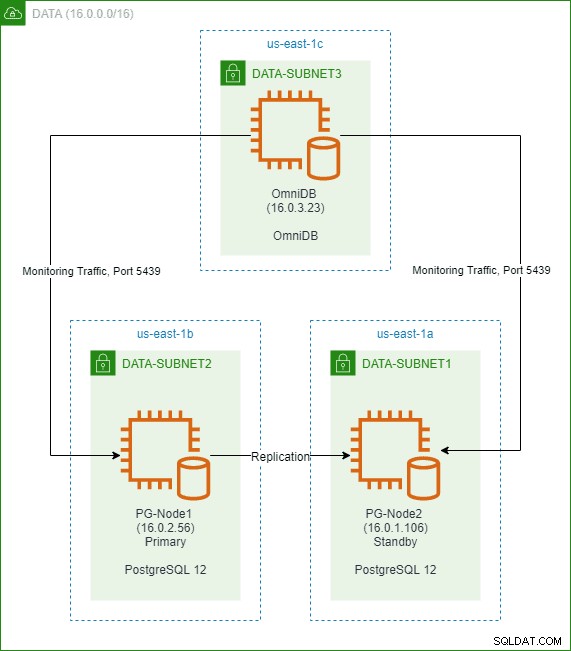
W poprzednim artykule z tej serii stworzyliśmy dwuwęzłowy klaster PostgreSQL 12 w chmurze AWS. Zainstalowaliśmy również i skonfigurowaliśmy 2ndQuadrant OmniDB w trzecim węźle. Poniższy obrazek przedstawia architekturę:
Mogliśmy połączyć się zarówno z węzłem podstawowym, jak i rezerwowym z internetowego interfejsu użytkownika OmniDB. Następnie przywróciliśmy przykładową bazę danych o nazwie „dvdrental” w węźle podstawowym, która rozpoczęła replikację w trybie gotowości.
W tej części serii nauczymy się tworzyć i korzystać z dashboardu monitorującego w OmniDB. Administratorzy baz danych i zespoły operacyjne często wolą narzędzia graficzne niż złożone zapytania do wizualnej kontroli stanu bazy danych. OmniDB zawiera szereg ważnych widżetów, które można łatwo wykorzystać w panelu monitorowania. Jak zobaczymy później, pozwala również użytkownikom pisać własne widżety monitorowania.
Tworzenie panelu monitorowania wydajności
Zacznijmy od domyślnego pulpitu nawigacyjnego, z którego korzysta OmniDB.
Na poniższym obrazku jesteśmy połączeni z węzłem podstawowym (PG-Node1). Klikamy prawym przyciskiem myszy nazwę instancji, a następnie z wyskakującego menu wybieramy „Monitor”, a następnie „Pulpit nawigacyjny”.
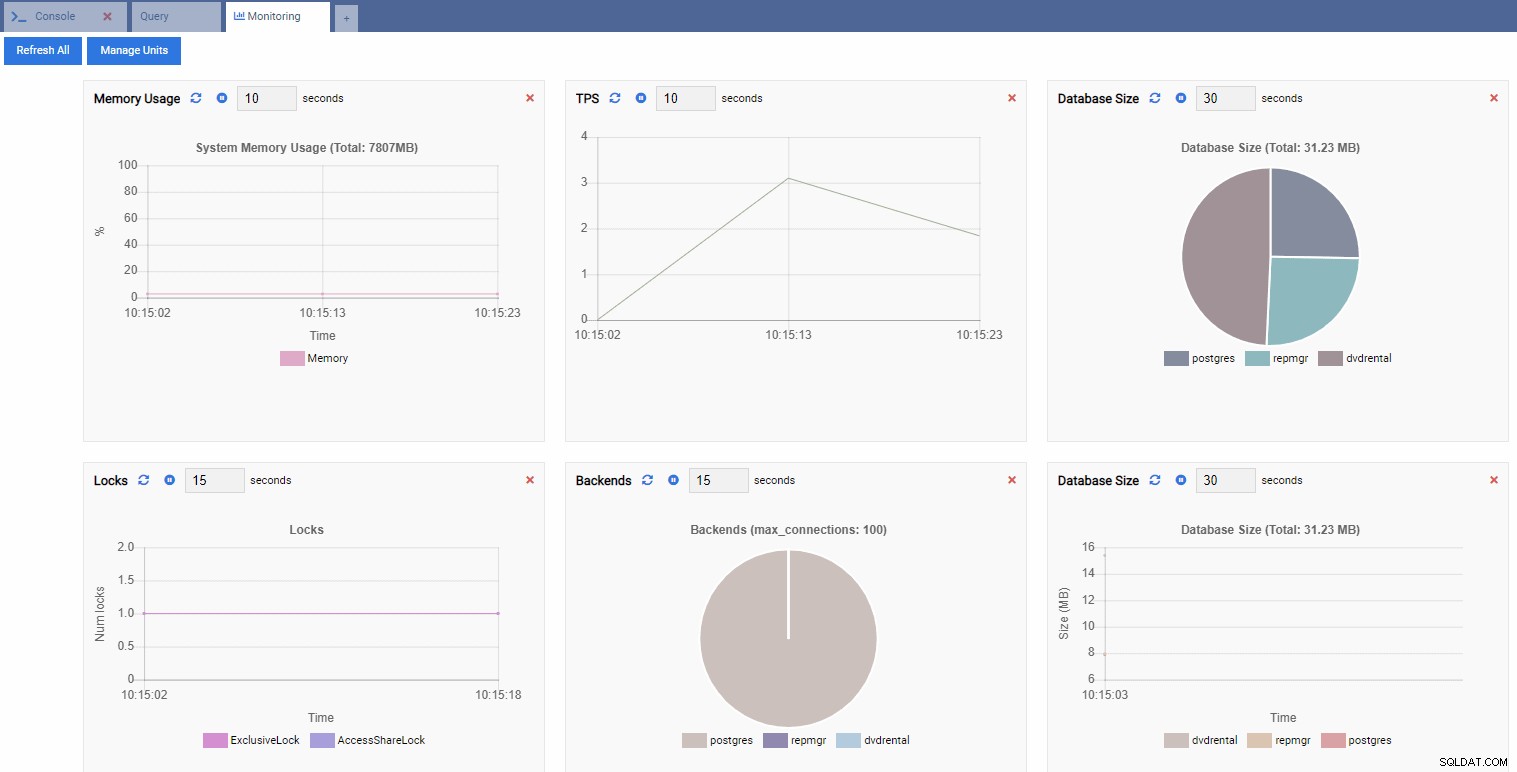
Spowoduje to otwarcie pulpitu nawigacyjnego z kilkoma widżetami.
W terminologii OmniDB prostokątne widżety na desce rozdzielczej nazywają się jednostkami monitorowania . Każda z tych jednostek pokazuje określoną metrykę z instancji PostgreSQL, z którą jest połączona, i dynamicznie odświeża swoje dane.
