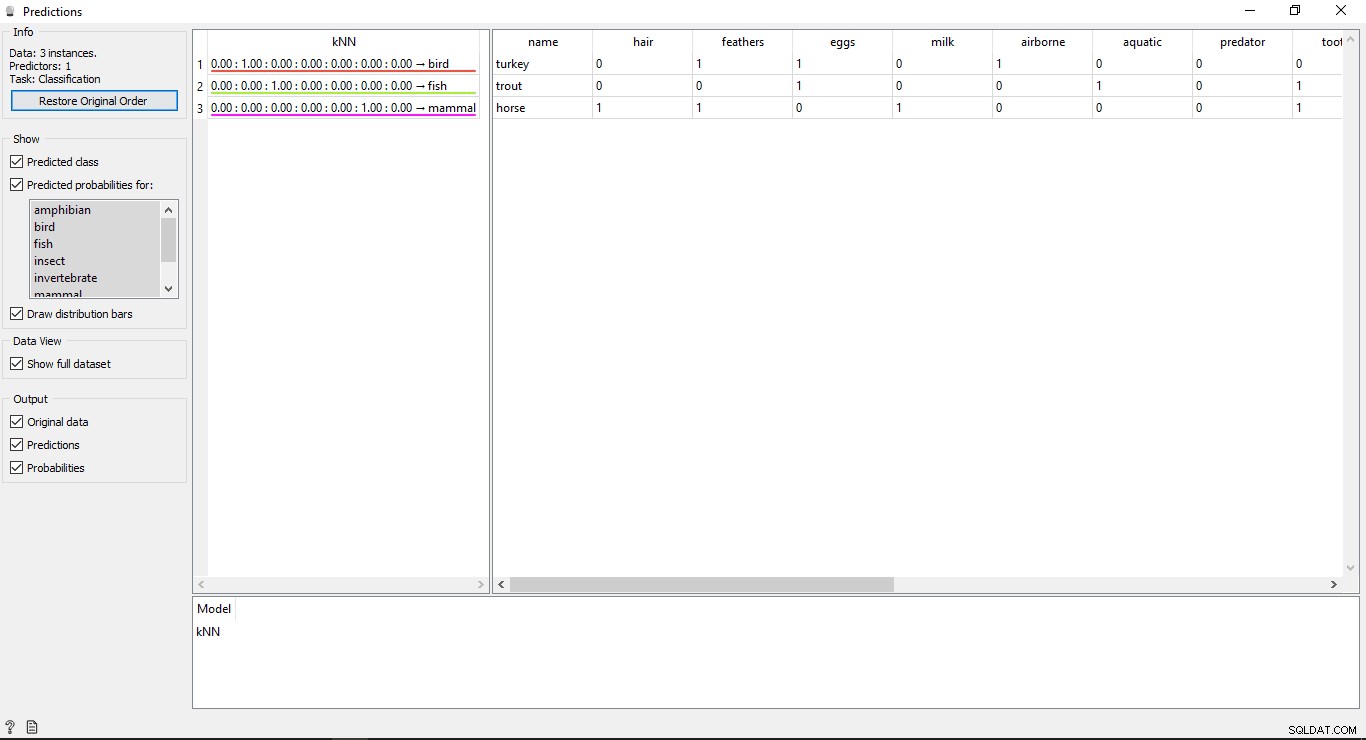
Zrozumienie wyników
Zobaczysz 2 główne tabele w oknie przewidywania. Tabela po lewej stronie pokazuje przewidywane wyniki, podczas gdy tabela po prawej pokazuje oryginalne dane testowe, które zostały dostarczone do przewidywań.
Od KNN model został użyty do trenowania danych, więc zobaczysz jedną kolumnę o nazwie KNN który zawiera listę wyników.
Jak wiemy:
- Koń to ssak
- Pstrąg to ryba
- Turcja to Ptak
Dzięki temu KNN jest w stanie poprawnie określić wszystkie typy.
Dokładność prognoz
Jeśli widzisz tabelę po lewej stronie danych wyjściowych widżetu przewidywania, oznacza to, że przed przewidywanym typem znajduje się kilka liczb, tj. 1,00. 0,00 Te liczby pokazują dokładność przewidywanego typu.
Użyliśmy 7 rodzajów zwierząt w zestawie danych treningowych, więc pokazuje on całkowitą liczbę 7 kolumn z wartościami dokładności, każda kolumna będzie reprezentować 1 rodzaj zwierzęcia. Możesz sprawdzić, która kolumna reprezentuje typ zwierzęcia, patrząc na listę dostępną po lewej stronie ekranu w sekcji Przewidywane prawdopodobieństwa etykieta. Jeśli spojrzysz na pierwszy wiersz z napisem Turcja to Ptak . Widzimy, że jego dokładność wynosi 1,00 (100% z 2. kolumny). To samo dotyczy innych przykładów Pstrąg to ryba a jego dokładność wynosi 1,00 (100% z 3. kolumny).
W tym artykule wykorzystaliśmy algorytm k-najbliższych sąsiadów (KNN) do implementacji modelu uczenia maszynowego. W następnym blogu będziemy używać Support Vector Machine (SVM).
W przypadku jakichkolwiek pytań lub komentarzy prosimy o kontakt za pomocą formularza kontaktowego tutaj.