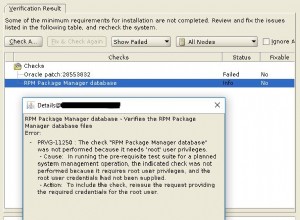
date jest słowem zarezerwowanym
w standardowym SQL i nazwę typu danych w PostgreSQL. PostgreSQL pozwala na to jako identyfikator, ale to nie jest dobry pomysł. Używam thedate zamiast nazwy kolumny.
Nie polegaj na braku luk w identyfikatorze zastępczym. To prawie zawsze zły pomysł. Traktuj taki identyfikator jako unikalny numer bez znaczenia , nawet jeśli wydaje się mieć pewne inne atrybuty przez większość czasu .
W tym konkretnym przypadku, jako @ Clodoaldo skomentował
, date wydaje się być idealnym kluczem podstawowym, a kolumna id to tylko cruft - który usunąłem:
CREATE TEMP TABLE tbl (thedate date PRIMARY KEY, rainfall numeric);
INSERT INTO tbl(thedate, rainfall) VALUES
('2002-05-06', 110.2)
, ('2002-05-07', 56.6)
, ('2002-05-09', 65.6)
, ('2002-05-10', 75.9);
Zapytanie
Pełna tabela według zapytania:
SELECT x.thedate, t.rainfall -- rainfall automatically NULL for missing rows
FROM (
SELECT generate_series(min(thedate), max(thedate), '1d')::date AS thedate
FROM tbl
) x
LEFT JOIN tbl t USING (thedate)
ORDER BY x.thedate
Podobne do tego, co @a_horse_with_no_name
wysłana, ale uproszczona i ignorująca przycięty id .
Wypełnia luki między pierwszą a ostatnią datą znalezioną w tabeli. Jeśli mogą występować luki wiodące/opóźnione, należy je odpowiednio wydłużyć. Możesz użyć date_trunc() jak @Clodoaldo
zademonstrowane - ale jego zapytanie zawiera błędy składniowe i może być prostsze.
WSTAW brakujące wiersze
Najszybszym i najbardziej czytelnym sposobem na to jest NOT EXISTS anty-semi-join.
INSERT INTO tbl (thedate, rainfall)
SELECT x.thedate, NULL
FROM (
SELECT generate_series(min(thedate), max(thedate), '1d')::date AS thedate
FROM tbl
) x
WHERE NOT EXISTS (SELECT 1 FROM tbl t WHERE t.thedate = x.thedate)