Dzienniki transakcji są istotnym i ważnym elementem architektury bazy danych. W tym artykule omówimy logi transakcji SQL Server, znaczenie i ich rolę w migracji bazy danych.
Wprowadzenie
Porozmawiajmy o różnych opcjach wykonywania kopii zapasowych SQL Server. SQL Server obsługuje trzy różne typy kopii zapasowych.
1. Pełny
2. Dyferencjał
3. Dziennik transakcji
Zanim przejdziemy do koncepcji dziennika transakcji, omówmy inne podstawowe typy kopii zapasowych w SQL Server.
Pełna kopia zapasowa to kopia wszystkiego. Jak sama nazwa wskazuje, utworzy kopię zapasową wszystkiego. Utworzy kopię zapasową wszystkich danych, każdego obiektu bazy danych, takiego jak plik, grupa plików, tabela itp.:– Pełna kopia zapasowa jest podstawą dla każdego innego typu kopii zapasowych.
Różnicowa kopia zapasowa utworzy kopię zapasową danych, które zmieniły się od ostatniej pełnej kopii zapasowej.
Trzecią opcją jest Backup-Log Transakcji, który będzie rejestrował wszystkie wyciągi, które wydamy do bazy danych w logu transakcji. Dziennik transakcji to mechanizm znany jako „WAL” (Write-Ahead-Logging). Najpierw zapisuje każdą informację do dziennika transakcji, a następnie do bazy danych. Innymi słowy, proces zazwyczaj nie aktualizuje bazy danych bezpośrednio. Jest to jedyna pełna dostępna opcja z modelem pełnego odzyskiwania bazy danych. W innych modelach odzyskiwania dane są częściowe lub w dzienniku nie ma wystarczającej ilości danych. Na przykład rekord dziennika podczas rejestrowania początku nowej transakcji (rekord dziennika LOP_BEGIN_XACT) będzie zawierał czas rozpoczęcia transakcji, a rekordy dziennika LOP_COMMIT_XACT (lub LOP_ABORT_XACT) będą rejestrować czas zatwierdzenia (lub przerwania) transakcji.
Aby znaleźć wewnętrzne elementy dziennika transakcji online, możesz zapytać o funkcję sys.fn_dblog.
Funkcja systemowa sys.fn_dblog akceptuje dwa parametry, po pierwsze, początek LSN i koniec LSN transakcji. Domyślnie jest ustawiony na NULL. Jeśli jest ustawiony na NULL, zwróci wszystkie rekordy dziennika z pliku dziennika transakcji.
USE WideWorldImporters GO SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], [Log Record Fixed Length], [Log Record Length] [Transaction SID], [SPID], [Begin Time], * FROM fn_dblog(null,null)

Jak wszyscy wiemy, transakcje są przechowywane w formacie binarnym i nie jest w formacie czytelnym. Aby odczytać plik dziennika transakcji offline, możesz użyć fn_dump_dblog.
Przeanalizujmy plik dziennika transakcji, aby zobaczyć, kto upuścił obiekt za pomocą fn_dump_dblog.
SELECT [Current LSN], [Operation], [Transaction Name], [Transaction ID], SUSER_SNAME ([Transaction SID]) AS DBUser
FROM fn_dump_dblog (
NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn',
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT,
DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT)
WHERE
Context IN ('LCX_NULL') AND Operation IN ('LOP_BEGIN_XACT')
AND [Transaction Name] LIKE '%DROP%'
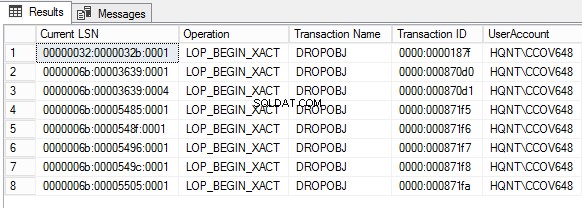
Użyjemy funkcji fn_dblog() do odczytania aktywnej części dziennika transakcji w celu znalezienia aktywności wykonywanej na danych . Po wyczyszczeniu dziennika transakcji musisz wykonać zapytanie o dane z pliku dziennika za pomocą fn_dump_dblog().
Ta funkcja udostępnia ten sam zestaw wierszy, co fn_dblog(), ale ma kilka interesujących funkcji, które sprawiają, że jest przydatna, to niektóre scenariusze rozwiązywania problemów i odzyskiwania. W szczególności może odczytywać nie tylko dziennik transakcji bieżącej bazy danych, ale także kopie zapasowe dziennika transakcji na dysku lub taśmie.
Aby uzyskać listę obiektów, które zostały usunięte za pomocą pliku transakcji, uruchom następujące zapytanie. Początkowo dane są zrzucane do tabeli tymczasowej. W niektórych przypadkach wykonanie fun_dump_dblog() zajmuje trochę więcej czasu. Dlatego lepiej jest przechwycić dane w tabeli tymczasowej.
