Moodle to bardzo popularna platforma do prowadzenia kursów online. W sytuacji, którą obserwujemy w 2020 r., Moodle wraz z komunikatorami, takimi jak Zoom, stanowi podstawę usług, które umożliwiają naukę online i edukację w domu. Zapotrzebowanie na platformy Moodle znacznie wzrosło w porównaniu do lat poprzednich. Zbudowano nowe platformy, dociążono platformy, które dawniej działały tylko jako narzędzie pomocnicze, a teraz mają napędzać cały wysiłek edukacyjny. Jak skalować Moodle? Prowadzimy blog na ten temat. Jak skalować backend bazy danych dla Moodle? Cóż, to już inna historia. Przyjrzyjmy się temu, ponieważ skalowanie baz danych nie jest najłatwiejsze, zwłaszcza jeśli Moodle doda swój własny mały zwrot.
Jako punkt wejścia użyjemy architektury opisanej w jednym z naszych wcześniejszych postów. Klaster MariaDB z ProxySQL i Keepalived na szczycie.
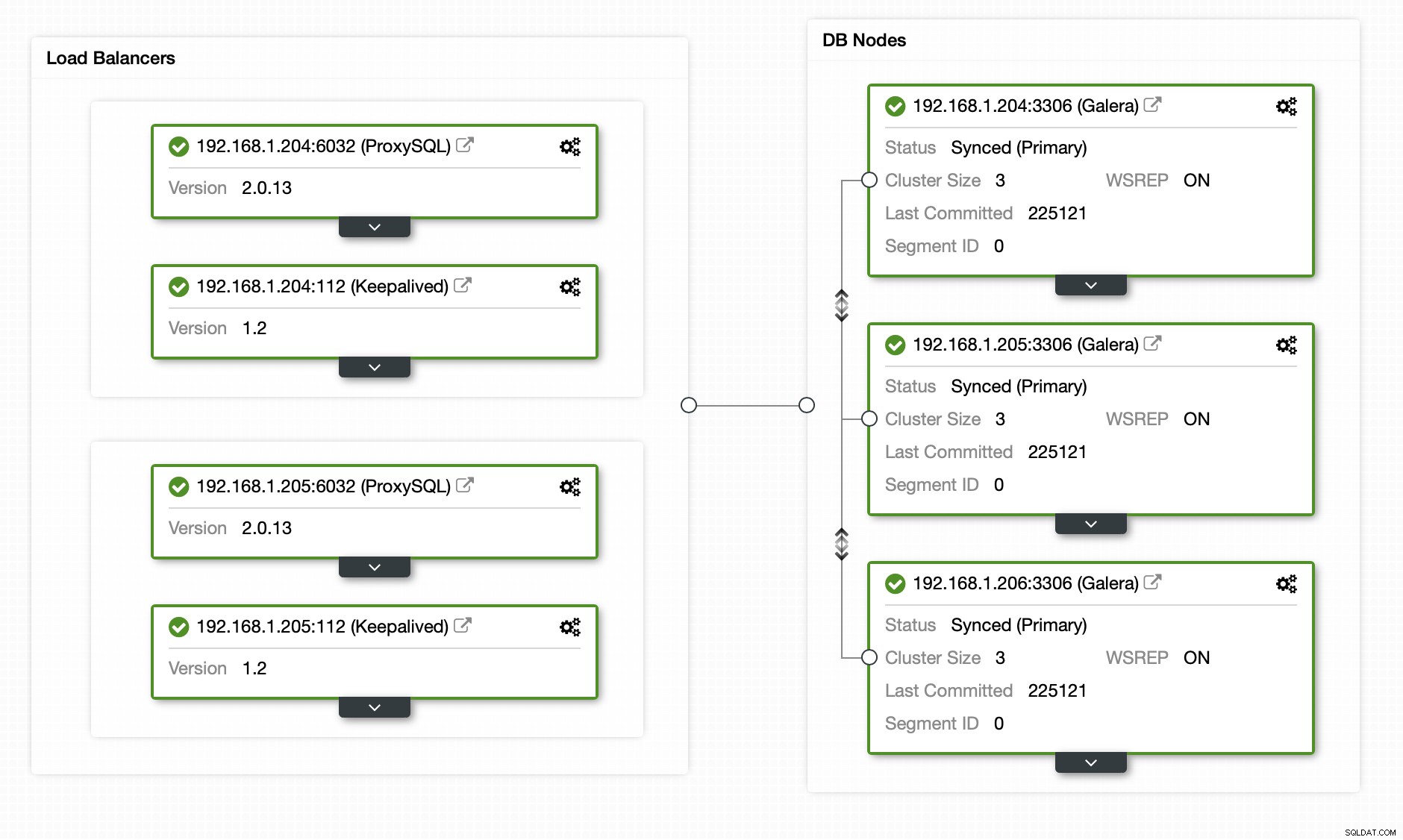
Jak widać, mamy trzywęzłowy klaster MariaDB z ProxySQL, który oddziela bezpieczne odczyty od reszty ruchu na podstawie użytkownika.
