Według Wikipedii „Wstawianie zbiorcze to proces lub metoda zapewniana przez system zarządzania bazą danych w celu załadowania wielu wierszy danych do tabeli bazy danych”. Jeśli dostosujemy to wyjaśnienie zgodnie z instrukcją BULK INSERT, to bulk insert umożliwia importowanie zewnętrznych plików danych do SQL Server. Załóżmy, że nasza organizacja ma plik CSV zawierający 1.500.000 wierszy i chcemy zaimportować ten plik do określonej tabeli w SQL Server, dzięki czemu możemy łatwo użyć instrukcji BULK INSERT w SQL Server. Z pewnością możemy znaleźć kilka metodologii importu, aby obsłużyć ten proces importu pliku CSV, m.in. możemy użyć bcp (b ulk c pisz p programu), Kreator importu i eksportu SQL Server lub pakiet SQL Server Integration Service. Jednak instrukcja BULK INSERT jest znacznie szybsza i niezawodna niż przy użyciu innych metodologii. Kolejną zaletą instrukcji zbiorczego wstawiania jest to, że oferuje kilka parametrów, które pomagają określić ustawienia procesu wstawiania zbiorczego.
Najpierw rozpoczniemy bardzo podstawową próbkę, a następnie przejdziemy przez różne wyrafinowane scenariusze.
Przygotowanie
Przed uruchomieniem próbek potrzebujemy przykładowego pliku CSV. Dlatego pobierzemy przykładowy plik CSV ze strony internetowej E for Excel, na której można znaleźć różne próbkowane pliki CSV z różnymi numerami wierszy. Link znajdziesz na końcu artykułu. W naszych scenariuszach użyjemy 1.500.000 rekordów sprzedaży. Pobierz plik zip, a następnie rozpakuj plik CSV i umieść go na dysku lokalnym.

Importuj plik CSV do tabeli SQL Server
Scenariusz-1:miejsce docelowe i plik CSV mają taką samą liczbę kolumn
W tym pierwszym scenariuszu zaimportujemy plik CSV do tabeli docelowej w najprostszej formie. Umieściłem swój przykładowy plik CSV na dysku C:i teraz utworzymy tabelę, do której zaimportujemy dane z pliku CSV.
DROP TABLE IF EXISTS Sales CREATE TABLE [dbo].[Sales]( [Region] [varchar](50) , [Country] [varchar](50) , [ItemType] [varchar](50) NULL, [SalesChannel] [varchar](50) NULL, [OrderPriority] [varchar](50) NULL, [OrderDate] datetime, [OrderID] bigint NULL, [ShipDate] datetime, [UnitsSold] float, [UnitPrice] float, [UnitCost] float, [TotalRevenue] float, [TotalCost] float, [TotalProfit] float )
Poniższa instrukcja BULK INSERT importuje plik CSV do tabeli Sprzedaż.
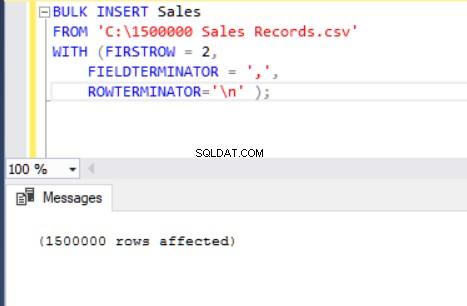
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
Teraz wyjaśnimy parametry powyższej instrukcji zbiorczego wstawiania.
Parametr FIRSTROW określa punkt początkowy instrukcji INSERT. W poniższym przykładzie chcemy pominąć nagłówki kolumn, więc ustawiamy ten parametr na 2.

FIELDTERMINATOR definiuje znak oddzielający od siebie pola. SQL Server w taki sposób wykrywa każde pole. ROWTERMINATOR niewiele różni się od FIELDTERMINATORA. Określa charakter separacji rzędów. W przykładowym pliku CSV terminator pola jest bardzo wyraźny i jest to przecinek (,). Ale jak możemy wykryć terminator polowy? Otwórz plik CSV w Notepad ++, a następnie przejdź do Widok->Pokaż symbol->Pokaż wszystkie karty, a następnie znajdź znaki CRLF na końcu każdego pola.