Zrozumienie jednostek monitorujących
OmniDB zawiera cztery rodzaje jednostek monitorujących:
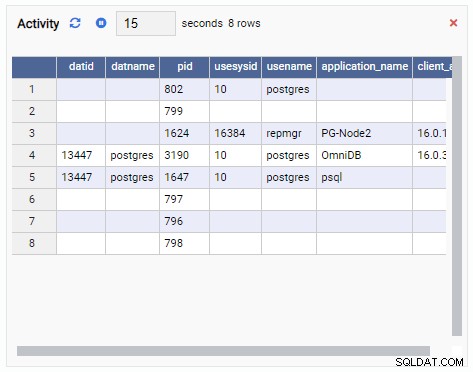
- Siatka to struktura tabelaryczna, która pokazuje wynik zapytania. Na przykład może to być wynik SELECT * FROM pg_stat_replication. Siatka wygląda tak:
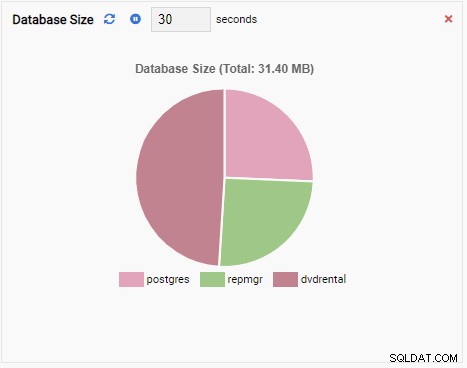
- Wykres pokazuje dane w formacie graficznym, takim jak linie lub wykresy kołowe. Gdy się odświeży, cały wykres zostanie przerysowany na ekranie z nową wartością, a stara wartość zniknie. Dzięki tym jednostkom monitorującym możemy zobaczyć tylko bieżącą wartość metryki. Oto przykład wykresu:
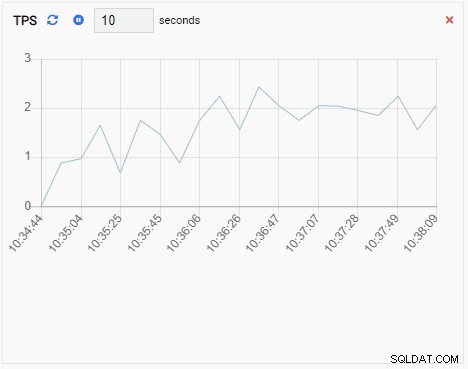
- Dołącz do wykresu jest również jednostką monitorującą typu Wykres, z wyjątkiem tego, że podczas odświeżania dodaje nową wartość do istniejącej serii. Dzięki Chart-Append możemy łatwo zobaczyć trendy w czasie. Oto przykład:
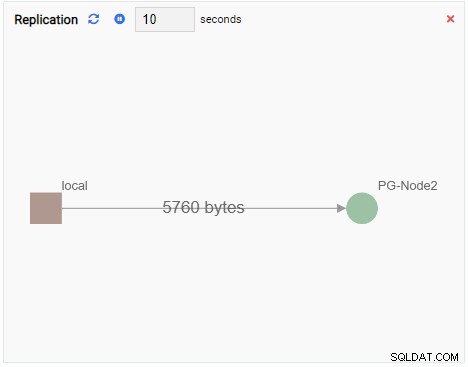
- Wykres pokazuje relacje między instancjami klastra PostgreSQL a powiązaną metryką. Podobnie jak jednostka monitorująca wykres, jednostka monitorująca wykres również odświeża swoją starą wartość nową. Poniższy obrazek pokazuje, że bieżący węzeł (PG-Node1) jest replikowany do PG-Node2:
Każda jednostka monitorująca ma kilka wspólnych elementów:
- Nazwa jednostki monitorującej
- Przycisk „odśwież” do ręcznego odświeżenia jednostki
- Przycisk „wstrzymaj”, aby tymczasowo zatrzymać odświeżanie jednostki monitorującej
- Pole tekstowe pokazujące aktualny interwał odświeżania. Można to zmienić
- Przycisk „zamknij” (czerwony krzyżyk) do usunięcia jednostki monitorującej z deski rozdzielczej
- Rzeczywisty obszar rysowania monitoringu
Wstępnie zbudowane jednostki monitorujące
OmniDB zawiera szereg jednostek monitorujących dla PostgreSQL, które możemy dodać do naszego pulpitu nawigacyjnego. Aby uzyskać dostęp do tych jednostek, klikamy przycisk „Zarządzaj jednostkami” u góry panelu:
Spowoduje to otwarcie listy „Zarządzaj jednostkami”:
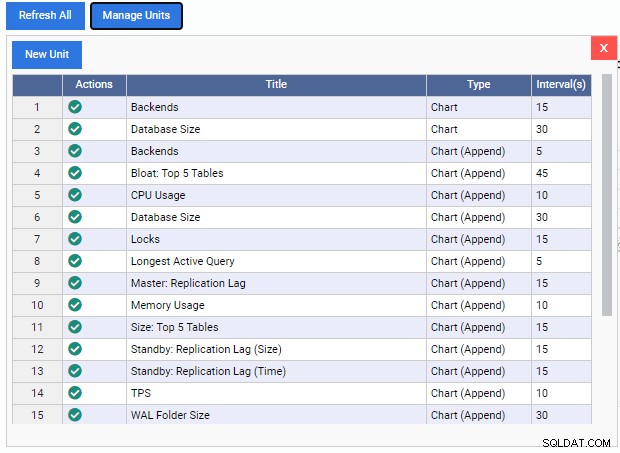
Jak widać, jest tu kilka gotowych Jednostek Monitorujących. Kody dla tych jednostek monitorujących można bezpłatnie pobrać z repozytorium GitHub 2ndQuadrant. Każda wymieniona tutaj jednostka pokazuje swoją nazwę, typ (wykres, dołączanie do wykresu, wykres lub siatka) i domyślną częstotliwość odświeżania.
