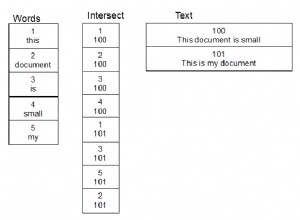
Tak jest w przypadku relational-division .
Rzeczywiste definicje tabel (standardowa relacja 1:n, ukryta przez Ruby ORM) będą wyglądać mniej więcej tak:
CREATE TABLE instructor_student (
id serial PRIMARY KEY
name ...
);
CREATE TABLE fees (
id serial PRIMARY KEY
, instructor_student_id integer NOT NULL REFERENCES instructor_student
, course_type ...
, monthly_detail date
, UNIQUE (instructor_student_id, course_type, monthly_detail)
);
Twoja próba zapytania skutecznie próbuje przetestować każdy pojedynczy wiersz w fees w stosunku do wielu wartości w danej tablicy, co zawsze kończy się niepowodzeniem, gdy elementy tablicy nie są identyczne. Jeden wartość nie może być taka sama jak wiele inne wartości. Potrzebujesz innego podejścia:
SELECT instructor_student_id
FROM fees
WHERE course_type = ?
AND monthly_detail = ANY(ARRAY[?]::date[]) -- ANY, not ALL!
GROUP BY instructor_student_id
HAVING count(*) = cardinality(ARRAY[?]::date[]);
Przyjmujemy, że różne wartości w Twojej tablicy i unikalne wpisy w opłatach za tabele, takie jak wymuszone przez UNIQUE ograniczenie, które dodałem powyżej. W przeciwnym razie liczenia nie są wiarygodne i musisz użyć bardziej wyrafinowanego zapytania. Oto arsenał opcji:
Jak widać, nie włączyłem tabeli instructor_student w ogóle. Podczas gdy integralność referencyjna jest wymuszana za pomocą ograniczenia FK (jak zwykle), możemy pracować z fees samodzielnie, aby określić kwalifikujący się instructor_student_id . Jeśli chcesz pobrać więcej atrybutów z głównej tabeli, zrób to w drugim kroku, na przykład:
SELECT i.* -- or whatever you need
FROM instructor_student i
JOIN (
SELECT ... -- query from above
) f ON f.instructor_student_id = i.id
;