Puppet to oprogramowanie typu open source do zarządzania konfiguracją i wdrażania. Założona w 2005 roku, jest wieloplatformowa, a nawet ma własny deklaratywny język do konfiguracji.

Zadania związane z administracją i utrzymaniem PostgreSQL (a tak naprawdę innego oprogramowania) składa się z codziennych, powtarzalnych procesów wymagających monitorowania. Dotyczy to nawet zadań obsługiwanych przez skrypty lub polecenia za pomocą narzędzia do planowania. Złożoność tych zadań wzrasta wykładniczo, gdy są wykonywane na ogromnej infrastrukturze, jednak używanie Puppet do tego rodzaju zadań może często rozwiązywać tego rodzaju problemy na dużą skalę, ponieważ Puppet centralizuje i automatyzuje wykonywanie tych operacji w bardzo zwinny sposób.
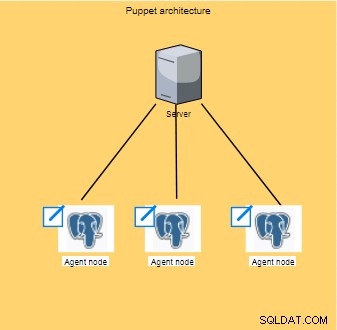
Puppet działa w ramach architektury na poziomie klient/serwer, na którym wykonywana jest konfiguracja; te operacje są następnie rozpowszechniane i wykonywane na wszystkich klientach (znanych również jako węzły).
Zazwyczaj uruchamiany co 30 minut, węzeł agenta zbiera zestaw informacji (typ procesora, architektura, adres IP itp.), nazywanych również faktami, a następnie wysyła informacje do master, który czeka na odpowiedź, aby sprawdzić, czy są jakieś nowe konfiguracje do zastosowania.
Te fakty pozwolą masterowi dostosować tę samą konfigurację dla każdego węzła.
W bardzo uproszczony sposób Puppet jest jednym z najważniejszych narzędzi DevOps dostępny dzisiaj. W tym blogu przyjrzymy się następującym...
- Przypadek użycia Puppet i PostgreSQL
- Instalowanie Puppet
- Konfigurowanie i programowanie lalki
- Konfigurowanie Puppet dla PostgreSQL
Instalacja i konfiguracja Puppet (wersja 5.3.10) opisana poniżej została przeprowadzona na zestawie hostów używających CentOS 7.0 jako systemu operacyjnego.
Przypadek użycia Puppet i PostgreSQL
Załóżmy, że występuje problem z zaporą sieciową na komputerach, które obsługują wszystkie serwery PostgreSQL, wówczas konieczne byłoby odrzucenie wszystkich połączeń wychodzących do PostgreSQL i zrobienie tego tak szybko, jak to możliwe.

Puppet jest idealnym narzędziem w tej sytuacji, zwłaszcza że szybkość i wydajność są kluczowy. Porozmawiamy o tym przykładzie przedstawionym w sekcji „Konfiguracja Puppet dla PostgreSQL”, zarządzając parametrem listen_addresses.
Instalowanie marionetki
Istnieje zestaw typowych kroków do wykonania na hoście głównym lub agencie:
Krok pierwszy
Aktualizacja pliku /etc/hosts z nazwami hostów i ich adresami IP
192.168.1.85 agent agent.severalnines.com
192.168.1.87 master master.severalnines.com puppetKrok drugi
Dodawanie repozytoriów Puppet w systemie
$ sudo rpm –Uvh https://yum.puppetlabs.com/puppet5/el/7/x86_64/puppet5-release-5.0.0-1-el7.noarch.rpmW przypadku innych systemów operacyjnych lub wersji CentOS najbardziej odpowiednie repozytorium można znaleźć w Puppet, Inc. Yum Repositories.
Krok trzeci
Konfiguracja serwera NTP (Network Time Protocol)
$ sudo yum -y install chronyKrok czwarty
Chrony służy do synchronizacji zegara systemowego z różnych serwerów NTP, a tym samym utrzymuje synchronizację czasu między serwerem głównym a serwerem agenta.
Po zainstalowaniu chronometru należy go włączyć i ponownie uruchomić:
$ sudo systemctl enable chronyd.service
$ sudo systemctl restart chronyd.serviceKrok piąty
Wyłącz parametr SELinux
W pliku /etc/sysconfig/selinux parametr SELINUX (Security-Enhanced Linux) musi być wyłączony, aby nie ograniczał dostępu na obu hostach.