<?php // Moodle configuration file
unset($CFG);
global $CFG;
$CFG = new stdClass();
$CFG->dbtype = 'mysqli';
$CFG->dblibrary = 'native';
$CFG->dbhost = '192.168.1.222';
$CFG->dbname = 'moodle';
$CFG->dbuser = 'moodle';
$CFG->dbpass = 'pass';
$CFG->prefix = 'mdl_';
$CFG->dboptions = array (
'dbpersist' => 0,
'dbport' => 6033,
'dbsocket' => '',
'dbcollation' => 'utf8mb4_general_ci',
'readonly' => [
'instance' => [
'dbhost' => '192.168.1.222',
'dbport' => 6033,
'dbuser' => 'moodle_safereads',
'dbpass' => 'pass'
]
]
);
$CFG->wwwroot = 'https://192.168.1.200/moodle';
$CFG->dataroot = '/var/www/moodledata';
$CFG->admin = 'admin';
$CFG->directorypermissions = 0777;
require_once(__DIR__ . '/lib/setup.php');
// There is no php closing tag in this file,
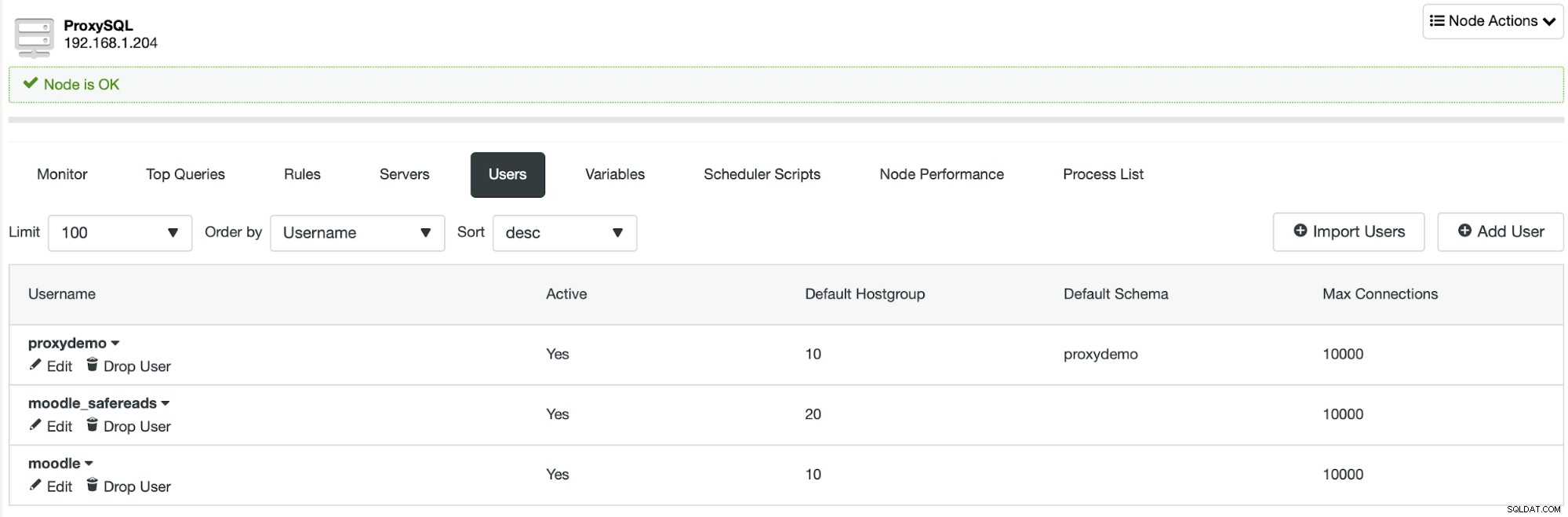
// it is intentional because it prevents trailing whitespace problems!Użytkownik, jak pokazano powyżej, jest zdefiniowany w pliku konfiguracyjnym Moodle. Pozwala nam to na automatyczne i bezpieczne wysyłanie zapisów i wszystkich instrukcji SELECT, które wymagają spójności danych do węzła zapisującego, przy jednoczesnym wysyłaniu niektórych poleceń SELECT do pozostałych węzłów w klastrze MariaDB.
