Wprowadzenie
Ten samouczek zawiera informacje o SQL (DDL, DML), które zebrałem podczas mojego życia zawodowego. To minimum, które musisz znać pracując z bazami danych. Jeśli istnieje potrzeba użycia skomplikowanych konstrukcji SQL, to zazwyczaj przeglądam bibliotekę MSDN, którą można łatwo znaleźć w internecie. Moim zdaniem bardzo trudno jest trzymać wszystko w głowie, a przy okazji nie ma takiej potrzeby. Polecam znać wszystkie główne konstrukcje używane w większości relacyjnych baz danych, takich jak Oracle, MySQL i Firebird. Mimo to mogą różnić się typami danych. Na przykład do tworzenia obiektów (tabele, ograniczenia, indeksy itp.) można po prostu wykorzystać zintegrowane środowisko programistyczne (IDE) do pracy z bazami danych i nie ma potrzeby studiowania narzędzi wizualnych dla konkretnego typu bazy danych (MS SQL, Oracle , MySQL, Firebird itp.). Jest to wygodne, ponieważ możesz zobaczyć cały tekst i nie musisz przeszukiwać wielu zakładek, aby utworzyć np. indeks lub ograniczenie. Jeśli stale pracujesz z bazami danych, tworzenie, modyfikowanie, a zwłaszcza przebudowywanie obiektu za pomocą skryptów jest znacznie szybsze niż w trybie wizualnym. Poza tym moim zdaniem w trybie skryptowym (z należytą precyzją) łatwiej jest określić i kontrolować reguły nazewnictwa obiektów. Ponadto wygodnie jest używać skryptów, gdy trzeba przenieść zmiany w bazie danych z bazy testowej do bazy produkcyjnej.
SQL jest podzielony na kilka części. W moim artykule omówię najważniejsze z nich:
DDL – Język definicji danych
DML – Język manipulacji danymi, który obejmuje następujące konstrukcje:
- WYBIERZ – wybór danych
- INSERT – nowe wstawianie danych
- AKTUALIZACJA – aktualizacja danych
- USUŃ – usuwanie danych
- MERGE – scalanie danych
Wszystkie konstrukcje wyjaśnię w studiach przypadków. Ponadto uważam, że język programowania, zwłaszcza SQL, powinien być studiowany w praktyce, aby lepiej zrozumieć.
To jest samouczek krok po kroku, w którym podczas czytania musisz wykonywać przykłady. Jeśli jednak chcesz poznać szczegóły polecenia, surfuj po Internecie, na przykład MSDN.
Podczas tworzenia tego samouczka używałem bazy danych MS SQL Server w wersji 2014 i MS SQL Server Management Studio (SSMS) do wykonywania skryptów.
Krótko o MS SQL Server Management Studio (SSMS)
SQL Server Management Studio (SSMS) to narzędzie Microsoft SQL Server do konfigurowania, zarządzania i administrowania składnikami bazy danych. Zawiera edytor skryptów i program graficzny, który współpracuje z obiektami i ustawieniami serwera. Głównym narzędziem SQL Server Management Studio jest Object Explorer, który umożliwia użytkownikowi przeglądanie, pobieranie i zarządzanie obiektami serwera. Ten tekst jest częściowo zaczerpnięty z Wikipedii.
Aby utworzyć nowy edytor skryptów, użyj przycisku Nowe zapytanie:
Aby przełączyć się z bieżącej bazy danych, możesz użyć menu rozwijanego:
Aby wykonać określone polecenie lub zestaw poleceń, zaznacz je i naciśnij przycisk Wykonaj lub F5. Jeśli w edytorze jest tylko jedno polecenie lub musisz wykonać wszystkie polecenia, nie zaznaczaj niczego.
Po wykonaniu skryptów tworzących obiekty (tabele, kolumny, indeksy), wybierz odpowiedni obiekt (na przykład Tabele lub Kolumny), a następnie kliknij Odśwież w menu skrótów, aby zobaczyć zmiany.
Właściwie to wszystko, co musisz wiedzieć, aby wykonać podane tutaj przykłady.