SELINUX=disabledKrok szósty
Przed instalacją Puppet (główną lub agentową) należy odpowiednio zdefiniować firewall na tych hostach:
$ sudo firewall-cmd -–add-service=ntp -–permanent
$ sudo firewall-cmd –-reload Instalowanie mistrza marionetek
Po dodaniu repozytorium pakietów puppet5-release-5.0.0-1-el7.noarch.rpm do systemu można przeprowadzić instalację serwera puppetserver:
$ sudo yum install -y puppetserverParametr maksymalnej alokacji pamięci jest ważnym ustawieniem do aktualizacji pliku /etc/sysconfig/puppetserver do 2 GB (lub do 1 GB, jeśli usługa się nie uruchamia):
JAVA_ARGS="-Xms2g –Xmx2g "W pliku konfiguracyjnym /etc/puppetlabs/puppet/puppet.conf należy dodać następującą parametryzację:
[master]
dns_alt_names=master.severalnines.com,puppet
[main]
certname = master.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hUsługa puppetserver używa portu 8140 do nasłuchiwania żądań węzłów, dlatego należy upewnić się, że ten port będzie włączony:
$ sudo firewall-cmd --add-port=8140/tcp --permanent
$ sudo firewall-cmd --reloadPo wprowadzeniu wszystkich ustawień w puppet master, czas uruchomić tę usługę:
$ sudo systemctl start puppetserver
$ sudo systemctl enable puppetserver
Instalowanie agenta marionetek
Agent marionetek w repozytorium pakietów puppet5-release-5.0.0-1-el7.noarch.rpm jest również dodawany do systemu, instalację agenta marionetek można przeprowadzić od razu:
$ sudo yum install -y puppet-agentPlik konfiguracyjny puppet-agent /etc/puppetlabs/puppet/puppet.conf również wymaga aktualizacji poprzez dodanie następującego parametru:
[main]
certname = agent.severalnines.com
server = master.severalnines.com
environment = production
runinterval = 1hNastępny krok polega na zarejestrowaniu węzła agenta na hoście głównym poprzez wykonanie następującego polecenia:
$ sudo /opt/puppetlabs/bin/puppet resource service puppet ensure=running enable=true
service { ‘puppet’:
ensure => ‘running’,
enable => ‘true’
}W tej chwili na głównym hoście istnieje oczekujące żądanie od agenta marionetkowego o podpisanie certyfikatu:

To musi być podpisane przez wykonanie jednego z następujących poleceń:
$ sudo /opt/puppetlabs/bin/puppet cert sign agent.severalnines.comlub
$ sudo /opt/puppetlabs/bin/puppet cert sign --allWreszcie (i kiedy mistrz marionetek podpisze certyfikat) nadszedł czas na zastosowanie konfiguracji do agenta poprzez pobranie katalogu od mistrza marionetek:
$ sudo /opt/puppetlabs/bin/puppet agent --testW tym poleceniu parametr --test nie oznacza testu, ustawienia pobrane z mastera zostaną zastosowane do lokalnego agenta. Aby przetestować/sprawdzić konfiguracje z urządzenia głównego, należy wykonać następujące polecenie:
$ sudo /opt/puppetlabs/bin/puppet agent --noopKonfigurowanie i programowanie lalki
Puppet używa deklaratywnego podejścia programistycznego, którego celem jest określenie, co należy zrobić i nie ma znaczenia, jak to osiągnąć!
Najbardziej podstawowy fragment kodu w Puppet to zasób, który określa właściwość systemową, taką jak polecenie, usługa, plik, katalog, użytkownik lub pakiet.
Poniżej przedstawiono składnię zasobu do utworzenia użytkownika:
user { 'admin_postgresql':
ensure => present,
uid => '1000',
gid => '1000',
home => '/home/admin/postresql'
}Do poprzedniej klasy (znanej również jako manifest) pliku z rozszerzeniem „pp” (skrót od Puppet Program) można było dołączyć różne zasoby, niemniej jednak kilka manifestów i danych (takich jak fakty, pliki i szablony) utworzą moduł. Wszystkie logiczne hierarchie i reguły są przedstawione na poniższym schemacie:
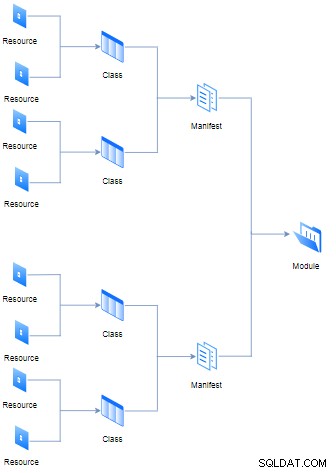
Celem każdego modułu jest zawieranie wszystkich manifestów potrzebnych do wykonania pojedynczego zadania w sposób modułowy. Z drugiej strony koncepcja klasy nie jest taka sama jak w przypadku języków programowania obiektowego, w Puppet działa ona jako agregator zasobów.
Ta organizacja plików ma określoną strukturę katalogów, których należy przestrzegać:
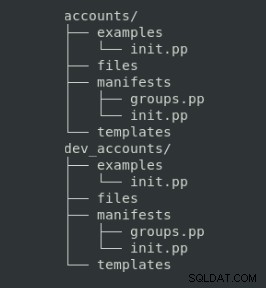
Jakie przeznaczenie każdego folderu jest następujące:
| Folder | Opis |
| manifesty | Kod marionetki |
| pliki | Pliki statyczne do skopiowania do węzłów |
| szablony | Pliki szablonów do skopiowania do węzłów zarządzanych (można je dostosować za pomocą zmiennych) |
| przykłady | Manifest pokazujący, jak korzystać z modułu |
class dev_accounts {
$rootgroup = $osfamily ? {
'Debian' => 'sudo',
'RedHat' => 'wheel',
default => warning('This distribution is not supported by the Accounts module'),
}
include accounts::groups
user { 'username':
ensure => present,
home => '/home/admin/postresql',
shell => '/bin/bash',
managehome => true,
gid => 'admin_db',
groups => "$rootgroup",
password => '$1$7URTNNqb$65ca6wPFDvixURc/MMg7O1'
}
}W następnej sekcji pokażemy, jak wygenerować zawartość folderu przykładów oraz polecenia do testowania i publikowania każdego modułu.
Konfigurowanie Puppet dla PostgreSQL
Przed przedstawieniem kilku przykładów konfiguracji w celu wdrożenia i utrzymania bazy danych PostgreSQL konieczne jest zainstalowanie modułu marionetek PostgreSQL (na hoście serwera), aby móc korzystać ze wszystkich jego funkcji:
$ sudo /opt/puppetlabs/bin/puppet module install puppetlabs-postgresqlObecnie tysiące modułów gotowych do użycia w Puppet są dostępne w publicznym repozytorium modułów Puppet Forge.
Krok pierwszy
Skonfiguruj i wdróż nową instancję PostgreSQL. Oto całe niezbędne programowanie i konfiguracja, aby zainstalować nową instancję PostgreSQL we wszystkich węzłach.
Pierwszym krokiem jest utworzenie nowego katalogu ze strukturą modułów, który został wcześniej udostępniony:
$ cd /etc/puppetlabs/code/environments/production/modules
$ mkdir db_postgresql_admin
$ cd db_postgresql_admin; mkdir{examples,files,manifests,templates}Następnie w pliku manifests/init.pp należy dołączyć klasę postgresql::server dostarczoną przez zainstalowany moduł :
class db_postgresql_admin{
include postgresql::server
}Aby sprawdzić składnię manifestu, dobrą praktyką jest wykonanie następującego polecenia:
$ sudo /opt/puppetlabs/bin/puppet parser validate init.ppJeśli nic nie zostanie zwrócone, oznacza to, że składnia jest poprawna
Aby pokazać, jak korzystać z tego modułu w przykładowym folderze, konieczne jest utworzenie nowego pliku manifestu init.pp o następującej treści:
include db_postgresql_adminPrzykładowa lokalizacja w module musi zostać przetestowana i zastosowana do głównego katalogu:
$ sudo /opt/puppetlabs/bin/puppet apply --modulepath=/etc/puppetlabs/code/environments/production/modules --noop init.ppNa koniec konieczne jest zdefiniowanie, do którego modułu każdy węzeł ma dostęp w pliku „/etc/puppetlabs/code/environments/production/manifests/site.pp” :
node ’agent.severalnines.com’,’agent2.severalnines.com’{
include db_postgresql_admin
}Lub domyślna konfiguracja dla wszystkich węzłów:
node default {
include db_postgresql_admin
}Zazwyczaj co 30 minut węzły sprawdzają główny katalog, jednak zapytanie to można wymusić po stronie węzła za pomocą następującego polecenia:
$ /opt/puppetlabs/bin/puppet agent -tLub, jeśli celem jest symulacja różnic między konfiguracją główną a bieżącymi ustawieniami węzła, można użyć parametru nopp (bez operacji):
$ /opt/puppetlabs/bin/puppet agent -t --noopKrok drugi
Zaktualizuj instancję PostgreSQL, aby nasłuchiwać wszystkich interfejsów. Poprzednia instalacja definiuje ustawienie instancji w bardzo restrykcyjnym trybie:zezwala tylko na połączenia na hoście lokalnym, co może potwierdzić host powiązany z portem 5432 (zdefiniowanym dla PostgreSQL):
$ sudo netstat -ntlp|grep 5432
tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 3237/postgres
tcp6 0 0 ::1:5432 :::* LISTEN 3237/postgres Aby umożliwić nasłuchiwanie całego interfejsu, konieczne jest posiadanie następującej zawartości w pliku /etc/puppetlabs/code/environments/production/modules/db_postgresql_admin/manifests/init.pp
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
}W powyższym przykładzie zadeklarowana jest klasa postgresql::server z parametrem listen_addresses na „*”, co oznacza wszystkie interfejsy.
Teraz port 5432 jest powiązany ze wszystkimi interfejsami, można to potwierdzić za pomocą następującego adresu/portu IP:„0.0.0.0:5432”
$ sudo netstat -ntlp|grep 5432
tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 1232/postgres
tcp6 0 0 :::5432 :::* LISTEN 1232/postgres Aby przywrócić ustawienia początkowe:zezwalaj tylko na połączenia z bazą danych z hosta lokalnego, parametr listen_addresses musi być ustawiony na „localhost” lub w razie potrzeby określić listę hostów:
listen_addresses = 'agent2.severalnines.com,agent3.severalnines.com,localhost'Aby pobrać nową konfigurację z hosta głównego, wystarczy zażądać jej w węźle:
$ /opt/puppetlabs/bin/puppet agent -tKrok trzeci
Utwórz bazę danych PostgreSQL. Instancję PostgreSQL można utworzyć z nową bazą danych, jak również z nowym użytkownikiem (z hasłem) do korzystania z tej bazy danych i regułą w pliku pg_hab.conf, aby umożliwić połączenie z bazą danych dla tego nowego użytkownika:
class db_postgresql_admin{
class{‘postgresql:server’:
listen_addresses=>’*’ #listening all interfaces
}
postgresql::server::db{‘nines_blog_db’:
user => ‘severalnines’, password=> postgresql_password(‘severalnines’,’passwd12’)
}
postgresql::server::pg_hba_rule{‘Authentication for severalnines’:
Description =>’Open access to severalnines’,
type => ‘local’,
database => ‘nines_blog_db’,
user => ‘severalnines’,
address => ‘127.0.0.1/32’
auth_method => ‘md5’
}
}Ten ostatni zasób ma nazwę „Uwierzytelnianie przez kilka dziewiątek”, a plik pg_hba.conf będzie miał jeszcze jedną dodatkową regułę:
# Rule Name: Authentication for severalnines
# Description: Open access for severalnines
# Order: 150
local nines_blog_db severalnines 127.0.0.1/32 md5Aby pobrać nową konfigurację z hosta głównego, wystarczy zażądać jej w węźle:
$ /opt/puppetlabs/bin/puppet agent -tKrok czwarty
Utwórz użytkownika tylko do odczytu. Aby utworzyć nowego użytkownika z uprawnieniami tylko do odczytu, do poprzedniego manifestu należy dodać następujące zasoby:
postgresql::server::role{‘Creation of a new role nines_reader’:
createdb => false,
createrole => false,
superuser => false, password_hash=> postgresql_password(‘nines_reader’,’passwd13’)
}
postgresql::server::pg_hba_rule{‘Authentication for nines_reader’:
description =>’Open access to nines_reader’,
type => ‘host’,
database => ‘nines_blog_db’,
user => ‘nines_reader’,
address => ‘192.168.1.10/32’,
auth_method => ‘md5’
}Aby pobrać nową konfigurację z hosta głównego, wystarczy zażądać jej w węźle:
$ /opt/puppetlabs/bin/puppet agent -tWnioski
W tym poście na blogu pokazaliśmy podstawowe kroki, aby wdrożyć i rozpocząć konfigurację bazy danych PostgreSQL w automatyczny i dostosowany sposób na kilku węzłach (które mogą być nawet maszynami wirtualnymi).
Te rodzaje automatyzacji mogą pomóc Ci stać się bardziej efektywnym niż robienie tego ręcznie, a konfigurację PostgreSQL można łatwo przeprowadzić przy użyciu kilku klas dostępnych w repozytorium puppetforge