Aby dodać jednostkę monitorującą do pulpitu nawigacyjnego, wystarczy kliknąć zielony znacznik pod kolumną „Działania” dla tej jednostki. Możemy mieszać i dopasowywać różne jednostki monitorujące, aby zbudować żądany pulpit nawigacyjny.
Na poniższym obrazku dodaliśmy następujące jednostki do naszego panelu monitorowania wydajności i usunęliśmy wszystko inne:
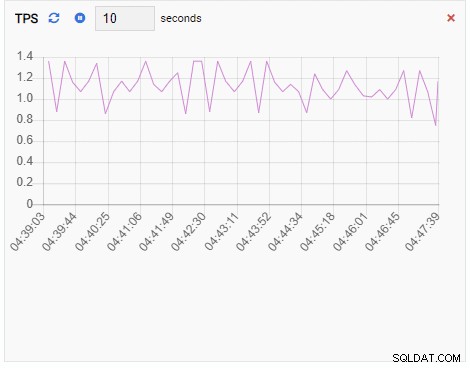
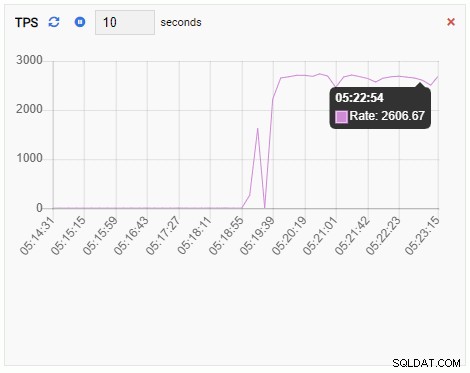
TPS (transakcja na sekundę):
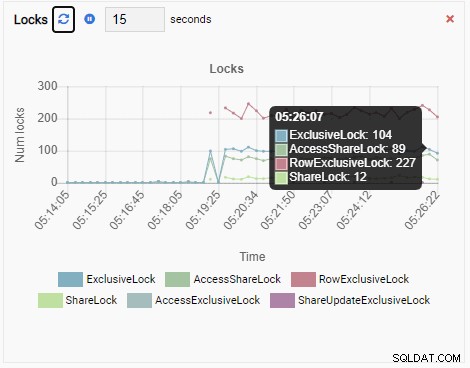
Liczba zamków:
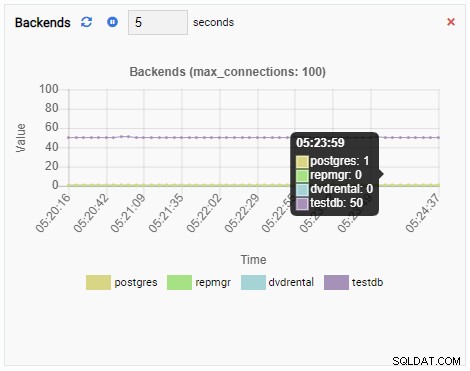
Liczba backendów:
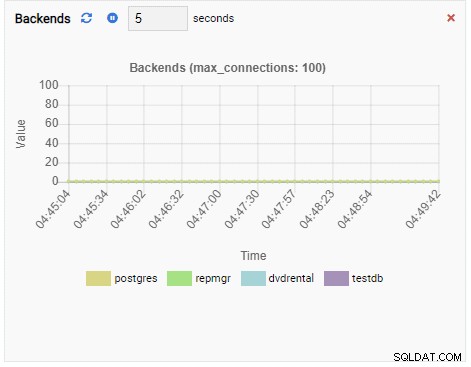
Ponieważ nasza instancja jest bezczynna, widzimy, że wartości TPS, Locks i Backends są minimalne.
