ProxySQL zwykle znajduje się pomiędzy warstwą aplikacji i bazy danych, w tak zwanej warstwie reverse-proxy. Gdy kontenery aplikacji są zaaranżowane i zarządzane przez Kubernetes, możesz chcieć użyć ProxySQL przed serwerami baz danych.
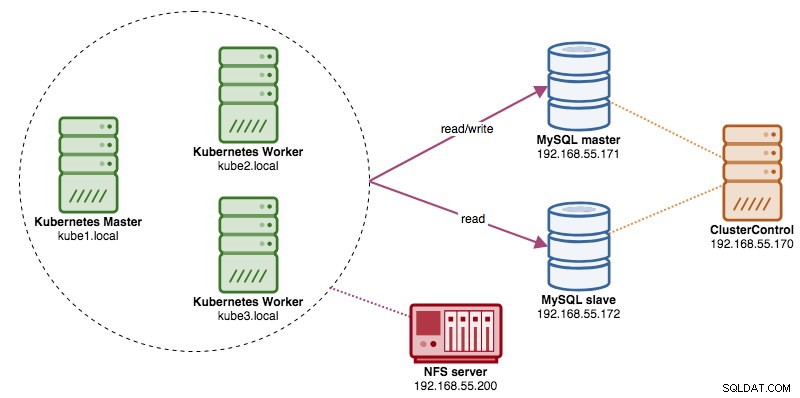
W tym poście pokażemy, jak uruchomić ProxySQL na Kubernetes jako kontener pomocniczy w pod. Jako przykładowej aplikacji użyjemy Wordpressa. Usługa danych jest świadczona przez naszą dwuwęzłową replikację MySQL, wdrożoną przy użyciu ClusterControl i znajdującą się poza siecią Kubernetes w infrastrukturze bare-metal, jak pokazano na poniższym diagramie:
Obraz dokera ProxySQL
W tym przykładzie użyjemy obrazu ProxySQL Docker obsługiwanego przez Manynines, ogólny obraz publiczny zbudowany do użytku wielozadaniowego. Obraz nie zawiera skryptu punktu wejścia i obsługuje Galera Cluster (oprócz wbudowanej obsługi replikacji MySQL), gdzie do celów kontroli stanu wymagany jest dodatkowy skrypt.
Zasadniczo, aby uruchomić kontener ProxySQL, po prostu wykonaj następujące polecenie:
$ docker run -d -v /path/to/proxysql.cnf:/etc/proxysql.cnf severalnines/proxysqlTen obraz zaleca powiązanie pliku konfiguracyjnego ProxySQL z punktem montowania, /etc/proxysql.cnf, aczkolwiek możesz to pominąć i skonfigurować później za pomocą konsoli administracyjnej ProxySQL. Przykładowe konfiguracje są dostępne na stronie Docker Hub lub Github.
ProxySQL na Kubernetes
Projektowanie architektury ProxySQL jest tematem subiektywnym i silnie uzależnionym od umiejscowienia kontenerów aplikacji i bazy danych oraz roli samego ProxySQL. ProxySQL nie tylko kieruje zapytania, ale może być również używany do przepisywania i buforowania zapytań. Wydajne trafienia w pamięci podręcznej mogą wymagać niestandardowej konfiguracji dostosowanej specjalnie do obciążenia bazy danych aplikacji.
W idealnej sytuacji możemy skonfigurować ProxySQL do zarządzania przez Kubernetes w dwóch konfiguracjach:
- ProxySQL jako usługa Kubernetes (scentralizowane wdrażanie).
- ProxySQL jako kontener pomocniczy w pod (rozproszone wdrożenie).
Pierwsza opcja jest dość prosta, gdzie tworzymy pod ProxySQL i dołączamy do niego usługę Kubernetes. Aplikacje będą wówczas łączyć się z usługą ProxySQL za pośrednictwem sieci na skonfigurowanych portach. Domyślna wartość to 6033 dla portu równoważenia obciążenia MySQL i 6032 dla portu administracyjnego ProxySQL. To wdrożenie zostanie omówione w nadchodzącym poście na blogu.
Druga opcja jest nieco inna. Kubernetes ma koncepcję o nazwie „pod”. Możesz mieć jeden lub więcej pojemników na zasobnik, są one stosunkowo ściśle powiązane. Zawartość kapsuły jest zawsze zlokalizowana i współzaplanowana oraz uruchamiana we wspólnym kontekście. Pod to najmniejsza zarządzalna jednostka kontenerowa w Kubernetes.
