Według Wikipedii wstawianie zbiorcze to proces lub metoda zapewniana przez system zarządzania bazą danych w celu załadowania wielu wierszy danych do tabeli bazy danych. Jeśli dostosujemy to wyjaśnienie do instrukcji BULK INSERT, wstawka zbiorcza umożliwia importowanie zewnętrznych plików danych do SQL Server.
Załóżmy, że nasza organizacja ma plik CSV zawierający 1.500.000 wierszy i chcemy go zaimportować do określonej tabeli w SQL Server, aby użyć instrukcji BULK INSERT w SQL Server. Możemy znaleźć kilka metod radzenia sobie z tym zadaniem. Może to być użycie BCP (b ulk c pisz p programu), Kreator importu i eksportu SQL Server lub pakiet SQL Server Integration Service. Jednak instrukcja BULK INSERT jest znacznie szybsza i skuteczniejsza. Kolejną zaletą jest to, że oferuje kilka parametrów pomagających określić ustawienia procesu wstawiania zbiorczego.
Zacznijmy od podstawowej próbki. Następnie przejdziemy przez bardziej wyrafinowane scenariusze.
Przygotowanie
Przede wszystkim potrzebujemy przykładowego pliku CSV. Pobieramy przykładowy plik CSV ze strony internetowej E for Excel (zbiór próbkowanych plików CSV z innym numerem wiersza). Tutaj użyjemy 1.500.000 rekordów sprzedaży.
Pobierz plik zip, rozpakuj go, aby uzyskać plik CSV i umieść go na dysku lokalnym.
Importuj plik CSV do tabeli SQL Server
Importujemy nasz plik CSV do tabeli docelowej w najprostszej formie. Umieściłem swój przykładowy plik CSV na dysku C:. Teraz tworzymy tabelę, aby zaimportować do niej dane z pliku CSV:
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Poniższa instrukcja BULK INSERT importuje plik CSV do tabeli Sprzedaż:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Prawdopodobnie zauważyłeś określone parametry powyższej instrukcji wstawiania zbiorczego. Wyjaśnijmy je:
- PIERWSZA określa punkt początkowy instrukcji INSERT. W poniższym przykładzie chcemy pominąć nagłówki kolumn, więc ustawiamy ten parametr na 2.

- FIELDTERMINATOR definiuje znak oddzielający od siebie pola. SQL Server wykrywa w ten sposób każde pole.
- ROWTERMINATOR niewiele różni się od FIELDTERMINATORA. Definiuje charakter separacji wierszy.
W przykładowym pliku CSV FIELDTERMINATOR jest bardzo wyraźny i jest to przecinek (,). Aby wykryć ten parametr, otwórz plik CSV w Notepad ++ i przejdź do Widok -> Pokaż symbol -> Pokaż wszystkie karty. Znaki CRLF znajdują się na końcu każdego pola.
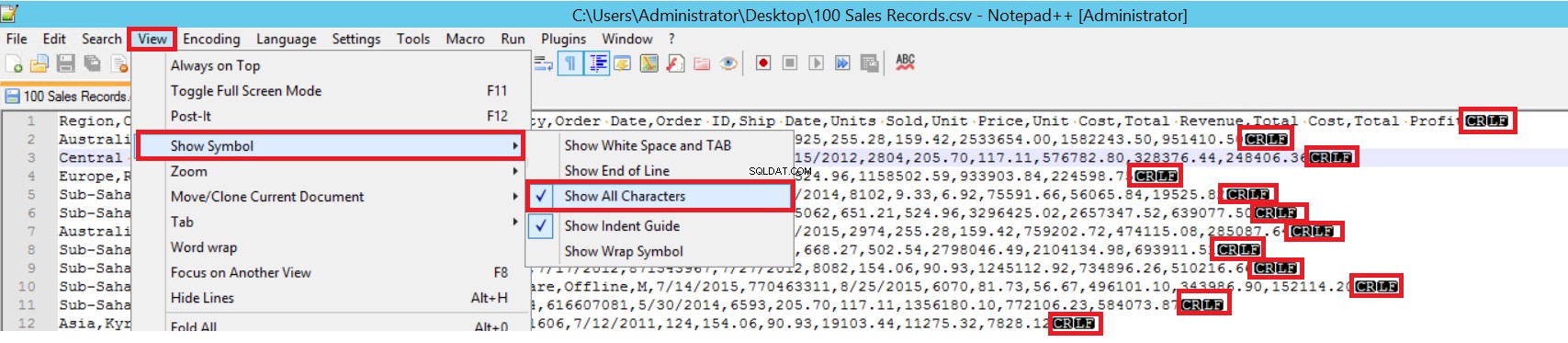
CR =Powrót karetki i LF =Wysuw linii. Służą do zaznaczania łamania wiersza w pliku tekstowym. Wskaźnik to „\n” w instrukcji zbiorczego wstawiania.