Testowanie panelu monitorowania
Uruchomimy teraz pgbench w naszym węźle podstawowym (PG-Node1). pgbench to proste narzędzie do testów porównawczych dostarczane z PostgreSQL. Podobnie jak większość innych narzędzi tego rodzaju, pgbench tworzy przykładowy schemat i tabele systemów OLTP w bazie danych podczas inicjalizacji. Następnie może emulować wiele połączeń klienckich, z których każde przeprowadza pewną liczbę transakcji w bazie danych. W tym przypadku nie będziemy testować węzła podstawowego PostgreSQL; utworzymy bazę danych tylko dla pgbench i sprawdzimy, czy nasze jednostki monitorujące deski rozdzielczej wykryją zmianę stanu systemu.
Najpierw tworzymy bazę danych dla pgbench w węźle podstawowym:
[example@sqldat.com ~]$ psql -h PG-Node1 -U postgres -c "CREATE DATABASE testdb"; CREATE DATABASE
Następnie inicjujemy bazę danych „testdb” dla pgbench:
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -I dtgvp -i -s 20 testdb dropping old tables... creating tables... generating data... 100000 of 2000000 tuples (5%) done (elapsed 0.02 s, remaining 0.43 s) 200000 of 2000000 tuples (10%) done (elapsed 0.05 s, remaining 0.41 s) … … 2000000 of 2000000 tuples (100%) done (elapsed 1.84 s, remaining 0.00 s) vacuuming... creating primary keys... done.
Po zainicjowaniu bazy danych rozpoczynamy właściwy proces ładowania. W poniższym fragmencie kodu prosimy pgbench o rozpoczęcie od 50 jednoczesnych połączeń klientów z bazą danych testdb, przy czym każde połączenie uruchamia 100000 transakcji na swoich tabelach. Test obciążenia będzie przebiegał w dwóch wątkach.
[example@sqldat.com ~]$ /usr/pgsql-12/bin/pgbench -h PG-Node1 -p 5432 -c 50 -j 2 -t 100000 testdb starting vacuum...end. … …
Jeśli teraz wrócimy do naszego pulpitu nawigacyjnego OmniDB, zobaczymy, że jednostki monitorujące pokazują bardzo różne wyniki.
Wskaźnik TPS wykazuje dość wysoką wartość. Nastąpił nagły skok z mniej niż 2 do ponad 2000:
Zwiększyła się liczba backendów. Zgodnie z oczekiwaniami, testdb ma 50 połączeń, podczas gdy inne bazy danych są bezczynne:
I wreszcie, liczba blokad na wyłączność wierszy w bazie danych testdb jest również wysoka:
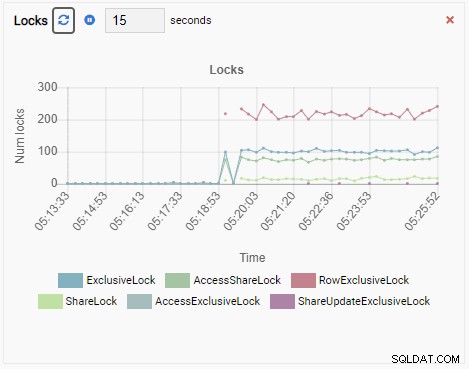
Teraz wyobraź sobie to. Jesteś DBA i używasz OmniDB do zarządzania flotą instancji PostgreSQL. Otrzymasz telefon, aby zbadać niską wydajność w jednej z instancji.
