Jest to pierwszy artykuł z serii artykułów dotyczących OLTP w pamięci. Pomaga zrozumieć, jak nowy silnik Hekaton działa wewnętrznie. Skoncentrujemy się na szczegółach tabel i indeksów zoptymalizowanych w pamięci. To jest artykuł dla początkujących, co oznacza, że nie musisz być ekspertem SQL Server, jednak musisz mieć podstawową wiedzę na temat tradycyjnego silnika SQL Server.
Wprowadzenie
Silnik SQL Server 2014 In-Memory OLTP (projekt Hekaton) został stworzony od podstaw w celu wykorzystania terabajtów dostępnej pamięci i ogromnej liczby rdzeni przetwarzania. OLTP w pamięci umożliwia użytkownikom pracę z tabelami i indeksami zoptymalizowanymi pod kątem pamięci oraz natywnie skompilowanymi procedurami składowanymi. Można go używać wraz z tabelami i indeksami na dysku oraz procedurami składowanymi T-SQL, które SQL Server zawsze zapewniał.
Wewnętrzne i możliwości silnika OLTP w pamięci znacznie różnią się od standardowego silnika relacyjnego. Musisz zrewidować prawie wszystko, co wiedziałeś o obsłudze wielu współbieżnych procesów.
Aparat SQL Server jest zoptymalizowany pod kątem przechowywania na dysku. Wczytuje 8KB strony danych do pamięci w celu przetworzenia i zapisuje 8KB strony danych z powrotem na dysk po modyfikacji. Oczywiście SQL Server przede wszystkim naprawia zmiany na dysku w dzienniku transakcji. Odczytywanie stron danych o rozmiarze 8 KB z dysku i zapisywanie ich z powrotem może generować wiele operacji we/wy i prowadzić do wyższych kosztów opóźnień. Nawet gdy dane w buforze podręcznym, serwer SQL jest zaprojektowany tak, aby zakładać, że tak nie jest, co prowadzi do nieefektywnego wykorzystania procesora.
Biorąc pod uwagę ograniczenia tradycyjnych struktur pamięci dyskowych, zespół SQL Server rozpoczął budowę silnika bazy danych zoptymalizowanego pod kątem dużej pamięci głównej i wielordzeniowych procesorów. Zespół wyznaczył następujące cele:
- Zoptymalizowany pod kątem danych, które były całkowicie przechowywane w pamięci, ale były również trwałe po ponownym uruchomieniu SQL Server
- W pełni zintegrowany z istniejącym silnikiem SQL Server
- Bardzo wysoka wydajność dla operacji OLTP
- Zaprojektowany dla nowoczesnych procesorów
SQL Server In-Memory OLTP spełnia wszystkie te cele.
Informacje o OLTP w pamięci
SQL Server 2014 In-Memory OLTP udostępnia szereg technologii do pracy z tabelami zoptymalizowanymi pod kątem pamięci oraz tabelami dyskowymi. Na przykład umożliwia dostęp do danych w pamięci za pomocą standardowych interfejsów, takich jak T-SQL i SSMS. Na poniższej ilustracji przedstawiono tabele i indeksy zoptymalizowane pod kątem pamięci jako część protokołu OLTP w pamięci (po lewej) oraz tabel opartych na dyskach (po lewej), które wymagają odczytu i zapisu stron danych o wielkości 8 KB. OLTP w pamięci obsługuje również natywnie skompilowane procedury składowane i zapewnia nowy kompilator OLTP w pamięci.
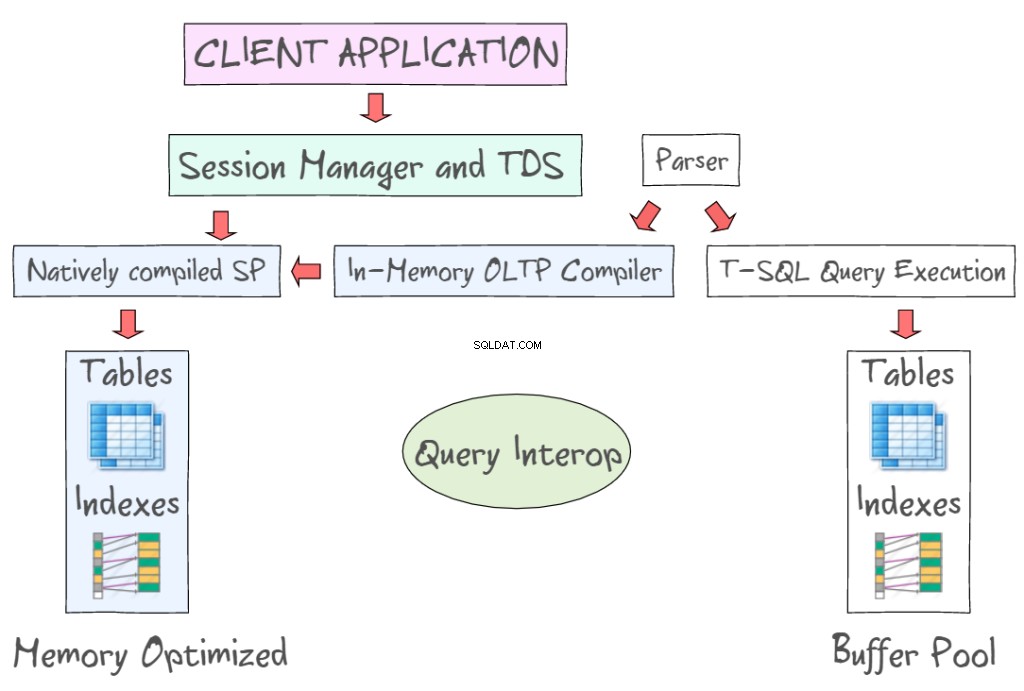
Query Interop umożliwia interpretację T-SQL w celu odwoływania się do tabel zoptymalizowanych pod kątem pamięci. Jeśli transakcja odwołuje się zarówno do tabel zoptymalizowanych pod względem pamięci, jak i opartych na dyskach, można ją nazwać transakcją międzykontenerową. Aplikacja kliencka wykorzystuje Tabular Data Stream – protokół warstwy aplikacji służący do przesyłania danych między serwerem bazy danych a klientem. Został pierwotnie zaprojektowany i opracowany przez Sybase Inc. dla ich relacyjnego silnika bazy danych Sybase SQL Server w 1984 roku, a później przez Microsoft w Microsoft SQL Server.
Tabele zoptymalizowane pod kątem pamięci
Podczas uzyskiwania dostępu do tabel dyskowych wymagane dane mogą już znajdować się w pamięci, chociaż może nie być. Jeśli danych nie ma w pamięci, SQL Server musi je odczytać z dysku. Najbardziej podstawową różnicą podczas korzystania z tabel zoptymalizowanych pod kątem pamięci jest to, że cała tabela i jej indeksy są przechowywane w pamięci przez cały czas . Jednoczesne operacje na danych nie wymagają blokowania ani zatrzaskiwania.
Podczas gdy użytkownik modyfikuje dane w pamięci, SQL Server wykonuje pewne operacje we/wy dysku dla dowolnej tabeli, która musi być trwała, inaczej mówiąc, gdy potrzebujemy tabeli do przechowywania danych w pamięci w momencie awarii lub ponownego uruchomienia serwera.
Struktura pamięci oparta na wierszach
Kolejną istotną różnicą jest podstawowa struktura pamięci. Tabele dyskowe są zoptymalizowane pod kątem adresowalności bloków miejsce na dysku, podczas gdy tabele zoptymalizowane w pamięci są zoptymalizowane pod kątem adresowalności bajtowej pamięć masowa.
SQL Server przechowuje wiersze danych na stronach danych o rozmiarze 8K, z alokacją miejsca z ekstentów dla tabel opartych na dyskach. Strona danych jest podstawową jednostką przechowywania dysku i pamięci. Podczas odczytu i zapisu danych z dysku SQL Server odczytuje i zapisuje tylko odpowiednie strony danych. Strona danych będzie zawierać tylko dane z jednej tabeli lub indeksu. Procesy aplikacji modyfikują wiersze na różnych stronach danych zgodnie z wymaganiami. Później, podczas operacji CHECKPOINT, SQL Server najpierw naprawia rekordy dziennika na dysku, a następnie zapisuje wszystkie nieczyste strony na dysku. Ta operacja często powoduje wiele losowych fizycznych operacji we/wy.