Oba wdrożenia można łatwo odróżnić, patrząc na następujący diagram:
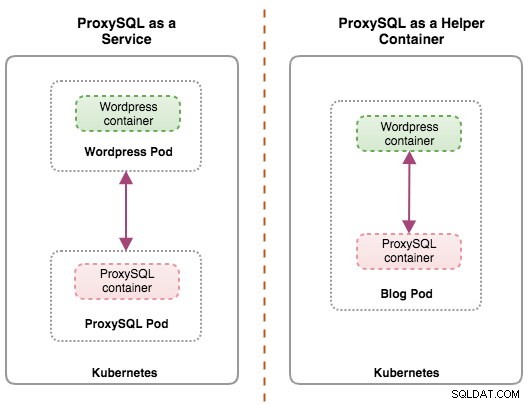
Głównym powodem, dla którego zasobniki mogą mieć wiele kontenerów, jest obsługa aplikacji pomocniczych, które wspomagają aplikację podstawową. Typowymi przykładami aplikacji pomocniczych są ściągacze danych, wypychacze danych i serwery proxy. Aplikacje pomocnicze i podstawowe często muszą się ze sobą komunikować. Zazwyczaj odbywa się to poprzez współdzielony system plików, jak pokazano w tym ćwiczeniu, lub przez interfejs sieciowy pętli zwrotnej, localhost. Przykładem tego wzorca jest serwer WWW wraz z programem pomocniczym, który odpytuje repozytorium Git o nowe aktualizacje.
Ten wpis na blogu obejmie drugą konfigurację — uruchamianie ProxySQL jako kontenera pomocniczego w pode.
ProxySQL jako pomocnik w pode
W tej konfiguracji uruchamiamy ProxySQL jako kontener pomocniczy do naszego kontenera Wordpress. Poniższy diagram ilustruje naszą architekturę wysokiego poziomu:
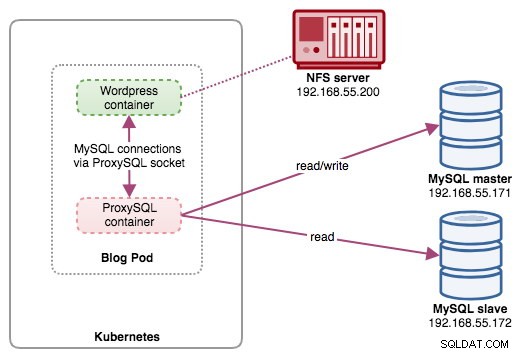
W tej konfiguracji kontener ProxySQL jest ściśle powiązany z kontenerem Wordpress i nazwaliśmy go pod „blog”. Jeśli nastąpi zmiana harmonogramu, np. węzeł roboczy Kubernetes ulegnie awarii, te dwa kontenery zawsze zostaną ponownie zaplanowane razem jako jedna jednostka logiczna na następnym dostępnym hoście. Aby zawartość kontenerów aplikacji była trwała w wielu węzłach, musimy użyć klastrowego lub zdalnego systemu plików, którym w tym przypadku jest NFS.
Rolą ProxySQL jest zapewnienie warstwy abstrakcji bazy danych do kontenera aplikacji. Ponieważ używamy dwuwęzłowej replikacji MySQL jako usługi bazy danych zaplecza, dzielenie odczytu i zapisu jest niezbędne, aby zmaksymalizować zużycie zasobów na obu serwerach MySQL. ProxySQL przoduje w tym i wymaga minimalnych lub żadnych zmian w aplikacji.
Istnieje wiele innych korzyści z używania ProxySQL w tej konfiguracji:
- Przynieś możliwości buforowania zapytań najbliżej warstwy aplikacji działającej w Kubernetes.
- Bezpieczna implementacja dzięki połączeniu przez plik gniazda ProxySQL UNIX. Jest jak potok, którego serwer i klienci mogą używać do łączenia się i wymiany żądań i danych.
- Rozproszona warstwa zwrotnego proxy z architekturą niczego współdzielonego.
- Mniejsze obciążenie sieci dzięki implementacji „pomijania sieci”.
- Podejście do wdrażania bezstanowego z wykorzystaniem Kubernetes ConfigMaps.
Przygotowywanie bazy danych
Utwórz bazę danych wordpress i użytkownika na urządzeniu głównym i przypisz z odpowiednimi uprawnieniami:
mysql-master> CREATE DATABASE wordpress;
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'passw0rd';
mysql-master> GRANT ALL PRIVILEGES ON wordpress.* TO example@sqldat.com'%';Utwórz także użytkownika monitorującego ProxySQL:
mysql-master> CREATE USER example@sqldat.com'%' IDENTIFIED BY 'proxysqlpassw0rd';Następnie ponownie załaduj tabelę grantów:
mysql-master> FLUSH PRIVILEGES;Przygotowywanie poda
Teraz skopiuj i wklej następujące wiersze do pliku o nazwie blog-deployment.yml na hoście, na którym skonfigurowano kubectl:
apiVersion: apps/v1
kind: Deployment
metadata:
name: blog
labels:
app: blog
spec:
replicas: 1
selector:
matchLabels:
app: blog
tier: frontend
strategy:
type: RollingUpdate
template:
metadata:
labels:
app: blog
tier: frontend
spec:
restartPolicy: Always
containers:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmp
- image: severalnines/proxysql
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Plik YAML ma wiele wierszy i przyjrzyjmy się tylko interesującej części. Pierwsza sekcja:
apiVersion: apps/v1
kind: DeploymentPierwsza linia to apiVersion. Nasz klaster Kubernetes działa w wersji 1.12, więc powinniśmy zapoznać się z dokumentacją interfejsu API Kubernetes w wersji 1.12 i postępować zgodnie z deklaracją zasobów zgodnie z tym interfejsem API. Kolejny to rodzaj, który mówi, jaki rodzaj zasobu chcemy wdrożyć. Deployment, Service, ReplicaSet, DaemonSet, PersistentVolume to tylko niektóre z przykładów.
Kolejną ważną sekcją jest sekcja „kontenery”. Tutaj definiujemy wszystkie kontenery, które chcielibyśmy uruchomić razem w tym pod. Pierwsza część to kontener Wordpress:
- image: wordpress:4.9-apache
name: wordpress
env:
- name: WORDPRESS_DB_HOST
value: localhost:/tmp/proxysql.sock
- name: WORDPRESS_DB_USER
value: wordpress
- name: WORDPRESS_DB_PASSWORD
valueFrom:
secretKeyRef:
name: mysql-pass
key: password
ports:
- containerPort: 80
name: wordpress
volumeMounts:
- name: wordpress-persistent-storage
mountPath: /var/www/html
- name: shared-data
mountPath: /tmpW tej sekcji mówimy Kubernetes, aby wdrożył Wordpress 4.9 przy użyciu serwera WWW Apache, a kontenerowi nadaliśmy nazwę "wordpress". Chcemy również, aby Kubernetes przekazywał szereg zmiennych środowiskowych:
- WORDPRESS_DB_HOST - Host bazy danych. Ponieważ nasz kontener ProxySQL znajduje się w tym samym Pod z kontenerem Wordpress, bezpieczniej jest użyć zamiast tego pliku gniazda ProxySQL. Format do użycia pliku typu socket w Wordpress to „localhost:{ścieżka do pliku typu socket}”. Domyślnie znajduje się w katalogu /tmp kontenera ProxySQL. Ta ścieżka /tmp jest współużytkowana przez kontenery Wordpress i ProxySQL przy użyciu „shared-data” volumeMounts, jak pokazano poniżej. Oba kontenery muszą zamontować ten wolumin, aby udostępniać tę samą zawartość w katalogu /tmp.
- WORDPRESS_DB_USER - Określ użytkownika bazy danych wordpress.
- WORDPRESS_DB_PASSWORD - Hasło dla WORDPRESS_DB_USER . Ponieważ nie chcemy ujawniać hasła w tym pliku, możemy je ukryć za pomocą Kubernetes Secrets. Tutaj instruujemy Kubernetes, aby zamiast tego przeczytał zasób tajny "mysql-pass". Sekrety muszą zostać utworzone na zaawansowanym etapie przed wdrożeniem pod, jak wyjaśniono poniżej.
Chcemy również opublikować port 80 kontenera dla użytkownika końcowego. Zawartość Wordpress przechowywana w /var/www/html w kontenerze zostanie zamontowana w naszej trwałej pamięci masowej działającej na NFS.
