Najbardziej intuicyjny sposób aktualizacji bazy danych, jaki można sobie wyobrazić, to wygenerowanie repliki w nowej wersji i wykonanie w niej przełączenia awaryjnego aplikacji, i faktycznie działa doskonale w innych silnikach. W PostgreSQL było to kiedyś niemożliwe w natywny sposób. Aby dokonać aktualizacji, trzeba było pomyśleć o innych sposobach aktualizacji, takich jak użycie pg_upgrade, zrzucanie i przywracanie lub korzystanie z narzędzi innych firm, takich jak Slony lub Bucardo, z których wszystkie mają swoje własne zastrzeżenia. Wynika to ze sposobu, w jaki PostgreSQL używał do implementacji replikacji.
Replikacja strumieniowa PostgreSQL (powszechna replikacja PostgreSQL) to fizyczna replikacja, która replikuje zmiany na poziomie bajt po bajcie, tworząc identyczną kopię bazy danych na innym serwerze. Ta metoda ma wiele ograniczeń, gdy myślisz o aktualizacji, ponieważ po prostu nie możesz utworzyć repliki w innej wersji serwera lub nawet w innej architekturze.
Od PostgreSQL 10 zaimplementowano wbudowaną replikację logiczną, która w przeciwieństwie do replikacji fizycznej, można replikować między różnymi głównymi wersjami PostgreSQL. To oczywiście otwiera nowe drzwi dla strategii ulepszania.
W tym blogu zobaczymy, jak można zaktualizować PostgreSQL 11 do PostgreSQL 12 bez przestojów przy użyciu replikacji logicznej.
Replikacja logiczna PostgreSQL
Replikacja logiczna to metoda replikacji obiektów danych i ich zmian w oparciu o ich tożsamość replikacji (zwykle klucz podstawowy). Opiera się na trybie publikowania i subskrybowania, w którym jeden lub więcej subskrybentów subskrybuje jedną lub więcej publikacji w węźle wydawcy.
Publikacja to zestaw zmian wygenerowany z tabeli lub grupy tabel (nazywany również zbiorem replikacji). Węzeł, w którym zdefiniowana jest publikacja, jest określany jako wydawca. Subskrypcja jest następną stroną replikacji logicznej. Węzeł, w którym zdefiniowana jest subskrypcja, określany jest mianem subskrybenta i określa on połączenie z inną bazą danych oraz zbiorem publikacji (jedną lub więcej), które chce subskrybować. Subskrybenci pobierają dane z publikacji, które subskrybują.
Replikacja logiczna ma architekturę podobną do fizycznej replikacji strumieniowej. Jest realizowany przez procesy „walsender” i „apply”. Proces walsendera rozpoczyna logiczne dekodowanie WAL i ładuje standardową wtyczkę dekodowania logicznego. Wtyczka przekształca zmiany odczytane z WAL na protokół replikacji logicznej i filtruje dane zgodnie ze specyfikacją publikacji. Dane są następnie w sposób ciągły przesyłane za pomocą protokołu replikacji strumieniowej do procesu roboczego aplikacji, który mapuje dane do lokalnych tabel i stosuje poszczególne zmiany w miarę ich odbierania, w prawidłowej kolejności transakcyjnej.