Teoria
Relacyjna baza danych to zestaw połączonych ze sobą tabel. Ogólnie rzecz biorąc, baza danych to plik, który przechowuje uporządkowane dane.
Database Management System (DBMS) to zestaw narzędzi do pracy z określonymi typami baz danych (MS SQL, Oracle, MySQL, Firebird itp.).
Uwaga: Tak jak w naszym codziennym życiu, mówimy „Oracle DB” lub po prostu „Oracle”, co w rzeczywistości oznacza „Oracle DBMS”, więc w tym samouczku będę używał terminu „baza danych”.
Tabela to zestaw kolumn. Bardzo często można usłyszeć następujące definicje tych terminów:pola, wiersze i rekordy, które oznaczają to samo.
Głównym obiektem relacyjnej bazy danych jest tabela. Wszystkie dane są przechowywane wiersz po wierszu w kolumnach tabeli.
Dla każdej tabeli, jak również dla jej kolumn, musisz określić nazwę, według której możesz znaleźć żądany element.
Nazwa obiektu, tabeli, kolumny i indeksu może mieć minimalną długość – 128 znaków.
Uwaga: W bazach danych Oracle nazwa obiektu może mieć minimalną długość – 30 znaków. Dlatego w konkretnej bazie danych konieczne jest utworzenie niestandardowych reguł dla nazw obiektów.
SQL to język umożliwiający wykonywanie zapytań w bazach danych za pośrednictwem DBMS. W konkretnym DBMS język SQL może mieć swój własny dialekt.
DDL i DML – podjęzyk SQL:
- Język DDL służy do tworzenia i modyfikowania struktury bazy danych (usuwanie tabeli i linków);
- Język DML umożliwia manipulowanie danymi tabeli, jej wierszami. Służy również do wybierania danych z tabel, dodawania nowych danych, a także aktualizowania i usuwania bieżących danych.
W SQL można używać dwóch typów komentarzy (jednowierszowych i rozdzielanych):
-- single-line comment
i
/* delimited comment */
To wszystko co do teorii.
DDL — język definicji danych
Rozważmy przykładową tabelę z danymi o pracownikach przedstawionymi w sposób znany osobie, która nie jest programistą.
| Identyfikator pracownika | Imię i nazwisko | Data urodzenia | Pozycja | Dział | |
| 1000 | Jan | 19.02.1955 | example@sqldat.com | CEO | Administracja |
| 1001 | Daniel | 03.12.1983 | example@sqldat.com | programista | IT |
| 1002 | Mike | 07.06.1976 | example@sqldat.com | Księgowy | Dział kont |
| 1003 | Jordania | 17.04.1982 | example@sqldat.com | Starszy programista | IT |
W tym przypadku kolumny mają następujące tytuły:Identyfikator pracownika, Imię i nazwisko, Data urodzenia, E-mail, Stanowisko i Dział.
Możemy opisać każdą kolumnę tej tabeli według jej typu danych:
- Identyfikator pracownika – liczba całkowita
- Pełne imię i nazwisko – ciąg
- Data urodzenia – data
- E-mail – ciąg znaków
- Pozycja – ciąg
- Dział – ciąg
Typ kolumny to właściwość, która określa, jaki typ danych może przechowywać każda kolumna.
Na początek musisz pamiętać o głównych typach danych używanych w MS SQL:
| Definicja | Oznaczenie w MS SQL | Opis |
| Ciąg o zmiennej długości | varchar(N) i nvarchar(N) | Za pomocą liczby N możemy określić maksymalną możliwą długość ciągu dla konkretnej kolumny. Na przykład, jeśli chcemy powiedzieć, że wartość kolumny Pełna nazwa może zawierać 30 symboli (maksymalnie), to konieczne jest określenie typu nvarchar(30).