Załóżmy, że ta konkretna konfiguracja nam nie wystarcza. Jakie mamy opcje? W konfiguracji mamy dwa główne elementy - Klaster MariaDB i ProxySQL. Rozważymy problemy po obu stronach:
- Co można zrobić, jeśli instancja ProxySQL nie radzi sobie z ruchem?
- Co można zrobić, jeśli Klaster MariaDB nie radzi sobie z ruchem?
Zacznijmy od pierwszego scenariusza.
Instancja ProxySQL jest przeciążona
W obecnym środowisku tylko jedna instancja ProxySQL może obsługiwać ruch - ta, na którą wskazuje Virtual IP. To pozostawia nam instancję ProxySQL, która działa jako gotowość i działa, ale nie jest używana do niczego. Jeśli aktywna instancja ProxySQL zbliża się do nasycenia procesora, możesz chcieć zrobić kilka rzeczy. Po pierwsze, oczywiście, możesz skalować w pionie - zwiększenie rozmiaru instancji ProxySQL może być najłatwiejszym sposobem na obsłużenie większego ruchu. Należy pamiętać, że ProxySQL jest domyślnie skonfigurowany do korzystania z 4 wątków.
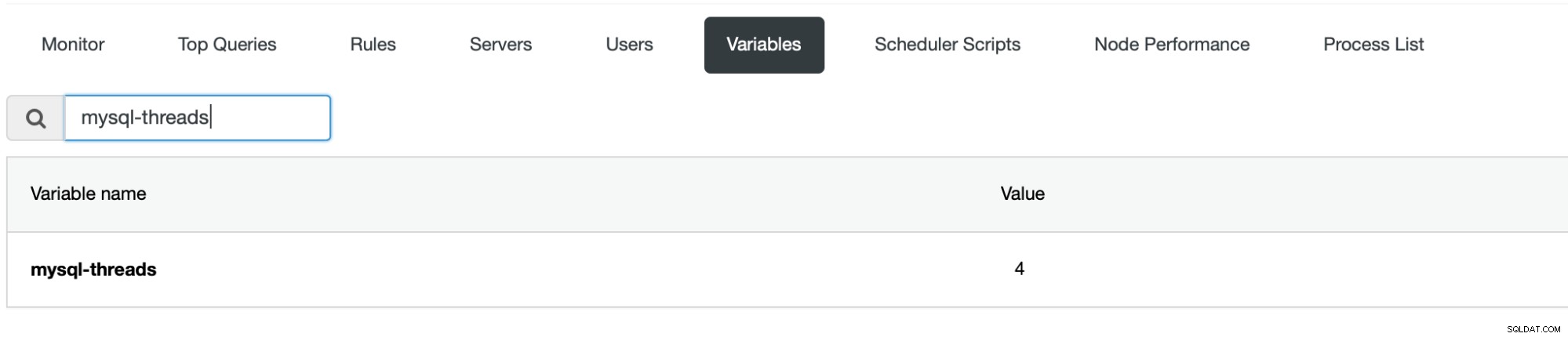
Jeśli chcesz mieć możliwość wykorzystania większej liczby rdzeni procesora, jest to ustawienie, które również musisz zmienić.