W przypadku tabel zoptymalizowanych pod kątem pamięci nie ma stron danych ani ekstentów. Istnieją tylko wiersze danych zapisywane w pamięci sekwencyjnie, w kolejności, w jakiej wystąpiły transakcje. Każdy wiersz zawiera wskaźnik indeksu do następnego wiersza. Wszystkie operacje we/wy to skanowanie tych struktur w pamięci. Nie ma pojęcia, że wiersze danych są zapisywane w określonej lokalizacji, która należy do określonego obiektu. Chociaż nie musisz myśleć, że tabele zoptymalizowane pod kątem pamięci są przechowywane jako niezorganizowany zestaw wierszy danych (podobnie jak sterty dyskowe). Każda instrukcja CREATE TABLE dla tabeli zoptymalizowanej pod kątem pamięci tworzy co najmniej jeden indeks, którego SQL Server używa do łączenia wszystkich wierszy danych w tej tabeli.
Każdy wiersz danych składa się z nagłówka wiersza i ładunku, który jest rzeczywistymi danymi kolumny. Nagłówek przechowuje informacje o instrukcji, która utworzyła wiersz, wskaźniki dla każdego indeksu w tabeli docelowej oraz wartości sygnatury czasowej. Znacznik czasu wskazuje czas wstawienia i usunięcia wiersza przez transakcję. Rekordy programu SQL Server zostały zaktualizowane przez wstawienie nowej wersji wiersza i oznaczenie starej wersji jako usuniętej. W danym momencie może istnieć kilka wersji tego samego wiersza. Pozwala to na jednoczesny dostęp do tego samego wiersza podczas modyfikacji danych. SQL Server wyświetla wersję wiersza odpowiednią dla każdej transakcji zgodnie z czasem rozpoczęcia transakcji względem sygnatur czasowych wersji wiersza. To jest rdzeń nowej kontroli współbieżności wielu wersji mechanizm tabel w pamięci.
Nawiasem mówiąc, Oracle ma doskonały system kontroli wielu wersji. Zasadniczo działa to w następujący sposób:
- Użytkownik A rozpoczyna transakcję i aktualizuje 1000 wierszy o pewną wartość w czasie T1.
- Użytkownik B czyta te same 1000 wierszy w czasie T2.
- Użytkownik A aktualizuje wiersz 565 o wartość Y (pierwotna wartość to X).
- Użytkownik B dociera do wiersza 565 i stwierdza, że transakcja jest aktywna od czasu T1.
- Baza danych zwraca niezmodyfikowany rekord z dzienników. Zwracana wartość to wartość, która została zatwierdzona w czasie mniejszym lub równym T2.
- Jeśli nie można pobrać rekordu z dzienników przeróbek, oznacza to, że baza danych nie jest odpowiednio skonfigurowana. Należy przydzielić więcej miejsca na dzienniki.
- Zwracane wyniki są zawsze takie same w odniesieniu do czasu rozpoczęcia transakcji. Tak więc w ramach transakcji osiągana jest spójność odczytu.
Tabele skompilowane natywnie
Ostatnia główna różnica polega na tym, że tabele zoptymalizowane w pamięci są kompilowane natywnie . Gdy użytkownik tworzy tabelę lub indeks zoptymalizowaną pod kątem pamięci, SQL Server przechowuje strukturę każdej tabeli (wraz ze wszystkimi indeksami) w metadanych. Później SQL Server wykorzystuje te metadane do kompilacji w DDL zestawu procedur języka natywnego w celu uzyskania dostępu do tabeli. Takie DDL są powiązane z bazą danych, ale w rzeczywistości nie są jej częścią.
Innymi słowy, SQL Server przechowuje w pamięci nie tylko tabele i indeksy, ale także DDL w celu uzyskania dostępu i modyfikacji tych struktur. Po zmianie tabeli SQL Server musi odtworzyć wszystkie DDL dla operacji na tabelach. Dlatego nie można zmienić raz utworzonej tabeli. Te operacje są niewidoczne dla użytkowników.
Natywnie skompilowane procedury składowane
Najlepszą wydajność osiąga się, korzystając z natywnie skompilowanych procedur składowanych w celu uzyskania dostępu do natywnie skompilowanych tabel. Takie procedury zawierają instrukcje procesora i mogą być wykonywane bezpośrednio przez procesor bez dalszej kompilacji. Istnieją jednak pewne ograniczenia dotyczące konstrukcji T-SQL dla natywnie kompilowanych procedur składowanych (w porównaniu z tradycyjnie interpretowanym kodem). Innym ważnym punktem jest to, że natywnie skompilowane procedury składowane mogą uzyskać dostęp tylko do tabel zoptymalizowanych pod kątem pamięci.