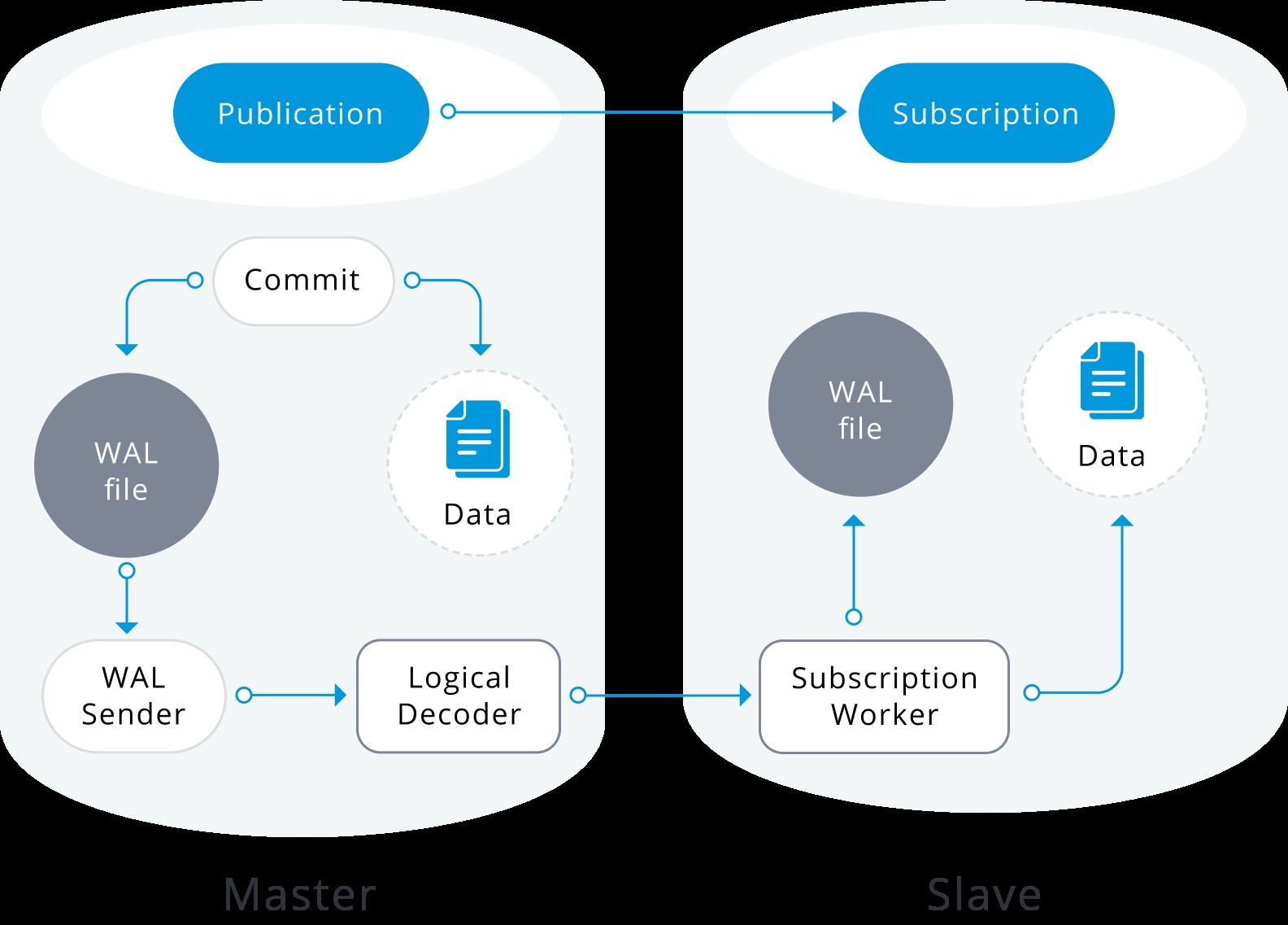
Replikacja logiczna rozpoczyna się od wykonania migawki danych w bazie danych wydawcy i kopiowanie tego do subskrybenta. Początkowe dane w istniejących subskrybowanych tabelach są zapisywane i kopiowane w równoległym wystąpieniu specjalnego rodzaju procesu stosowania. Ten proces utworzy własne tymczasowe gniazdo replikacji i skopiuje istniejące dane. Po skopiowaniu istniejących danych pracownik przechodzi w tryb synchronizacji, który zapewnia, że tabela zostanie przywrócona do stanu zsynchronizowanego z głównym procesem wprowadzania, przesyłając strumieniowo wszelkie zmiany, które zaszły podczas początkowego kopiowania danych, przy użyciu standardowej replikacji logicznej. Po zakończeniu synchronizacji kontrola nad replikacją tabeli jest przekazywana z powrotem do głównego procesu wprowadzania, w którym replikacja jest kontynuowana normalnie. Zmiany w wydawcy są wysyłane do subskrybenta w czasie rzeczywistym.
Jak zaktualizować PostgreSQL 11 do PostgreSQL 12 przy użyciu replikacji logicznej
Zamierzamy skonfigurować replikację logiczną między dwiema różnymi głównymi wersjami PostgreSQL (11 i 12) i oczywiście, gdy już to zadziała, wystarczy tylko wykonać awaryjne przełączanie aplikacji do baza danych z nowszą wersją.
Wykonamy następujące kroki, aby uruchomić replikację logiczną:
- Skonfiguruj węzeł wydawcy
- Skonfiguruj węzeł subskrybenta
- Utwórz użytkownika subskrybenta
- Utwórz publikację
- Utwórz strukturę tabeli w subskrybencie
- Utwórz subskrypcję
- Sprawdź stan replikacji
Więc zacznijmy.
Po stronie wydawcy skonfigurujemy następujące parametry w pliku postgresql.conf:
- listen_addresses: Na jakich adresach IP należy nasłuchiwać. Użyjemy „*” dla wszystkich.
- wal_level: Określa, ile informacji jest zapisywanych w WAL. Ustawimy go na „logiczny”.
- max_replication_slots :Określa maksymalną liczbę gniazd replikacji, które może obsługiwać serwer. Musi być ustawiony na co najmniej liczbę subskrypcji, które mają się połączyć, plus pewną rezerwę na synchronizację tabeli.
- max_wal_senders: Określa maksymalną liczbę jednoczesnych połączeń z serwerów w trybie gotowości lub strumieniowych klientów bazowych kopii zapasowych. Powinien być ustawiony na co najmniej taki sam jak max_replication_slots plus liczba fizycznych replik, które są połączone w tym samym czasie.
Pamiętaj, że niektóre z tych parametrów wymagały ponownego uruchomienia usługi PostgreSQL.
Plik pg_hba.conf również wymaga dostosowania, aby umożliwić replikację. Musisz zezwolić użytkownikowi replikacji na połączenie z bazą danych.
Więc na tej podstawie skonfigurujmy wydawcę (w tym przypadku serwer PostgreSQL 11) w następujący sposób:
postgresql.conf:
listen_addresses = '*'
wal_level = logical
max_wal_senders = 8
max_replication_slots = 4pg_hba.conf:
# TYPE DATABASE USER ADDRESS METHOD
host all rep1 10.10.10.131/32 md5
Musisz zmienić użytkownika (w tym przykładzie rep1), który będzie używany do replikacji, oraz adres IP 10.10.10.131/32 dla adresu IP odpowiadającego twojemu węzłowi PostgreSQL 12.
Po stronie subskrybenta wymaga również ustawienia max_replication_slots. W takim przypadku należy ustawić co najmniej liczbę subskrypcji, które zostaną dodane do subskrybenta.
Inne parametry, które również należy tutaj ustawić, to:
- max_logical_replication_workers :Określa maksymalną liczbę pracowników replikacji logicznej. Obejmuje to zarówno pracowników zastosowania, jak i pracowników synchronizacji tabeli. Logiczne procesy robocze replikacji są pobierane z puli zdefiniowanej przez max_worker_processes. Musi być ustawiona na co najmniej liczbę subskrypcji, ponownie plus pewną rezerwę na synchronizację tabeli.
- max_worker_processes :Ustawia maksymalną liczbę procesów w tle, które system może obsłużyć. Może zaistnieć potrzeba dostosowania, aby dostosować się do pracowników replikacji, co najmniej max_logical_replication_workers + 1. Ten parametr wymaga ponownego uruchomienia PostgreSQL.
Więc musisz skonfigurować subskrybenta (w tym przypadku serwer PostgreSQL 12) w następujący sposób:
postgresql.conf:
listen_addresses = '*'
max_replication_slots = 4
max_logical_replication_workers = 4
max_worker_processes = 8Ponieważ PostgreSQL 12 będzie wkrótce nowym węzłem podstawowym, powinieneś rozważyć dodanie w tym kroku parametrów wal_level i archive_mode, aby uniknąć ponownego ponownego uruchomienia usługi później.
wal_level = logical
archive_mode = onTe parametry będą przydatne, jeśli chcesz dodać nową replikę lub korzystać z kopii zapasowych PITR.
W wydawcy musisz utworzyć użytkownika, z którym połączy się subskrybent:
world=# CREATE ROLE rep1 WITH LOGIN PASSWORD '*****' REPLICATION;
CREATE ROLERola używana do połączenia replikacji musi mieć atrybut REPLICATION. Dostęp dla roli musi być skonfigurowany w pg_hba.conf i musi mieć atrybut LOGIN.
Aby móc skopiować dane początkowe, rola używana do połączenia replikacji musi mieć uprawnienie SELECT do opublikowanej tabeli.
world=# GRANT SELECT ON ALL TABLES IN SCHEMA public to rep1;
GRANTUtworzymy publikację pub1 w węźle wydawcy dla wszystkich tabel:
world=# CREATE PUBLICATION pub1 FOR ALL TABLES;
CREATE PUBLICATIONUżytkownik, który utworzy publikację, musi mieć uprawnienie CREATE w bazie danych, ale aby utworzyć publikację, która automatycznie publikuje wszystkie tabele, użytkownik musi być superużytkownikiem.
W celu potwierdzenia utworzonej publikacji skorzystamy z katalogu pg_publication. Ten katalog zawiera informacje o wszystkich publikacjach utworzonych w bazie danych.
world=# SELECT * FROM pg_publication;
-[ RECORD 1 ]+-----
pubname | pub1
pubowner | 10
puballtables | t
pubinsert | t
pubupdate | t
pubdelete | t
pubtruncate | tOpisy kolumn:
- nazwa wydawcy :Nazwa publikacji.
- właściciel :Właściciel publikacji.
- tabele wydawnicze :Jeśli tak, ta publikacja automatycznie uwzględnia wszystkie tabele w bazie danych, w tym te, które zostaną utworzone w przyszłości.
- wstawka publikacji :Jeśli prawda, operacje INSERT są replikowane dla tabel w publikacji.
- aktualizacja publikacji :Jeśli prawda, operacje UPDATE są replikowane dla tabel w publikacji.
- pubdelete :Jeśli prawda, operacje DELETE są replikowane dla tabel w publikacji.
- opublikuj :Jeśli prawda, operacje TRUNCATE są replikowane dla tabel w publikacji.
Ponieważ schemat nie jest replikowany, musisz wykonać kopię zapasową w PostgreSQL 11 i przywrócić ją w swoim PostgreSQL 12. Kopia zapasowa zostanie wykonana tylko dla schematu, ponieważ informacje zostaną zreplikowane w początkowym transfer.
W PostgreSQL 11:
$ pg_dumpall -s > schema.sqlW PostgreSQL 12:
$ psql -d postgres -f schema.sqlGdy masz już swój schemat w PostgreSQL 12, musisz utworzyć subskrypcję, zastępując wartości host, dbname, user i password tymi, które odpowiadają Twojemu środowisku.
PostgreSQL 12:
world=# CREATE SUBSCRIPTION sub1 CONNECTION 'host=10.10.10.130 dbname=world user=rep1 password=*****' PUBLICATION pub1;
NOTICE: created replication slot "sub1" on publisher
CREATE SUBSCRIPTIONPowyższe działanie rozpocznie proces replikacji, który synchronizuje początkową zawartość tabel w publikacji, a następnie rozpoczyna replikację przyrostowych zmian w tych tabelach.
Użytkownik tworzący subskrypcję musi być superużytkownikiem. Proces ubiegania się o subskrypcję zostanie uruchomiony w lokalnej bazie danych z uprawnieniami superużytkownika.
W celu weryfikacji utworzonej subskrypcji możesz skorzystać z katalogu pg_stat_subscription. Ten widok będzie zawierał jeden wiersz na subskrypcję dla głównego pracownika (z pustym numerem PID, jeśli pracownik nie jest uruchomiony) oraz dodatkowe wiersze dla pracowników obsługujących początkową kopię danych subskrybowanych tabel.
world=# SELECT * FROM pg_stat_subscription;
-[ RECORD 1 ]---------+------------------------------
subid | 16422
subname | sub1
pid | 476
relid |
received_lsn | 0/1771668
last_msg_send_time | 2020-09-29 17:40:34.711411+00
last_msg_receipt_time | 2020-09-29 17:40:34.711533+00
latest_end_lsn | 0/1771668
latest_end_time | 2020-09-29 17:40:34.711411+00Opisy kolumn:
- subid :OID subskrypcji.
- podnazwa :Nazwa subskrypcji.
- pid :Identyfikator procesu procesu roboczego subskrypcji.
- prawda :OID relacji, którą synchronizuje pracownik; null dla głównego pracownika aplikacji.
- received_lsn :Ostatnia odebrana lokalizacja dziennika zapisu z wyprzedzeniem, początkowa wartość tego pola to 0.
- last_msg_send_time :Czas wysłania ostatniej wiadomości otrzymanej od oryginalnego nadawcy WAL.
- last_msg_receipt_time :Czas otrzymania ostatniej wiadomości od nadawcy WAL.
- latest_end_lsn :Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem zgłoszona do pierwotnego nadawcy WAL.
- latest_end_time :Czas ostatniej lokalizacji dziennika zapisu z wyprzedzeniem zgłoszony do pierwotnego nadawcy WAL.
Aby zweryfikować stan replikacji w węźle podstawowym, możesz użyć pg_stat_replication:
world=# SELECT * FROM pg_stat_replication;
-[ RECORD 1 ]----+------------------------------
pid | 527
usesysid | 16428
usename | rep1
application_name | sub1
client_addr | 10.10.10.131
client_hostname |
client_port | 35570
backend_start | 2020-09-29 17:40:04.404905+00
backend_xmin |
state | streaming
sent_lsn | 0/1771668
write_lsn | 0/1771668
flush_lsn | 0/1771668
replay_lsn | 0/1771668
write_lag |
flush_lag |
replay_lag |
sync_priority | 0
sync_state | asyncOpisy kolumn:
- pid :Identyfikator procesu procesu nadawcy WAL.
- usesysid :OID użytkownika zalogowanego w tym procesie nadawcy WAL.
- nazwa użytkownika :Nazwa użytkownika zalogowanego w tym procesie nadawcy WAL.
- nazwa_aplikacji :Nazwa aplikacji, która jest połączona z tym nadawcą WAL.
- client_addr :adres IP klienta połączonego z tym nadawcą WAL. Jeśli to pole ma wartość NULL, oznacza to, że klient jest połączony przez gniazdo Unix na serwerze.
- nazwa_hosta_klienta :Nazwa hosta podłączonego klienta, zgłoszona przez odwrotne wyszukiwanie DNS client_addr. To pole nie będzie puste tylko dla połączeń IP i tylko wtedy, gdy log_hostname jest włączony.
- port_klienta :Numer portu TCP, którego klient używa do komunikacji z tym nadawcą WAL, lub -1, jeśli używane jest gniazdo Unix.
- backend_start :Czas rozpoczęcia tego procesu.
- backend_xmin :Horyzont xmin tego trybu gotowości zgłaszany przez hot_standby_feedback.
- stan :Bieżący stan nadawcy WAL. Możliwe wartości to:uruchamianie, przechwytywanie, przesyłanie strumieniowe, tworzenie kopii zapasowych i zatrzymywanie.
- sent_lsn :Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem wysłana w tym połączeniu.
- write_lsn :Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem zapisana na dysku przez ten serwer rezerwowy.
- flush_lsn :Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem opróżniona na dysk przez ten serwer rezerwowy.
- replay_lsn :Ostatnia lokalizacja dziennika zapisu z wyprzedzeniem odtworzona w bazie danych na tym serwerze rezerwowym.
- write_lag :Czas, jaki upłynął od lokalnego opróżnienia ostatniego WAL-a do otrzymania powiadomienia, że ten serwer rezerwowy go zapisał (ale jeszcze go nie opróżnił ani nie zastosował).
- flush_lag :Czas, jaki upłynął od lokalnego opróżnienia ostatniego WAL-a do otrzymania powiadomienia, że ten serwer rezerwowy go zapisał i opróżnił (ale jeszcze go nie zastosował).
- replay_lag :Czas, jaki upłynął od lokalnego opróżnienia ostatniego WAL-a do otrzymania powiadomienia, że ten serwer rezerwowy zapisał, opróżnił i zastosował go.
- sync_priority :Priorytet tego serwera rezerwowego, który zostanie wybrany jako synchroniczny tryb gotowości w replikacji synchronicznej opartej na priorytetach.
- sync_state :Synchroniczny stan tego serwera w trybie gotowości. Możliwe wartości to async, potencjał, synchronizacja, kworum.
Aby sprawdzić, kiedy pierwszy transfer się zakończył, możesz sprawdzić log PostgreSQL subskrybenta:
2020-09-29 17:40:04.403 UTC [476] LOG: logical replication apply worker for subscription "sub1" has started
2020-09-29 17:40:04.411 UTC [477] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has started
2020-09-29 17:40:04.422 UTC [478] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has started
2020-09-29 17:40:04.516 UTC [477] LOG: logical replication table synchronization worker for subscription "sub1", table "city" has finished
2020-09-29 17:40:04.522 UTC [479] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has started
2020-09-29 17:40:04.570 UTC [478] LOG: logical replication table synchronization worker for subscription "sub1", table "country" has finished
2020-09-29 17:40:04.676 UTC [479] LOG: logical replication table synchronization worker for subscription "sub1", table "countrylanguage" has finishedLub sprawdzenie zmiennej srsubstate w katalogu pg_subscription_rel. Ten katalog zawiera stan dla każdej replikowanej relacji w każdej subskrypcji.
world=# SELECT * FROM pg_subscription_rel;
srsubid | srrelid | srsubstate | srsublsn
---------+---------+------------+-----------
16422 | 16386 | r | 0/1771630
16422 | 16392 | r | 0/1771630
16422 | 16399 | r | 0/1771668
(3 rows)Opisy kolumn:
- srsubid :Odniesienie do subskrypcji.
- srrelid :Odniesienie do relacji.
- srsubstate :Kod stanu:i =inicjuj, d =dane są kopiowane, s =zsynchronizowane, r =gotowe (normalna replikacja).
- srsublsn :Zakończ LSN dla stanów s i r.
Możesz wstawić kilka rekordów testowych do swojego PostgreSQL 11 i sprawdzić, czy masz je w swoim PostgreSQL 12:
PostgreSQL 11:
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5001,'city1','USA','District1',10000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5002,'city2','ITA','District2',20000);
INSERT 0 1
world=# INSERT INTO city (id,name,countrycode,district,population) VALUES (5003,'city3','CHN','District3',30000);
INSERT 0 1PostgreSQL 12:
world=# SELECT * FROM city WHERE id>5000;
id | name | countrycode | district | population
------+-------+-------------+-----------+------------
5001 | city1 | USA | District1 | 10000
5002 | city2 | ITA | District2 | 20000
5003 | city3 | CHN | District3 | 30000
(3 rows)W tym momencie masz wszystko gotowe, aby skierować Twoją aplikację do PostgreSQL 12.
W tym celu przede wszystkim musisz potwierdzić, że nie masz opóźnienia replikacji.
W węźle głównym:
world=# SELECT application_name, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) lag FROM pg_stat_replication;
-[ RECORD 1 ]----+-----
application_name | sub1
lag | 0A teraz wystarczy zmienić punkt końcowy z aplikacji lub systemu równoważenia obciążenia (jeśli go posiadasz) na nowy serwer PostgreSQL 12.
Jeśli masz load balancer, taki jak HAProxy, możesz go skonfigurować, używając PostgreSQL 11 jako aktywnego i PostgreSQL 12 jako kopii zapasowej, w ten sposób:
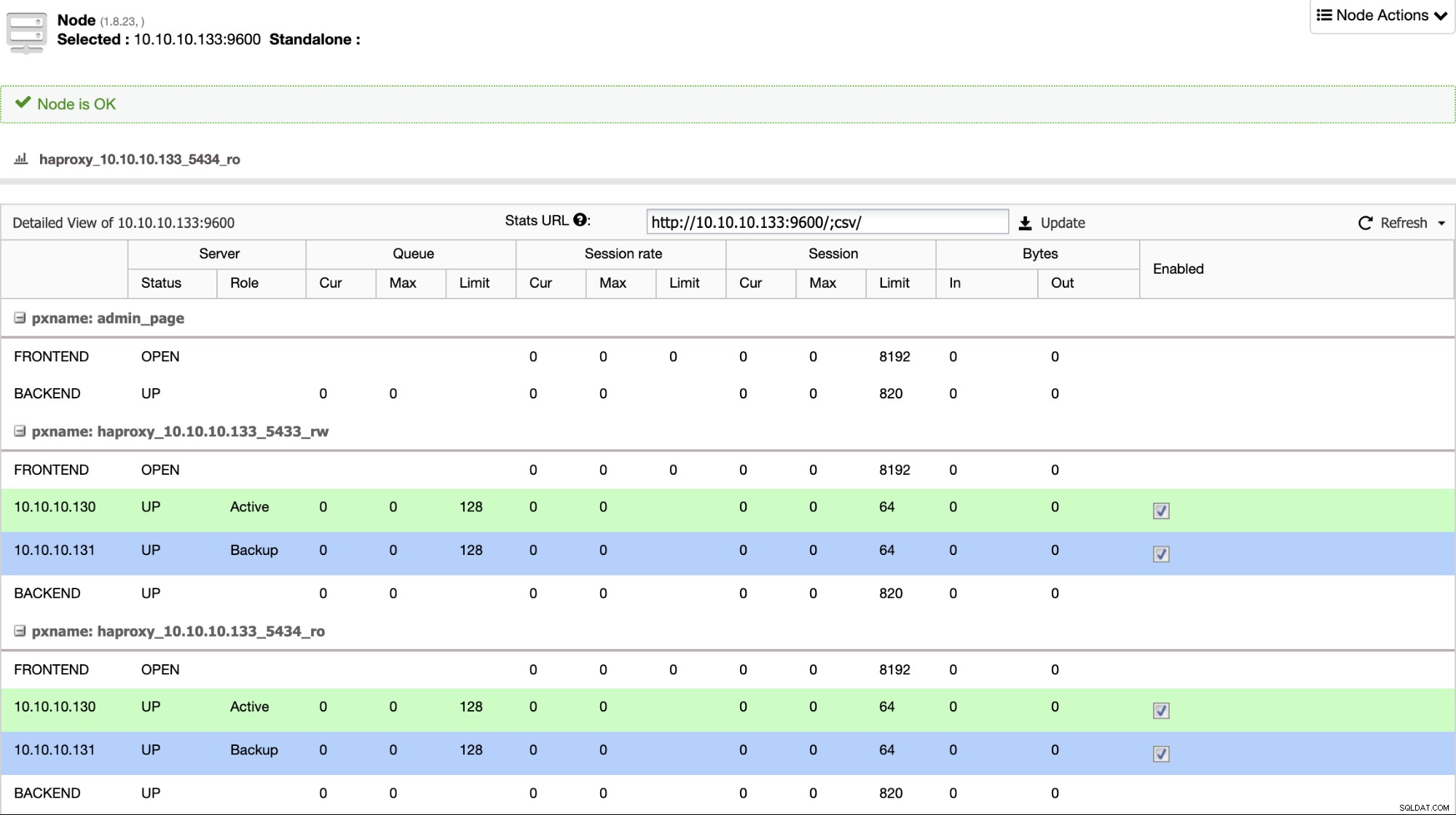
Jeśli po prostu zamkniesz stary węzeł podstawowy w PostgreSQL 11, serwer kopii zapasowej, w tym przypadku w PostgreSQL 12, zaczyna odbierać ruch w sposób przejrzysty dla użytkownika/aplikacji.