Alternatywnie możesz spróbować przeskalować w poziomie. Zamiast używać dwóch instancji ProxySQL z VIPem, możesz połączyć ProxySQL z hostami Moodle. Następnie chcesz przekonfigurować Moodle tak, aby łączyło się z ProxySQL na lokalnym hoście, najlepiej przez gniazdo Unix - jest to najbardziej wydajny sposób łączenia się z ProxySQL. Nie ma zbyt wielu konfiguracji, których używamy z ProxySQL, dlatego używanie wielu instancji ProxySQL nie powinno zwiększać obciążenia. Jeśli chcesz, zawsze możesz skonfigurować klaster ProxySQL, aby pomóc Ci zachować synchronizację instancji ProxySQL w odniesieniu do konfiguracji.
Klaster MariaDB jest przeciążony
Teraz mówimy o poważniejszym problemie. Oczywiście jak zwykle pomoże zwiększenie rozmiaru instancji. Z drugiej strony skalowanie w poziomie jest nieco ograniczone ze względu na ograniczenie „bezpiecznych odczytów”. Jasne, możesz dodać więcej węzłów do klastra, ale możesz ich używać tylko do bezpiecznych odczytów. W jakim stopniu pozwala to na skalowanie, zależy to od obciążenia pracą. Przy zwykłym obciążeniu tylko do odczytu (przeglądanie treści, forów itp.) wygląda to całkiem nieźle:
MySQL [(none)]> SELECT hostgroup, srv_host, srv_port, status, queries FROM stats_mysql_connection_pool WHERE hostgroup IN (20, 10) AND status='ONLINE';
+-----------+---------------+----------+--------+---------+
| hostgroup | srv_host | srv_port | status | Queries |
+-----------+---------------+----------+--------+---------+
| 20 | 192.168.1.204 | 3306 | ONLINE | 5683 |
| 20 | 192.168.1.205 | 3306 | ONLINE | 5543 |
| 10 | 192.168.1.206 | 3306 | ONLINE | 553 |
+-----------+---------------+----------+--------+---------+
3 rows in set (0.002 sec)To prawie stosunek 1:20 – na jedno zapytanie, które trafia do autora, mamy 20 „bezpiecznych odczytów”, które można rozłożyć na pozostałe węzły. Z drugiej strony, kiedy zaczynamy modyfikować dane, stosunek szybko się zmienia.
MySQL [(none)]> SELECT hostgroup, srv_host, srv_port, status, queries FROM stats_mysql_connection_pool WHERE hostgroup IN (20, 10) AND status='ONLINE';
+-----------+---------------+----------+--------+---------+
| hostgroup | srv_host | srv_port | status | Queries |
+-----------+---------------+----------+--------+---------+
| 20 | 192.168.1.204 | 3306 | ONLINE | 3117 |
| 20 | 192.168.1.205 | 3306 | ONLINE | 3010 |
| 10 | 192.168.1.206 | 3306 | ONLINE | 6807 |
+-----------+---------------+----------+--------+---------+
3 rows in set (0.003 sec)To jest wynik po wystawieniu kilku ocen, stworzeniu tematów na forum i dodaniu treści kursu. Jak widać, przy takim współczynniku bezpiecznych/niebezpiecznych zapytań, pisarz zostanie nasycony wcześniej niż czytniki, dlatego skalowanie poprzez dodanie większej liczby węzłów nie jest odpowiednie.
Co można z tym zrobić? Istnieje ustawienie zwane „opóźnieniem”. Zgodnie z plikiem konfiguracyjnym określa, kiedy można bezpiecznie odczytać tabelę po zapisie. Gdy nastąpi zapis, tabela jest oznaczana jako zmodyfikowana i przez czas „opóźnienia” wszystkie SELECTy będą wysyłane do węzła zapisującego. Po upływie czasu dłuższego niż „opóźnienie”, SELECTy z tej tabeli mogą ponownie zostać wysłane do węzłów odczytu. Należy pamiętać, że w przypadku klastra MariaDB czas wymagany do zastosowania zestawu zapisów we wszystkich węzłach jest zwykle bardzo krótki, liczony w milisekundach. To pozwoliłoby nam ustawić dość niskie opóźnienie w pliku konfiguracyjnym Moodle, na przykład wartość taka jak 0.1s (100 milisekund) powinna być całkiem w porządku. Oczywiście, jeśli napotkasz jakiekolwiek problemy, zawsze możesz zwiększyć tę wartość jeszcze bardziej.