Innym sposobem importowania pliku CSV do tabeli z wstawianiem zbiorczym jest użycie parametru FORMAT. Pamiętaj, że ten parametr jest dostępny tylko w SQL Server 2017 i nowszych wersjach.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
To był najprostszy scenariusz, w którym tabela docelowa i plik CSV mają taką samą liczbę kolumn. Jednak w przypadku, gdy tabela docelowa ma więcej kolumn, plik CSV jest typowy. Rozważmy to.
Do tabeli Sales dodajemy klucz podstawowy, aby rozbić mapowania kolumn równości. Tworzymy tabelę sprzedaży z kluczem podstawowym i importujemy plik CSV za pomocą polecenia wstawiania zbiorczego.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Ale generuje błąd:
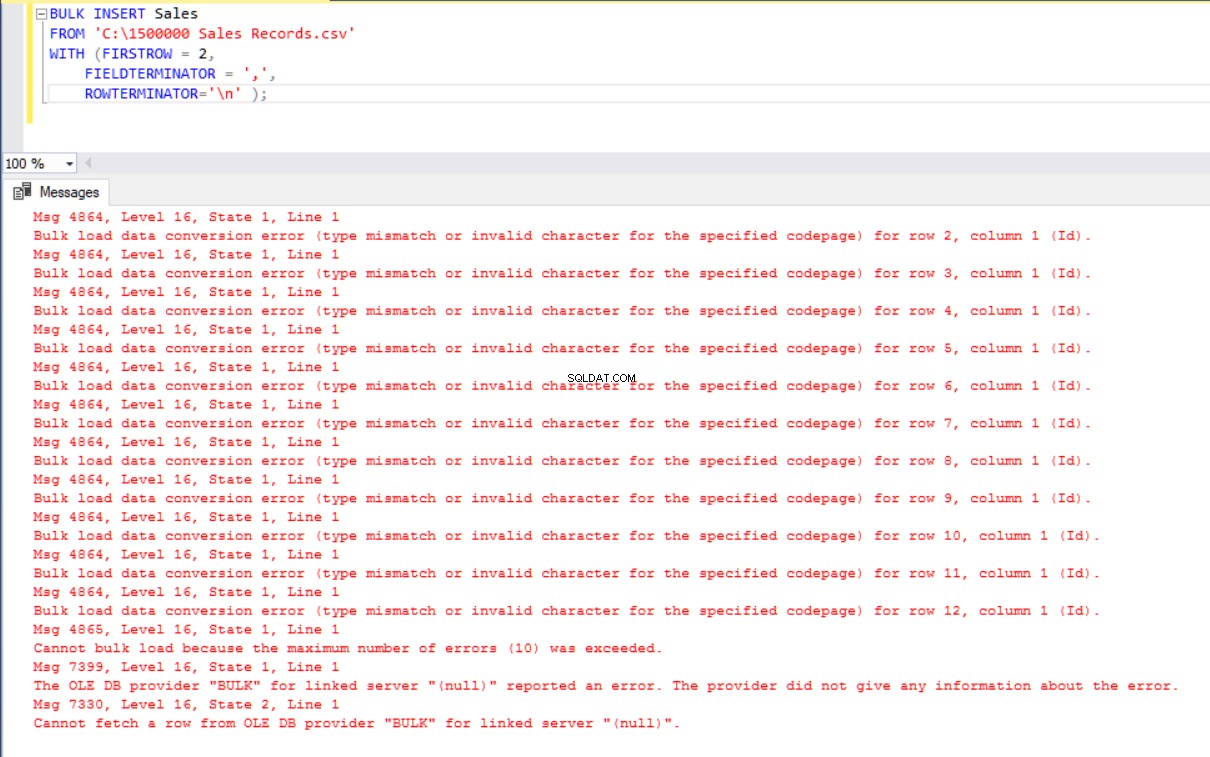
Aby obejść ten błąd, tworzymy widok tabeli Sales z mapowaniem kolumn do pliku CSV. Następnie importujemy dane CSV z tego widoku do tabeli Sprzedaż:
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Oddziel i załaduj duży plik CSV do małego rozmiaru partii
SQL Server uzyskuje blokadę do tabeli docelowej podczas operacji wstawiania zbiorczego. Domyślnie, jeśli nie ustawisz parametru BATCHSIZE, SQL Server otworzy transakcję i wstawi do niej całe dane CSV. Z tym parametrem SQL Server dzieli dane CSV zgodnie z wartością parametru.
Podzielmy całe dane CSV na kilka zestawów po 300 000 wierszy każdy.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 ); Dane będą importowane pięciokrotnie w częściach.
- Jeśli Twoja instrukcja wstawiania zbiorczego nie zawiera parametru BATCHSIZE, wystąpi błąd, a SQL Server wycofa cały proces wstawiania zbiorczego.
- Z tym parametrem ustawionym na instrukcję zbiorczego wstawiania, SQL Server wycofuje tylko część, w której wystąpił błąd.
Nie ma optymalnej ani najlepszej wartości dla tego parametru, ponieważ jego wartość może się zmieniać w zależności od wymagań systemu bazy danych.
Ustaw zachowanie w przypadku błędów
Jeśli w niektórych scenariuszach kopiowania zbiorczego wystąpi błąd, możemy anulować proces kopiowania zbiorczego lub kontynuować go. Parametr MAXERRORS pozwala nam określić maksymalną liczbę błędów. Jeśli proces wstawiania zbiorczego osiągnie tę maksymalną wartość błędu, anuluje operację zbiorczego importu i wycofuje się. Domyślna wartość tego parametru to 10.
Na przykład uszkodziliśmy typy danych w 3 wierszach pliku CSV. Parametr MAXERRORS jest ustawiony na 2.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2); Cała operacja wstawiania zbiorczego zostanie anulowana, ponieważ jest więcej błędów niż wartość parametru MAXERRORS.
Jeśli zmienimy parametr MAXERRORS na 4, instrukcja zbiorczego wstawiania pominie te wiersze z błędami i wstawi prawidłowe wiersze o strukturze danych. Proces wstawiania zbiorczego zostanie zakończony.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Jeśli użyjemy jednocześnie BATCHSIZE i MAXERRORS, proces kopiowania zbiorczego nie anuluje całej operacji wstawiania. Anuluje tylko podzieloną część.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales Spójrz na poniższy obrazek, który pokazuje wynik wykonania skryptu:
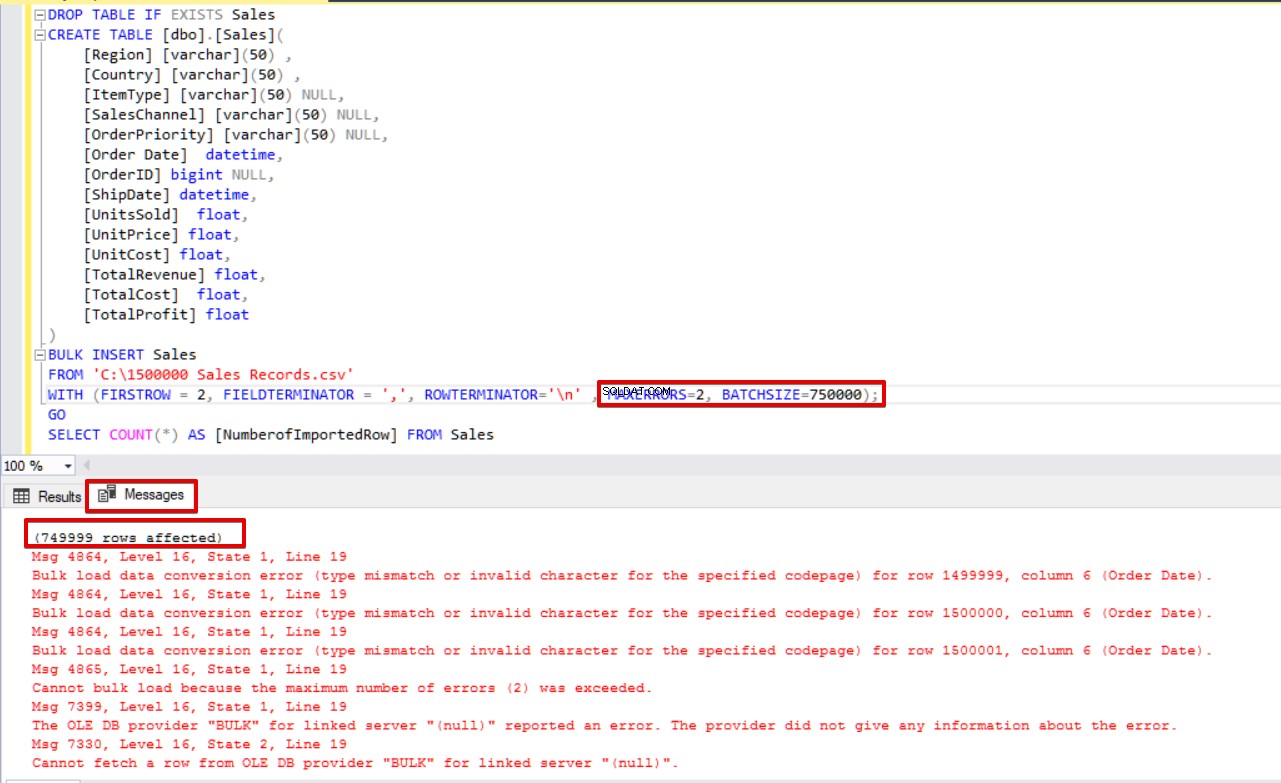
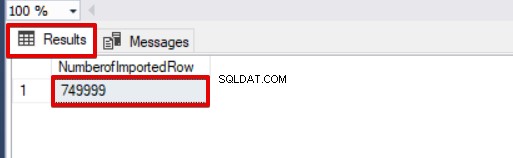
Inne opcje procesu wstawiania zbiorczego
FIRE_TRIGGERS – włącz wyzwalacze w tabeli docelowej podczas operacji zbiorczego wstawiania
Domyślnie podczas procesu zbiorczego wstawiania wyzwalacze wstawiania określone w tabeli docelowej nie są uruchamiane. Mimo to w niektórych sytuacjach możemy chcieć je włączyć.
Rozwiązanie korzysta z opcji FIRE_TRIGGERS w instrukcjach wstawiania zbiorczego. Należy jednak pamiętać, że może to wpłynąć i zmniejszyć wydajność operacji wstawiania zbiorczego. Dzieje się tak, ponieważ wyzwalacz/wyzwalacze mogą wykonywać oddzielne operacje w bazie danych.
Na początku nie ustawiamy parametru FIRE_TRIGGERS, a proces zbiorczego wstawiania nie uruchomi wyzwalacza wstawiania. Zobacz poniższy skrypt T-SQL:
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
DROP TABLE IF EXISTS SalesLog
CREATE TABLE SalesLog (OrderIDLog bigint)
GO
CREATE TRIGGER OrderLogIns ON Sales
FOR INSERT
AS
BEGIN
SET NOCOUNT ON
INSERT INTO SalesLog
SELECT OrderId from inserted
end
GO
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
SELECT Count(*) FROM SalesLogPo wykonaniu tego skryptu wyzwalacz wstawiania nie zostanie uruchomiony, ponieważ opcja FIRE_TRIGGERS nie jest ustawiona.