Następnie definiujemy kontener ProxySQL:
- image: severalnines/proxysql:1.4.12
name: proxysql
volumeMounts:
- name: proxysql-config
mountPath: /etc/proxysql.cnf
subPath: proxysql.cnf
- name: shared-data
mountPath: /tmp
ports:
- containerPort: 6033
name: proxysqlW powyższej sekcji mówimy Kubernetes, aby wdrożył ProxySQL przy użyciu severalnines/proxysql wersja obrazu 1.4.12. Chcemy również, aby Kubernetes zamontował nasz niestandardowy, wstępnie skonfigurowany plik konfiguracyjny i zmapował go do /etc/proxysql.cnf wewnątrz kontenera. Powstanie wolumin o nazwie „shared-data”, który będzie mapowany do katalogu /tmp w celu współdzielenia z obrazem Wordpress — katalog tymczasowy, który dzieli czas życia poda. Pozwala to na użycie pliku gniazda ProxySQL (/tmp/proxysql.sock) przez kontener Wordpress podczas łączenia się z bazą danych, z pominięciem sieci TCP/IP.
Ostatnia część to sekcja „tomy”:
Woluminy volumes:
- name: wordpress-persistent-storage
persistentVolumeClaim:
claimName: wp-pv-claim
- name: proxysql-config
configMap:
name: proxysql-configmap
- name: shared-data
emptyDir: {}Kubernetes będzie musiał utworzyć trzy woluminy dla tego poda:
- wordpress-persistent-storage – użyj PersistentVolumeClaim zasób do mapowania eksportu NFS do kontenera w celu trwałego przechowywania danych dla treści Wordpress.
- proxysql-config — użyj ConfigMap zasób do mapowania pliku konfiguracyjnego ProxySQL.
- shared-data – użyj emptyDir zasób do zamontowania współdzielonego katalogu dla naszych kontenerów wewnątrz Poda. pusty katalog zasób jest katalogiem tymczasowym, który dzieli czas życia poda.
Dlatego, w oparciu o naszą definicję YAML powyżej, musimy przygotować szereg zasobów Kubernetes, zanim będziemy mogli rozpocząć wdrażanie pod „blog”:
- Stała głośność i PersistentVolumeClaim - Aby przechowywać zawartość sieciową naszej aplikacji Wordpress, więc gdy pod zostanie przeniesiony do innego węzła roboczego, nie stracimy ostatnich zmian.
- Sekrety - Aby ukryć hasło użytkownika bazy danych Wordpress w pliku YAML.
- Mapa konfiguracji - Aby zmapować plik konfiguracyjny do kontenera ProxySQL, więc kiedy jest przesunięty do innego węzła, Kubernetes może automatycznie ponownie go zamontować.
PersistentVolume i PersistentVolumeClaim
Dobry magazyn trwały dla Kubernetes powinien być dostępny dla wszystkich węzłów Kubernetes w klastrze. Na potrzeby tego wpisu na blogu użyliśmy NFS jako dostawcy PersistentVolume (PV), ponieważ jest łatwy i obsługiwany od razu po zainstalowaniu. Serwer NFS znajduje się gdzieś poza naszą siecią Kubernetes i skonfigurowaliśmy go tak, aby zezwalał na wszystkie węzły Kubernetes z następującym wierszem w /etc/exports:
/nfs 192.168.55.*(rw,sync,no_root_squash,no_all_squash)Zwróć uwagę, że pakiet klienta NFS musi być zainstalowany na wszystkich węzłach Kubernetes. W przeciwnym razie Kubernetes nie byłby w stanie poprawnie zamontować NFS. Na wszystkich węzłach:
$ sudo apt-install nfs-common #Ubuntu/Debian
$ yum install nfs-utils #RHEL/CentOSUpewnij się również, że na serwerze NFS istnieje katalog docelowy:
(nfs-server)$ mkdir /nfs/kubernetes/wordpressNastępnie utwórz plik o nazwie wordpress-pv-pvc.yml i dodaj następujące wiersze:
apiVersion: v1
kind: PersistentVolume
metadata:
name: wp-pv
labels:
app: blog
spec:
accessModes:
- ReadWriteOnce
capacity:
storage: 3Gi
mountOptions:
- hard
- nfsvers=4.1
nfs:
path: /nfs/kubernetes/wordpress
server: 192.168.55.200
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: wp-pvc
spec:
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 3Gi
selector:
matchLabels:
app: blog
tier: frontendW powyższej definicji chcielibyśmy, aby Kubernetes przydzielił 3 GB przestrzeni woluminu na serwerze NFS dla naszego kontenera Wordpress. Zwróć uwagę na użycie produkcyjne, NFS powinien być skonfigurowany z automatycznym udostępnianiem i klasą pamięci.