Inną opcją do przetestowania byłoby poleganie wyłącznie na klastrze MariaDB, aby stwierdzić, kiedy odczyt jest bezpieczny, a kiedy nie. Istnieje zmienna wsrep_sync_wait, którą można skonfigurować tak, aby wymusić sprawdzanie przyczynowości w kilku wzorcach dostępu (odczyty, aktualizacje, wstawienia, usunięcia, zamiany i polecenia SHOW). Dla naszych celów wystarczyłoby upewnić się, że odczyty są wykonywane z wymuszoną przyczynowością, dlatego ustawimy tę zmienną na „1”.
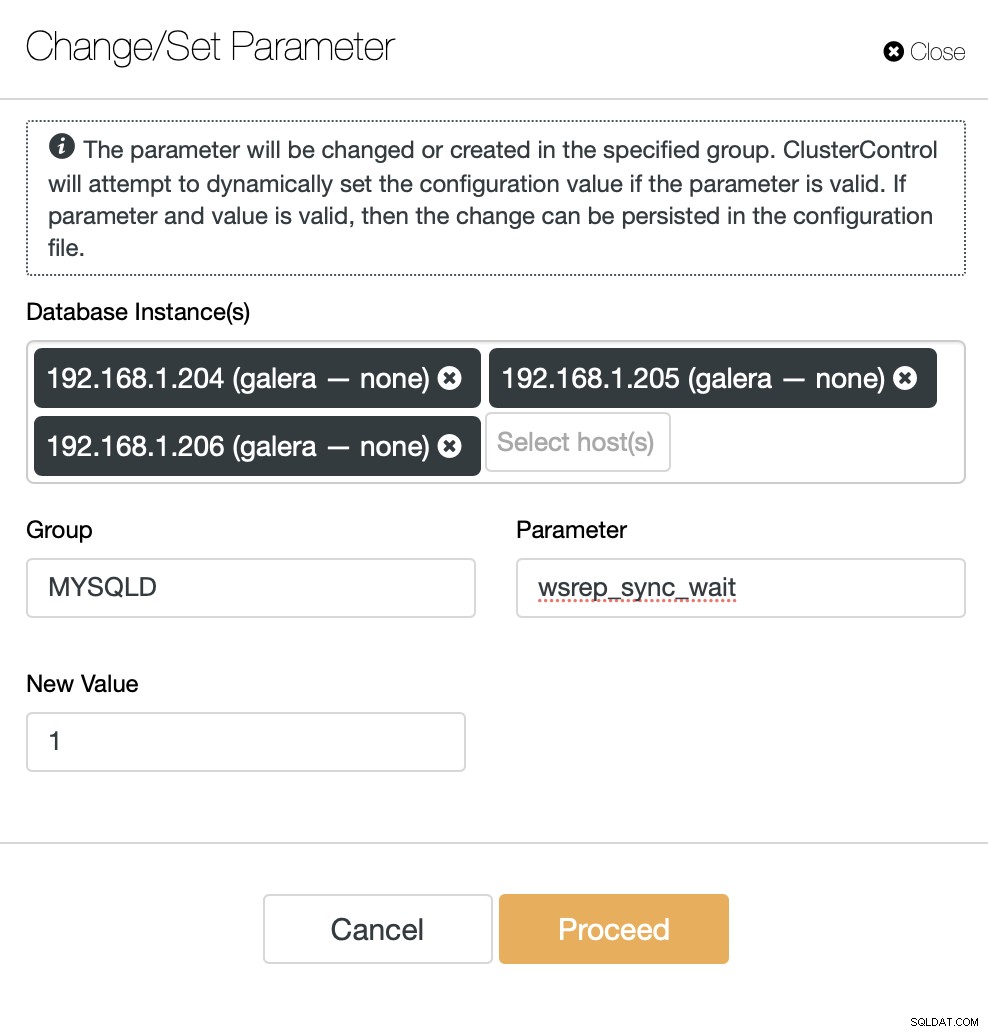
Zamierzamy wprowadzić tę zmianę we wszystkich węzłach klastra MariaDB. Będziemy także musieli przekonfigurować ProxySQL pod kątem podziału odczytu/zapisu na podstawie reguł zapytań, a nie tylko użytkowników, jak to robiliśmy wcześniej. Usuniemy również użytkownika „moodle_safereads”, ponieważ nie jest już potrzebny w tej konfiguracji.