Różnica między varchar a nvarchar polega na tym, że varchar umożliwia przechowywanie ciągów w formacie ASCII, podczas gdy nvarchar przechowuje ciągi w formacie Unicode, gdzie każdy symbol zajmuje 2 bajty. |
| Ciąg o stałej długości | znak(N) i nchar(N) | Ten typ różni się od ciągu o zmiennej długości w następujący sposób:jeśli długość ciągu jest mniejsza niż N symboli, to spacje są zawsze dodawane do długości N po prawej stronie. Tak więc w bazie danych przyjmuje dokładnie N symboli, gdzie jeden symbol zajmuje 1 bajt na znak i 2 bajty na nchar. W mojej praktyce ten typ jest rzadko używany. Mimo to, jeśli ktoś go używa, to zwykle ten typ ma format char(1), tj. gdy pole jest zdefiniowane przez 1 symbol. |
| Liczba całkowita | int | Ten typ pozwala nam używać w kolumnie tylko liczb całkowitych (zarówno dodatnich, jak i ujemnych). Uwaga:zakres numerów dla tego typu jest następujący:od 2 147 483 648 do 2 147 483 647. Zwykle jest to główny typ używany do вуашту identyfikatorów. |
| Liczba zmiennoprzecinkowa | pływający | Liczby z kropką dziesiętną. |
| Data | data | Służy do przechowywania tylko daty (daty, miesiąca i roku) w kolumnie. Na przykład 15.02.2014. Ten typ może być użyty dla następujących kolumn:data odbioru, data urodzenia itp., kiedy musisz podać tylko datę lub kiedy czas nie jest dla nas ważny i możemy go usunąć. |
| Czas | czas | Możesz użyć tego typu, jeśli konieczne jest przechowywanie czasu:godzin, minut, sekund i milisekund. Na przykład masz 17:38:31.3231603 lub musisz dodać czas odlotu. |
| Data i godzina | data i godzina | Ten typ umożliwia użytkownikom przechowywanie zarówno daty, jak i godziny. Na przykład masz wydarzenie 15.02.2014 17:38:31.323. |
| Wskaźnik | bitowe | Możesz użyć tego typu do przechowywania wartości, takich jak „Tak”/„Nie”, gdzie „Tak” to 1, a „Nie” to 0. |
Ponadto nie jest konieczne określanie wartości pola, chyba że jest to zabronione. W takim przypadku możesz użyć wartości NULL.
Aby wykonać przykłady, utworzymy testową bazę danych o nazwie „Test”.
Aby utworzyć prostą bazę danych bez żadnych dodatkowych właściwości, uruchom następujące polecenie:
CREATE DATABASE Test
Aby usunąć bazę danych, wykonaj następujące polecenie:
DROP DATABASE Test
Aby przejść do naszej bazy danych użyj polecenia:
USE Test
Alternatywnie możesz wybrać Testuj bazę danych z menu rozwijanego w obszarze menu programu SSMS.
Teraz możemy utworzyć tabelę w naszej bazie danych za pomocą opisów, spacji i symboli cyrylicy:
CREATE TABLE [Employees]( [EmployeeID] int, [FullName] nvarchar(30), [Birthdate] date, [E-mail] nvarchar(30), [Position] nvarchar(30), [Department] nvarchar(30) )
W takim przypadku musimy owinąć nazwy w nawiasy kwadratowe […].
Jednak lepiej jest podawać wszystkie nazwy obiektów po łacinie i nie używać w nazwach spacji. W tym przypadku każde słowo zaczyna się od dużej litery. Na przykład w polu „Identyfikator pracownika” możemy podać nazwę PersonnelNumber. Możesz również użyć numerów w nazwie, na przykład NumerTelefonu1.
Uwaga: W niektórych SZBD wygodniej jest użyć następującego formatu nazwy «NUMER_TELEFONU». Na przykład możesz zobaczyć ten format w bazach danych ORACLE. Ponadto nazwa pola nie powinna pokrywać się ze słowami kluczowymi używanymi w DBMS.
Z tego powodu możesz zapomnieć o składni nawiasów kwadratowych i usunąć tabelę Pracownicy:
DROP TABLE [Employees]
Na przykład możesz nazwać tabelę z pracownikami jako „Pracownicy” i ustawić następujące nazwy dla jej pól:
- ID
- Nazwa
- Urodziny
- Pozycja
- Dział
Bardzo często używamy „ID” jako pola identyfikatora.