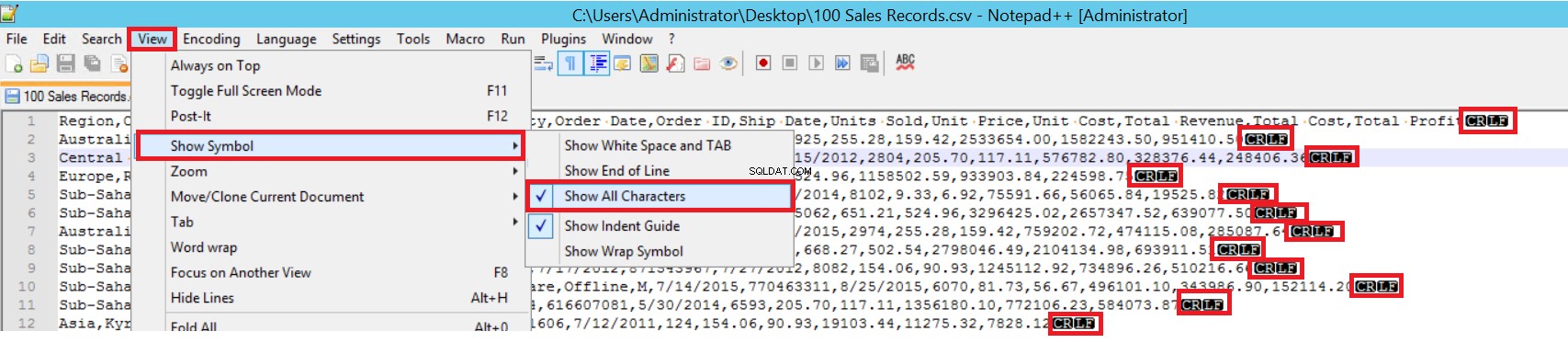
CR =Powrót karetki i LF =Wysuw linii. Służą do oznaczania łamania wiersza w pliku tekstowym i jest to oznaczone znakiem „\n” w instrukcji zbiorczego wstawiania.
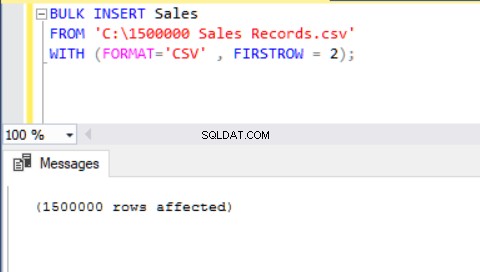
Inną metodą importowania pliku CSV do tabeli za pomocą wstawiania zbiorczego jest użycie parametru FORMAT. Należy pamiętać, że parametr FORMAT jest dostępny tylko w SQL Server 2017 i nowszych wersjach.
BULK INSERT Sales FROM 'C:\1500000 Sales Records.csv' WITH (FORMAT='CSV' , FIRSTROW = 2);
Teraz przeanalizujemy inny scenariusz.
Scenariusz-2:tabela docelowa ma więcej kolumn niż plik CSV
W tym scenariuszu dodamy klucz podstawowy do tabeli Sales, co spowoduje przerwanie mapowania kolumn równości. Teraz utworzymy tabelę Sales z kluczem podstawowym, spróbujemy zaimportować plik CSV za pomocą polecenia wstawiania zbiorczego, a wtedy otrzymamy błąd.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
Id INT PRIMARY KEY IDENTITY (1,1),
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' );
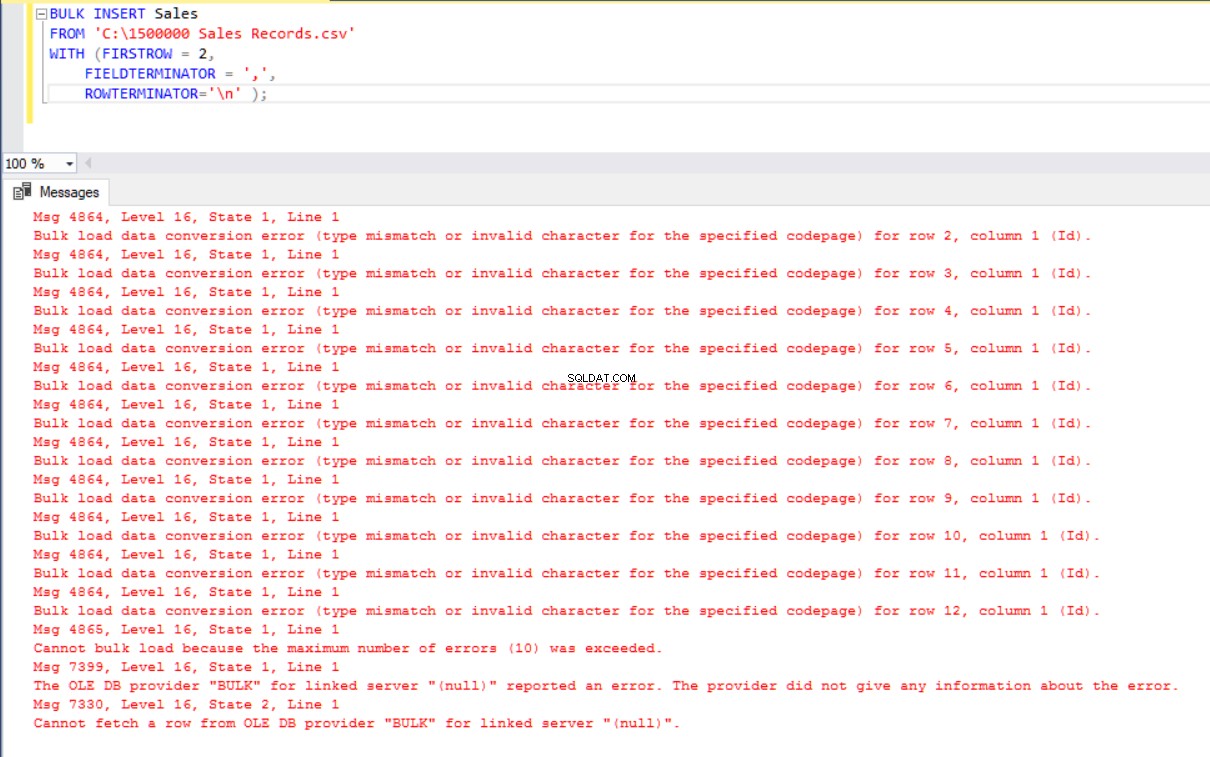
Aby obejść ten błąd, utworzymy widok tabeli Sprzedaż z mapowaniem kolumn do pliku CSV i zaimportujemy dane CSV z tego widoku do tabeli Sprzedaż.
DROP VIEW IF EXISTS VSales
GO
CREATE VIEW VSales
AS
SELECT Region ,
Country ,
ItemType ,
SalesChannel ,
OrderPriority ,
OrderDate ,
OrderID ,
ShipDate ,
UnitsSold ,
UnitPrice ,
UnitCost ,
TotalRevenue,
TotalCost,
TotalProfit from Sales
GO
BULK INSERT VSales
FROM 'C:\1500000 Sales Records.csv'
WITH ( FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ); Scenariusz-3:Jak oddzielić i załadować plik CSV do małego rozmiaru partii?