Utwórz zasoby PV i PVC:
$ kubectl create -f wordpress-pv-pvc.ymlSprawdź, czy te zasoby zostały utworzone i czy musi mieć status „Związany”:
$ kubectl get pv,pvc
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
persistentvolume/wp-pv 3Gi RWO Recycle Bound default/wp-pvc 22h
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
persistentvolumeclaim/wp-pvc Bound wp-pv 3Gi RWO 22hSekrety
Pierwszym z nich jest utworzenie sekretu używanego przez kontener Wordpress dla WORDPRESS_DB_PASSWORD Zmienna środowiskowa. Powodem jest to, że nie chcemy ujawniać hasła w postaci zwykłego tekstu w pliku YAML.
Utwórz tajny zasób o nazwie mysql-pass i odpowiednio przekaż hasło:
$ kubectl create secret generic mysql-pass --from-literal=password=passw0rdSprawdź, czy nasz sekret został utworzony:
$ kubectl get secrets mysql-pass
NAME TYPE DATA AGE
mysql-pass Opaque 1 7h12mMapa konfiguracji
Musimy również utworzyć zasób ConfigMap dla naszego kontenera ProxySQL. Plik Kubernetes ConfigMap zawiera pary klucz-wartość danych konfiguracyjnych, które mogą być używane w zasobnikach lub używane do przechowywania danych konfiguracyjnych. ConfigMaps umożliwia oddzielenie artefaktów konfiguracji od zawartości obrazu, aby zapewnić przenośność aplikacji kontenerowych.
Ponieważ nasz serwer bazy danych działa już na serwerach bare-metal ze statyczną nazwą hosta i adresem IP oraz statyczną nazwą użytkownika i hasłem monitorowania, w tym przypadku plik ConfigMap będzie przechowywać wstępnie skonfigurowane informacje o konfiguracji usługi ProxySQL, której chcemy użyć.
Najpierw utwórz plik tekstowy o nazwie proxysql.cnf i dodaj następujące wiersze:
datadir="/var/lib/proxysql"
admin_variables=
{
admin_credentials="admin:adminpassw0rd"
mysql_ifaces="0.0.0.0:6032"
refresh_interval=2000
}
mysql_variables=
{
threads=4
max_connections=2048
default_query_delay=0
default_query_timeout=36000000
have_compress=true
poll_timeout=2000
interfaces="0.0.0.0:6033;/tmp/proxysql.sock"
default_schema="information_schema"
stacksize=1048576
server_version="5.1.30"
connect_timeout_server=10000
monitor_history=60000
monitor_connect_interval=200000
monitor_ping_interval=200000
ping_interval_server_msec=10000
ping_timeout_server=200
commands_stats=true
sessions_sort=true
monitor_username="proxysql"
monitor_password="proxysqlpassw0rd"
}
mysql_servers =
(
{ address="192.168.55.171" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=10, max_connections=100 },
{ address="192.168.55.171" , port=3306 , hostgroup=20, max_connections=100 },
{ address="192.168.55.172" , port=3306 , hostgroup=20, max_connections=100 }
)
mysql_users =
(
{ username = "wordpress" , password = "passw0rd" , default_hostgroup = 10 , active = 1 }
)
mysql_query_rules =
(
{
rule_id=100
active=1
match_pattern="^SELECT .* FOR UPDATE"
destination_hostgroup=10
apply=1
},
{
rule_id=200
active=1
match_pattern="^SELECT .*"
destination_hostgroup=20
apply=1
},
{
rule_id=300
active=1
match_pattern=".*"
destination_hostgroup=10
apply=1
}
)
mysql_replication_hostgroups =
(
{ writer_hostgroup=10, reader_hostgroup=20, comment="MySQL Replication 5.7" }
)Zwróć szczególną uwagę na sekcje „mysql_servers” i „mysql_users”, w których może być konieczne zmodyfikowanie wartości, aby dopasować je do konfiguracji klastra bazy danych. W tym przypadku mamy dwa serwery baz danych działające w replikacji MySQL, jak podsumowano na poniższym zrzucie ekranu topologii zaczerpniętym z ClusterControl:
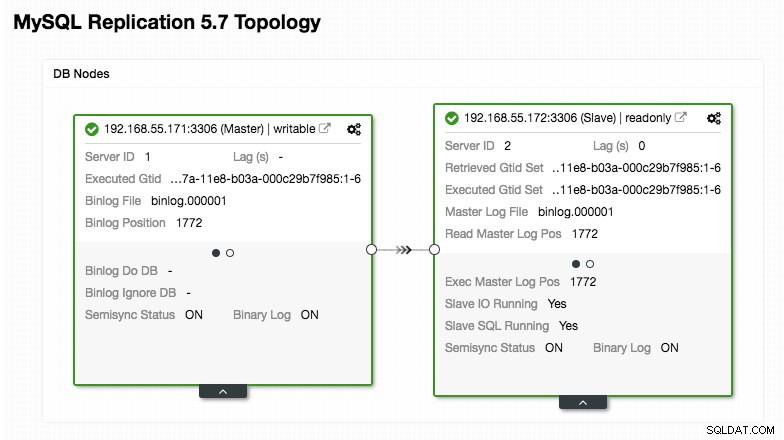
Wszystkie zapisy powinny iść do węzła głównego, podczas gdy odczyty są przekazywane do grupy hostów 20, zgodnie z definicją w sekcji „mysql_query_rules”. To podstawa dzielenia odczytu/zapisu i chcemy je całkowicie wykorzystać.