Korzystając z pulpitu nawigacyjnego, takiego jak ten, który właśnie widzieliśmy (chociaż jest to bardzo prosty), możesz łatwo znaleźć przyczynę. Możesz sprawdzić liczbę backendów, blokad, dostępnej pamięci itp., aby zobaczyć, co powoduje problem.
I właśnie tam OmniDB może być naprawdę pomocnym narzędziem.
Tworzenie niestandardowych jednostek monitorowania
Czasami będziemy musieli stworzyć własne Jednostki Monitorujące. Aby napisać nową jednostkę monitorującą, klikamy przycisk „Nowa jednostka” na liście „Zarządzaj jednostkami”. Spowoduje to otwarcie nowej karty z pustym obszarem roboczym do pisania kodu:
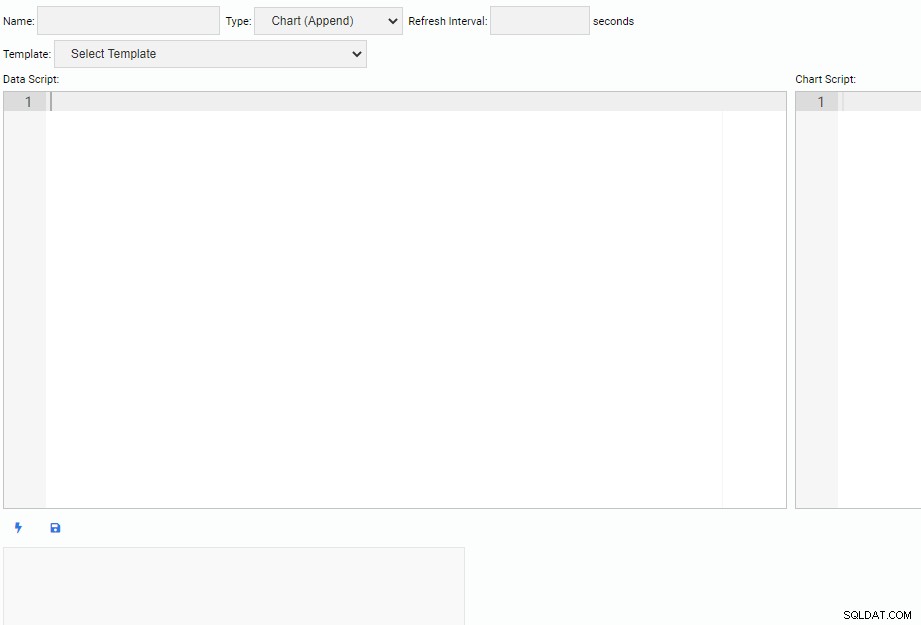
W górnej części ekranu musimy określić nazwę naszej jednostki monitorującej, wybrać jej typ i określić domyślny interwał odświeżania. Możemy również wybrać istniejącą jednostkę jako szablon.
Pod sekcją nagłówka znajdują się dwa pola tekstowe. Edytor „Data Script” to miejsce, w którym piszemy kod, aby uzyskać dane dla naszej jednostki monitorującej. Za każdym razem, gdy jednostka jest odświeżana, zostanie uruchomiony kod skryptu danych. Edytor „Chart Script” to miejsce, w którym piszemy kod do rysowania rzeczywistej jednostki. Jest uruchamiany, gdy jednostka jest rysowana po raz pierwszy.
Cały kod skryptu danych jest napisany w Pythonie. W przypadku jednostki monitorowania typu wykresu OmniDB wymaga, aby skrypt wykresu był napisany w Chart.js.
Utworzymy teraz jednostkę monitorującą, aby pokazać 5 największych dużych tabel w bieżącej bazie danych. W oparciu o bazę danych wybraną w OmniDB, jednostka monitorująca zmieni swój sposób wyświetlania, aby odzwierciedlić nazwy pięciu największych tabel w tej bazie danych.