Teraz utwórzmy tabelę:
CREATE TABLE Employees( ID int, Name nvarchar(30), Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Aby ustawić obowiązkowe kolumny, możesz użyć opcji NOT NULL.
Dla bieżącej tabeli możesz przedefiniować pola za pomocą następujących poleceń:
-- ID field update ALTER TABLE Employees ALTER COLUMN ID int NOT NULL -- Name field update ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NOT NULL
Uwaga: Ogólna koncepcja języka SQL dla większości DBMS jest taka sama (z własnego doświadczenia). Różnica między DDL w różnych DBMS polega głównie na typach danych (mogą się różnić nie tylko nazwą, ale także specyficzną implementacją). Ponadto konkretna implementacja SQL (polecenia) jest taka sama, ale mogą występować niewielkie różnice w dialekcie. Znając podstawy SQL, możesz łatwo przełączać się z jednego DBMS na inny. W takim przypadku będziesz musiał jedynie zrozumieć specyfikę implementacji poleceń w nowym DBMS.
Porównaj te same polecenia w ORACLE DBMS:
-- create table CREATE TABLE Employees( ID int, -- In ORACLE the int type is a value for number(38) Name nvarchar2(30), -- in ORACLE nvarchar2 is identical to nvarchar in MS SQL Birthday date, Email nvarchar2(30), Position nvarchar2(30), Department nvarchar2(30) ); -- ID and Name field update (here we use MODIFY(…) instead of ALTER COLUMN ALTER TABLE Employees MODIFY(ID int NOT NULL,Name nvarchar2(30) NOT NULL); -- add PK (in this case the construction is the same as in the MS SQL) ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID);
ORACLE różni się implementacją typu varchar2. Jego format zależy od ustawień bazy danych i możesz zapisać tekst np. w UTF-8. Dodatkowo możesz określić długość pola zarówno w bajtach, jak i symbolach. Aby to zrobić, musisz użyć wartości BYTE i CHAR, a następnie pola długości. Na przykład:
NAME varchar2(30 BYTE) – field capacity equals 30 bytes NAME varchar2(30 CHAR) -- field capacity equals 30 symbols
Wartość (BYTE lub CHAR), która ma być używana domyślnie, gdy tylko wskażesz varchar2(30) w ORACLE, będzie zależeć od ustawień bazy danych. Często można się łatwo pomylić. Dlatego zalecam jawne określenie CHAR, gdy używasz typu varchar2 (na przykład z UTF-8) w ORACLE (ponieważ wygodniej jest odczytać długość ciągu w symbolach).
Jednak w tym przypadku, jeśli w tabeli znajdują się jakieś dane, aby pomyślnie wykonać polecenia, konieczne jest wypełnienie pól ID i Nazwa we wszystkich wierszach tabeli.
Pokażę to na konkretnym przykładzie.
Wstawmy dane w polach ID, Stanowisko i Dział za pomocą następującego skryptu:
INSERT Employees(ID,Position,Department) VALUES (1000,’CEO,N'Administration'), (1001,N'Programmer',N'IT'), (1002,N'Accountant',N'Accounts dept'), (1003,N'Senior Programmer',N'IT')
W takim przypadku polecenie INSERT również zwraca błąd. Dzieje się tak, ponieważ nie określiliśmy wartości obowiązkowego pola Nazwa.
Gdyby w oryginalnej tabeli były jakieś dane, zadziałałoby polecenie „ALTER TABLE Employees ALTER COLUMN ID int NOT NULL”, podczas gdy polecenie „ALTER TABLE Employees ALTER COLUMN Name int NOT NULL” zwróci błąd, który zawiera pole Name wartości NULL.
Dodajmy wartości w polu Nazwa:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Ponadto możesz użyć NOT NULL podczas tworzenia nowej tabeli za pomocą instrukcji CREATE TABLE.
