Jest to druga część dwuczęściowej serii repmgr firmy 2ndQuadrant, otwartego narzędzia wysokiej dostępności dla PostgreSQL.
W pierwszej części skonfigurujemy trzywęzłowy klaster PostgreSQL 12 wraz z węzłem „świadkiem”. Klaster składał się z węzła podstawowego i dwóch węzłów rezerwowych. Klaster i węzeł-świadek były hostowane w wirtualnej chmurze prywatnej usługi Amazon Web Service (VPC). Serwery EC2 hostujące instancje Postgres zostały umieszczone w podsieciach w różnych strefach dostępności (AZ), jak pokazano poniżej:
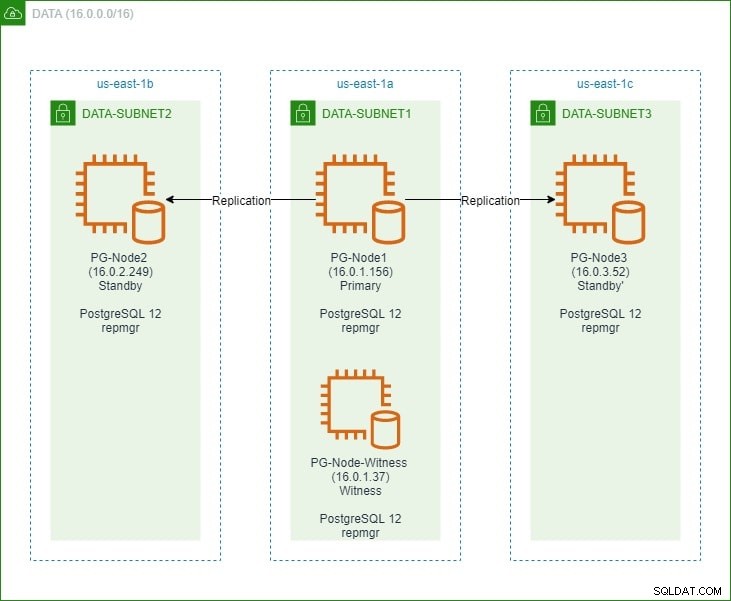
Zrobimy obszerne odniesienia do nazw węzłów i ich adresów IP, więc oto tabela ze szczegółami węzłów:
| Nazwa węzła | Adres IP | Rola | Aplikacje uruchomione |
| PG-Node1 | 16.0.1.156 | Podstawowy | PostgreSQL 12 i repmgr |
| PG-Node2 | 16.0.2.249 | Gotowość 1 | PostgreSQL 12 i repmgr |
| PG-Node3 | 16.0.3.52 | Gotowość 2 | PostgreSQL 12 i repmgr |
| Świadek węzła PG | 16.0.1.37 | Świadek | PostgreSQL 12 i repmgr |
Zainstalowaliśmy repmgr w węźle podstawowym i zapasowym, a następnie zarejestrowaliśmy węzeł główny za pomocą repmgr. Następnie sklonowaliśmy oba węzły rezerwowe z podstawowego i uruchomiliśmy je. Oba węzły rezerwowe zostały również zarejestrowane w repmgr. Polecenie „repmgr cluster show” pokazało nam, że wszystko działa zgodnie z oczekiwaniami:

Aktualny problem
Konfiguracja replikacji strumieniowej za pomocą repmgr jest bardzo prosta. To, co musimy teraz zrobić, to upewnić się, że klaster będzie działał nawet wtedy, gdy podstawowy stanie się niedostępny. To omówimy w tym artykule.
W replikacji PostgreSQL podstawa może stać się niedostępna z kilku powodów. Na przykład:
- System operacyjny węzła podstawowego może ulec awarii lub przestać odpowiadać
- Węzeł podstawowy może utracić połączenie sieciowe
- Usługa PostgreSQL w węźle podstawowym może ulec awarii, zatrzymać się lub nieoczekiwanie stać się niedostępna
- Usługa PostgreSQL w węźle podstawowym może zostać zatrzymana celowo lub przypadkowo
Ilekroć podstawowa staje się niedostępna, rezerwa nie automatycznie awansuje do roli głównej. Stan gotowości nadal obsługuje zapytania tylko do odczytu — chociaż dane będą aktualne aż do ostatniej LSN otrzymanej z sieci podstawowej. Każda próba operacji zapisu nie powiedzie się.
