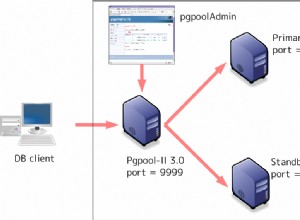
Prostsza alternatywa dla opublikowanej odpowiedzi. Powinien działać znacznie lepiej.
Ta funkcja pobiera wiersz z podanej tabeli (in_table_name ) i wartość klucza podstawowego (in_row_pk ) i wstawia go jako nowy wiersz do tej samej tabeli, z zamienionymi niektórymi wartościami (in_override_values ). Zwracana jest domyślnie nowa wartość klucza podstawowego (pk_new ).
CREATE OR REPLACE FUNCTION f_clone_row(in_table_name regclass
, in_row_pk int
, in_override_values hstore
, OUT pk_new int) AS
$func$
DECLARE
_pk text; -- name of PK column
_cols text; -- list of names of other columns
BEGIN
-- Get name of PK column
SELECT INTO _pk a.attname
FROM pg_catalog.pg_index i
JOIN pg_catalog.pg_attribute a ON a.attrelid = i.indrelid
AND a.attnum = i.indkey[0] -- 1 PK col!
WHERE i.indrelid = 't'::regclass
AND i.indisprimary;
-- Get list of columns excluding PK column
_cols := array_to_string(ARRAY(
SELECT quote_ident(attname)
FROM pg_catalog.pg_attribute
WHERE attrelid = in_table_name -- regclass used as OID
AND attnum > 0 -- exclude system columns
AND attisdropped = FALSE -- exclude dropped columns
AND attname <> _pk -- exclude PK column
), ',');
-- INSERT cloned row with override values, returning new PK
EXECUTE format('
INSERT INTO %1$I (%2$s)
SELECT %2$s
FROM (SELECT (t #= $1).* FROM %1$I t WHERE %3$I = $2) x
RETURNING %3$I'
, in_table_name, _cols, _pk)
USING in_override_values, in_row_pk -- use override values directly
INTO pk_new; -- return new pk directly
END
$func$ LANGUAGE plpgsql;
Zadzwoń:
SELECT f_clone_row('t', 1, '"col1"=>"foo_new","col2"=>"bar_new"'::hstore);
-
Użyj
regclassjako typ parametru wejściowego, więc na początku można używać tylko prawidłowych nazw tabel, a wstrzyknięcie SQL jest wykluczone. Funkcja również zawodzi wcześniej i bardziej wdzięcznie, jeśli powinieneś podać nieprawidłową nazwę tabeli. -
Użyj
OUTparametr (pk_new), aby uprościć składnię. -
Nie ma potrzeby ręcznego określania następnej wartości klucza podstawowego. Jest on wstawiany automatycznie i zwracany po fakcie. To nie tylko prostsze i szybsze, ale także pozwala uniknąć zmarnowanych lub niesprawnych numerów sekwencyjnych.
-
Użyj
format()w celu uproszczenia montażu dynamicznego ciągu zapytania i zmniejszenia jego podatności na błędy. Zwróć uwagę, jak używam parametrów pozycyjnych odpowiednio dla identyfikatorów i ciągów. -
Opieram się na twoim domniemanym założeniu że dozwolone tabele mają pojedynczą kolumnę klucza podstawowego typu liczba całkowita z domyślną kolumną . Zazwyczaj
serialkolumny. -
Kluczowym elementem funkcji jest końcowe
INSERT:- Scal wartości zastąpienia z istniejącym wierszem za pomocą
#=operator w podselekcji i natychmiast zdekomponuj wynikowy wiersz. - Następnie możesz wybrać tylko odpowiednie kolumny w głównym
SELECT. - Pozwól Postgresowi przypisać domyślną wartość PK i odzyskać ją za pomocą
POWRÓTklauzula. - Zapisz zwróconą wartość do
OUTparametr bezpośrednio. - Wszystko zrobione w jednym poleceniu SQL, które jest zazwyczaj najszybsze.
- Scal wartości zastąpienia z istniejącym wierszem za pomocą