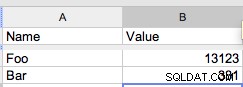
Cóż, możesz użyć wspólnego wyrażenia tabelowego aby uniknąć powielania kodu:
with cte_s as (
select id_movie, count(id_movie) as awards
from Award natural join awardwinner
where award_year = 2012
group by id_movie
)
select
sub.id_movie, sub.awards
from cte_s as sub
where sub.awards = (select max(sub2.awards) from cte_s as sub2)
lub możesz zrobić coś takiego za pomocą funkcji okna (nietestowane, ale myślę, że PostgreSQL na to pozwala):
with cte_s as (
select
id_movie,
count(id_movie) as awards,
max(count(id_movie)) over() as max_awards
from Award natural join awardwinner
where award_year = 2012
group by id_movie
)
select id_movie
from cte_s
where max_awards = awards
Innym sposobem na to może być użycie rank() funkcja (nieprzetestowana, być może będziesz musiał użyć dwóch cte zamiast jednego):
with cte_s as (
select
id_movie,
count(id_movie) as awards,
rank() over(order by count(id_movie) desc) as rnk
from Award natural join awardwinner
where award_year = 2012
group by id_movie
)
select id_movie
from cte_s
where rnk = 1
aktualizacja Kiedy stworzyłem tę odpowiedź, moim głównym celem było pokazanie, jak używać cte, aby uniknąć duplikacji kodu. Ogólnie rzecz biorąc, lepiej unikać używania cte więcej niż jeden raz w zapytaniu, jeśli jest to możliwe - pierwsze zapytanie wykorzystuje skanowanie 2 tabel (lub wyszukiwanie indeksu), a drugie i trzecie używa tylko jednego, więc powinienem określić, że lepiej jest iść z te zapytania. W każdym razie @Erwin wykonał te testy w swojej odpowiedzi. Wystarczy dodać do jego wielkich głównych punktów:
- Odradzam również
natural joinz powodu podatnej na błędy natury tego. Właściwie moim głównym RDBMS jest SQL Server, który go nie obsługuje, więc jestem bardziej przyzwyczajony do jawnegoouter/inner join. - Dobrym zwyczajem jest używanie aliasów w zapytaniach, aby uniknąć dziwne wyniki .
- Może to być rzecz całkowicie subiektywna, ale zwykle, jeśli używam jakiejś tabeli tylko do odfiltrowania wierszy z głównej tabeli zapytania (tak jak w tym zapytaniu, chcemy po prostu uzyskać
awardsdla roku 2012 i po prostu filtruj wiersze odawardwinner), wolę nie używaćjoin, ale użyjexistslubinzamiast tego wydaje mi się to bardziej logiczne.
with cte_s as (
select
aw.id_movie,
count(*) as awards,
rank() over(order by count(*) desc) as rnk
from awardwinner as aw
where
exists (
select *
from award as a
where a.id_award = aw.id_award and a.award_year = 2012
)
group by aw.id_movie
)
select id_movie
from cte_s
where rnk = 1