Następnie zaimportuj plik konfiguracyjny do ConfigMap:
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnf
configmap/proxysql-configmap createdSprawdź, czy ConfigMap jest załadowany do Kubernetes:
$ kubectl get configmap
NAME DATA AGE
proxysql-configmap 1 45sWdrażanie poda
Teraz powinniśmy być w porządku, aby wdrożyć blog pod. Wyślij zadanie wdrożenia do Kubernetes:
$ kubectl create -f blog-deployment.ymlSprawdź stan poda:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-t4cb7 2/2 Running 0 100sMusi wskazywać 2/2 pod kolumną GOTOWE, co oznacza, że wewnątrz kapsuły znajdują się dwa pojemniki. Użyj flagi opcji -c, aby sprawdzić kontenery Wordpress i ProxySQL w blogu:
$ kubectl logs blog-54755cbcb5-t4cb7 -c wordpress
$ kubectl logs blog-54755cbcb5-t4cb7 -c proxysqlW dzienniku kontenera ProxySQL powinny pojawić się następujące wiersze:
2018-10-20 08:57:14 [INFO] Dumping current MySQL Servers structures for hostgroup ALL
HID: 10 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 10 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: OFFLINE_HARD , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.171 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:
HID: 20 , address: 192.168.55.172 , port: 3306 , weight: 1 , status: ONLINE , max_connections: 100 , max_replication_lag: 0 , use_ssl: 0 , max_latency_ms: 0 , comment:HID 10 (zapisująca grupa hostów) musi mieć tylko jeden węzeł ONLINE (wskazujący jednego mastera), a drugi host musi mieć co najmniej status OFFLINE_HARD. W przypadku HID 20 oczekuje się, że będzie ONLINE dla wszystkich węzłów (wskazując wiele replik do odczytu).
Aby uzyskać podsumowanie wdrożenia, użyj flagi opisu:
$ kubectl describe deployments blogNasz blog jest już uruchomiony, jednak nie możemy uzyskać do niego dostępu spoza sieci Kubernetes bez skonfigurowania usługi, jak wyjaśniono w następnej sekcji.
Tworzenie serwisu blogów
Ostatnim krokiem jest stworzenie usługi attach na naszym pod. Ma to na celu zapewnienie, że nasz blog WordPress jest dostępny ze świata zewnętrznego. Utwórz plik o nazwie blog-svc.yml i wklej następujący wiersz:
apiVersion: v1
kind: Service
metadata:
name: blog
labels:
app: blog
tier: frontend
spec:
type: NodePort
ports:
- name: blog
nodePort: 30080
port: 80
selector:
app: blog
tier: frontendUtwórz usługę:
$ kubectl create -f blog-svc.ymlSprawdź, czy usługa została utworzona poprawnie:
example@sqldat.com:~/proxysql-blog# kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
blog NodePort 10.96.140.37 <none> 80:30080/TCP 26s
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 43hPort 80 opublikowany przez blog pod jest teraz mapowany na świat zewnętrzny przez port 30080. Możemy uzyskać dostęp do naszego wpisu na blogu pod adresem https://{any_kubernetes_host}:30080/ i powinien zostać przekierowany na stronę instalacji Wordpress. Jeśli będziemy kontynuować instalację, pominiemy część dotyczącą połączenia z bazą danych i wyświetlimy bezpośrednio tę stronę:
Oznacza to, że nasza konfiguracja MySQL i ProxySQL jest poprawnie skonfigurowana w pliku wp-config.php. W przeciwnym razie zostaniesz przekierowany na stronę konfiguracji bazy danych.