Można to złagodzić na dwa sposoby:
- Tryb gotowości ręcznie uaktualniony do roli podstawowej. Zwykle dzieje się tak w przypadku planowanego przełączenia awaryjnego lub „przełączenia”
- Tryb gotowości automatycznie awansowany do głównej roli. Dzieje się tak w przypadku nienatywnych narzędzi, które stale monitorują replikację i podejmują działania odzyskiwania, gdy podstawowy jest niedostępny. repmgr jest jednym z takich narzędzi.
Rozważymy tutaj drugi scenariusz. Ta sytuacja ma jednak kilka dodatkowych wyzwań:
- Jeśli istnieje więcej niż jedna rezerwa, w jaki sposób narzędzie (lub rezerwy) decyduje, który z nich ma być promowany jako podstawowy? Jak działa kworum i proces awansu?
- W przypadku wielu trybów gotowości, jeśli jeden jest ustawiony jako główny, w jaki sposób inne węzły zaczynają „podążać za nim” jako nowy główny?
- Co się stanie, jeśli podstawowa działa, ale z jakiegoś powodu jest tymczasowo odłączona od sieci? Jeśli jeden z rezerwowych zostanie awansowany do szkoły podstawowej, a następnie pierwotna podstawowa wróci do sieci, jak można uniknąć sytuacji „rozszczepionego mózgu”?
Odpowiedź remgr:Węzeł świadka i demon repmgr
Aby odpowiedzieć na te pytania, repmgr używa czegoś, co nazywa się węzłem świadka . Gdy podstawowa jest niedostępna — zadaniem węzła świadka jest pomaganie rezerwowym w osiągnięciu kworum, jeśli jeden z nich powinien zostać awansowany do roli podstawowej. Tryby gotowości osiągają to kworum, określając, czy węzeł podstawowy jest rzeczywiście w trybie offline, czy tylko tymczasowo niedostępny. Węzeł-świadek powinien znajdować się w tym samym centrum danych/segmencie/podsieci, co węzeł główny, ale NIGDY nie może działać na tym samym hoście fizycznym, co węzeł główny.
Pamiętaj, że w pierwszej części tej serii wprowadziliśmy węzeł-świadek w tej samej strefie i podsieci dostępności, co węzeł podstawowy. Nazwaliśmy go PG-Node-Witness i zainstalowaliśmy tam instancję PostgreSQL 12. W tym poście zainstalujemy tam również repmgr, ale o tym później.
Drugim składnikiem rozwiązania jest demon repmgr (repmgrd) działa we wszystkich węzłach klastra i w węźle monitora. Ponownie, nie uruchomiliśmy tego demona w pierwszej części tej serii, ale zrobimy to tutaj. Demon jest częścią pakietu repmgr — po włączeniu działa jako zwykła usługa i stale monitoruje stan klastra. Inicjuje przełączenie awaryjne, gdy zostanie osiągnięte kworum, że podstawowa jest w trybie offline. Może nie tylko automatycznie promować stan gotowości, ale może również ponownie inicjować inne stany gotowości w klastrze wielowęzłowym, aby podążać za nowym trybem podstawowym .
Proces kworum
Kiedy rezerwowy zdaje sobie sprawę, że nie widzi podstawowego, konsultuje się z innymi rezerwowymi. Wszystkie rezerwy działające w klastrze osiągają kworum w celu wybrania nowego podstawowego za pomocą serii sprawdzeń:
- Każdy rezerwowy pyta inne rezerwowe o czas, w którym ostatni raz „widział” główny. Jeśli ostatnia zreplikowana sieć LSN w trybie gotowości lub czas ostatniej komunikacji z siecią podstawową jest późniejszy niż ostatnia zreplikowana sieć LSN bieżącego węzła lub czas ostatniej komunikacji, węzeł nie robi nic i czeka na przywrócenie komunikacji z siecią podstawową
- Jeśli żaden z rezerwowych nie widzi podstawowego, sprawdzają, czy węzeł-świadek jest dostępny. Jeśli węzeł-świadek również nie jest osiągalny, tryby gotowości zakładają, że po stronie głównej jest awaria sieci i nie wybierają nowego głównego
- Jeśli można dotrzeć do świadka, osoby w stanie gotowości zakładają, że główny jest wyłączony i przystępują do wyboru głównego
- Węzeł, który został skonfigurowany jako „preferowany” podstawowy, zostanie wtedy awansowany. W każdym trybie gotowości zostanie ponownie zainicjowana replikacja, aby podążać za nową podstawową.
