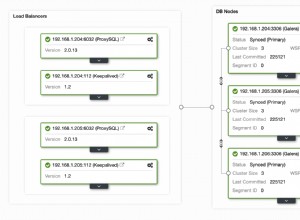
Twoje obliczenia są wyłączone w kilku punktach.
- Rozmiar pamięci
varchar,text(icharacter!) jest cytując instrukcję ):
Odważny nacisk, aby odpowiedzieć na pytanie w komentarzu.
-
HeapTupleHeader zajmuje 23 bajty . Ale każda krotka („element” — pozycja wiersza lub indeksu) ma identyfikator elementu na początku strony danych do niego, łącznie na wspomnianych 27 bajtach. Rozróżnienie jest istotne, ponieważ rzeczywiste dane użytkownika zaczynają się od wielokrotności
MAXALIGNod początku każdego elementu, a identyfikator elementu nie wlicza się do tego przesunięcia - podobnie jak rzeczywisty "rozmiar krotki". -
1 bajt dopełnienia z powodu wyrównania danych (wielokrotność 8), które w tym przypadku jest używane dla bitmapy NULL.
-
Brak dopełnienia dla typu
varchar(ale dodatkowy bajt wspomniany powyżej)
Tak więc rzeczywiste obliczenia (ze wszystkimi kolumnami wypełnionymi do maksimum) to:
23 -- heaptupleheader
+ 1 -- NULL bitmap (or padding if row has NO null values)
+ 9 -- columns ...
+ 101
+ 2
+ 101
+ 4
+ 11
-------------
252 bytes
+ 4 -- item identifier at page startPowiązane:
- Czy nie używasz NULL w PostgreSQL nadal używa bitmapy NULL w nagłówku?
- Obliczanie i oszczędzanie miejsca w PostgreSQL
Więcej znajdziesz na liście linków po prawej stronie tych odpowiedzi.