Nasze wdrożenie zostało zakończone.
Zarządzanie kontenerem ProxySQL wewnątrz poda
Oczekuje się, że przełączanie awaryjne i odzyskiwanie będą obsługiwane automatycznie przez Kubernetes. Na przykład, jeśli proces roboczy Kubernetes przestanie działać, pod zostanie odtworzony w następnym dostępnym węźle po --pod-eviction-timeout (domyślnie 5 minut). Jeśli kontener ulegnie awarii lub zostanie zabity, Kubernetes zastąpi go niemal natychmiast.
Oczekuje się, że niektóre typowe zadania zarządzania będą inne podczas uruchamiania w Kubernetes, jak pokazano w następnych sekcjach.
Skalowanie w górę i w dół
W powyższej konfiguracji wdrażaliśmy jedną replikę w naszym wdrożeniu. Aby zwiększyć skalę, po prostu zmień spec.replicas wartość odpowiednio za pomocą polecenia edycji kubectl:
$ kubectl edit deployment blogOtworzy definicję wdrożenia w domyślnym pliku tekstowym i po prostu zmieni spec.replicas wartość na coś wyższego, na przykład „repliki:3”. Następnie zapisz plik i natychmiast sprawdź stan wdrożenia, używając następującego polecenia:
$ kubectl rollout status deployment blog
Waiting for deployment "blog" rollout to finish: 1 of 3 updated replicas are available...
Waiting for deployment "blog" rollout to finish: 2 of 3 updated replicas are available...
deployment "blog" successfully rolled outW tym momencie mamy trzy blogi (Wordpress + ProxySQL) działające jednocześnie w Kubernetes:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 11m
blog-54755cbcb5-cwpdj 2/2 Running 0 11m
blog-54755cbcb5-jxtvc 2/2 Running 0 22mW tym momencie nasza architektura wygląda mniej więcej tak:
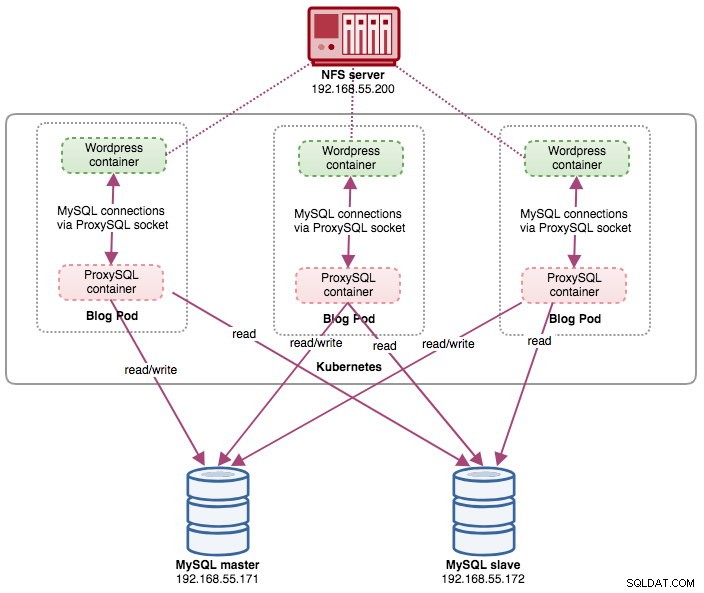
Należy pamiętać, że płynne uruchamianie Wordpressa w środowisku produkcyjnym o skali poziomej może wymagać większego dostosowania niż nasza obecna konfiguracja (pomyśl o zawartości statycznej, zarządzaniu sesjami i innych). W rzeczywistości wykraczają one poza zakres tego wpisu na blogu.
Procedury zmniejszania skali są podobne.
