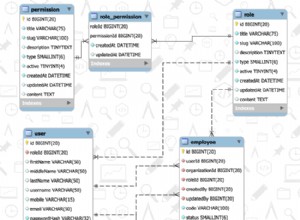
Jeśli Twój projekt wymusza integralność referencyjną, nie musisz dołączać do tabeli residences w ogóle w tym celu. Również przy założeniu UNIQUE lub PK ograniczenie na (residence_id, amenity_id) (inaczej potrzebujesz różnych zapytań!)
Najlepsze zapytanie zależy od tego, czego potrzebujesz dokładnie .
Korzystając z funkcji okna, możesz zrób to nawet na poziomie pojedynczego zapytania:
SELECT count(*) OVER () AS ct
FROM listed_amenities
WHERE amenity_id IN (48, 49, 50)
GROUP BY residence_id
HAVING count(*) = 3
LIMIT 1;
Ta funkcja okna dołącza całkowitą liczbę do każdego wiersza bez agregowania wierszy. Rozważ sekwencję zdarzeń w SELECT zapytanie:
W związku z tym możesz użyć podobnego zapytania, aby zwrócić wszystkie kwalifikujące się identyfikatory (lub nawet całe wiersze) i dodać liczbę do każdego wiersza (nadmiarowo):
SELECT residence_id, count(*) OVER () AS ct
FROM listed_amenities
WHERE amenity_id IN (48, 49, 50)
GROUP BY residence_id
HAVING count(*) = 3;
Ale lepiej użyj podzapytania, które jest zazwyczaj znacznie tańsze :
SELECT count(*) AS ct
FROM (
SELECT 1
FROM listed_amenities
WHERE amenity_id IN (48, 49, 50)
GROUP BY residence_id
HAVING count(*) = 3
) sub;
możesz zwrócić tablicę identyfikatorów (w przeciwieństwie do zestawu powyżej) w tym samym czasie, za niewiele więcej kosztów:
SELECT array_agg(residence_id ) AS ids, count(*) AS ct
FROM (
SELECT residence_id
FROM listed_amenities
WHERE amenity_id IN (48, 49, 50)
GROUP BY residence_id
HAVING count(*) = 3
) sub;
Istnieje wiele innych wariantów, należałoby doprecyzować oczekiwany wynik. Jak ten:
SELECT count(*) AS ct
FROM listed_amenities l1
JOIN listed_amenities l2 USING (residence_id)
JOIN listed_amenities l3 USING (residence_id)
WHERE l1.amenity_id = 48
AND l2.amenity_id = 49
AND l2.amenity_id = 50;
Zasadniczo jest to podział relacyjny. Zebraliśmy tutaj arsenał technik: