Jakie problemy rozważymy?
Jeśli serwer poinformuje, że „nie ma już miejsca na dysku E” – nie jest potrzebna głęboka analiza. Nie będziemy brać pod uwagę błędów, których rozwiązanie jest oczywiste z tekstu wiadomości i dla których Google natychmiast wrzuca link do MSDN z rozwiązaniem.
Przyjrzyjmy się problemom, które nie są oczywiste dla Google, jak np. nagły spadek wydajności czy brak połączenia. Rozważ główne narzędzia dostosowywania i analizy. Zobaczmy, gdzie znajdują się logi i inne przydatne informacje. W rzeczywistości postaram się zebrać w jednym artykule wszystkie informacje niezbędne do szybkiego rozpoczęcia.
Przede wszystkim
Zaczniemy od najczęstszych pytań i rozważymy je osobno.
Jeśli Twoja baza danych nagle, bez wyraźnego powodu, zaczęła działać powoli, ale nic nie zmieniłeś – przede wszystkim zaktualizuj statystyki i odbuduj indeksy.
W Internecie istnieje wiele takich metod, podano przykłady skryptów. Zakładam, że wszystkie te metody są dla profesjonalistów. Cóż, opiszę najprostszy sposób:do jego wdrożenia potrzebujesz tylko myszy.
Skróty
- SSMS to aplikacja Microsoft SQL Server Management Studio. Od wersji 2016 jest dostępny bezpłatnie na stronie MS jako samodzielna aplikacja. docs.microsoft.com/en-us/sql/ssms/download-sql-server-management-studio-ssms
- Profiler to aplikacja „SQL Server Profiler” instalowana z SSMS.
- Monitor wydajności to przystawka panelu sterowania, która pozwala monitorować liczniki wydajności, rejestrować i przeglądać historię pomiarów.
Aktualizacja statystyk za pomocą „planu serwisowego”:
- uruchom SMS-y;
- połączyć się z wymaganym serwerem;
- rozwiń drzewo w Object Inspector:Management\Maintenance Plans (Service Plans);
- kliknij prawym przyciskiem myszy węzeł i wybierz „Kreator planu konserwacji”;
- w kreatorze zaznacz wymagane zadania:odbuduj indeks i zaktualizuj statystyki
- możesz oznaczyć oba zadania jednocześnie lub stworzyć dwa plany konserwacji z jednym zadaniem w każdym (patrz „ważne uwagi” poniżej);
- ponadto sprawdzamy wymaganą bazę danych (lub kilka baz danych). Robimy to dla każdego zadania (jeśli zostaną wybrane dwa zadania, pojawią się dwa okna dialogowe z wyborem bazy danych);
- Dalej, Dalej, Zakończ.
Po tych czynnościach zostanie utworzony (niewykonany) „plan konserwacji”. Możesz uruchomić go ręcznie, klikając go prawym przyciskiem myszy i wybierając "Wykonaj". Alternatywnie możesz skonfigurować uruchamianie za pomocą agenta SQL.
Ważne uwagi:
- Aktualizowanie statystyk nie jest operacją blokującą. Możesz to wykonać w trybie pracy.
- Odbudowa indeksu jest operacją blokującą. Możesz go uruchomić tylko poza godzinami pracy. Jest wyjątek — wersja Enterprise serwera umożliwia wykonanie „przebudowy online”. Tę opcję można włączyć w ustawieniach zadania. Pamiętaj, że we wszystkich wydaniach znajduje się znacznik wyboru, ale działa on tylko w Enterprise.
- Oczywiście zadania te należy wykonywać regularnie. Proponuję prosty sposób określenia, jak często to robisz:
– Przy pierwszych problemach wykonaj plan konserwacji;
– Jeśli to pomogło, poczekaj, aż problemy wystąpią ponownie (zwykle do następnego miesięcznego zamknięcia/obliczenia wynagrodzenia/itd. transakcji zbiorczych);
– Punktem odniesienia będzie wynikowy okres normalnej eksploatacji;
– Na przykład skonfiguruj wykonanie planu konserwacji dwa razy częściej.
Serwer działa wolno – co należy zrobić?
Zasoby używane przez serwer
Jak każdy inny program, serwer potrzebuje czasu procesora, danych na dysku, ilości pamięci RAM i przepustowości sieci.
Menedżer zadań pomoże Ci ocenić brak danego zasobu w pierwszym przybliżeniu, bez względu na to, jak okropnie może to zabrzmieć.
procesor Załaduj
Nawet uczeń może sprawdzić wykorzystanie w Managerze. Musimy tylko upewnić się, że jeśli procesor jest załadowany, to jest to proces sqlserver.exe.
Jeśli tak jest w Twoim przypadku, musisz przejść do analizy aktywności użytkowników, aby zrozumieć, co dokładnie spowodowało obciążenie (patrz poniżej).
Płyta Loa d
Wiele osób patrzy tylko na obciążenie procesora, ale zapomina, że DBMS jest magazynem danych. Ilość danych rośnie, wydajność procesora rośnie, a prędkość dysku twardego jest prawie taka sama. W przypadku dysków SSD sytuacja jest lepsza, ale przechowywanie na nich terabajtów jest drogie.
Okazuje się, że często spotykam się z sytuacjami, w których wąskim gardłem staje się system dyskowy, a nie procesor.
W przypadku dysków ważne są następujące metryki:
- średnia długość kolejki (wyjątkowe operacje we/wy, liczba);
- prędkość odczytu i zapisu (w Mb/s).
Wersja serwerowa Menedżera zadań z reguły (w zależności od wersji systemu) pokazuje oba. Jeśli nie, uruchom przystawkę Monitor wydajności (monitor systemu). Interesują nas następujące liczniki:
- Fizyczny (logiczny) dysk/średni czas odczytu (zapisu)
- Fizyczny (logiczny) dysk/średnia długość kolejki dyskowej
- Fizyczna (logiczna) prędkość dysku/dysku
Więcej informacji można znaleźć w instrukcjach producenta, na przykład tutaj:social.technet.microsoft.com/wiki/contents/articles/3214.monitoring-disk-usage.aspx.
W skrócie:
- Kolejka nie powinna przekraczać 1. Krótkie serie są dozwolone, jeśli szybko ustępują. Serie mogą się różnić w zależności od systemu. Dla prostego mirrora RAID dwóch dysków twardych – kolejka ponad 10-20 jest problemem. W przypadku fajnej biblioteki z superbuforowaniem widziałem wybuchy do 600-800, które były natychmiast rozwiązywane bez powodowania opóźnień.
- Normalny kurs wymiany zależy również od typu systemu dyskowego. Zwykły (komputerowy) dysk twardy przesyła z prędkością 50-100 MB/s. Dobra biblioteka dyskowa – z prędkością 500 MB/s i więcej. W przypadku małych operacji losowych prędkość jest mniejsza. To może być twój punkt odniesienia.
- Te parametry należy traktować jako całość. Jeśli twoja biblioteka przesyła 50 MB/s i ustawia się kolejka 50 operacji — oczywiście coś jest nie tak ze sprzętem. Jeśli kolejka ustawia się, gdy transmisja zbliża się do maksimum – najprawdopodobniej nie można winić dysków – po prostu nie mogą zrobić więcej – musimy poszukać sposobu na zmniejszenie obciążenia.
- Obciążenie należy osobno sprawdzić na dyskach (jeśli jest ich kilka) i porównać z lokalizacją plików serwera. Menedżer zadań może wyświetlać najaktywniej używane pliki. Można to wykorzystać, aby upewnić się, że obciążenie jest spowodowane przez DBMS.
Co może powodować problemy z systemem dysku:
- problemy ze sprzętem
- wypaliła się pamięć podręczna, wydajność dramatycznie spadła;
- system dyskowy jest używany przez coś innego;
- Brak pamięci RAM. Zamiana. Pamięć podręczna zepsuła się, wydajność spadła (zobacz sekcję o pamięci RAM poniżej).
- Wzrosło obciążenie użytkowników. Konieczna jest ocena pracy użytkowników (problematyczne zapytanie/nowa funkcjonalność/wzrost liczby użytkowników/wzrost ilości danych/itd).
- Fragmentacja danych bazy danych (patrz powyżej przebudowa indeksu), fragmentacja plików systemowych.
- System dysków osiągnął swoje maksymalne możliwości.
W przypadku ostatniej opcji – nie wyrzucaj sprzętu od razu. Czasami możesz wydobyć trochę więcej z systemu, jeśli mądrze podejdziesz do problemu. Sprawdź lokalizację plików systemowych pod kątem zgodności z zalecanymi wymaganiami:
- Nie mieszaj plików systemu operacyjnego z plikami danych bazy danych. Przechowuj je na różnych nośnikach fizycznych, aby system nie konkurował z DBMS o I/O.
- Baza danych składa się z dwóch typów plików:danych (*.mdf, *.ndf) i dzienników (*.ldf).
Pliki danych z reguły służą głównie do odczytu. Logi służą do pisania (przy czym pismo jest konsekutywne). Dlatego zaleca się przechowywanie dzienników i danych na różnych nośnikach fizycznych, aby rejestrowanie nie przerywało odczytu danych (z reguły operacja zapisu ma pierwszeństwo przed odczytem). - MS SQL może używać „tablic tymczasowych” do przetwarzania zapytań. Są one przechowywane w bazie danych systemu tempdb. Jeśli masz duże obciążenie plików tej bazy danych, możesz spróbować renderować ją na fizycznie oddzielnym nośniku.
Podsumowując problem z lokalizacją plików, zastosuj zasadę „dziel i rządź”. Oceń, które pliki są dostępne, i spróbuj rozpowszechniać je na różnych nośnikach. Korzystaj także z funkcji systemów RAID. Na przykład odczyty RAID-5 są szybsze niż zapisy – co jest dobre w przypadku plików danych.
Przyjrzyjmy się, jak uzyskać informacje o wydajności użytkownika:kto co robi i ile zasobów jest zużywanych
Zadania audytu aktywności użytkowników podzieliłem na następujące grupy:
- Zadania analizy konkretnego żądania.
- Zadania analizy obciążenia z aplikacji w określonych warunkach (na przykład, gdy użytkownik kliknie przycisk w aplikacji innej firmy zgodnej z bazą danych).
- Zadania analizy obecnej sytuacji.
Przyjrzyjmy się każdemu z nich szczegółowo.
Ostrzeżenie
Analiza wydajności wymaga dogłębnego zrozumienia struktury i zasad działania serwera bazy danych oraz systemu operacyjnego. Dlatego czytanie tylko tych artykułów nie uczyni Cię profesjonalistą.
Rozważane kryteria i liczniki w rzeczywistych systemach są bardzo od siebie zależne. Na przykład duże obciążenie HDD jest często spowodowane brakiem pamięci RAM. Nawet jeśli przeprowadzisz jakieś pomiary, to nie wystarczy, aby rozsądnie ocenić problemy.
Celem artykułów jest wprowadzenie zasadniczych elementów na prostych przykładach. Nie powinieneś traktować moich zaleceń jako przewodnika. Polecam używać ich jako zadań szkoleniowych, które mogą wyjaśnić przepływ myśli.
Mam nadzieję, że nauczysz się racjonalizować swoje wnioski dotyczące wydajności serwera w liczbach.
Zamiast mówić „serwer zwalnia”, podasz określone wartości określonych wskaźników.
Przeanalizuj P stawowy R prośba
Pierwszy punkt jest dość prosty, zastanówmy się nad nim pokrótce. Rozważymy kilka mniej oczywistych kwestii.
Oprócz wyników zapytania, SSMS umożliwia pobieranie dodatkowych informacji o wykonaniu zapytania:
- Plan zapytania można uzyskać, klikając przyciski „Wyświetl szacowany plan wykonania” i „Uwzględnij rzeczywisty plan wykonania”. Różnica między nimi polega na tym, że plan estymacji jest budowany bez wykonywania zapytania. W ten sposób zostaną oszacowane informacje o liczbie przetworzonych wierszy. W rzeczywistym planie będą zarówno dane szacunkowe, jak i rzeczywiste. Duże rozbieżności tych wartości wskazują, że statystyki są nieistotne. Analiza planu jest jednak tematem na inny artykuł – na razie nie będziemy się zagłębiać.
- Możemy uzyskać pomiary kosztów procesora i operacji dyskowych serwera. W tym celu konieczne jest włączenie opcji SET. Możesz to zrobić w oknie dialogowym „Opcje zapytania” w następujący sposób:
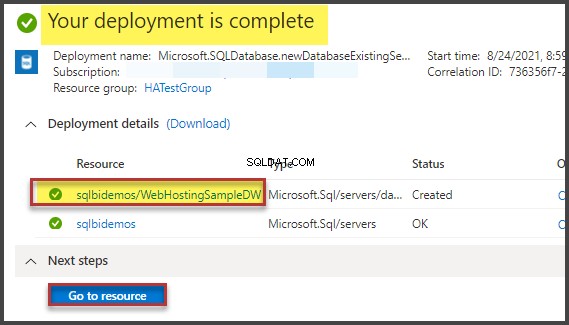
Lub za pomocą bezpośrednich poleceń SET w zapytaniu:
SET STATISTICS IO ON
SET STATISTICS TIME ON
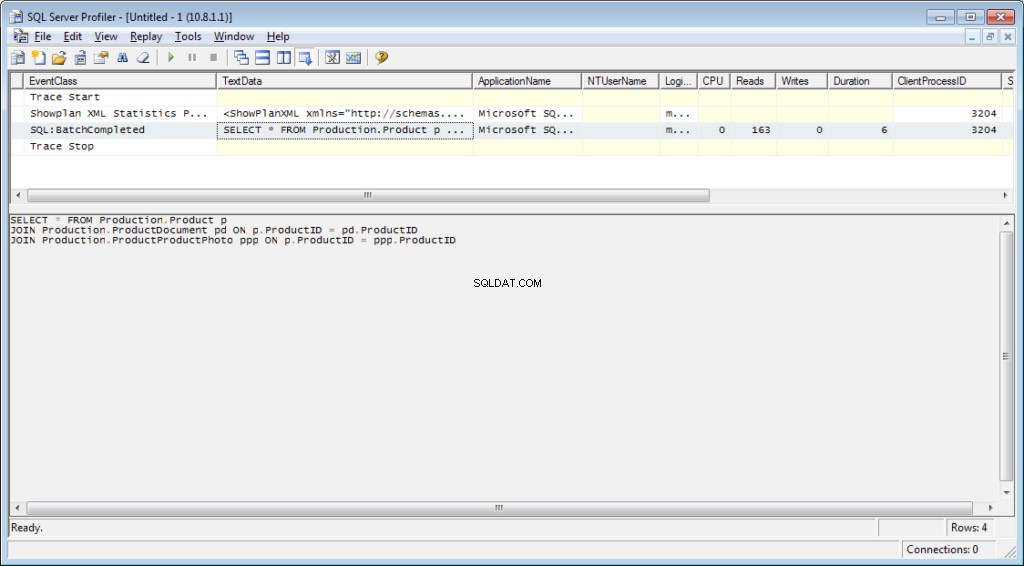
SELECT * FROM Production.Product p
JOIN Production.ProductDocument pd ON p.ProductID = pd.ProductID
JOIN Production.ProductProductPhoto ppp ON p.ProductID = ppp.ProductIDW rezultacie otrzymamy dane dotyczące czasu poświęconego na kompilację i wykonanie, a także liczbę operacji dyskowych.
Time of SQL Server parsing and compilation:
CPU time = 16 ms, elapsed time = 89 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
SQL Server performance time:
CPU time = 0 ms, time spent = 0 ms.
(32 row(s) affected)
The «ProductProductPhoto» table. The number of views is 32, logic reads – 96, physical reads 5, read-ahead reads 0, lob of logical reads 0, lob of physical reads 0, lob of read-ahead reads 0.
The ‘Product’ table. The number of views is 0, logic reads – 64, physical reads – 0, read-ahead reads – 0, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
The «ProductDocument» table. The number of views is 1, logical reads – 3, physical reads – 1, read-ahead reads -, lob of logical reads – 0, lob of physical reads – 0, lob of readahead reads – 0.
Time of SQL activity:
CPU time = 15 ms, spent time = 35 ms.Chciałbym zwrócić uwagę na czas kompilacji, odczyty logiczne 96 i odczyty fizyczne 5. Podczas wykonywania tego samego zapytania po raz drugi i później, odczyty fizyczne mogą się zmniejszyć, a ponowna kompilacja może nie być wymagana. Z tego powodu często zdarza się, że przy drugim i kolejnych razach zapytanie jest wykonywane szybciej niż za pierwszym razem. Powodem, jak rozumiesz, jest buforowanie danych i skompilowanych planów zapytań.
- Przycisk «Dołącz statystyki klienta» wyświetla informacje o wymianie sieci, ilości wykonanych operacji i całkowitym czasie wykonania, w tym koszty wymiany sieci i przetwarzania przez klienta. Przykład pokazuje, że wykonanie zapytania po raz pierwszy zajmuje więcej czasu:
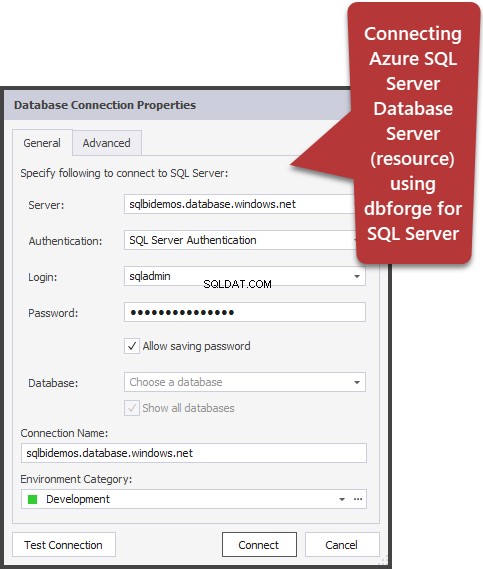
- W SSMS 2016 znajduje się przycisk «Dołącz statystyki zapytań na żywo». Wyświetla obraz jak w przypadku planu zapytania, ale zawiera nielosowe cyfry przetwarzanych wierszy, które zmieniają się na ekranie podczas wykonywania zapytania. Obraz jest bardzo wyraźny – migające strzałki i biegnące cyfry, od razu widać, gdzie marnuje się czas. Przycisk działa również dla SQL Server 2014 i nowszych.
Podsumowując:
- Sprawdź koszty procesora za pomocą SET STATISTICS TIME ON.
- Operacje na dyskach:WŁĄCZ STATYSTYKI IO. Nie zapominaj, że odczyt logiczny jest operacją odczytu zakończoną w pamięci podręcznej dysku bez fizycznego dostępu do systemu dyskowego. „Odczyt fizyczny” zajmuje znacznie więcej czasu.
- Oceń natężenie ruchu sieciowego za pomocą «Dołącz statystyki klienta».
- Przeanalizuj algorytm wykonania zapytania według planu wykonania za pomocą «Uwzględnij rzeczywisty plan wykonania» i «Uwzględnij statystyki zapytań na żywo».
Analizuj ładowanie aplikacji
Tutaj użyjemy SQL Server Profiler. Po uruchomieniu i połączeniu się z serwerem należy wybrać logowanie zdarzeń. Aby to zrobić, uruchom profilowanie za pomocą standardowego szablonu śledzenia. Na Ogólnym w zakładce Użyj szablonu w polu wybierz Standardowy (domyślny) i kliknij Uruchom .
Bardziej skomplikowanym sposobem jest dodawanie/upuszczanie filtrów lub zdarzeń do/z wybranego szablonu. Opcje te można znaleźć w drugiej zakładce menu dialogowego. Aby zobaczyć pełny zakres możliwych zdarzeń i kolumn do wybrania, wybierz Pokaż wszystkie zdarzenia i Pokaż wszystkie kolumny pola wyboru.

Będziemy potrzebować następujących wydarzeń:
- Przechowywane procedury \ RPC:zakończone
- TSQL \ SQL:BatchCompleted
Zdarzenia te monitorują wszystkie zewnętrzne wywołania SQL do serwera. Pojawiają się po zakończeniu przetwarzania zapytania. Istnieją podobne zdarzenia, które śledzą start SQL Server:
- Przechowywane procedury \ RPC:Rozpoczęcie
- TSQL \ SQL:Uruchamianie wsadowe
Jednak nie potrzebujemy tych procedur, ponieważ nie zawierają one informacji o zasobach serwera wydanych na wykonanie zapytania. Wiadomo, że takie informacje są dostępne dopiero po zakończeniu procesu egzekucyjnego. W związku z tym kolumny z danymi dotyczącymi procesora, odczytów i zapisów w *zdarzeniach początkowych będą puste.
Mogą nas również zainteresować następujące wydarzenia, jednak na razie ich nie włączymy:
- Procedury składowane \ SP:Starting (*Completed) monitoruje wewnętrzne wywołanie procedury składowanej nie od klienta, ale w ramach bieżącego żądania lub innej procedury.
- Procedury składowane \ SP:StmtStarting (*Completed) śledzi początek każdej instrukcji w ramach procedury składowanej. Jeśli w procedurze występuje cykl, liczba zdarzeń dla poleceń w cyklu będzie równa liczbie iteracji w cyklu.
- TSQL \ SQL:StmtStarting (*Completed) monitoruje początek każdej instrukcji w partiach SQL. Jeśli w zapytaniu jest kilka poleceń, każde z nich będzie zawierać jedno zdarzenie. W ten sposób działa dla poleceń znajdujących się w zapytaniu.
Te zdarzenia są wygodne do monitorowania procesu wykonywania.
Autor:C kolumny
Które kolumny wybrać, wynika z nazwy przycisku. Będziemy potrzebować następujących:
- TextData, BinaryData zawierają tekst zapytania.
- CPU, odczyty, zapisy, czas wyświetlania danych o zużyciu zasobów.
- StartTime, EndTime to czas rozpoczęcia i zakończenia procesu wykonywania. Są wygodne do sortowania.
Dodaj inne kolumny na podstawie swoich preferencji.
Filtry kolumn… przycisk otwiera okno dialogowe konfiguracji filtrów zdarzeń. Jeśli interesuje Cię aktywność konkretnego użytkownika, możesz ustawić filtr według numeru SID lub nazwy użytkownika. Niestety, w przypadku łączenia aplikacji przez serwer-aplikację z ciągiem połączeń, monitorowanie konkretnego użytkownika staje się bardziej skomplikowane.
Możesz użyć filtrów do selekcji tylko skomplikowanych zapytań (Duration>X), zapytań powodujących intensywny zapis (Writes>Y), a także selekcji treści zapytań itp.
Czego jeszcze potrzebujemy od profilera? Oczywiście plan wykonania!
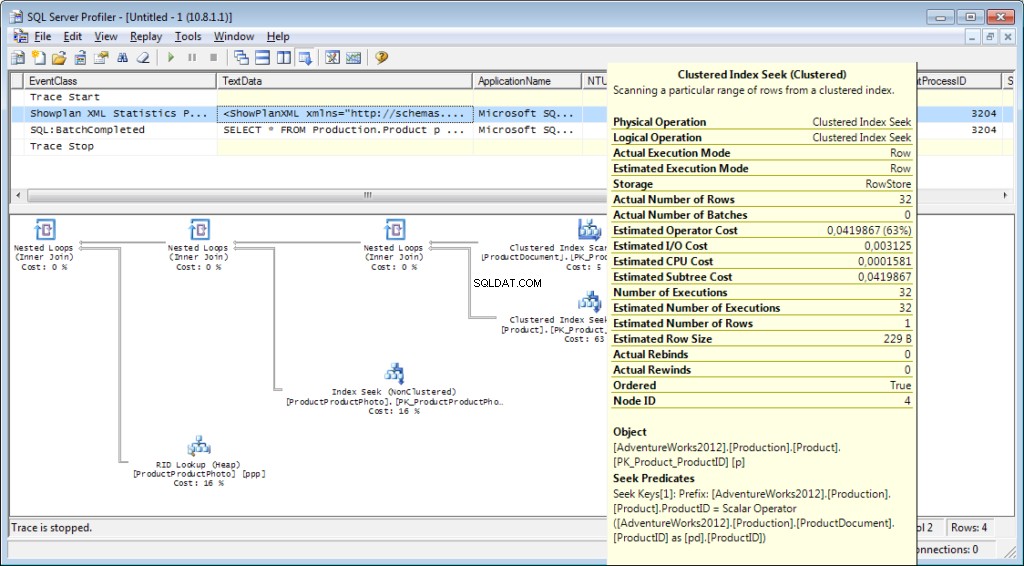
Do śledzenia należy dodać zdarzenie «Performance \ Showplan XML Statistics Profile». Podczas wykonywania naszego zapytania otrzymamy następujący obraz:
Tekst zapytania:
Plan wykonania:
A to nie wszystko
Możliwe jest zapisanie śladu do pliku lub tabeli bazy danych. Ustawienia śledzenia można przechowywać jako osobisty szablon w celu szybkiego uruchomienia. Śledzenie można uruchomić bez profilera, po prostu przy użyciu kodu T-SQL i procedur sp_trace_create, sp_trace_setevent, sp_trace_setstatus, sp_trace_getdata. Przykład znajdziesz tutaj. Takie podejście może być przydatne, na przykład, aby automatycznie rozpocząć przechowywanie śladu do pliku zgodnie z harmonogramem. Możesz rzucić okiem na profilera, aby zobaczyć, jak używać tych poleceń. Możesz uruchomić dwa ślady i w jednym z nich śledzić, co się stanie, gdy rozpocznie się drugi. Sprawdź, czy nie ma filtra w kolumnie „Nazwa aplikacji” w samym profilerze.
Lista zdarzeń monitorowanych przez profilera jest bardzo duża i nie ogranicza się do odbierania tekstów zapytań. Istnieją zdarzenia, które śledzą pełne skanowanie, ponowne kompilowanie, automatyczne powiększanie, zakleszczenie i wiele więcej.
Analiza aktywności użytkownika na serwerze
Są różne sytuacje. Zapytanie może zawiesić się na „wykonaniu” przez długi czas i nie jest jasne, czy zostanie zakończone, czy nie. Chciałbym osobno przeanalizować problematyczne zapytanie; jednak najpierw musimy określić, jakie jest zapytanie. Nie ma sensu łapać go profilerem – już przegapiliśmy wydarzenie początkowe i nie jest jasne, jak długo czekać na zakończenie procesu.
Zastanówmy się
Być może słyszałeś o „Monitorze aktywności”. Jego wyższe edycje mają naprawdę bogatą funkcjonalność. Jak może nam pomóc? Monitor aktywności zawiera wiele przydatnych i interesujących funkcji. Wszystko, czego potrzebujemy, dostaniemy z widoków systemowych i funkcji. Samo monitorowanie jest przydatne, ponieważ możesz ustawić na nim profiler i zobaczyć, jakie zapytania wykonuje.
Będziemy potrzebować:
- dm_exec_sessions dostarcza informacji o sesjach podłączonych użytkowników. W naszym artykule przydatne pola to te, które identyfikują użytkownika (login_name, login_time, host_name, program_name, …) oraz pola z informacjami o wykorzystanych zasobach (cpu_time, reads, writes, memory_usage, …)
- dm_exec_requests dostarcza informacji o zapytaniach wykonywanych w danej chwili.
- session_id to identyfikator sesji, który ma być połączony z poprzednim widokiem.
- czas_startu to czas uruchomienia widoku.
- polecenie to pole, które zawiera typ wykonywanego polecenia. W przypadku zapytań użytkowników jest to select/update/delete/
- sql_handle, statement_start_offset, statement_end_offset dostarczają informacji do pobrania tekstu zapytania:handle, a także pozycji początkowej i końcowej w tekście zapytania, co oznacza część, która jest aktualnie wykonywana (w przypadku, gdy zapytanie zawiera kilka polecenia).
- plan_handle to uchwyt wygenerowanego planu.
- blocking_session_id wskazuje numer sesji, która spowodowała blokowanie, jeśli istnieją bloki, które uniemożliwiają wykonanie zapytania
- wait_type, wait_time, wait_resource to pola z informacją o przyczynie i czasie trwania oczekiwania. W przypadku niektórych typów waitów, np. blokady danych, konieczne jest dodatkowo wskazanie kodu do zablokowanego zasobu.
- percent_complete to procent ukończenia. Niestety jest dostępny tylko dla poleceń z wyraźnie przewidywalnym postępem (na przykład tworzenie kopii zapasowej lub przywracanie).
- Cpu_time, odczyty, zapisy, logiczne_odczyty, grant_query_memory to koszty zasobów.
- dm_exec_sql_text(sql_handle | plan_handle), sys.dm_exec_query_plan(plan_handle) to funkcje pobierania tekstu i planu wykonania. Poniżej rozważymy przykład jego użycia.
- dm_exec_query_stats to podsumowanie statystyk wykonywania zapytań. Wyświetla zapytanie, liczbę jego wykonań i ilość zużytych zasobów.
Ważne uwagi
Powyższa lista to tylko niewielka część. Pełna lista wszystkich widoków i funkcji systemu jest opisana w dokumentacji. Jest też piękny obraz przedstawiający schemat połączeń między głównymi obiektami.
Tekst zapytania, jego plan i statystyki wykonania to dane przechowywane w pamięci podręcznej procedur. Są dostępne w trakcie realizacji. Wtedy dostępność nie jest gwarantowana i zależy od obciążenia pamięci podręcznej. Tak, pamięć podręczną można wyczyścić ręcznie. Czasami jest to zalecane, gdy plany wykonania „wywróciły się”. Mimo to istnieje wiele niuansów.
Pole „polecenie” nie ma znaczenia dla żądań użytkowników, ponieważ możemy uzyskać pełny tekst. Jest to jednak bardzo ważne dla uzyskania informacji o procesach systemowych. Z reguły wykonują pewne zadania wewnętrzne i nie posiadają tekstu SQL. W przypadku takich procesów informacja o poleceniu jest jedyną wskazówką o rodzaju aktywności.
W komentarzach do poprzedniego artykułu pojawiło się pytanie o to, w co zaangażowany jest serwer, kiedy nie powinien działać. Odpowiedź będzie prawdopodobnie w znaczeniu tego pola. W mojej praktyce pole „polecenie” zawsze zapewniało coś całkiem zrozumiałego dla aktywnych procesów systemowych:autoshrink / autogrow / checkpoint / logwriter / itp.
Jak z niego korzystać
Przejdziemy do części praktycznej. Podam kilka przykładów jego użycia. Możliwości serwera nie są ograniczone – możesz wymyślić własne przykłady.
Przykład 1. Jaki proces zużywa procesor/odczyt/zapis/pamięć
Najpierw spójrz na sesje, które zużywają więcej zasobów, na przykład procesor. Możesz znaleźć te informacje w sys.dm_exec_sessions. Jednak dane dotyczące procesora, w tym odczyty i zapisy, kumulują się. Oznacza to, że numer zawiera sumę za cały czas połączenia. Oczywiste jest, że użytkownik, który połączył się miesiąc temu i nie został odłączony, będzie miał wyższą wartość. Nie oznacza to, że przeciążają system.
Kod z następującym algorytmem może rozwiązać ten problem:
- Dokonaj wyboru i zapisz go w tabeli tymczasowej
- Poczekaj chwilę
- Dokonaj wyboru po raz drugi
- Porównaj te wyniki. Ich różnica wskaże koszty poniesione w kroku 2.
- Dla wygody różnicę można podzielić przez czas trwania kroku 2 w celu uzyskania średnich „kosztów na sekundę”.
if object_id('tempdb..#tmp') is NULL
BEGIN
SELECT * into #tmp from sys.dm_exec_sessions s
PRINT 'wait for a second to collect statistics at the first run '
-- we do not wait for the next launches, because we compare with the result of the previous launch
WAITFOR DELAY '00:00:01';
END
if object_id('tempdb..#tmp1') is not null drop table #tmp1
declare @d datetime
declare @dd float
select @d = crdate from tempdb.dbo.sysobjects where id=object_id('tempdb..#tmp')
select * into #tmp1 from sys.dm_exec_sessions s
select @dd=datediff(ms,@d,getdate())
select @dd AS [time interval, ms]
SELECT TOP 30 s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff, convert(numeric(16,2),(s.cpu_time-isnull(t.cpu_time,0))/@dd*1000) as cpu_sec,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff, convert(numeric(16,2),(s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0))/@dd*1000) as totIO_sec,
s.reads-isnull(t.reads,0) as reads_Diff, convert(numeric(16,2),(s.reads-isnull(t.reads,0))/@dd*1000) as reads_sec,
s.writes-isnull(t.writes,0) as writes_Diff, convert(numeric(16,2),(s.writes-isnull(t.writes,0))/@dd*1000) as writes_sec,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff, convert(numeric(16,2),(s.logical_reads-isnull(t.logical_reads,0))/@dd*1000) as logical_reads_sec,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_D],
s.nt_user_name,s.nt_domain
from #tmp1 s
LEFT join #tmp t on s.session_id=t.session_id
order BY
cpu_Diff desc
--totIO_Diff desc
--logical_reads_Diff desc
drop table #tmp
GO
select * into #tmp from #tmp1
drop table #tmp1 W kodzie używam dwóch tabel:#tmp – dla pierwszego wyboru i #tmp1 – dla drugiego. Podczas pierwszego uruchomienia skrypt tworzy i wypełnia #tmp i #tmp1 w odstępie jednej sekundy, a następnie wykonuje inne zadania. Przy kolejnych uruchomieniach skrypt wykorzystuje wyniki poprzedniego wykonania jako podstawę do porównania. W związku z tym czas trwania kroku 2 będzie równy czasowi oczekiwania między uruchomieniami skryptu.
Spróbuj go wykonać, nawet na serwerze produkcyjnym. Skrypt utworzy tylko „tabele tymczasowe” (dostępne w ramach bieżącej sesji i usunięte po wyłączeniu) i nie ma wątku.
Ci, którzy nie lubią wykonywać zapytania w MS SSMS, mogą zapakować je w aplikację napisaną w ich ulubionym języku programowania. Pokażę ci, jak to zrobić w MS Excel bez ani jednej linii kodu.
W menu Dane połącz się z serwerem. Jeśli zostaniesz poproszony o wybranie tabeli, wybierz losową. Klikaj Dalej i Zakończ, aż pojawi się okno dialogowe Import danych. W tym oknie musisz kliknąć Właściwości. We właściwościach konieczne jest zastąpienie typu polecenia wartością SQL i wstawienie naszego zmodyfikowanego zapytania w polu tekstowym Polecenie.
Będziesz musiał trochę zmodyfikować zapytanie:
- Dodaj «USTAW NOCOUNT ON»
- Zastąp tabele tymczasowe tabelami zmiennymi
- Opóźnienie potrwa do 1 sek. Pola z wartościami uśrednionymi nie są wymagane
Zmodyfikowane zapytanie dla programu Excel
SET NOCOUNT ON;
declare @tmp table(session_id smallint primary key,login_time datetime,host_name nvarchar(256),program_name nvarchar(256),login_name nvarchar(256),nt_user_name nvarchar(256),cpu_time int,memory_usage int,reads bigint,writes bigint,logical_reads bigint,database_id smallint)
declare @d datetime;
select @d=GETDATE()
INSERT INTO @tmp(session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id)
SELECT session_id,login_time,host_name,program_name,login_name,nt_user_name,cpu_time,memory_usage,reads,writes,logical_reads,database_id
from sys.dm_exec_sessions s;
WAITFOR DELAY '00:00:01';
declare @dd float;
select @dd=datediff(ms,@d,getdate());
SELECT
s.session_id, s.host_name, db_name(s.database_id) as db, s.login_name,s.login_time,s.program_name,
s.cpu_time-isnull(t.cpu_time,0) as cpu_Diff,
s.reads+s.writes-isnull(t.reads,0)-isnull(t.writes,0) as totIO_Diff,
s.reads-isnull(t.reads,0) as reads_Diff,
s.writes-isnull(t.writes,0) as writes_Diff,
s.logical_reads-isnull(t.logical_reads,0) as logical_reads_Diff,
s.memory_usage, s.memory_usage-isnull(t.memory_usage,0) as [mem_Diff],
s.nt_user_name,s.nt_domain
from sys.dm_exec_sessions s
left join @tmp t on s.session_id=t.session_id Wynik:
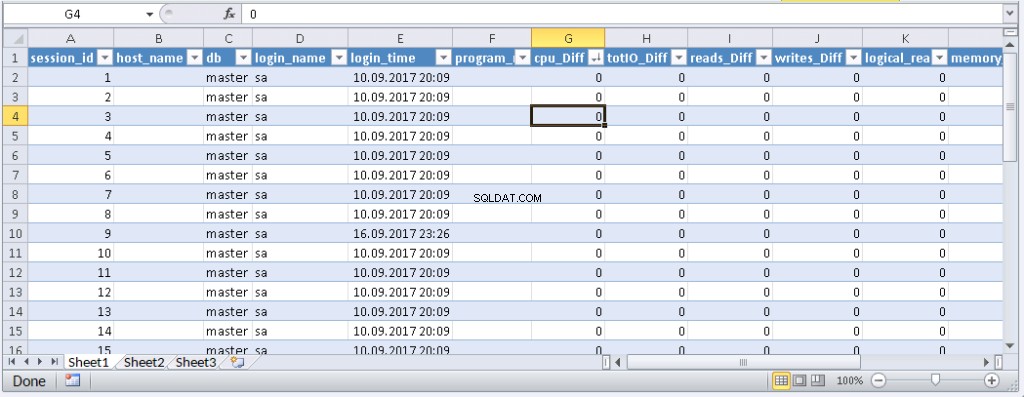
Gdy dane pojawią się w programie Excel, możesz je posortować według potrzeb. Aby zaktualizować informacje, kliknij „Odśwież”. W ustawieniach skoroszytu możesz umieścić „automatyczną aktualizację” w określonym czasie i „aktualizację na początku”. Możesz zapisać plik i przekazać go współpracownikom. W ten sposób stworzyliśmy wygodne i proste narzędzie.