SQL Server uzyskuje blokadę do tabeli docelowej podczas operacji wstawiania zbiorczego. Domyślnie, jeśli nie ustawisz parametru BATCHSIZE, SQL Server otworzy transakcję i wstawi do tej transakcji całe dane CSV. Jeśli jednak ustawisz parametr BATCHSIZE, SQL Server podzieli dane CSV zgodnie z wartością tego parametru. W poniższym przykładzie podzielimy całe dane CSV na kilka zestawów po 300 000 wierszy każdy. W ten sposób dane zostaną zaimportowane 5 razy.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[OrderDate] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
batchsize=300000 );
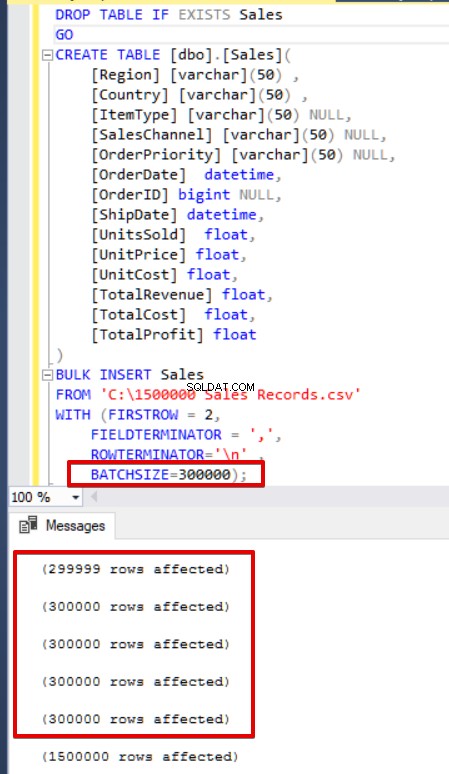
Jeśli instrukcja wstawiania zbiorczego nie zawiera parametru rozmiaru partii (BATCHSIZE), wystąpi błąd, a program SQL Server wycofa cały proces wstawiania zbiorczego. Z drugiej strony, jeśli ustawisz parametr rozmiaru partii na instrukcję zbiorczego wstawiania, SQL Server wycofa tylko tę podzieloną część, w której wystąpił błąd. Nie ma optymalnej ani najlepszej wartości dla tego parametru, ponieważ wartość tego parametru można zmienić zgodnie z wymaganiami systemu bazy danych.
Scenariusz-4:Jak anulować proces importowania, gdy pojawia się błąd?
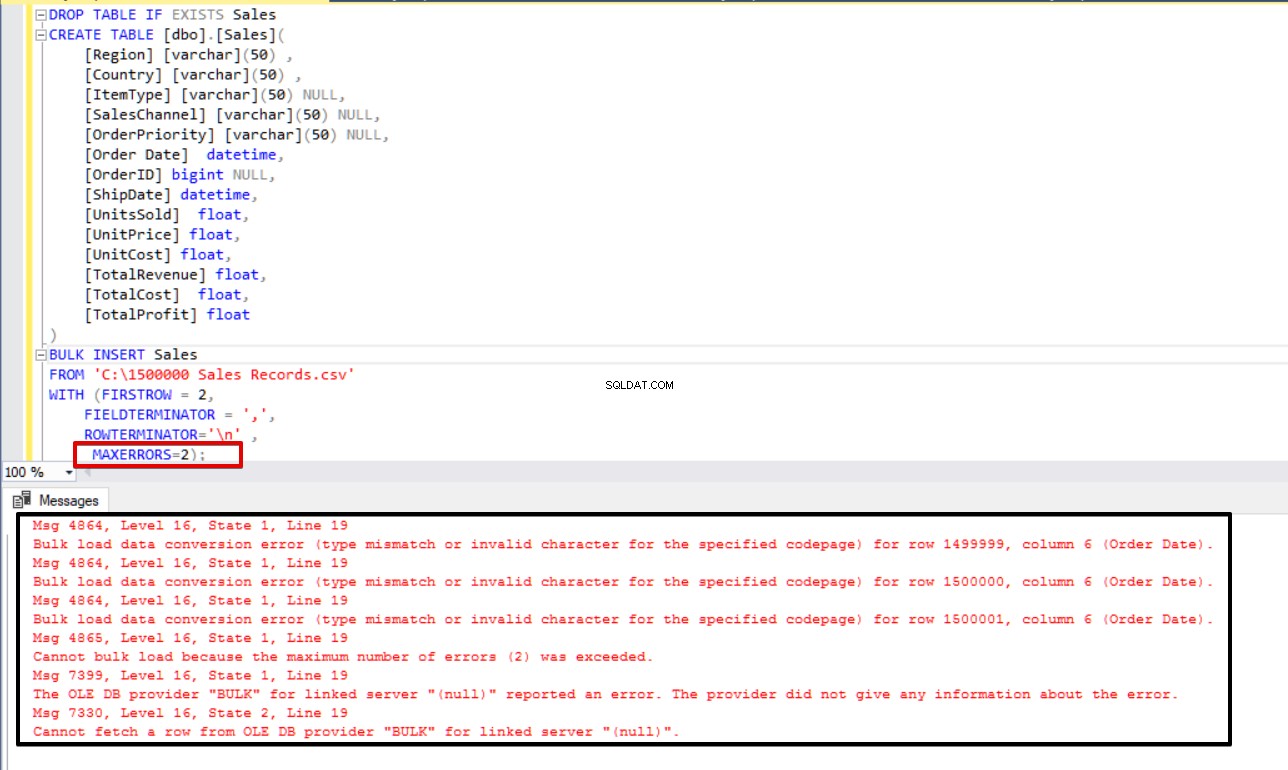
W niektórych scenariuszach kopiowania zbiorczego, jeśli wystąpi błąd, możemy anulować proces kopiowania zbiorczego lub kontynuować proces. Parametr MAXERRORS pozwala nam określić maksymalną liczbę błędów. Jeśli proces wstawiania zbiorczego osiągnie tę maksymalną wartość błędu, operacja importu zbiorczego zostanie anulowana i wycofana. Domyślna wartość tego parametru to 10.