Konfigurowanie klastra do automatycznego przełączania awaryjnego
Skonfigurujemy teraz klaster i węzeł-świadek do automatycznego przełączania awaryjnego.
Krok 1:Zainstaluj i skonfiguruj repmgr w programie Witness
Widzieliśmy już, jak zainstalować pakiet repmgr w naszym ostatnim artykule. Robimy to również w węźle świadka:
# wget https://download.postgresql.org/pub/repos/yum/reporpms/EL-8-x86_64/pgdg-redhat-repo-latest.noarch.rpm
A potem:
# yum install repmgr12 -y
Następnie dodajemy następujące wiersze w pliku postgresql.conf węzła świadka:
listen_addresses = '*' shared_preload_libraries = 'repmgr'
Dodamy również następujące wiersze w pliku pg_hba.conf w węźle monitora. Zwróć uwagę, jak używamy zakresu CIDR klastra zamiast określania indywidualnych adresów IP.
local replication repmgr trust host replication repmgr 127.0.0.1/32 trust host replication repmgr 16.0.0.0/16 trust local repmgr repmgr trust host repmgr repmgr 127.0.0.1/32 trust host repmgr repmgr 16.0.0.0/16 trust
Uwaga
[Opisane tutaj kroki służą wyłącznie do celów demonstracyjnych. Nasz przykład to użycie zewnętrznie osiągalnych adresów IP dla węzłów. Używanie listen_address =‘*’ wraz z mechanizmem bezpieczeństwa „trust” pg_hba stwarza zatem zagrożenie bezpieczeństwa i NIE powinno być używane w scenariuszach produkcyjnych. W systemie produkcyjnym wszystkie węzły będą znajdować się w jednej lub więcej prywatnych podsieciach, osiągalnych przez prywatne adresy IP z hostów skokowych.]
Po wprowadzeniu zmian postgresql.conf i pg_hba.conf tworzymy użytkownika repmgr i bazę danych repmgr w świadku oraz zmieniamy domyślną ścieżkę wyszukiwania użytkownika repmgr:
[example@sqldat.comitness ~]$ createuser --superuser repmgr [example@sqldat.com ~]$ createdb --owner=repmgr repmgr [example@sqldat.com ~]$ psql -c "ALTER USER repmgr SET search_path TO repmgr, public;"
Na koniec dodajemy następujące wiersze do pliku repmgr.conf, znajdującego się w /etc/repmgr/12/
node_id=4 node_name='PG-Node-Witness' conninfo='host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2' data_directory='/var/lib/pgsql/12/data'
Po ustawieniu parametrów konfiguracyjnych ponownie uruchamiamy usługę PostgreSQL w węźle świadka:
# systemctl restart postgresql-12.service
Aby przetestować łączność z repmgr węzła świadka, możemy uruchomić to polecenie z węzła podstawowego:
[example@sqldat.com ~]$ psql 'host=16.0.1.37 user=repmgr dbname=repmgr connect_timeout=2'
Następnie rejestrujemy węzeł-świadek za pomocą repmgr, uruchamiając polecenie „repmgr świadek rejestru” jako użytkownik postgres. Zwróć uwagę, jak używamy adresu podstawowego węzeł, a NIE węzeł-świadek w poniższym poleceniu:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf witness register -h 16.0.1.156
Dzieje się tak, ponieważ polecenie „repmgr monitor register” dodaje metadane węzła świadka do bazy danych repmgr węzła głównego i, jeśli to konieczne, inicjuje węzeł świadka, instalując rozszerzenie repmgr i kopiując metadane repmgr do węzła świadka.
Wynik będzie wyglądał tak:
INFO: connecting to witness node "PG-Node-Witness" (ID: 4) INFO: connecting to primary node NOTICE: attempting to install extension "repmgr" NOTICE: "repmgr" extension successfully installed INFO: witness registration complete NOTICE: witness node "PG-Node-Witness" (ID: 4) successfully registered
Na koniec sprawdzamy stan ogólnej konfiguracji z dowolnego węzła:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
Wynik wygląda tak:

Krok 2:Modyfikowanie pliku sudoers
Po uruchomieniu klastra i monitora dodajemy następujące wiersze w pliku sudoers w każdym węźle klastra i węźle monitora:
Defaults:postgres !requiretty postgres ALL = NOPASSWD: /usr/bin/systemctl stop postgresql-12.service, /usr/bin/systemctl start postgresql-12.service, /usr/bin/systemctl restart postgresql-12.service, /usr/bin/systemctl reload postgresql-12.service, /usr/bin/systemctl start repmgr12.service, /usr/bin/systemctl stop repmgr12.service
Krok 3:Konfiguracja parametrów repmgrd
Dodaliśmy już cztery parametry w pliku repmgr.conf w każdym węźle. Dodane parametry są podstawowymi parametrami potrzebnymi do działania repmgr. Aby włączyć demona repmgr i automatyczne przełączanie awaryjne, należy włączyć/dodać szereg innych parametrów. W kolejnych podrozdziałach opiszemy każdy parametr i wartość, na jaką zostaną ustawione w każdym węźle.
przełączenie awaryjne
Parametr przełączania awaryjnego jest jednym z obowiązkowych parametrów demona repmgr. Ten parametr informuje demona, czy powinien zainicjować automatyczne przełączanie awaryjne po wykryciu sytuacji awaryjnej. Może mieć jedną z dwóch wartości:„ręczna” lub „automatyczna”. Ustawimy to na automatyczne w każdym węźle:
failover='automatic'
promote_command
Jest to kolejny obowiązkowy parametr demona repmgr. Ten parametr informuje demona repmgr, jakie polecenie powinien uruchomić, aby promować stan gotowości. Wartością tego parametru będzie zwykle komenda „repmgr Standby Promowanie” lub ścieżka do skryptu powłoki wywołującego to polecenie. W naszym przypadku użycia ustawiamy to w następujący sposób w każdym węźle:
promote_command='/usr/pgsql-12/bin/repmgr standby promote -f /etc/repmgr/12/repmgr.conf --log-to-file'
follow_command
Jest to trzeci obowiązkowy parametr demona repmgr. Ten parametr mówi węzłowi rezerwowemu, aby podążał za nowym podstawowym. Demon repmgr zastępuje symbol zastępczy %n identyfikatorem węzła nowego podstawowego w czasie wykonywania:
follow_command='/usr/pgsql-12/bin/repmgr standby follow -f /etc/repmgr/12/repmgr.conf --log-to-file --upstream-node-id=%n'
priorytet
Parametr priorytet dodaje wagę do kwalifikacji węzła do zostania głównym. Ustawienie tego parametru na wyższą wartość daje węzłowi większą możliwość stania się węzłem podstawowym. Ponadto ustawienie tej wartości na zero dla węzła zapewni, że węzeł nigdy nie będzie promowany jako główny.