Teraz dodajmy opcję FIRE_TRIGGERS do instrukcji zbiorczego wstawiania:
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n',
FIRE_TRIGGERS);
GO
SELECT Count(*) as [NumberOfRowsinTriggerTable] FROM SalesLog 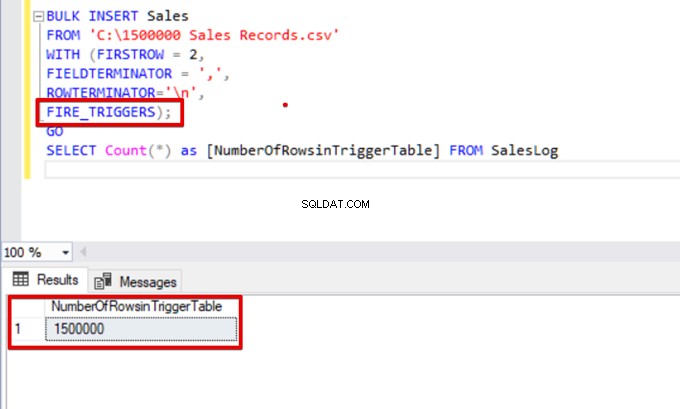
CHECK_CONSTRAINTS – włącz ograniczenie sprawdzające podczas operacji wstawiania zbiorczego
Ograniczenia sprawdzania pozwalają nam wymusić integralność danych w tabelach SQL Server. Celem ograniczenia jest sprawdzenie wprowadzonych, zaktualizowanych lub usuniętych wartości zgodnie z ich regulacją składni. Na przykład ograniczenie NOT NULL zapewnia, że wartość NULL nie może modyfikować określonej kolumny.
Tutaj skupiamy się na ograniczeniach i interakcjach wstawiania zbiorczego. Domyślnie podczas procesu zbiorczego wstawiania wszelkie ograniczenia sprawdzania i klucza obcego są ignorowane. Ale są pewne wyjątki.
Według Microsoftu „Ograniczenia UNIQUE i PRIMARY KEY są zawsze wymuszane. Podczas importowania do kolumny znaków, dla której zdefiniowano ograniczenie NOT NULL, BULK INSERT wstawia pusty ciąg, gdy w pliku tekstowym nie ma żadnej wartości”.
W poniższym skrypcie T-SQL dodajemy ograniczenie sprawdzające do kolumny OrderDate, która kontroluje datę zamówienia większą niż 01.01.2016.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
ALTER TABLE [Sales] ADD CONSTRAINT OrderDate_Check
CHECK(OrderDate >'20160101')
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);
GO
SELECT COUNT(*) AS [UnChekedData] FROM
Sales WHERE OrderDate <'20160101'W rezultacie proces wstawiania zbiorczego pomija kontrolę ograniczenia sprawdzania. Jednak SQL Server wskazuje ograniczenie sprawdzania jako niezaufane:
SELECT is_not_trusted ,* FROM sys.check_constraints where name='OrderDate_Check'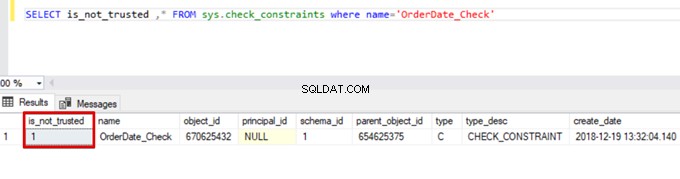
Ta wartość wskazuje, że ktoś wstawił lub zaktualizował niektóre dane do tej kolumny, pomijając ograniczenie sprawdzania. Jednocześnie kolumna ta może zawierać niespójne dane dotyczące tego ograniczenia.
Spróbuj wykonać instrukcję zbiorczego wstawiania z opcją CHECK_CONSTRAINTS. Wynik jest prosty:ograniczenie sprawdzania zwraca błąd z powodu niewłaściwych danych.