W poniższym przykładzie celowo uszkodzimy typ danych w 3 wierszach pliku CSV i ustawimy parametr MAXERRORS na 2. W rezultacie cała operacja wstawiania zbiorczego zostanie anulowana, ponieważ liczba błędów przekracza parametr max error.

DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2);
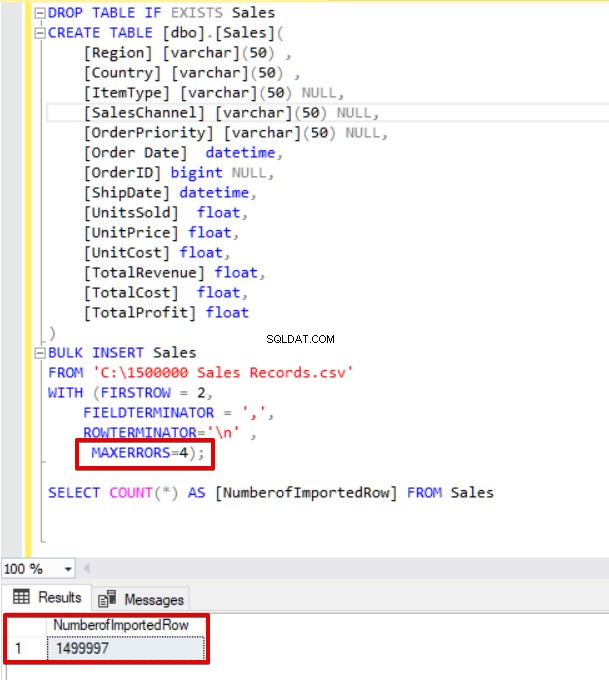
Teraz zmienimy parametr max error na 4. W rezultacie instrukcja bulk insert pominie te wiersze i wstawi odpowiednie wiersze o strukturze danych oraz zakończy proces zbiorczego wstawiania.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=4);
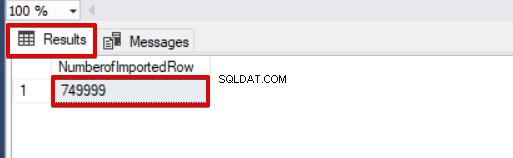
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
Ponadto, jeśli użyjemy jednocześnie parametrów rozmiaru partii i maksymalnego błędu, proces kopiowania zbiorczego nie anuluje całej operacji wstawiania, a jedynie anuluje podzieloną część.