Zarządzanie konfiguracją
Zarządzanie konfiguracją jest ważne w ProxySQL. To tutaj dzieje się magia, gdy możesz zdefiniować własny zestaw reguł zapytań, aby wykonać buforowanie zapytań, zapory ogniowe i przepisywanie. W przeciwieństwie do powszechnej praktyki, w której ProxySQL byłby konfigurowany za pomocą konsoli administracyjnej i wprowadzany w stan utrwalenia za pomocą „ZAPISZ .. NA DYSKU”, pozostaniemy przy plikach konfiguracyjnych tylko po to, aby rzeczy były bardziej przenośne w Kubernetes. To jest powód, dla którego używamy ConfigMaps.
Ponieważ polegamy na naszej scentralizowanej konfiguracji przechowywanej przez Kubernetes ConfigMaps, istnieje wiele sposobów wprowadzania zmian w konfiguracji. Po pierwsze, za pomocą polecenia edycji kubectl:
$ kubectl edit configmap proxysql-configmapOtworzy się konfiguracja w domyślnym edytorze tekstu i możesz bezpośrednio wprowadzić w niej zmiany i zapisać plik tekstowy po zakończeniu. W przeciwnym razie ponowne utworzenie map konfiguracji również powinno wystarczyć:
$ vi proxysql.cnf # edit the configuration first
$ kubectl delete configmap proxysql-configmap
$ kubectl create configmap proxysql-configmap --from-file=proxysql.cnfPo wypchnięciu konfiguracji do programu ConfigMap uruchom ponownie pod lub kontener, jak pokazano w sekcji Kontrola usług. Konfiguracja kontenera przez interfejs administratora ProxySQL (port 6032) nie sprawi, że będzie on trwały po zmianie harmonogramu pod przez Kubernetes.
Kontrola usług
Ponieważ dwa kontenery wewnątrz zasobnika są ściśle powiązane, najlepszym sposobem zastosowania zmian w konfiguracji ProxySQL jest wymuszenie na Kubernetes zastąpienia zasobnika. Weź pod uwagę, że po zwiększeniu skali mamy teraz trzy blogi:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-jxtvc 2/2 Running 1 22mUżyj następującego polecenia, aby zastąpić jeden pod na raz:
$ kubectl get pod blog-54755cbcb5-6fnqn -n default -o yaml | kubectl replace --force -f -
pod "blog-54755cbcb5-6fnqn" deleted
pod/blog-54755cbcb5-6fnqnNastępnie zweryfikuj w następujący sposób:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
blog-54755cbcb5-6fnqn 2/2 Running 0 31m
blog-54755cbcb5-cwpdj 2/2 Running 0 31m
blog-54755cbcb5-qs6jm 2/2 Running 1 2m26sZauważysz, że ostatnia kapsuła została zrestartowana, patrząc na kolumnę AGE i RESTART, pojawiła się inna nazwa kapsuły. Powtórz te same kroki dla pozostałych strąków. W przeciwnym razie możesz również użyć polecenia „docker kill”, aby ręcznie zabić kontener ProxySQL w węźle roboczym Kubernetes. Na przykład:
(kube-worker)$ docker kill $(docker ps | grep -i proxysql_blog | awk {'print $1'})Kubernetes zastąpi zabity kontener ProxySQL nowym.
Monitorowanie
Użyj polecenia kubectl exec, aby wykonać instrukcję SQL za pośrednictwem klienta mysql. Na przykład, aby monitorować skracanie zapytań:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032
mysql> SELECT * FROM stats_mysql_query_digest;Lub z jednym linijką:
$ kubectl exec -it blog-54755cbcb5-29hqt -c proxysql -- mysql -uadmin -p -h127.0.0.1 -P6032 -e 'SELECT * FROM stats_mysql_query_digest'Zmieniając instrukcję SQL, możesz monitorować inne składniki ProxySQL lub wykonywać dowolne zadania administracyjne za pośrednictwem tej konsoli administracyjnej. Ponownie, będzie on utrzymywał się tylko podczas życia kontenera ProxySQL i nie zostanie utrwalony, jeśli pod zostanie przełożony.
Ostateczne myśli
ProxySQL odgrywa kluczową rolę, jeśli chcesz skalować kontenery aplikacji i mieć inteligentny sposób na dostęp do rozproszonego zaplecza bazy danych. Istnieje wiele sposobów wdrożenia ProxySQL na Kubernetes w celu wsparcia rozwoju naszej aplikacji działającej na dużą skalę. Ten post na blogu dotyczy tylko jednego z nich.
W nadchodzącym poście na blogu przyjrzymy się, jak uruchomić ProxySQL w scentralizowanym podejściu, używając go jako usługi Kubernetes.