Do pisania nowej jednostki najlepiej zacząć od istniejącego szablonu i zmodyfikować jego kod. Oszczędzi to zarówno czas, jak i wysiłek. Na poniższym obrazku nazwaliśmy naszą Jednostkę Monitorującą „5 największych dużych stołów”. Wybraliśmy go jako wykres (bez dołączania) i zapewniliśmy częstotliwość odświeżania 30 sekund. Oparliśmy również naszą jednostkę monitorującą na szablonie rozmiaru bazy danych:
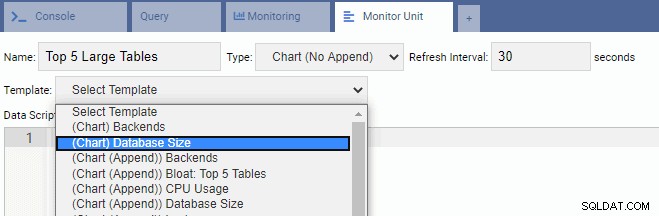
Pole tekstowe Data Script jest automatycznie wypełniane kodem jednostki monitorującej rozmiar bazy danych:
from datetime import datetime
from random import randint
databases = connection.Query('''
SELECT d.datname AS datname,
round(pg_catalog.pg_database_size(d.datname)/1048576.0,2) AS size
FROM pg_catalog.pg_database d
WHERE d.datname not in ('template0','template1')
''')
data = []
color = []
label = []
for db in databases.Rows:
data.append(db["size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(db["datname"])
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Dataset 1"
}
],
"title": "Database Size (Total: " + str(total_size) + " MB)"
} Pole tekstowe Chart Script jest również wypełnione kodem:
total_size = connection.ExecuteScalar('''
SELECT round(sum(pg_catalog.pg_database_size(datname)/1048576.0),2)
FROM pg_catalog.pg_database
WHERE NOT datistemplate
''')
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Database Size (Total: " + str(total_size) + " MB)"
}
}
} Możemy zmodyfikować Data Script, aby uzyskać 5 największych dużych tabel w bazie danych. W poniższym skrypcie zachowaliśmy większość oryginalnego kodu, z wyjątkiem instrukcji SQL:
from datetime import datetime
from random import randint
tables = connection.Query('''
SELECT nspname || '.' || relname AS "tablename",
round(pg_catalog.pg_total_relation_size(c.oid)/1048576.0,2) AS "table_size"
FROM pg_class C
LEFT JOIN pg_namespace N ON (N.oid = C.relnamespace)
WHERE nspname NOT IN ('pg_catalog', 'information_schema')
AND C.relkind <> 'i'
AND nspname !~ '^pg_toast'
ORDER BY 2 DESC
LIMIT 5;
''')
data = []
color = []
label = []
for table in tables.Rows:
data.append(table["table_size"])
color.append("rgb(" + str(randint(125, 225)) + "," + str(randint(125, 225)) + "," + str(randint(125, 225)) + ")")
label.append(table["tablename"])
result = {
"labels": label,
"datasets": [
{
"data": data,
"backgroundColor": color,
"label": "Top 5 Large Tables"
}
]
} Tutaj otrzymujemy łączny rozmiar każdej tabeli i jej indeksów w bieżącej bazie danych. Sortujemy wyniki w kolejności malejącej i wybieramy pięć górnych wierszy.
Następnie wypełniamy trzy tablice Pythona, iterując po zestawie wyników.
Na koniec budujemy ciąg JSON na podstawie wartości tablic.