DROP TABLE IF EXISTS Sales
CREATE TABLE [dbo].[Sales](
[Region] [varchar](50) ,
[Country] [varchar](50) ,
[ItemType] [varchar](50) NULL,
[SalesChannel] [varchar](50) NULL,
[OrderPriority] [varchar](50) NULL,
[Order Date] datetime,
[OrderID] bigint NULL,
[ShipDate] datetime,
[UnitsSold] float,
[UnitPrice] float,
[UnitCost] float,
[TotalRevenue] float,
[TotalCost] float,
[TotalProfit] float
)
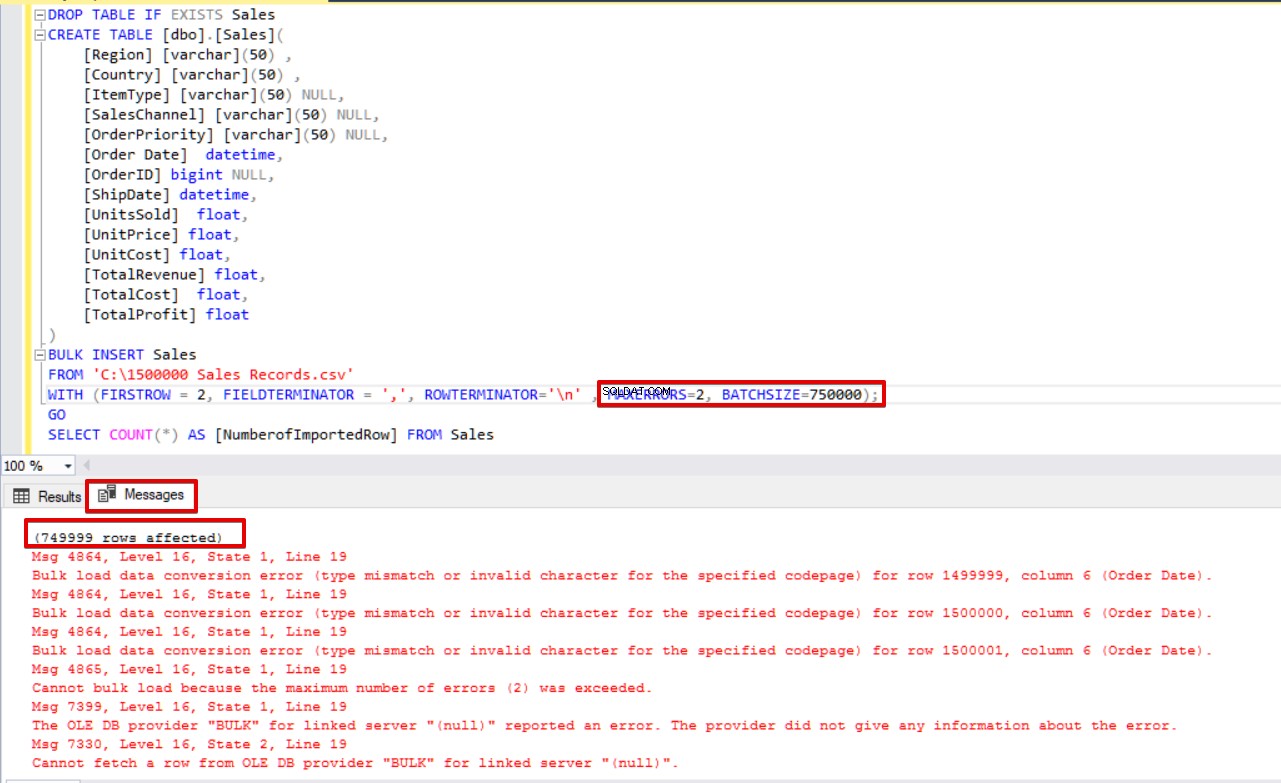
BULK INSERT Sales
FROM 'C:\1500000 Sales Records.csv'
WITH (FIRSTROW = 2,
FIELDTERMINATOR = ',',
ROWTERMINATOR='\n' ,
MAXERRORS=2,
BATCHSIZE=750000);
GO
SELECT COUNT(*) AS [NumberofImportedRow] FROM Sales
W pierwszej części tej serii artykułów omówiliśmy podstawy korzystania z operacji zbiorczego wstawiania w SQL Server i przeanalizowaliśmy kilka scenariuszy, które są zbliżone do rzeczywistych problemów.
Wstawianie zbiorcze programu SQL Server — część 2
Przydatne linki:
Wstaw zbiorczy
E for Excel – przykładowe pliki CSV / zestawy danych do testów (do 1,5 miliona rekordów)
Pobieranie Notepad++
Przydatne narzędzie:
dbForge Data Pump – dodatek SSMS do wypełniania baz danych SQL zewnętrznymi danymi źródłowymi i migracji danych między systemami.