Aby uzyskać identyfikator obiektu z kolumny Informacje o blokadzie, uruchom następujące zapytanie.
SELECT * INTO TEMP FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction ID] in( SELECT DISTINCT [Transaction ID] FROM fn_dump_dblog ( NULL, NULL, N'DISK', 1, N'G:\BKP\AdventureWorks_2016_log.trn', DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT, DEFAULT) WHERE [Transaction Name] LIKE '%DROP%') and [Lock Information] like '%ACQUIRE_LOCK_SCH_M OBJECT%'
Aby uzyskać identyfikator obiektu z kolumny Informacje o blokadzie, uruchom następujące zapytanie.
SELECT DISTINCT [Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4,
Substring([Lock Information],PATINDEX('%: 0%', [Lock Information])+4,(PATINDEX('%:0%', [Lock Information])-PATINDEX('%: 0%', [Lock Information]))-4) objectid
from temp
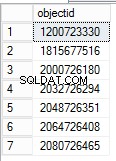
Object_id można znaleźć, manipulując wartością kolumny Lock Information. Aby znaleźć nazwę obiektu dla odpowiedniego identyfikatora obiektu, przywróć bazę danych z kopii zapasowej tuż przed usunięciem tabeli. Po przywróceniu możesz wysłać zapytanie do widoku systemowego, aby uzyskać nazwę obiektu.
USE AdventureWorks2016; GO SELECT name, object_id from sys.objects WHERE object_id = '1815677516';
Teraz zobaczmy różne formy tych samych szczegółów transakcji przy użyciu sys.dn_dblog, sys.fn_full_dblog. Funkcja systemowa fn_full_dblog działa tylko z SQL Server 2017.
Zapytanie o pobranie 10 największych transakcji za pomocą fn_dblog.
SELECT TOP 10 * FROM sys.fn_dblog(null,null)

Począwszy od SQL Server 2017, możesz używać fn_full dblog.
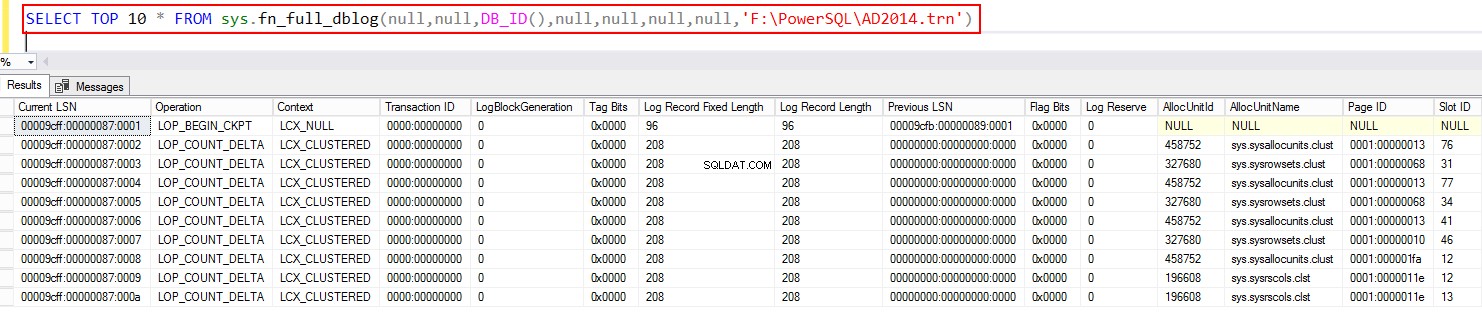
SELECT TOP 10 * FROM sys.fn_full_dblog(null,null,DB_ID(),null,null,null,null,NULL)

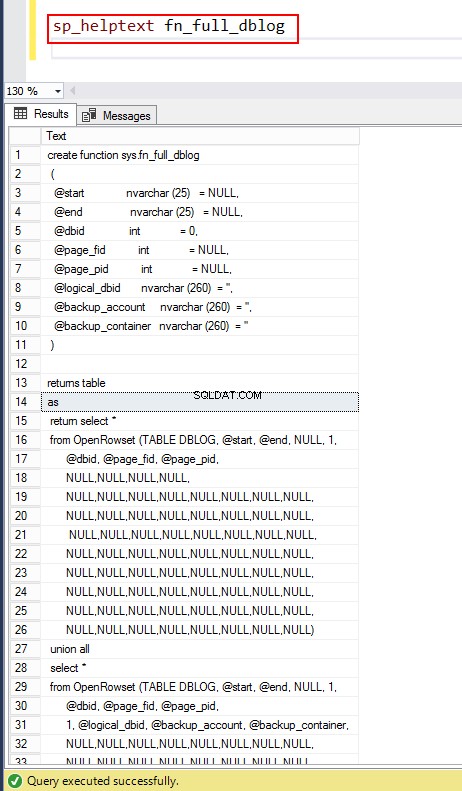
Możesz dalej zagłębić się w funkcje systemu za pomocą sp_helptext fn_full_dblog.