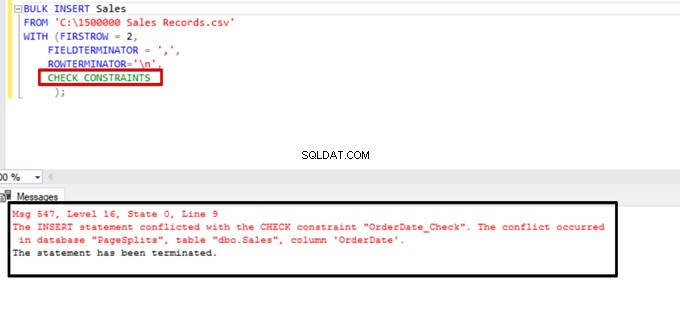
TABLOCK – zwiększ wydajność wielu wstawek zbiorczych do jednej tabeli docelowej
Podstawowym celem mechanizmu blokowania w SQL Server jest ochrona i zapewnienie integralności danych. W głównej koncepcji artykułu dotyczącego blokowania SQL Server można znaleźć szczegółowe informacje na temat mechanizmu blokowania.
Skoncentrujemy się na szczegółach blokowania procesu wstawiania zbiorczego.
Jeśli uruchomisz instrukcję zbiorczego wstawiania bez opcji TABLELOCK, uzyskuje ona blokadę wierszy lub tabel zgodnie z hierarchią blokad. Ale w niektórych przypadkach możemy chcieć wykonać wiele procesów wstawiania zbiorczego w jednej tabeli docelowej, a tym samym skrócić czas operacji.
Najpierw wykonujemy jednocześnie dwie instrukcje zbiorczego wstawiania i analizujemy zachowanie mechanizmu blokującego. Otwórz dwa okna zapytań w SQL Server Management Studio i uruchom jednocześnie następujące instrukcje zbiorczego wstawiania.
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n'
);Wykonaj następujące zapytanie DMV (Dynamic Management View) – pomaga monitorować stan procesu wstawiania zbiorczego:
SELECT session_id,command ,status,last_wait_type,text FROM sys.dm_exec_requests cross apply
sys.dm_exec_sql_text(sys.dm_exec_requests.sql_handle)
where text like '%BULK INSERT Sales%' and session_id <>@@SPID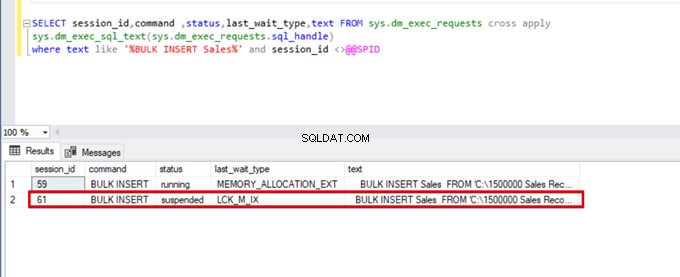
Jak widać na powyższym obrazku, sesja 61, stan procesu wstawiania zbiorczego jest zawieszony z powodu zablokowania. Jeśli zweryfikujemy problem, sesja 59 blokuje tabelę docelową wstawiania zbiorczego. Następnie sesja 61 czeka na zwolnienie tej blokady, aby kontynuować proces zbiorczego wstawiania.
Teraz dodajemy opcję TABLOCK do zbiorczych instrukcji wstawiania i wykonujemy zapytania.