Najpierw usuńmy tabelę:
DROP TABLE Employees
Teraz utworzymy tabelę z obowiązkowymi polami ID i Nazwa:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Można również określić NULL po nazwie kolumny, co oznacza, że dozwolone są wartości NULL. Nie jest to obowiązkowe, ponieważ ta opcja jest ustawiona domyślnie.
Jeśli chcesz, aby bieżąca kolumna była nieobowiązkowa, użyj następującej składni:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30) NULL
Alternatywnie możesz użyć tego polecenia:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(30)
Dodatkowo za pomocą tego polecenia możemy zmienić typ pola na inny kompatybilny lub zmienić jego długość. Na przykład rozszerzmy pole Nazwa do 50 symboli:
ALTER TABLE Employees ALTER COLUMN Name nvarchar(50)
Klucz główny
Tworząc tabelę, musisz określić kolumnę lub zestaw kolumn unikalny dla każdego wiersza. Używając tej unikalnej wartości, możesz zidentyfikować rekord. Ta wartość nazywana jest kluczem podstawowym. Kolumna ID (zawierająca „osobisty numer pracownika” – w naszym przypadku jest to unikalna wartość dla każdego pracownika i nie może być duplikowana) może być kluczem podstawowym dla naszej tabeli Pracownicy.
Możesz użyć następującego polecenia, aby utworzyć klucz podstawowy dla tabeli:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY(ID)
„PK_Employees” to nazwa ograniczenia definiująca klucz podstawowy. Zwykle nazwa klucza podstawowego składa się z przedrostka „PK_” i nazwy tabeli.
Jeśli klucz podstawowy zawiera kilka pól, musisz umieścić te pola w nawiasach, oddzielonych przecinkiem:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY(field1,field2,…)
Należy pamiętać, że w MS SQL wszystkie pola klucza podstawowego nie powinny mieć wartości NULL.
Poza tym podczas tworzenia tabeli możesz zdefiniować klucz podstawowy. Usuńmy tabelę:
DROP TABLE Employees
Następnie utwórz tabelę, używając następującej składni:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), CONSTRAINT PK_Employees PRIMARY KEY(ID) – describe PK after all the fileds as a constraint )
Dodaj dane do tabeli:
INSERT Employees(ID,Position,Department,Name) VALUES (1000,N'CEO',N'Administration',N'John'), (1001,N'Programmer',N'IT',N'Daniel'), (1002,N'Accountant',N'Accounts dept',N'Mike'), (1003,N'Senior Programmer',N'IT',N'Jordan’)
Właściwie nie musisz określać nazwy ograniczenia. W takim przypadku zostanie przypisana nazwa systemu. Na przykład «PK__Pracownik__3214EC278DA42077»:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30), PRIMARY KEY(ID) )
lub
CREATE TABLE Employees( ID int NOT NULL PRIMARY KEY, Name nvarchar(30) NOT NULL, Birthday date, Email nvarchar(30), Position nvarchar(30), Department nvarchar(30) )
Osobiście polecam jawne określenie nazwy ograniczenia dla stałych tabel, ponieważ w przyszłości łatwiej jest pracować z lub usuwać jawnie zdefiniowaną i wyraźną wartość. Na przykład:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees
Mimo to wygodniej jest zastosować tę krótką składnię, bez nazw ograniczeń, podczas tworzenia tymczasowych tabel bazy danych (nazwa tabeli tymczasowej zaczyna się od # lub ##).
Podsumowanie:
Przeanalizowaliśmy już następujące polecenia:
- UTWÓRZ TABELĘ nazwa_tabeli (lista pól i ich typów oraz ograniczeń) – służy do tworzenia nowej tabeli w aktualnej bazie danych;
- ZRZUT TABELI nazwa_tabeli – służy do usunięcia tabeli z aktualnej bazy danych;
- ZMIANA TABELI table_name ALTER COLUMN nazwa_kolumny … – służy do aktualizacji typu kolumny lub modyfikacji jej ustawień (np. gdy trzeba ustawić NULL lub NOT NULL);
- ZMIANA TABELI table_name DODAJ OGRANICZENIE bound_name KLUCZ PODSTAWOWY (pole1, pole2,…) – służy do dodawania klucza podstawowego do aktualnej tabeli;
- ZMIANA TABELI table_name OGRANICZENIE UPUSZCZENIA bound_name – służy do usuwania ograniczenia z tabeli.