Następnie odpytaj plik kopii zapasowej za pomocą funkcji systemowej, używając fn_full_dblog. Ponownie, dotyczy to tylko wersji SQL Server 2017 i nowszych.
Przywracanie do określonego momentu
Załóżmy, że masz listę kopii zapasowej całego dziennika, a gdy zamierzasz przywrócić dzienniki, masz możliwość przywrócenia danych do określonego momentu. Tak więc w procesie przywracania dziennika nie musisz koniecznie przywracać wszystkich danych, możesz je przywrócić do, przed lub po każdej pojedynczej transakcji. Tak więc, jeśli baza danych ulegnie awarii w określonym czasie i mamy zarówno pełną kopię zapasową, jak i kopie zapasowe dziennika, powinniśmy być w stanie najpierw przywrócić pełną kopię zapasową, a następnie przywrócić kopię zapasową dziennika, a następnie przywrócić ostatni dziennik do określonego czasu , a to pozostawiłoby bazę danych dokładnie w stanie, w jakim była przed wystąpieniem tego problemu.
Kopie zapasowe dzienników to dość powszechne VLDB (bardzo duża baza danych) i najbardziej krytyczne bazy danych. Zawsze zaleca się przetestowanie procesu przywracania. Za każdym razem, gdy wykonujesz kopie zapasowe bazy danych, zaleca się dobrze przemyśleć proces przywracania i zawsze należy częściej testować proces przywracania.
Zawsze dobrze jest od czasu do czasu złagodzić testowanie procesu przywracania, więc po prostu upewnij się, że proces przebiega normalnie.
Scenariusze
Porozmawiajmy o scenariuszu, w którym trzeba przywrócić bardzo dużą bazę danych, a wszyscy wiemy, że normalnie może to zająć kilka godzin, a wszyscy powinni być tego świadomi. Jeśli planujesz migrację bazy danych z zerową utratą danych i mniejszymi przerwami w działaniu, nadal może to być dość duży problem. Dlatego upewnij się, że korzystasz z kopii zapasowej dziennika transakcji, aby przyspieszyć ten proces.
Rozważmy inny scenariusz, w którym przeprowadzasz migrację bazy danych side-by-side między dwiema różnymi wersjami SQL Server; bierzesz udział w migracji bazy danych do tej samej wersji oprogramowania w miejscu docelowym, co obejmuje przeniesienie systemu operacyjnego, bazy danych, aplikacji i sieci itp.:-; migrację bazy danych z jednego sprzętu na inny; zmiana zarówno oprogramowania, jak i sprzętu. Proces migracji bazy danych jest zawsze wyzwaniem, w którym utrata danych jest zawsze możliwa i podlega środowisku.
Najlepsze praktyki migracji bazy danych
Omówmy standardowe praktyki zarządzania migracją baz danych.
Migrację należy przeprowadzić w sposób transakcyjny, aby uniknąć niespójności danych. Zwykłe etapy procesu migracji są zwykle następujące:
- Zatrzymaj usługę aplikacji — tutaj zaczyna się przestój
- Rozpocznij tworzenie kopii zapasowej dziennika, zależy to od Twoich wymagań
- Przełącz bazę danych w tryb odzyskiwania, aby nie dokonywać dalszych zmian w bazie danych
- Przenieś plik(i) dziennika
- Przywróć plik(i) dziennika transakcji bazy danych — pod warunkiem, że przywróciłeś już pełną kopię zapasową bazy danych w miejscu docelowym i pozostawiłeś bazę danych w stanie przywracania.
- Klonuj loginy i popraw użytkowników osieroconych
- Utwórz oferty pracy
- Zainstaluj aplikację
- Konfiguruj sieć – Zmień wpisy DNS
- Ponownie skonfiguruj ustawienia aplikacji
- Uruchom usługę aplikacji
- Przetestuj aplikację
Rozpoczęcie
W tym artykule omówimy, jak obsłużyć bardzo dużą migrację bazy danych OLTP. Omówimy strategie wykorzystania technik serwerowych SQL i narzędzi innych firm w celu zapewnienia bezpieczeństwa danych wraz z zerowym lub minimalnym zakłóceniem dostępności systemu produkcyjnego. Podczas procesu zawsze istnieje szansa na utratę danych. Czy uważasz, że bezproblemowa obsługa transakcji to dobra strategia? Jeśli „tak”, jakie są twoje ulubione opcje?
Zagłębmy się w dostępne opcje:
- Kopia zapasowa i przywracanie
- Wysyłka dziennika
- Odbicie lustrzane bazy danych
- Narzędzia innych firm
Kopia zapasowa i przywracanie
Technika tworzenia kopii zapasowych i przywracania bazy danych jest najbardziej realną opcją dla każdej migracji bazy danych. Jeśli zostanie odpowiednio zaplanowany i przetestowany, unikniemy wielu nieprzewidzianych błędów w migracji. Wszyscy wiemy, że tworzenie kopii zapasowej jest procesem online, łatwo jest zainicjować tworzenie kopii zapasowej dziennika transakcji w odpowiednim czasie, aby zawęzić liczbę transakcji, które mają zostać dostarczone do nowej bazy danych. W oknie migracji możemy ograniczyć użytkownikom dostęp do bazy danych i zainicjować ostatnią kopię zapasową dziennika i przenieść go do miejsca docelowego. W ten sposób czas przestoju może zostać znacznie skrócony.
Wysyłka dziennika
Wszyscy rozumiemy znaczenie plików dziennika w świecie baz danych. Technika przesyłania dzienników zapewnia dobre rozwiązanie do odzyskiwania po awarii i obsługuje ograniczony dostęp tylko do odczytu do pomocniczych baz danych w okresie między zadaniami przywracania. Jest to zasadniczo koncepcja tworzenia kopii zapasowej dziennika transakcji i jest odtwarzana w pełnej kopii zapasowej w jeszcze jednej dodatkowej bazie danych. Te pomocnicze bazy danych są zduplikowanymi kopiami podstawowej bazy danych i stale przywracają kopie zapasowe dziennika transakcji do własnej kopii, aby zachować synchronizację z podstawową bazą danych. Ponieważ dodatkowa baza danych znajduje się na oddzielnym sprzęcie, w przypadku awarii podstawowej z jakiegokolwiek powodu, w pełni utworzona kopia zapasowa systemu jest natychmiast dostępna do użytku, a ruch sieciowy można po prostu przekierować na serwer pomocniczy, bez wiedzy użytkowników, że wystąpiła usterka. Wysyłka dziennika zapewnia łatwy i skuteczny sposób zarządzania migracją w większym stopniu w większości przypadków.
Odbicie lustrzane
Database Mirroring jest również opcją migracji bazy danych, pod warunkiem, że źródło i cel mają te same wersje i wydania. Zasadniczo dublowanie tworzy dwie zduplikowane kopie bazy danych na dwóch instancjach sprzętowych. Transakcje miałyby miejsce jednocześnie w obu bazach danych. Masz możliwość przełączenia produkcyjnej bazy danych w tryb offline, przełączenia się na dublowaną wersję tej bazy danych i umożliwienia użytkownikom dalszego uzyskiwania dostępu do danych, tak jakby nic się nie stało. Jeśli chodzi o jego implementację, mamy do czynienia z serwerem głównym, serwerem lustrzanym i świadkiem. Ale będzie to przestarzała funkcja i zostanie usunięta z przyszłych wersji SQL Server.
Podsumowanie
W tym artykule omówiliśmy szczegółowo typy kopii zapasowych, kopie zapasowe dziennika transakcji, standardy migracji danych, proces i strategię, nauczyliśmy się używać technik SQL do efektywnej obsługi etapów migracji danych.
Mechanizm zapisywania dziennika transakcji WAL zapewnia, że transakcje są zawsze najpierw zapisywane w pliku dziennika. W ten sposób SQL Server gwarantuje, że efekty wszystkich zatwierdzonych transakcji zostaną ostatecznie zapisane w plikach danych (na dysk), a wszelkie modyfikacje danych na dysku, które pochodzą z niekompletnych transakcji, zostaną wycofane i nie zostaną odzwierciedlone w plikach danych.
W większości przypadków opóźnienie w synchronizacji danych jest nieprzewidziane, a utrata danych trwała. Najczęściej wszystko zależy od wielkości bazy danych i dostępnej infrastruktury. Zalecaną praktyką jest przeprowadzanie migracji ręcznie niż w ramach wdrożenia, aby zachować segregację, aby dane wyjściowe były bardziej przewidywalne.
Osobiście wolałbym wysyłkę dziennika z różnych powodów:możesz wykonać pełną kopię zapasową danych ze starego serwera z dużym wyprzedzeniem, przenieść je na nowy serwer, przywrócić, a następnie zastosować pozostałe transakcje (kopia zapasowa t-log ) od punktu aż do momentu przełączenia. Proces jest w rzeczywistości dość prosty.
Migracja bazy danych nie jest trudna, jeśli odbywa się to we właściwy sposób. Mam nadzieję, że ten post pomoże ci przeprowadzić migracje baz danych w płynniejszy sposób.