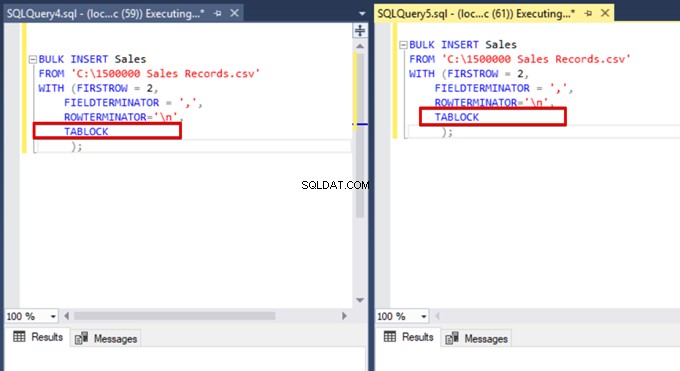
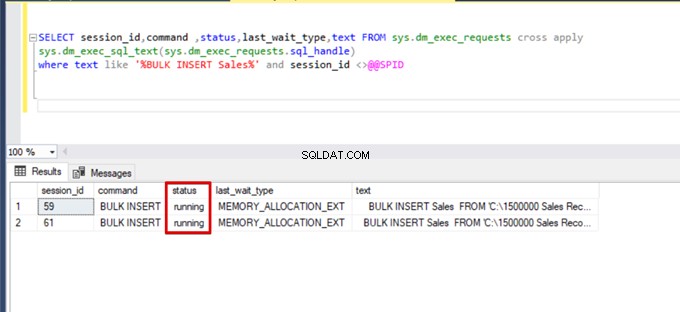
Gdy ponownie wykonujemy zapytanie monitorujące DMV, nie widzimy żadnego zawieszonego procesu wstawiania zbiorczego, ponieważ SQL Server używa określonego typu blokady zwanego blokadą aktualizacji zbiorczej (BU). Ten typ blokady umożliwia jednoczesne przetwarzanie wielu operacji wstawiania zbiorczego w tej samej tabeli. Ta opcja zmniejsza również całkowity czas procesu wstawiania zbiorczego.
Gdy wykonujemy następujące zapytanie podczas procesu wstawiania zbiorczego, możemy monitorować szczegóły blokowania i typy blokad:
SELECT dm_tran_locks.request_session_id,
dm_tran_locks.resource_database_id,
DB_NAME(dm_tran_locks.resource_database_id) AS dbname,
CASE
WHEN resource_type = 'OBJECT'
THEN OBJECT_NAME(dm_tran_locks.resource_associated_entity_id)
ELSE OBJECT_NAME(partitions.OBJECT_ID)
END AS ObjectName,
partitions.index_id,
indexes.name AS index_name,
dm_tran_locks.resource_type,
dm_tran_locks.resource_description,
dm_tran_locks.resource_associated_entity_id,
dm_tran_locks.request_mode,
dm_tran_locks.request_status
FROM sys.dm_tran_locks
LEFT JOIN sys.partitions ON partitions.hobt_id = dm_tran_locks.resource_associated_entity_id
LEFT JOIN sys.indexes ON indexes.OBJECT_ID = partitions.OBJECT_ID AND indexes.index_id = partitions.index_id
WHERE resource_associated_entity_id > 0
AND resource_database_id = DB_ID()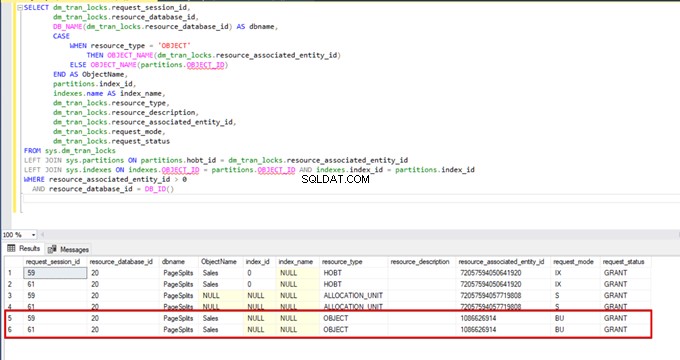
Wniosek
W bieżącym artykule omówiono wszystkie szczegóły operacji wstawiania zbiorczego w programie SQL Server. W szczególności wspomnieliśmy o poleceniu BULK INSERT oraz jego ustawieniach i opcjach. Przeanalizowaliśmy również różne scenariusze zbliżone do rzeczywistych problemów.
Przydatne narzędzie:
dbForge Data Pump – dodatek SSMS do wypełniania baz danych SQL zewnętrznymi danymi źródłowymi i migracji danych między systemami.