Tabele tymczasowe
Wyciąg z MSDN. Istnieją dwa typy tabel tymczasowych w MS SQL Server:lokalne (#) i globalne (##). Lokalne tabele tymczasowe są widoczne tylko dla ich twórców, zanim wystąpienie SQL Server zostanie odłączone. Są one automatycznie usuwane po odłączeniu użytkownika od instancji SQL Server. Globalne tabele tymczasowe są widoczne dla wszystkich użytkowników podczas wszelkich sesji połączeń po utworzeniu tych tabel. Tabele te są usuwane po odłączeniu użytkowników od instancji SQL Server.
Tabele tymczasowe tworzone są w bazie danych systemu tempdb, co oznacza, że nie zalejemy głównej bazy danych. Dodatkowo możesz je usunąć za pomocą polecenia DROP TABLE. Bardzo często używane są lokalne (#) tabele tymczasowe.
Aby utworzyć tabelę tymczasową, możesz użyć polecenia CREATE TABLE:
CREATE TABLE #Temp( ID int, Name nvarchar(30) )
Możesz usunąć tymczasową tabelę za pomocą polecenia DROP TABLE:
DROP TABLE #Temp
Ponadto możesz utworzyć tymczasową tabelę i wypełnić ją danymi za pomocą składni SELECT … INTO:
SELECT ID,Name INTO #Temp FROM Employees
Uwaga: W różnych DBMS implementacja tymczasowych baz danych może się różnić. Na przykład w systemach DBMS ORACLE i Firebird strukturę tabel tymczasowych należy wcześniej zdefiniować za pomocą polecenia CREATE GLOBAL TEMPORARY TABLE. Musisz także określić sposób przechowywania danych. Następnie użytkownik widzi go wśród popularnych tabel i pracuje z nim tak, jak z konwencjonalnym stołem.
Normalizacja bazy danych:podział na podtabele (tabele referencyjne) i definiowanie relacji między tabelami
Nasza obecna tabela Pracownicy ma wadę:użytkownik może wpisać dowolny tekst w pola Stanowisko i Dział, co może zwracać błędy, gdyż dla jednego pracownika może określić dział „IT”, natomiast dla innego pracownika może określić „IT”. dział". W rezultacie nie będzie jasne, co miał na myśli użytkownik, czy ci pracownicy pracują w tym samym dziale, czy też jest błąd w pisowni i są 2 różne działy. Co więcej, w tym przypadku nie będziemy w stanie poprawnie pogrupować danych do raportu, w którym musimy pokazać liczbę pracowników dla każdego działu.
Kolejną wadą jest wielkość pamięci i jej duplikacja, tzn. trzeba podać pełną nazwę działu dla każdego pracownika, co wymaga miejsca w bazach danych na przechowywanie każdego symbolu nazwy działu.
Trzecią wadą jest złożoność aktualizacji danych terenowych, gdy trzeba zmienić nazwę dowolnej pozycji – od programisty do młodszego programisty. W takim przypadku będziesz musiał dodać nowe dane w każdym wierszu tabeli, w którym pozycja to „Programista”.
Aby uniknąć takich sytuacji, zaleca się stosowanie normalizacji bazy danych – podział na podtabele – tabele referencyjne.
Stwórzmy 2 tabele referencyjne „Pozycje” i „Dział”:
CREATE TABLE Positions( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Positions PRIMARY KEY, Name nvarchar(30) NOT NULL ) CREATE TABLE Departments( ID int IDENTITY(1,1) NOT NULL CONSTRAINT PK_Departments PRIMARY KEY, Name nvarchar(30) NOT NULL )
Zauważ, że tutaj użyliśmy nowej właściwości IDENTITY. Oznacza to, że dane w kolumnie ID będą automatycznie wyświetlane począwszy od 1. Tak więc przy dodawaniu nowych rekordów wartości 1, 2, 3 itd. będą nadawane sekwencyjnie. Zwykle pola te nazywane są polami autoinkrementacji. Tylko jedno pole z właściwością IDENTITY można zdefiniować jako klucz podstawowy w tabeli. Zwykle, ale nie zawsze, takie pole jest kluczem podstawowym tabeli.