W naszym przypadku użycia mamy dwa tryby gotowości:PG-Node2 i PG-Node3. Chcemy promować PG-Node2 jako nowy główny, gdy PG-Node1 przechodzi w tryb offline, a PG-Node3 podążać za PG-Node2 jako nowym głównym. Ustawiamy parametr na następujące wartości w dwóch węzłach gotowości:
| Nazwa węzła | Ustawienia parametrów |
| PG-Node2 | priorytet =60 |
| PG-Node3 | priorytet =40 |
monitor_interval_secs
Ten parametr mówi demonowi repmgr, jak często (w sekundach) powinien sprawdzać dostępność węzła nadrzędnego. W naszym przypadku istnieje tylko jeden węzeł upstream:węzeł podstawowy. Domyślna wartość to 2 sekundy, ale ustawimy to wyraźnie w każdym węźle:
monitor_interval_secs=2
connection_check_type
Parametr connection_check_type określa, jakiego demona protokołu repmgr użyje do nawiązania kontaktu z węzłem upstream. Ten parametr może przyjmować trzy wartości:
- ping :repmgr używa metody PQPing()
- połączenie :repmgr próbuje utworzyć nowe połączenie z węzłem upstream
- zapytanie :repmgr próbuje uruchomić zapytanie SQL na węźle nadrzędnym przy użyciu istniejącego połączenia
Ponownie ustawimy ten parametr na domyślną wartość ping w każdym węźle:
connection_check_type='ping'
reconnect_attempts i reconnect_interval
Gdy podstawowa staje się niedostępna, demon repmgr w węzłach rezerwowych będzie próbował ponownie połączyć się z podstawowym przez czas reconnect_attempts. Domyślna wartość tego parametru to 6. Pomiędzy każdą próbą ponownego połączenia będzie czekać przez sekundy reconnect_interval, który ma domyślną wartość 10. W celach demonstracyjnych użyjemy krótkiego interwału i mniejszej liczby prób ponownego połączenia. Ustawiamy ten parametr w każdym węźle:
reconnect_attempts=4 reconnect_interval=8
primary_visibility_consensus
Gdy podstawowa staje się niedostępna w klastrze wielowęzłowym, rezerwy mogą konsultować się ze sobą, aby zbudować kworum na temat przełączania awaryjnego. Odbywa się to poprzez zapytanie każdego rezerwowego o czas, w którym ostatni raz widział pierwotną. Jeśli ostatnia komunikacja węzła była bardzo niedawna i późniejsza niż w momencie, gdy węzeł lokalny zobaczył węzeł podstawowy, węzeł lokalny zakłada, że węzeł podstawowy jest nadal dostępny i nie podejmuje decyzji o przełączeniu awaryjnym.
Aby włączyć ten model konsensusu, parametr primary_visibility_consensus musi być ustawiony na „prawda” w każdym węźle – w tym świadku:
primary_visibility_consensus=true
standby_disconnect_on_failover
Gdy parametr standby_disconnect_on_failover jest ustawiony na „true” w węźle gotowości, demon repmgr zapewni, że jego odbiornik WAL zostanie odłączony od podstawowego i nie otrzyma żadnych segmentów WAL. Będzie również czekać na zatrzymanie odbiorników WAL innych węzłów rezerwowych przed podjęciem decyzji o przełączeniu awaryjnym. Ten parametr powinien mieć taką samą wartość w każdym węźle. Ustawiamy to na „prawda”.
standby_disconnect_on_failover=true
Ustawienie tego parametru na wartość true oznacza, że każdy węzeł rezerwowy przestał otrzymywać dane z sieci podstawowej podczas przełączania awaryjnego. Proces będzie miał opóźnienie 5 sekund plus czas potrzebny do zatrzymania odbiornika WAL przed podjęciem decyzji o przełączeniu awaryjnym. Domyślnie demon repmgr czeka 30 sekund, aby potwierdzić, że wszystkie rodzeństwo przestały otrzymywać segmenty WAL, zanim nastąpi przełączenie awaryjne.
repmgrd_service_start_command i repmgrd_service_stop_command
Te dwa parametry określają sposób uruchamiania i zatrzymywania demona repmgr za pomocą poleceń „repmgr daemon start” i „repmgr daemon stop”.