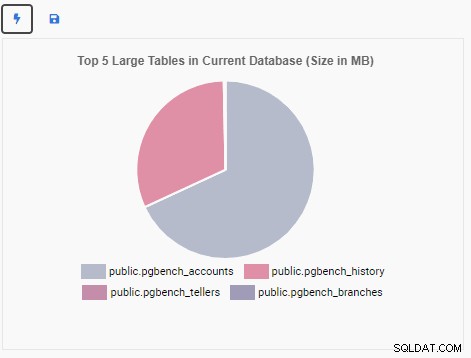
W polu tekstowym Chart Script zmodyfikowaliśmy kod, aby usunąć oryginalne polecenie SQL. Tutaj określamy tylko kosmetyczny aspekt wykresu. Definiujemy wykres jako typ kołowy i podajemy jego tytuł:
result = {
"type": "pie",
"data": None,
"options": {
"responsive": True,
"title":{
"display":True,
"text":"Top 5 Large Tables in Current Database (Size in MB)"
}
}
} Teraz możemy przetestować jednostkę, klikając ikonę błyskawicy. Spowoduje to wyświetlenie nowej jednostki monitorującej w obszarze podglądu rysunku:
Następnie zapisujemy jednostkę, klikając ikonę dysku. Okno komunikatu potwierdza, że jednostka została zapisana:

Teraz wracamy do naszego pulpitu monitorowania i dodajemy nową jednostkę monitorującą:
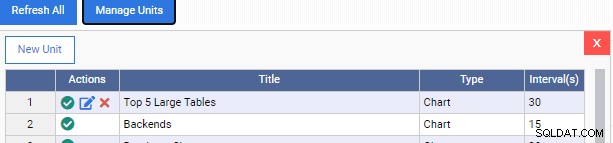
Zwróć uwagę, że w kolumnie „Działania” mamy jeszcze dwie ikony dla naszej niestandardowej jednostki monitorującej. Jeden służy do jego edycji, drugi do usuwania go z OmniDB.
Jednostka monitorująca „Top 5 dużych tabel” wyświetla teraz pięć największych tabel w bieżącej bazie danych:
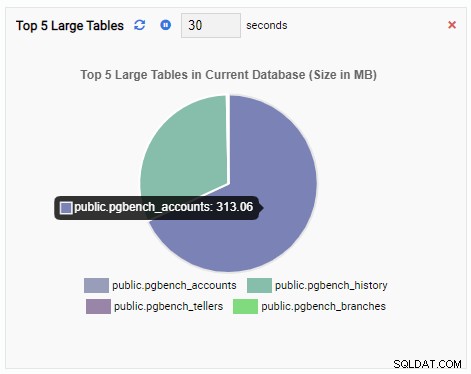
Jeśli zamkniemy pulpit nawigacyjny, przełączymy się do innej bazy danych z panelu nawigacyjnego i ponownie otworzymy pulpit nawigacyjny, zobaczymy, że jednostka monitorująca zmieniła się, aby odzwierciedlić tabele tej bazy danych:
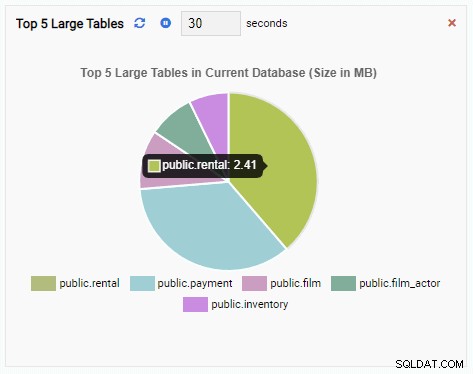
Końcowe słowa
To kończy naszą dwuczęściową serię dotyczącą OmniDB. Jak widzieliśmy, OmniDB ma kilka fajnych jednostek monitorujących, które administratorzy baz danych PostgreSQL uznają za przydatne do śledzenia wydajności. Zobaczyliśmy, jak możemy wykorzystać te jednostki do identyfikacji potencjalnych wąskich gardeł na serwerze. Zobaczyliśmy również, jak tworzyć własne, niestandardowe jednostki. Zachęcamy czytelników do tworzenia i testowania jednostek monitorowania wydajności dla ich określonych obciążeń. 2ndQuadrant z zadowoleniem przyjmuje każdy wkład w repozytorium jednostki monitorującej OmniDB na GitHub.