Brak zamków
In-Memory OLTP to system bez blokad. Jest to możliwe, ponieważ SQL Server nigdy nie modyfikuje żadnego istniejącego wiersza. Operacja UPDATE tworzy nową wersję i oznacza poprzednią wersję jako usuniętą. Następnie wstawia nową wersję wiersza z nowymi danymi w środku.
Indeksy
Jak można się domyślić, indeksy bardzo różnią się od tradycyjnych. Tabele zoptymalizowane w pamięci nie mają stron. SQL Server wykorzystuje indeksy do łączenia wszystkich wierszy należących do tabeli w jedną strukturę. Nie możemy użyć instrukcji CREATE INDEX do utworzenia indeksu dla tabeli zoptymalizowanej w pamięci. Po utworzeniu klucza podstawowego w kolumnie SQL Server automatycznie tworzy unikalny indeks w tej kolumnie. Właściwie jest to jedyny dozwolony unikalny indeks. Możesz utworzyć maksymalnie osiem indeksów w tabeli zoptymalizowanej pod kątem pamięci.
Analogicznie do tabel, SQL Server przechowuje w pamięci indeksy zoptymalizowane pod kątem pamięci. Jednak SQL Server nigdy nie rejestruje operacji na indeksach. SQL Server automatycznie utrzymuje indeksy podczas modyfikacji tabel.
Tabele zoptymalizowane pod kątem pamięci obsługują dwa typy indeksów:indeks mieszający i indeks zakresu . Obie są strukturami nieklastrowymi.
indeks skrótu to nowy typ indeksu, zaprojektowany specjalnie dla tabel zoptymalizowanych pod kątem pamięci. Jest to niezwykle przydatne przy wyszukiwaniu określonych wartości. Sam indeks jest przechowywany jako tablica mieszająca. Jest to tablica wiader mieszających, gdzie każde wiadro jest wskaźnikiem do pojedynczego wiersza.
indeks zakresu (nie klastrowany) jest przydatny do pobierania zakresów wartości.
Odzyskiwanie
Podstawowy mechanizm odtwarzania bazy danych z tabelami zoptymalizowanymi pod kątem pamięci jest taki sam, jak mechanizm odtwarzania baz danych z tabelami dyskowymi. Jednak odzyskiwanie tabel zoptymalizowanych pod kątem pamięci obejmuje etap ładowania tabel zoptymalizowanych pod kątem pamięci do pamięci, zanim baza danych będzie dostępna dla użytkownika.
Po ponownym uruchomieniu SQL Server każda baza danych przechodzi przez następujące fazy procesu odzyskiwania:analiza , ponów i cofnij .
W fazie analizy aparat OLTP w pamięci identyfikuje spis punktów kontrolnych do załadowania i wstępnie ładuje wpisy dziennika tabeli systemowej. Przetworzy również niektóre zapisy dziennika alokacji plików.
W fazie ponawiania dane z par danych i plików delta są ładowane do pamięci. Następnie dane z aktywnego dziennika transakcji są aktualizowane na podstawie ostatniego trwałego punktu kontrolnego, a tabele w pamięci są wypełniane, a indeksy odbudowywane. Podczas tej fazy odzyskiwanie tabel z dysku i zoptymalizowanych pod kątem pamięci działa jednocześnie.
Faza cofania nie jest potrzebna w przypadku tabel zoptymalizowanych pod kątem pamięci, ponieważ OLTP w pamięci nie rejestruje żadnych niezatwierdzonych transakcji dla tabel zoptymalizowanych pod kątem pamięci.
Po zakończeniu wszystkich operacji baza danych jest dostępna.
Podsumowanie
W tym artykule przyjrzeliśmy się mechanizmowi OLTP w pamięci programu SQL Server. Dowiedzieliśmy się, że struktury zoptymalizowane pod kątem pamięci są przechowywane w pamięci. Procesy aplikacji mogą znaleźć wymagane dane, uzyskując dostęp do tych struktur w pamięci bez potrzeby wykonywania operacji we/wy na dysku. W kolejnych artykułach przyjrzymy się, jak tworzyć i uzyskiwać dostęp do baz danych i tabel OLTP w pamięci.
Dalsze czytanie
In-Memory OLTP:Co nowego w SQL Server 2016
Korzystanie z indeksów w tabelach SQL Server zoptymalizowanych pod kątem pamięci