Zasadniczo te dwa polecenia są opakowaniami wokół poleceń systemu operacyjnego służących do uruchamiania/zatrzymywania usługi. Dwie wartości parametrów mapują te polecenia na ich wersje specyficzne dla systemu operacyjnego. Ustawiamy te parametry na następujące wartości w każdym węźle:
repmgrd_service_start_command='sudo /usr/bin/systemctl start repmgr12.service' repmgrd_service_stop_command='sudo /usr/bin/systemctl stop repmgr12.service'
Polecenia uruchamiania/zatrzymywania/restartowania usługi PostgreSQL
W ramach swojego działania demon repmgr często będzie musiał zatrzymać, uruchomić lub ponownie uruchomić usługę PostgreSQL. Aby zapewnić bezproblemowe działanie, najlepiej określić odpowiednie polecenia systemu operacyjnego jako wartości parametrów w pliku repmgr.conf. W tym celu ustawimy cztery parametry w każdym węźle:
service_start_command='sudo /usr/bin/systemctl start postgresql-12.service' service_stop_command='sudo /usr/bin/systemctl stop postgresql-12.service' service_restart_command='sudo /usr/bin/systemctl restart postgresql-12.service' service_reload_command='sudo /usr/bin/systemctl reload postgresql-12.service'
monitoring_history
Ustawienie parametru monitoring_history na „yes” zapewni, że repmgr zapisze dane monitorowania klastra. Ustawiamy to na „tak” w każdym węźle:
monitoring_history=yes
log_status_interval
Ustawiamy parametr w każdym węźle, aby określić, jak często demon repmgr będzie rejestrował komunikat o stanie. W tym przypadku ustawiamy to co 60 sekund:
log_status_interval=60
Krok 4:Uruchamianie demona repmgr
Po ustawieniu parametrów w klastrze i węźle-świadzie wykonujemy próbny przebieg polecenia, aby uruchomić demona repmgr. Testujemy to najpierw w węźle podstawowym, a następnie w dwóch węzłach rezerwowych, a następnie w węźle-świadku. Polecenie musi zostać wykonane jako użytkownik postgres:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start --dry-run
Wynik powinien wyglądać tak:
INFO: prerequisites for starting repmgrd met DETAIL: following command would be executed: sudo /usr/bin/systemctl start repmgr12.service
Następnie uruchamiamy demona we wszystkich czterech węzłach:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf daemon start
Dane wyjściowe w każdym węźle powinny wskazywać, że demon został uruchomiony:
NOTICE: executing: "sudo /usr/bin/systemctl start repmgr12.service" NOTICE: repmgrd was successfully started
Możemy również sprawdzić zdarzenie uruchomienia usługi z węzła podstawowego lub zapasowego:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event --event=repmgrd_start
Dane wyjściowe powinny pokazywać, że demon monitoruje połączenia:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+---------------+----+---------------------+------------------------------------------------------------------ 4 | PG-Node-Witness | repmgrd_start | t | 2020-02-05 11:37:31 | witness monitoring connection to primary node "PG-Node1" (ID: 1) 3 | PG-Node3 | repmgrd_start | t | 2020-02-05 11:37:24 | monitoring connection to upstream node "PG-Node1" (ID: 1) 2 | PG-Node2 | repmgrd_start | t | 2020-02-05 11:37:19 | monitoring connection to upstream node "PG-Node1" (ID: 1) 1 | PG-Node1 | repmgrd_start | t | 2020-02-05 11:37:14 | monitoring cluster primary "PG-Node1" (ID: 1)
Na koniec możemy sprawdzić dane wyjściowe demona z dziennika systemowego w dowolnym trybie gotowości:
# cat /var/log/messages | grep repmgr | less
Oto wynik z PG-Node3:
Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] connecting to database "host=16.0.3.52 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:24 PG-Node3 systemd[1]: repmgr12.service: Can't open PID file /run/repmgr/repmgrd-12.pid (yet?) after start: No such file or directory Feb 5 11:37:24 PG-Node3 repmgrd[2014]: INFO: set_repmgrd_pid(): provided pidfile is /run/repmgr/repmgrd-12.pid Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [NOTICE] starting monitoring of node "PG-Node3" (ID: 3) Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:24 PG-Node3 repmgrd[2014]: [2020-02-05 11:37:24] [INFO] monitoring connection to upstream node "PG-Node1" (ID: 1) Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state Feb 5 11:38:25 PG-Node3 repmgrd[2014]: [2020-02-05 11:38:25] [DETAIL] last monitoring statistics update was 2 seconds ago Feb 5 11:39:26 PG-Node3 repmgrd[2014]: [2020-02-05 11:39:26] [INFO] node "PG-Node3" (ID: 3) monitoring upstream node "PG-Node1" (ID: 1) in normal state … …
Sprawdzenie dziennika systemowego w głównym węźle pokazuje inny typ danych wyjściowych:
Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] using provided configuration file "/etc/repmgr/12/repmgr.conf" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] repmgrd (repmgrd 5.0.0) starting up Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] connecting to database "host=16.0.1.156 user=repmgr dbname=repmgr connect_timeout=2" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] starting monitoring of node "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] "connection_check_type" set to "ping" Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [NOTICE] monitoring cluster primary "PG-Node1" (ID: 1) Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node-Witness" (ID: 4) is not yet attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node3" (ID: 3) is attached Feb 5 11:37:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:14] [INFO] child node "PG-Node2" (ID: 2) is attached Feb 5 11:37:32 PG-Node1 repmgrd[2017]: [2020-02-05 11:37:32] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:38:14 PG-Node1 repmgrd[2017]: [2020-02-05 11:38:14] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state Feb 5 11:39:15 PG-Node1 repmgrd[2017]: [2020-02-05 11:39:15] [INFO] monitoring primary node "PG-Node1" (ID: 1) in normal state … …