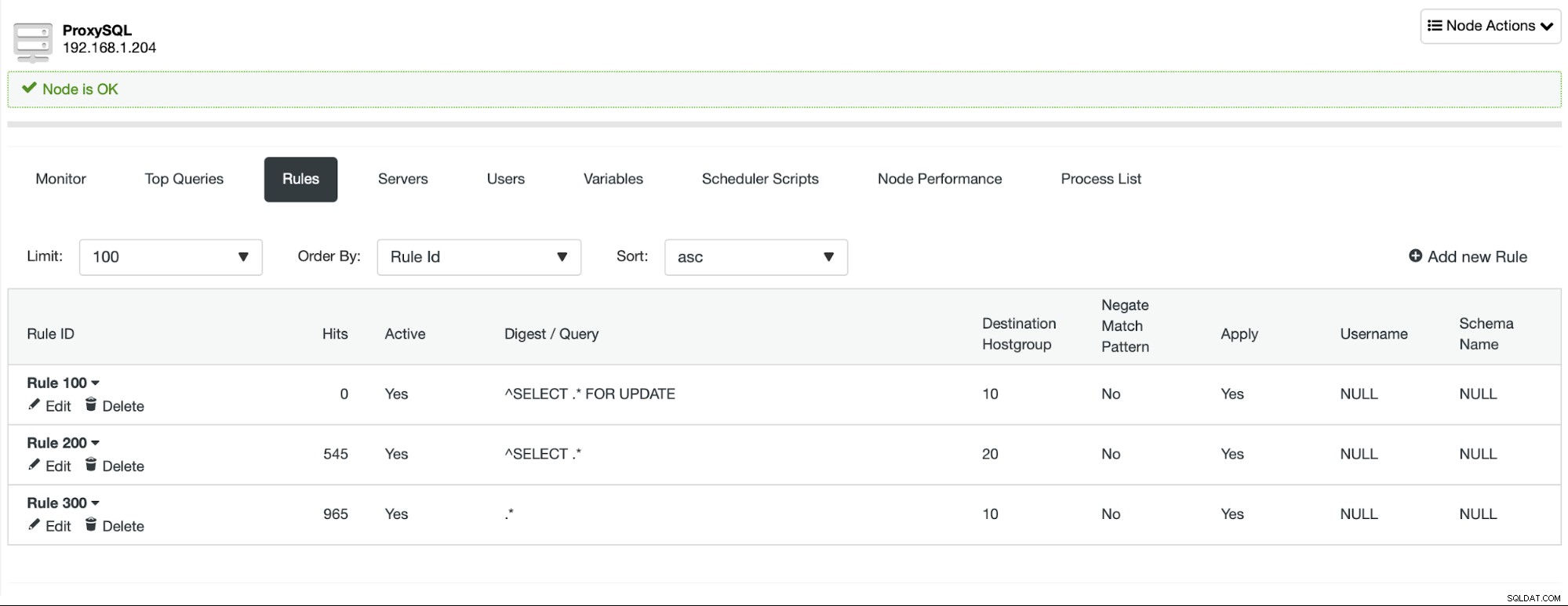
Konfigurujemy trzy reguły zapytań, które rozdzielają ruch na podstawie zapytania. SELECT … FOR UPDATE jest wysyłane do węzła zapisującego, wszystkie zapytania SELECT są wysyłane do czytelników, a wszystko inne (INSERT, DELETE, REPLACE, UPDATE, BEGIN, COMMIT itd.) jest również wysyłane do węzła zapisującego.
Dzięki temu możemy zapewnić, że wszystkie odczyty mogą być rozłożone na węzły czytnika, co umożliwia skalowanie w poziomie poprzez dodanie większej liczby węzłów do klastra MariaDB.
Mamy nadzieję, że dzięki tym kilku wskazówkom będziesz w stanie znacznie łatwiej i w większym stopniu skalować swój backend bazy danych Moodle