Pod koniec migracji możesz usunąć subskrypcję w nowym węźle podstawowym w PostgreSQL 12:
world=# DROP SUBSCRIPTION sub1;
NOTICE: dropped replication slot "sub1" on publisher
DROP SUBSCRIPTIONI sprawdź, czy został poprawnie usunięty:
world=# SELECT * FROM pg_subscription_rel;
(0 rows)
world=# SELECT * FROM pg_stat_subscription;
(0 rows)Ograniczenia
Przed użyciem replikacji logicznej pamiętaj o następujących ograniczeniach:
- Schemat bazy danych i polecenia DDL nie są replikowane. Początkowy schemat można skopiować za pomocą pg_dump --schema-only.
- Dane sekwencji nie są replikowane. Dane w kolumnach serii lub tożsamości poparte sekwencjami będą replikowane jako część tabeli, ale sama sekwencja nadal będzie pokazywać wartość początkową subskrybenta.
- Replikacja poleceń TRUNCATE jest obsługiwana, ale należy zachować ostrożność podczas obcinania grup tabel połączonych kluczami obcymi. Podczas replikacji akcji obcinania subskrybent obcina tę samą grupę tabel, która została obcięta u wydawcy, jawnie określonej lub niejawnie zebranej za pomocą funkcji CASCADE, z pominięciem tabel, które nie są częścią subskrypcji. Będzie to działać poprawnie, jeśli wszystkie tabele, których dotyczy problem, są częścią tej samej subskrypcji. Ale jeśli niektóre tabele subskrybenta, które mają zostać obcięte, mają łącza klucza obcego do tabel, które nie są częścią tej samej (lub żadnej) subskrypcji, wówczas zastosowanie akcji obcinania na subskrybenta nie powiedzie się.
- Duże obiekty nie są replikowane. Nie ma na to obejścia, poza przechowywaniem danych w normalnych tabelach.
- Replikacja jest możliwa tylko z tabel podstawowych do tabel podstawowych. Oznacza to, że tabele po stronie publikacji i po stronie subskrypcji muszą być tabelami normalnymi, a nie widokami, widokami zmaterializowanymi, tabelami głównymi partycji lub tabelami obcymi. W przypadku partycji można replikować hierarchię partycji jeden do jednego, ale obecnie nie można replikować do innej konfiguracji partycjonowanej.
Wnioski
Utrzymywanie aktualnego serwera PostgreSQL poprzez regularne aktualizacje było koniecznym, ale trudnym zadaniem aż do wersji PostgreSQL 10. Na szczęście teraz jest to inna historia dzięki logicznej replikacji.
W tym blogu przedstawiliśmy krótkie wprowadzenie do replikacji logicznej, funkcji PostgreSQL wprowadzonej natywnie w wersji 10, i pokazaliśmy, jak może ona pomóc w przeprowadzeniu aktualizacji z PostgreSQL 11 do PostgreSQL 12 przy strategii zerowych przestojów.