Krok 5:Symulacja nieudanej szkoły podstawowej
Teraz zasymulujemy awarię głównego węzła, zatrzymując główny węzeł (PG-Node1). Z wiersza poleceń węzła uruchamiamy następujące polecenie:
# systemctl stop postgresql-12.service
Proces przełączania awaryjnego
Po zatrzymaniu procesu czekamy około minuty lub dwóch, a następnie sprawdzamy plik syslog PG-Node2. Wyświetlane są następujące komunikaty. Dla jasności i prostoty mamy oznaczone kolorami grupy wiadomości i dodaliśmy białe odstępy między wierszami:
… Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:36 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:36] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] checking state of node 1, 2 of 4 attempts Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:44 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:44] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] checking state of node 1, 3 of 4 attempts Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:53:52 PG-Node2 repmgrd[2165]: [2020-02-05 11:53:52] [INFO] sleeping 8 seconds until next reconnection attempt Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of node 1, 4 of 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to ping "user=repmgr connect_timeout=2 dbname=repmgr host=16.0.1.156 fallback_application_name=repmgr" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] PQping() returned "PQPING_NO_RESPONSE" Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] unable to reconnect to node 1 after 4 attempts Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [WARNING] wal receiver not running Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] WAL receiver disconnected on all sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] WAL receiver disconnected on all 2 sibling nodes Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] local node's last receive lsn: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node3" (ID: 3) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 3 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] last receive LSN for sibling node "PG-Node3" (ID: 3) is: 0/2214A000 Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has same LSN as current candidate "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node3" (ID: 3) has lower priority (40) than current candidate "PG-Node2" (ID: 2) (60) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] checking state of sibling node "PG-Node-Witness" (ID: 4) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node "PG-Node-Witness" (ID: 4) reports its upstream is node 1, last seen 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] node 4 last saw primary node 26 second(s) ago Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [INFO] visible nodes: 3; total nodes: 3; no nodes have seen the primary within the last 4 seconds … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promotion candidate is "PG-Node2" (ID: 2) Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] this node is the winner, will now promote itself and inform other nodes … … Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] promoting standby to primary Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [DETAIL] promoting server "PG-Node2" (ID: 2) using pg_promote() Feb 5 11:54:00 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:00] [NOTICE] waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] STANDBY PROMOTE successful Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [DETAIL] server "PG-Node2" (ID: 2) was successfully promoted to primary Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] 2 followers to notify Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node3" (ID: 3) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] notifying node "PG-Node-Witness" (ID: 4) to follow node 2 Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [INFO] switching to primary monitoring mode Feb 5 11:54:01 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:01] [NOTICE] monitoring cluster primary "PG-Node2" (ID: 2) Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new witness "PG-Node-Witness" (ID: 4) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:54:07 PG-Node2 repmgrd[2165]: [2020-02-05 11:54:07] [NOTICE] new standby "PG-Node3" (ID: 3) has connected Feb 5 11:55:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:55:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state Feb 5 11:56:02 PG-Node2 repmgrd[2165]: [2020-02-05 11:56:02] [INFO] monitoring primary node "PG-Node2" (ID: 2) in normal state … …
There is a lot of information here, but let’s break down how the events have unfolded. For simplicity, we have grouped messages and placed whitespaces between the groups.
The first set of messages shows the repmgr daemon is trying to connect to the primary node (node ID 1) four times using PQPing(). This is because we specified the connection_check_type parameter to “ping” in the repmgr.conf file. After 4 attempts, the daemon reports it cannot connect to the primary node.
The next set of messages tells us the standbys have disconnected their WAL receivers. This is because we had set the parameter standby_disconnect_on_failover to “true” in the repmgr.conf file.
In the next set of messages, the standby nodes and the witness inquire about the last received LSN from the primary and the last time each saw the primary. The last received LSNs match for both the standby nodes. The nodes agree they cannot see the primary within the last 4 seconds. Note how repmgr daemon also finds PG-Node3 has a lower priority for promotion. As none of the nodes have seen the primary recently, they can reach a quorum that the primary is down.