Przykład 2. Na co sesja zużywa zasoby?
Teraz określimy, co właściwie robią sesje problemowe. Aby to zrobić, użyj sys.dm_exec_requests i funkcji, aby otrzymać tekst zapytania i plan zapytania.
Plan zapytania i wykonania według numeru sesji
DECLARE @sql_handle varbinary(64) DECLARE @plan_handle varbinary(64) DECLARE @sid INT Declare @statement_start_offset int, @statement_end_offset INT, @session_id SMALLINT -- for the information by a particular user – indicate a session number SELECT @sid=182 -- receive state variables for further processing IF @sid IS NOT NULL SELECT @sql_handle=der.sql_handle, @plan_handle=der.plan_handle, @statement_start_offset=der.statement_start_offset, @statement_end_offset=der.statement_end_offset, @session_id = der.session_id FROM sys.dm_exec_requests der WHERE example@sqldat.com -- print the text of the query being executed DECLARE @txt VARCHAR(max) IF @sql_handle IS NOT NULL SELECT @txt=[text] FROM sys.dm_exec_sql_text(@sql_handle) PRINT @txt -- output the plan of the batch/procedure being executed IF @plan_handle IS NOT NULL select * from sys.dm_exec_query_plan(@plan_handle) -- and the plan of the query being executed within the batch/procedure IF @plan_handle IS NOT NULL SELECT dbid, objectid, number, encrypted, CAST(query_plan AS XML) AS planxml from sys.dm_exec_text_query_plan(@plan_handle, @statement_start_offset, @statement_end_offset)
Wstaw numer sesji do zapytania i uruchom je. After execution, there will be plans on the Results tab (the first one is for the whole query, and the second one is for the current step if there are several steps in the query) and the query text on the Messages tab. To view the plan, you need to click the text that looks like the URL in the row. The plan will be opened in a separate tab. Sometimes, it happens that the plan is opened not in a graphical form, but in the form of XML-text. This may happen because the MS SSMS version is lower than the server. Delete the “Version” and “Build” from the first row and then save the result XML to a file with the .sqlplan extension. After that, open it separately. If this does not help, I remind you that the 2016 studio is officially available for free on the MS website.
It is obvious that the result plan will be an estimated one, as the query is being executed. Still, it is possible to receive some execution statistics. To do this, use the sys.dm_exec_query_stats view with the filter by our handles.
Add this information at the end of the previous query
-- plan statistics IF @sql_handle IS NOT NULL SELECT * FROM sys.dm_exec_query_stats QS WHERE example@sqldat.com_handle
As a result, we will get the information about the steps of the executed query:how many times they were executed and what resources were spent. This information is added to the statistics only after the execution process is completed. The statistics are not tied to the user but are maintained within the whole server. If different users execute the same query, the statistics will be total for all users.
Example 3. Can I see all of them?
Let’s combine the system views we considered with the functions in one query. It can be useful for evaluating the whole situation.
-- receive a list of all current queries SELECT LEFT((SELECT [text] FROM sys.dm_exec_sql_text(der.sql_handle)),500) AS txt --,(select top 1 1 from sys.dm_exec_query_profiles where session_id=der.session_id) as HasLiveStat ,der.blocking_session_id as blocker, DB_NAME(der.database_id) AS База, s.login_name, * from sys.dm_exec_requests der left join sys.dm_exec_sessions s ON s.session_id = der.session_id WHERE der.session_id<>@@SPID -- AND der.session_id>50
The query outputs a list of active sessions and texts of their queries. For system processes, usually, there is no query; however, the command field is filled up. You can see the information about blocks and waits, and mix this query with example 1 in order to sort by the load. Still, be careful, query texts may be large. Their massive selection can be resource-intensive and lead to a huge traffic increase. In the example, I limited the result query to the first 500 characters but did not execute the plan.
Wniosek
It would be great to get Live Query Statistics for an arbitrary session. According to the manufacturer, now, monitoring statistics requires many resources and therefore, it is disabled by default. Its enabling is not a problem, but additional manipulations complicate the process and reduce the practical benefit.
In this article, we analyzed user activity in the following ways:using possibilities MS SSMS, profiler, direct calls to system views. All these methods allow estimating costs on executing a query and getting the execution plan. Each method is suitable for a particular situation. Thus, the best solution is to combine them.