Wprowadzenie
W tym artykule omówimy, jak różne typy indeksów w tabelach SQL Server zoptymalizowanych pod kątem pamięci wpływają na wydajność. Przeanalizujemy przykłady, jak różne typy indeksów mogą wpływać na wydajność tabel zoptymalizowanych pod kątem pamięci.
Aby ułatwić dyskusję na dany temat, posłużymy się dość obszernym przykładem. Dla uproszczenia ten przykład będzie zawierał różne repliki jednej tabeli, dla których będziemy uruchamiać różne zapytania. Repliki te będą używać różnych indeksów lub w ogóle ich nie używać (poza oczywiście kluczami podstawowymi – PK).
Należy zauważyć, że faktycznym celem tego artykułu nie jest porównywanie wydajności między tabelami dyskowymi i zoptymalizowanymi pod kątem pamięci w programie SQL Server per se. Jego celem jest zbadanie, jak indeksy wpływają na wydajność w tabelach zoptymalizowanych pod kątem pamięci. Jednak, aby mieć pełny obraz eksperymentów, dostępne są również czasy dla odpowiednich zapytań w tabelach opartych na dyskach, a przyspieszenia są obliczane przy użyciu najbardziej optymalnej konfiguracji tabel opartych na dyskach jako linii bazowych.
Scenariusz
Przykładowe dane dla naszego scenariusza są oparte na pojedynczej tabeli zdefiniowanej w następujący sposób:
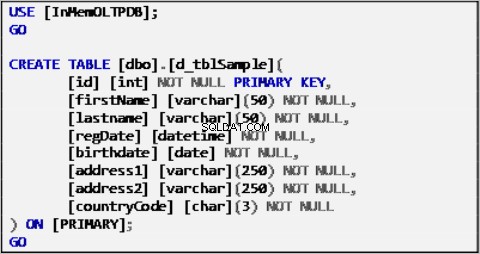
Lista 1:Przykładowa tabela źródeł danych.
Powyższa tabela została wypełniona przykładowymi danymi i będzie działać jako źródło danych dla pozostałych tabel.
Tak więc w oparciu o powyższą tabelę tworzymy następujące 9 odmian tabeli i wypełniamy je tymi samymi przykładowymi danymi:
- 3 tabele dyskowe:
- d_tblSample1
- Indeks klastrowy w kolumnie „id” – klucz podstawowy (PK)
- d_tblSample2
- Indeks klastrowy w kolumnie „id” (PK)
- Indeks nieklastrowy w kolumnie „countryCode”
- d_tblSample3
- Indeks klastrowy w kolumnie „id” (PK)
- Indeksy nieklastrowe w kolumnie „regDate”
- Indeksy nieklastrowe w kolumnie „countryCode”
- d_tblSample1
- 3 tabele zoptymalizowane pod kątem pamięci (zestaw 1:indeksy skrótu):
- m1_tblSample1
- Nieklastrowy indeks skrótu w kolumnie „id” – klucz podstawowy (PK)
- m1_tblSample2
- Nieklastrowy indeks skrótu w kolumnie „id” (PK)
- Indeks skrótu w kolumnie „countryCode”
- m1_tblSample3
- Nieklastrowy indeks skrótu w kolumnie „id” (PK)
- Indeks skrótu w kolumnie „regDate”
- Indeks skrótu w kolumnie „countryCode”
- 3 tabele zoptymalizowane pod kątem pamięci (zestaw 2:indeksy nieklastrowane):
- m2_tblSample1
- Indeks nieklastrowy w kolumnie „id” – klucz podstawowy (PK)
- m2_tblSample2
- Indeks nieklastrowy w kolumnie „id” (PK)
- Indeks nieklastrowy w kolumnie „countryCode”
- m2_tblSample3
- Indeks nieklastrowy w kolumnie „id” (PK)
- Indeks nieklastrowy w kolumnie „regDate”
- Indeks nieklastrowy w kolumnie „countryCode”
- m2_tblSample1
- m1_tblSample1
W poniższych zestawieniach można znaleźć definicje powyższych tabel.
Logika scenariusza polega na tym, że wykonujemy różne operacje na bazie danych w odniesieniu do odmian tej samej tabeli (ale z różnymi indeksami) i obserwujemy, jak w każdym przypadku wpływa to na wydajność.
Definicje
Tabele dyskowe
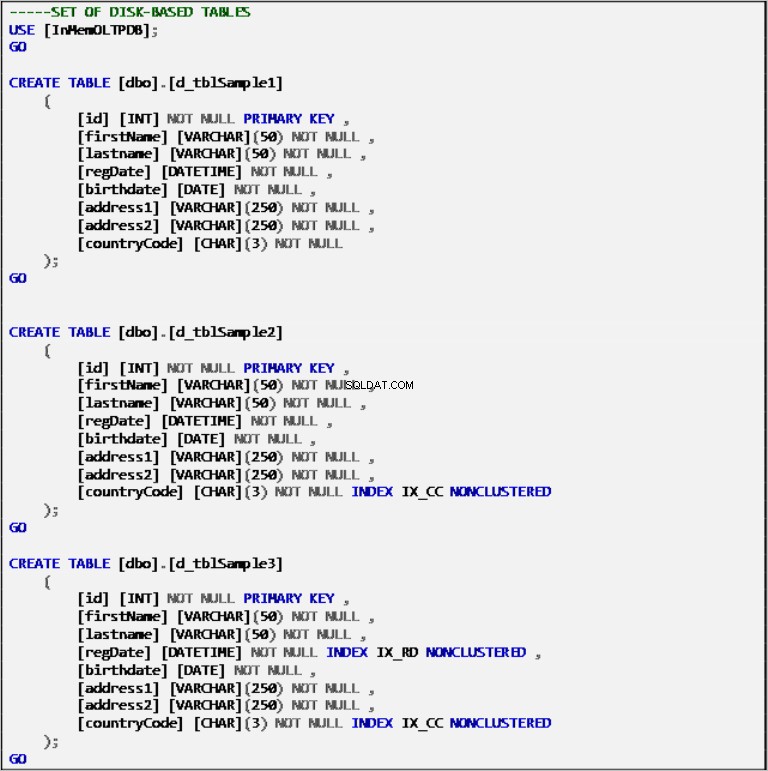
Listing 2:Definicja tabel opartych na dyskach.
Tabele zoptymalizowane pod kątem pamięci (zestaw 1:indeksy haszujące)

Listing 3:Tabele zoptymalizowane pod kątem pamięci – zestaw 1 (indeksy haszujące).
Tabele zoptymalizowane pod kątem pamięci (zestaw 2:indeksy nieklastrowane)

Listing 4:Tabele zoptymalizowane pod kątem pamięci – zestaw 2 (indeksy nieklastrowane).
Następnie wypełniamy wszystkie powyższe tabele tymi samymi przykładowymi danymi, co daje łącznie 5 milionów rekordów w każdej tabeli.
Oto wynik polecenia count dla każdego zestawu tabel:
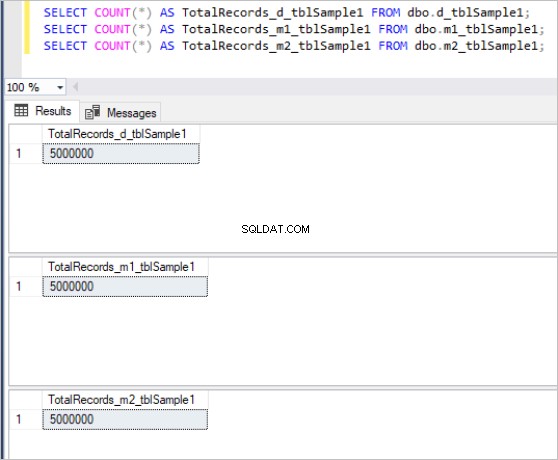
Rysunek 1:Całkowita liczba rekordów dla pierwszego zestawu tabel.
Rysunek 2:Całkowita liczba rekordów dla drugiego zestawu tabel.
Rysunek 3:Całkowita liczba rekordów dla trzeciego zestawu tabel.
Zapytania i realizacje scenariuszy
Teraz uruchomimy zestaw zapytań w odniesieniu do powyższych tabel i zobaczymy, jak działa każda tabela.
Te zapytania wykonują następujące operacje:
- Zapytanie 1:Agregacja (GROUP BY)
- Zapytanie 2:Wyszukiwanie indeksowe na podstawie predykatów równości
- Zapytanie 3:Poszukiwanie indeksowe dotyczące predykatów równości i nierówności
Planowane jest wykonanie zapytań jak poniżej:
Zapytanie 1 – Wykonanie względem następujących tabel:
- d_tblPrzykład3
- m1_tblPrzykład3
- m2_tblPrzykład3
- m1_tblSample1 (brak indeksu w kolumnach docelowych)
- m2_tblSample1 (brak indeksu w kolumnach docelowych)
Zapytanie 2 – Wykonanie względem następujących tabel:
- d_tblPrzykład2
- m1_tblPrzykład2
- m2_tblPrzykład2
- m1_tblSample1 (brak indeksu w kolumnach docelowych)
- m2_tblSample1 (brak indeksu w kolumnach docelowych)
Zapytanie 3 – Wykonanie względem następujących tabel:
- d_tblPrzykład3
- m1_tblPrzykład3
- m2_tblPrzykład3
- m1_tblSample1 (brak indeksu w kolumnach docelowych)
- m2_tblSample1 (brak indeksu w kolumnach docelowych)
Uwaga :mimo że definicja d_tblSample1 Tabela oparta na dyskach jest zawarta w powyższych definicjach tabeli, nie jest używana w zapytaniach przedstawionych w tym artykule. Powodem jest to, że w każdym scenariuszu używana jest najbardziej optymalna możliwa konfiguracja dla tabeli opartej na dyskach, ponieważ chcemy, aby nasza linia bazowa była jak najszybsza, gdy porównujemy ją z wydajnością tabel zoptymalizowanych pod kątem pamięci. W tym celu d_tblSample1 tabela jest prezentowana tylko w celach informacyjnych.
Poniżej znajdziesz skrypty T-SQL dla trzech zapytań wraz z mechanizmami pomiaru czasu wykonania.

Listing 5:Zapytanie 1 – Agregacja (z indeksami).
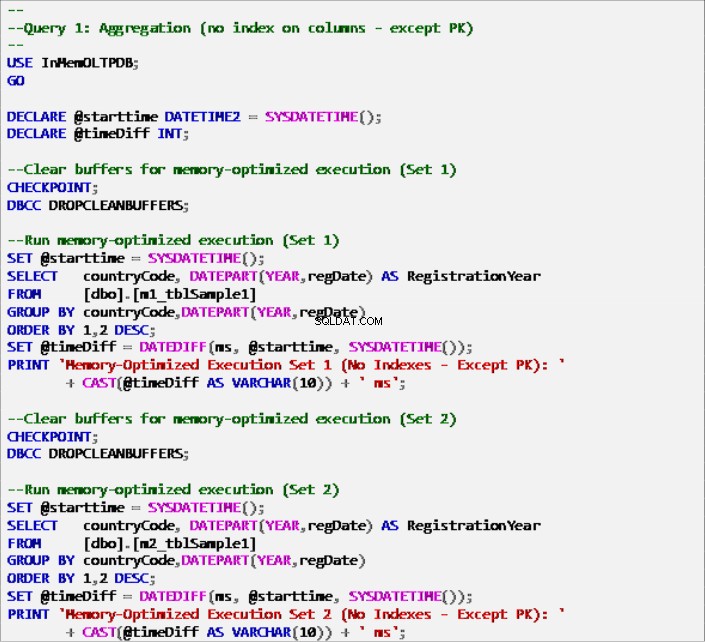
Listing 6:Zapytanie 1 – Agregacja (bez indeksów – z wyjątkiem klucza podstawowego).
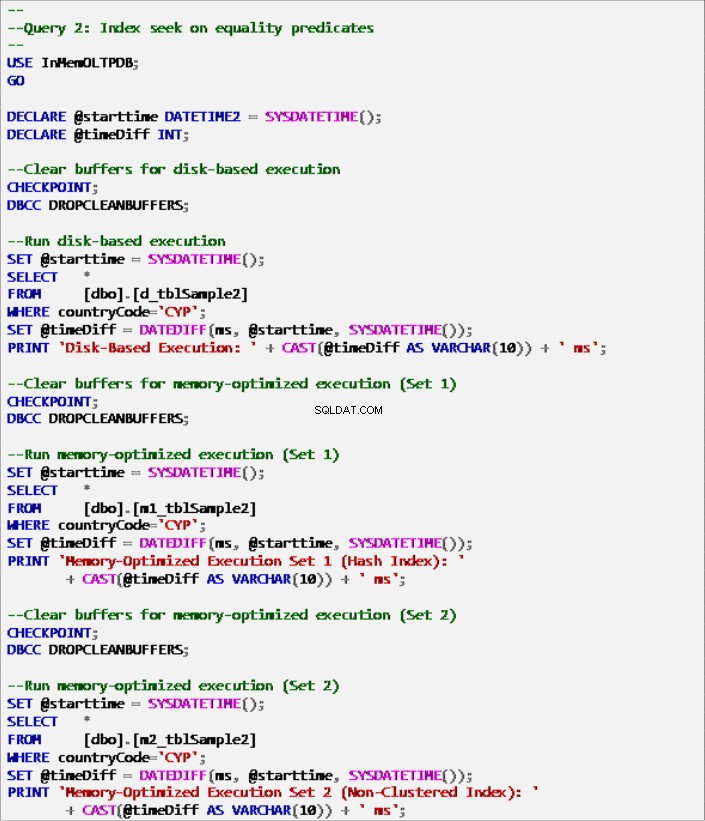
Listing 7:Zapytanie 2 – Wyszukiwanie indeksów w predykatach równości (z indeksami).

Listing 8:Zapytanie 2 – Wyszukiwanie indeksu w predykatach równości (bez indeksów – z wyjątkiem klucza podstawowego).
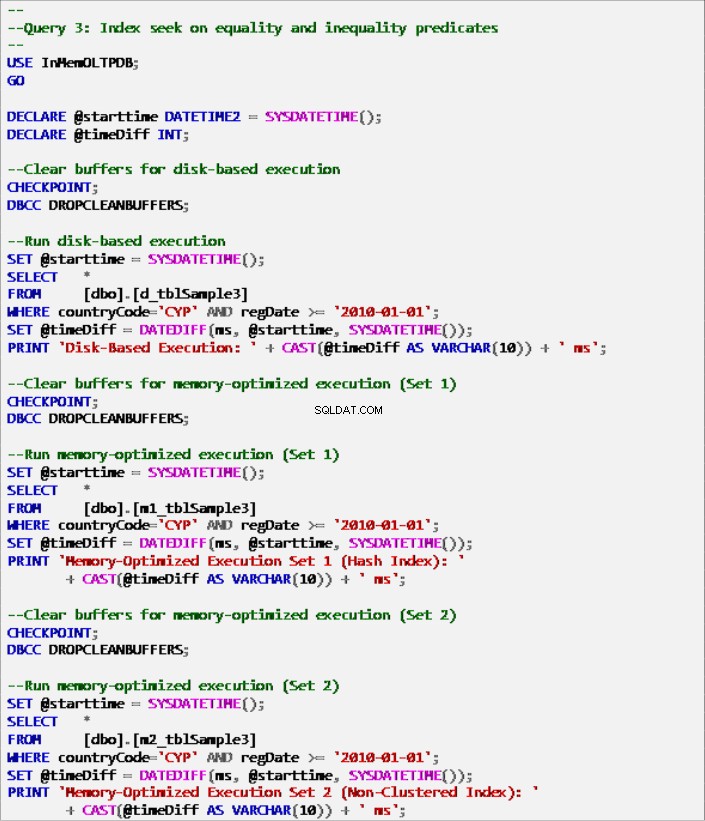
Listing 9:Zapytanie 3 – Wyszukiwanie indeksów dotyczące predykatów równości i nierówności (z indeksami).

Listing 10:Zapytanie 3 – Wyszukiwanie indeksu dotyczące predykatów równości i nierówności (bez indeksów – z wyjątkiem klucza podstawowego).
Poniższe zrzuty ekranu pokazują wyniki każdego wykonania zapytania:
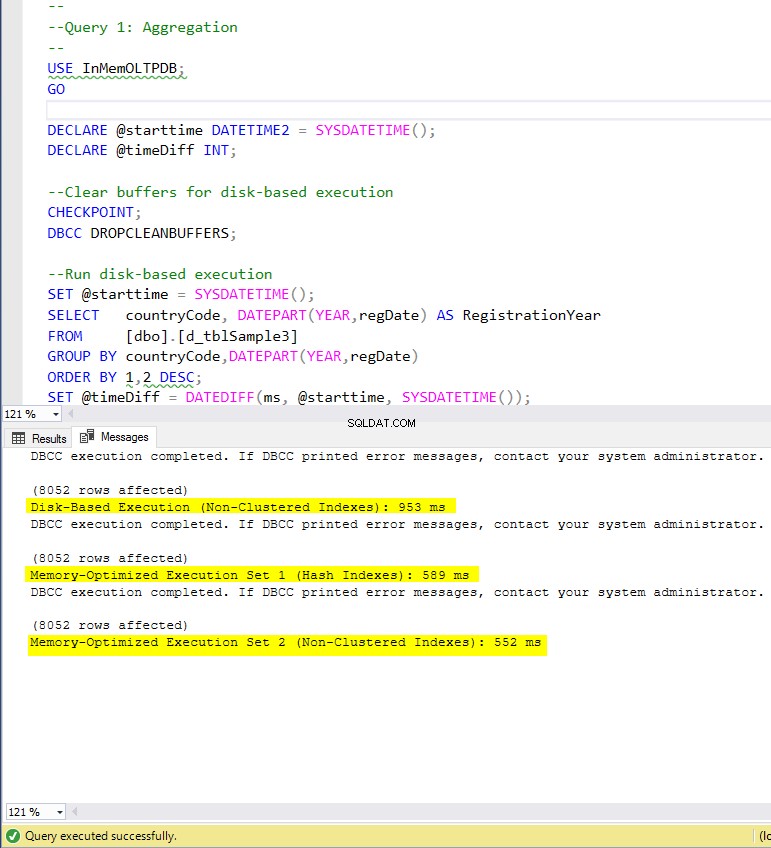
Rysunek 4:Czas wykonania zapytania 1 (z indeksami).
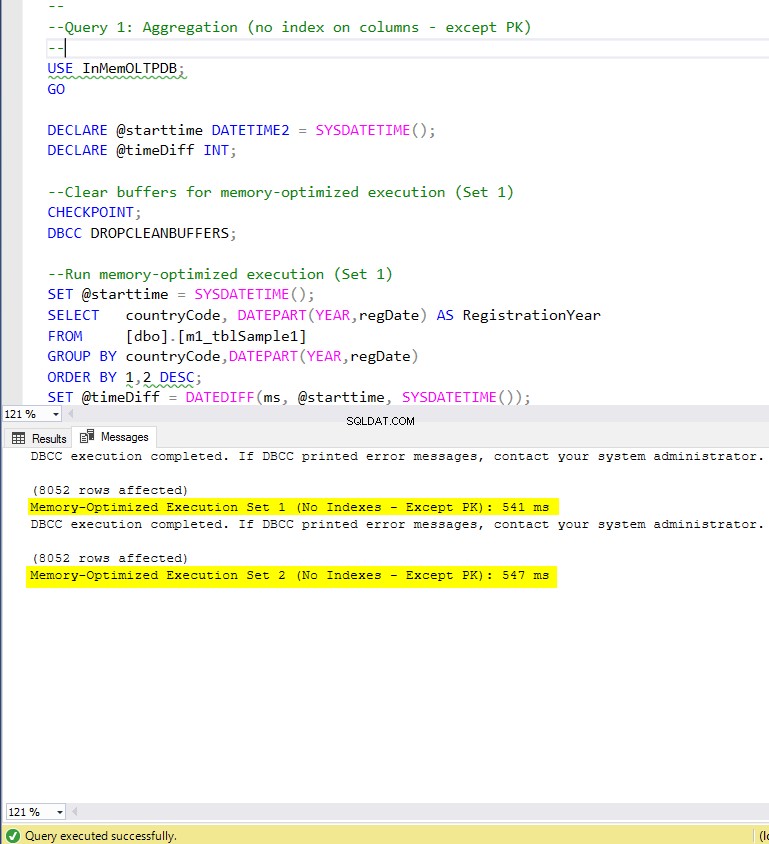
Rysunek 5:Czas wykonania zapytania 1 (bez indeksów – z wyjątkiem PK).
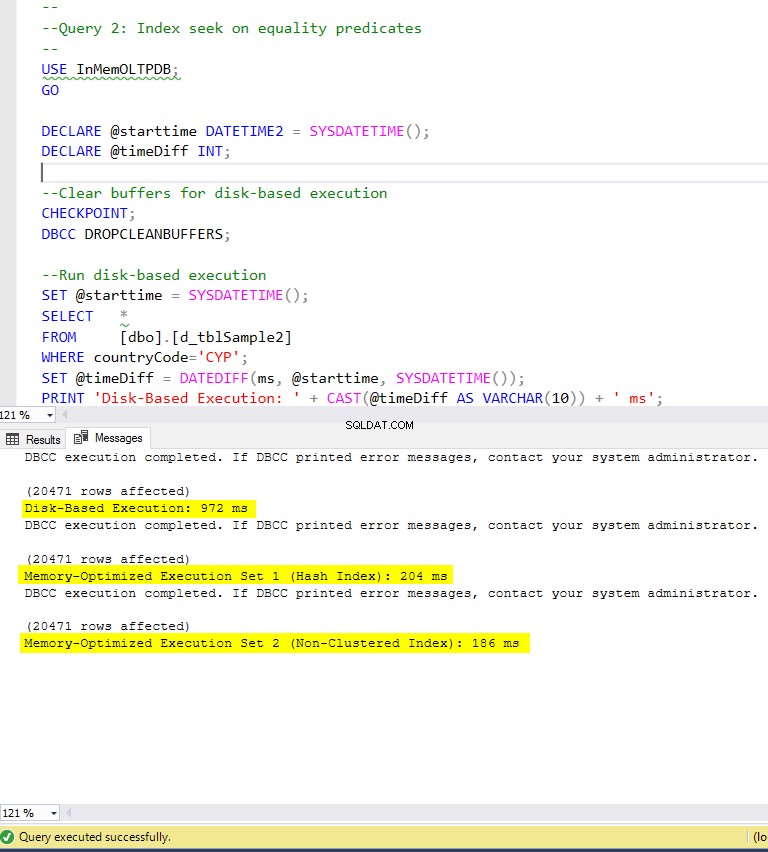
Rysunek 6:Czas wykonania zapytania 2 (z indeksami).
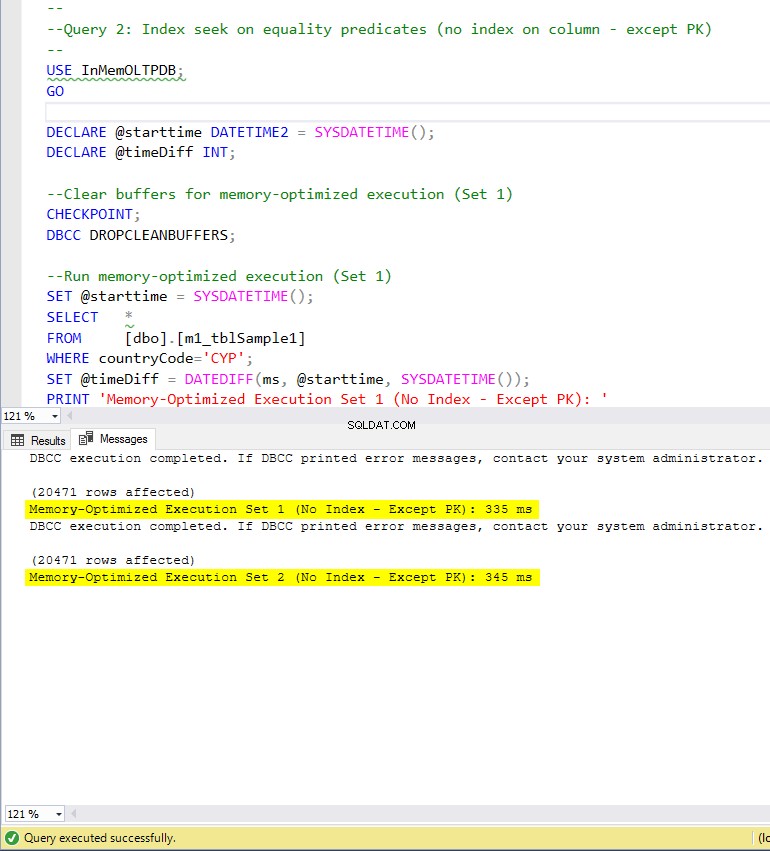
Rysunek 7:Czas wykonania zapytania 2 (bez indeksów – z wyjątkiem PK).
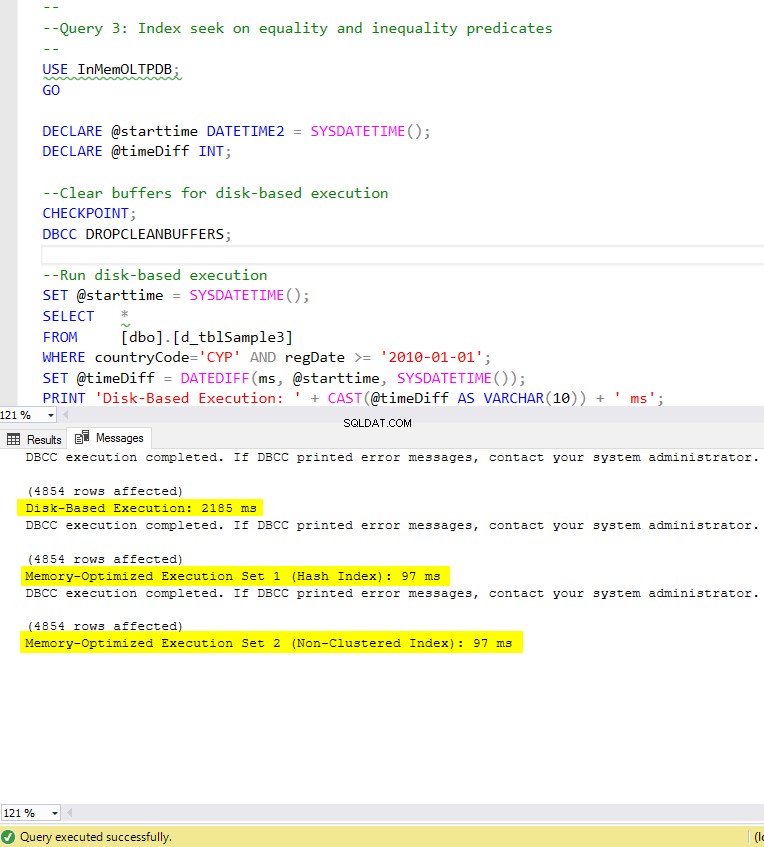
Rysunek 8:Czas wykonania zapytania 3 (z indeksami).
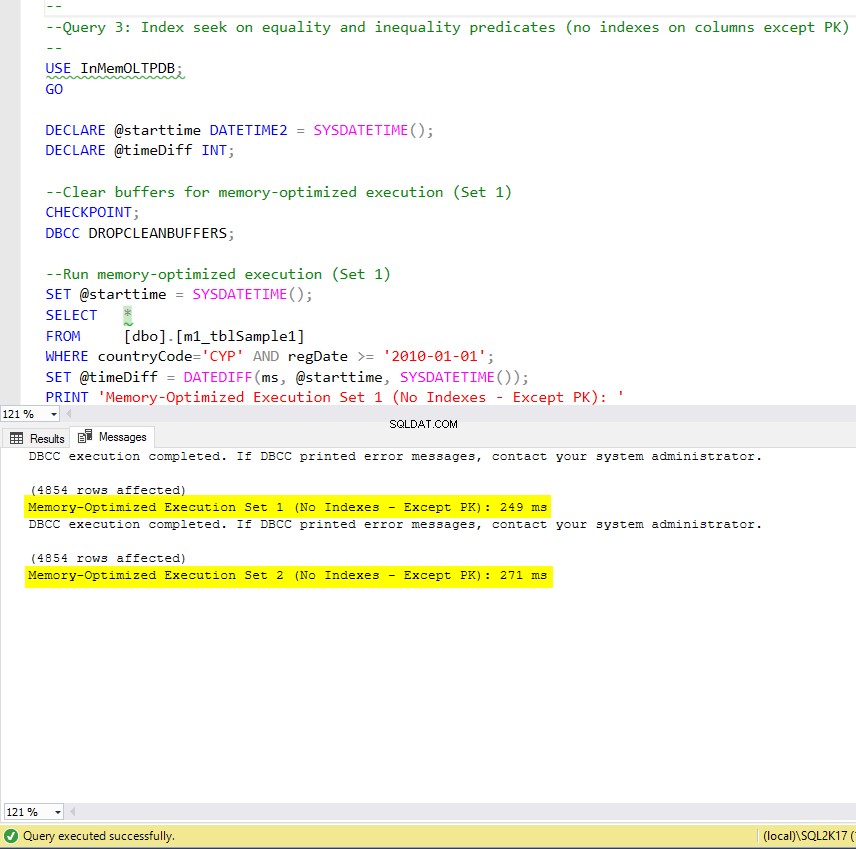
Rysunek 9:Czas wykonania zapytania 3 (bez indeksów – z wyjątkiem PK).
Podsumujmy teraz wyniki uzyskane powyżej. Poniższa tabela przedstawia zmierzone czasy wykonania dla wszystkich powyższych zapytań i kombinacji tabeli/indeksów.
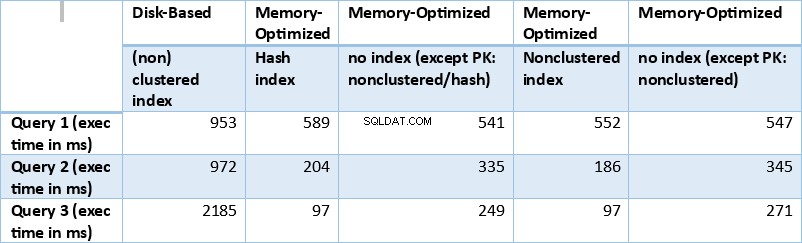
Tabela 1:Podsumowanie czasów wykonania (ms) dla wszystkich zapytań.
Dyskusja
Jeśli przyjrzymy się wynikom realizacji podsumowanym w powyższej tabeli, możemy dojść do pewnych wniosków. Narysujmy każdy wynik zapytania na wykresie. Poniższe wykresy ilustrują czasy wykonania, a także przyspieszenie tabel zoptymalizowanych pod kątem pamięci w stosunku do tabel dyskowych.
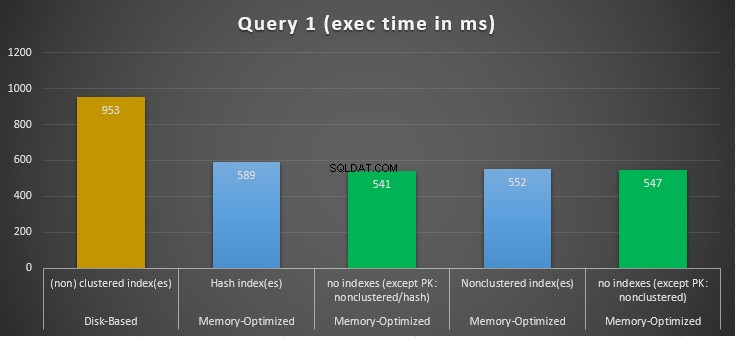
Rysunek 10:Porównanie czasów wykonania zapytania 1.
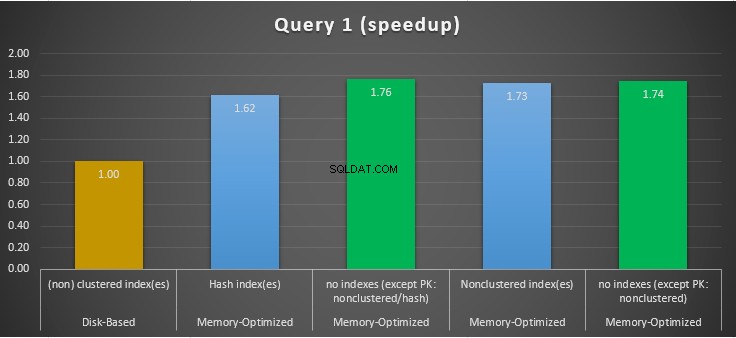
Rysunek 11:Porównanie przyspieszenia zapytania 1.
Jeśli chodzi o zapytanie 1, które było agregacją GROUP BY, widzimy, że obie wersje (indeksy vs brak indeksów) tabel zoptymalizowanych pod kątem pamięci działają prawie tak samo, mając przyspieszenie w stosunku do tabeli opartej na dysku (włączonej z indeksami) pomiędzy 1,62 i 1,76 raza szybciej.
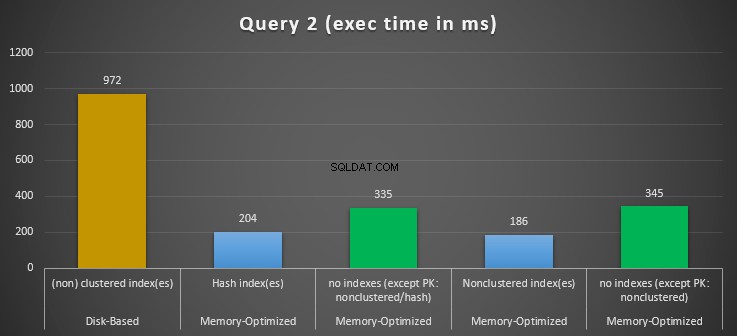
Rysunek 12:Porównanie czasów wykonania zapytania 2.
Rysunek 13:Porównanie przyspieszenia zapytania 2.
Jeśli chodzi o Query 2, które obejmowało wyszukiwanie indeksu na predykatach równości, widzimy, że tabele zoptymalizowane pod kątem pamięci z indeksami działały znacznie lepiej niż tabele zoptymalizowane pod kątem pamięci bez indeksów. Ponadto obserwujemy, że zoptymalizowana pod kątem pamięci tabela z indeksem nieklastrowym w kolumnie używanej jako predykat działała lepiej niż ta z indeksem mieszającym.
Tak więc w przypadku zapytania 2 zwycięzcą jest tabela zoptymalizowana pod kątem pamięci z indeksem nieklastrowym, która ma ogólne przyspieszenie 5,23 razy szybciej w porównaniu z wykonywaniem na dysku.
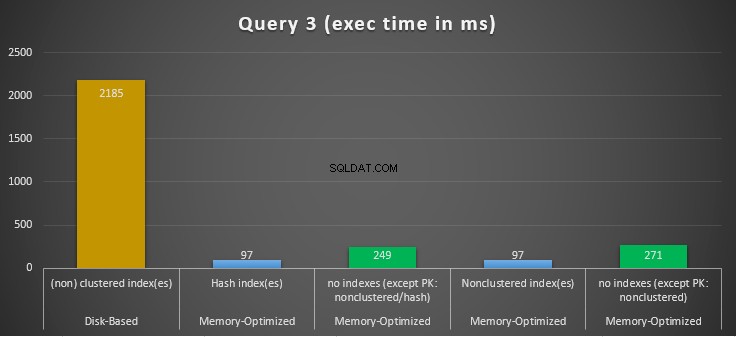
Rysunek 14:Porównanie czasów wykonania zapytania 3.
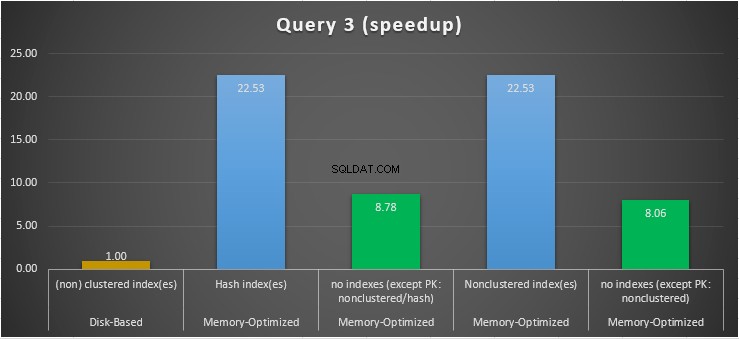
Rysunek 15:Porównanie przyspieszenia zapytania 3.
Jeśli chodzi o zapytanie 3, które obejmowało wyszukiwanie indeksu na podstawie połączonych predykatów równości i nierówności, widzimy, że tabele zoptymalizowane pod kątem pamięci z indeksami działały znacznie lepiej niż tabele zoptymalizowane pod kątem pamięci bez indeksów. Ponadto obserwujemy, że zoptymalizowana pod kątem pamięci tabela z indeksem nieklastrowym w kolumnie używanej jako predykat działała tak samo, jak ta z indeksem mieszającym.
W tym celu widzimy, że obie tabele zoptymalizowane pod kątem pamięci, które wykorzystują indeksy w kolumnach używanych jako predykaty, działały szybciej niż te bez indeksów i osiągnęły przyspieszenie 22,53 razy szybsze nad wykonaniem na dysku.
Wniosek
W tym artykule zbadaliśmy użycie indeksów w tabelach zoptymalizowanych pod kątem pamięci w SQL Server. Jako punkt odniesienia dla każdego zapytania użyliśmy najlepszej możliwej konfiguracji tabeli opartej na dyskach, a następnie porównaliśmy wydajność trzech zapytań z tabelami opartymi na dyskach i 4 odmianami tabel zoptymalizowanych pod kątem pamięci. Dwie z czterech tabel zoptymalizowanych pod kątem pamięci używały indeksów (mieszających/nieklastrowych), a pozostałe dwie nie używały żadnych indeksów, z wyjątkiem tych używanych dla kluczy podstawowych.
Ogólny wniosek jest taki, że zawsze trzeba zbadać, jak indeksy wpływają na wydajność, nie tylko w przypadku tabel zoptymalizowanych pod kątem pamięci, ale także w przypadku tabel dyskowych, i zawsze, gdy stwierdzisz, że poprawiają wydajność, aby z nich skorzystać. Wnioski z przykładów zawartych w tym artykule pokazują, że jeśli użyjesz odpowiednich indeksów w tabelach zoptymalizowanych pod kątem pamięci, możesz osiągnąć znacznie lepszą wydajność dla zapytań podobnych do tych użytych w tym artykule, w porównaniu do zwykłego korzystania z tabel zoptymalizowanych pod kątem pamięci bez indeksów .
Odniesienia i dalsza lektura:
- Microsoft Docs:Tabele zoptymalizowane pod kątem pamięci
- Microsoft Docs:Wskazówki dotyczące używania indeksów w tabelach zoptymalizowanych pod kątem pamięci
- Microsoft Docs:indeksy w tabelach zoptymalizowanych pod kątem pamięci
Przydatne narzędzie:
dbForge Index Manager – poręczny dodatek SSMS do analizy stanu indeksów SQL i rozwiązywania problemów z fragmentacją indeksów.