After this, we have messages that show repmgr is choosing PG-Node2 as the promotion candidate. It declares the node winner and says the node will promote itself and inform other nodes.
The group of messages after this shows PG-Node2 successfully promoting to the primary role. Once that’s done, the nodes PG-Node3 (node ID 3) and PG-Node-Witness (node ID 4) are signaled to follow the newly promoted primary.
The final set of messages shows the two nodes have connected to the new primary and the repmgr daemon has started monitoring the local node.
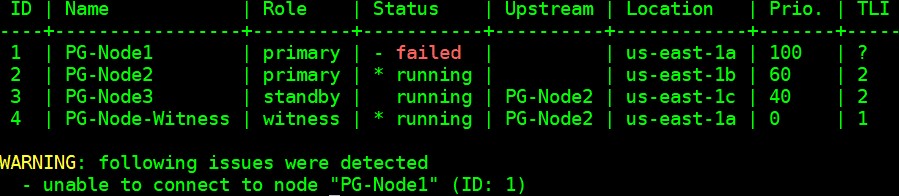
Our cluster is now back in action. We can confirm this by running the “repmgr cluster show” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster show --compact
The output shown in the image below is self-explanatory:
We can also look for the events by running the “repmgr cluster event” command:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/repmgr -f /etc/repmgr/12/repmgr.conf cluster event
The output displays how it happened:
Node ID | Name | Event | OK | Timestamp | Details --------+-----------------+----------------------------+----+---------------------+------------------------------------------------------------------------------------ 3 | PG-Node3 | repmgrd_failover_follow | t | 2020-02-05 11:54:08 | node 3 now following new upstream node 2 3 | PG-Node3 | standby_follow | t | 2020-02-05 11:54:08 | standby attached to upstream node "PG-Node2" (ID: 2) 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new standby "PG-Node3" (ID: 3) has connected 2 | PG-Node2 | child_node_new_connect | t | 2020-02-05 11:54:07 | new witness "PG-Node-Witness" (ID: 4) has connected 4 | PG-Node-Witness | repmgrd_upstream_reconnect | t | 2020-02-05 11:54:02 | witness monitoring connection to primary node "PG-Node2" (ID: 2) 4 | PG-Node-Witness | repmgrd_failover_follow | t | 2020-02-05 11:54:02 | witness node 4 now following new primary node 2 2 | PG-Node2 | repmgrd_reload | t | 2020-02-05 11:54:01 | monitoring cluster primary "PG-Node2" (ID: 2) 2 | PG-Node2 | repmgrd_failover_promote | t | 2020-02-05 11:54:01 | node 2 promoted to primary; old primary 1 marked as failed 2 | PG-Node2 | standby_promote | t | 2020-02-05 11:54:01 | server "PG-Node2" (ID: 2) was successfully promoted to primary 1 | PG-Node1 | child_node_new_connect | t | 2020-02-05 11:37:32 | new witness "PG-Node-Witness" (ID: 4) has connected
Wniosek
This completes our two-part series on repmgr and its daemon repmgrd. As we saw in the first part, setting up a multi-node PostgreSQL replication is very simple with repmgr. The daemon makes it even easier to automate a failover. It also automatically redirects existing standbys to follow the new primary. In native PostgreSQL replication, all existing standbys have to be manually configured to replicate from the new primary – automating this process saves valuable time and effort for the DBA.
One thing we have not covered here is “fencing off” the failed primary. In a failover situation, a failed primary needs to be removed from the cluster, and remain inaccessible to client connections. This is to prevent any split-brain situation in the event the old primary accidentally comes back online. The repmgr daemon can work with a connection-pooling tool like pgbouncer to implement the fence-off process. For more information, you can refer to this 2ndQuadrant Github documentation.
Also, after a failover, applications connecting to the cluster need to have their connection strings changed to repoint to the new master. This is a big topic in itself and we will not go into the details here, but one of the methods to address this can be the use of a virtual IP address (and associated DNS resolution) to hide the underlying master node of the cluster.
How to Automate PostgreSQL 12 Replication and Failover with repmgr – Part 1