Uwaga: W różnych DBMS implementacja pól z inkrementatorem może się różnić. Na przykład w MySQL takie pole jest zdefiniowane przez właściwość AUTO_INCREMENT. W ORACLE i Firebird można emulować tę funkcjonalność sekwencjami (SEQUENCE). Ale o ile wiem, właściwość GENERATED AS IDENTITY została dodana w ORACLE.
Wypełnijmy te tabele automatycznie na podstawie aktualnych danych w polach Stanowisko i Dział w tabeli Pracownicy:
-- fill in the Name field of the Positions table with unique values from the Position field of the Employees table INSERT Positions(Name) SELECT DISTINCT Position FROM Employees WHERE Position IS NOT NULL – drop records where a position is not specified
Musisz wykonać te same kroki dla tabeli Departamenty:
INSERT Departments(Name) SELECT DISTINCT Department FROM Employees WHERE Department IS NOT NULL
Teraz, jeśli otworzymy tabele Pozycje i Działy, zobaczymy ponumerowaną listę wartości w polu ID:
SELECT * FROM Positions
| ID | Nazwa |
| 1 | Księgowy |
| 2 | CEO |
| 3 | Programista |
| 4 | Starszy programista |
SELECT * FROM Departments
| ID | >Nazwa |
| 1 | Administracja |
| 2 | Dział kont |
| 3 | IT |
Tabele te będą tabelami referencyjnymi do definiowania stanowisk i działów. Teraz odniesiemy się do identyfikatorów stanowisk i działów. Najpierw utwórzmy nowe pola w tabeli Pracownicy do przechowywania identyfikatorów:
-- add a field for the ID position ALTER TABLE Employees ADD PositionID int -- add a field for the ID department ALTER TABLE Employees ADD DepartmentID int
Typ pól referencyjnych powinien być taki sam jak w tabelach referencyjnych, w tym przypadku jest to int.
Ponadto możesz dodać kilka pól za pomocą jednego polecenia, wymieniając pola oddzielone przecinkami:
ALTER TABLE Employees ADD PositionID int, DepartmentID int
Teraz dodamy ograniczenia referencyjne (FOREIGN KEY) do tych pól, aby użytkownik nie mógł dodać żadnych wartości, które nie są wartościami ID tabel referencyjnych.
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID)
Te same kroki należy wykonać dla drugiego pola:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID)
Teraz użytkownicy mogą wstawiać w te pola tylko wartości identyfikatorów z odpowiedniej tabeli referencyjnej. W związku z tym, aby użyć nowego działu lub stanowiska, użytkownik musi dodać nowy rekord w odpowiedniej tabeli referencyjnej. Ponieważ stanowiska i działy są przechowywane w tabelach referencyjnych w jednym egzemplarzu, aby zmienić ich nazwę, należy ją zmienić tylko w tabeli referencyjnej.
Nazwa ograniczenia referencyjnego jest zwykle złożona. Składa się z przedrostka «FK», po którym następuje nazwa tabeli i nazwa pola, która odnosi się do identyfikatora tabeli referencyjnej.
Identyfikator (ID) jest zwykle wartością wewnętrzną używaną tylko dla linków. Nie ma znaczenia, jaką ma wartość. Dlatego nie próbuj usuwać przerw w sekwencji wartości, które pojawiają się podczas pracy z tabelą, na przykład podczas usuwania rekordów z tabeli referencyjnej.
W niektórych przypadkach możliwe jest zbudowanie referencji z kilku pól:
ALTER TABLE table ADD CONSTRAINT constraint_name FOREIGN KEY(field1,field2,…) REFERENCES reference table(field1,field2,…)
W tym przypadku klucz podstawowy jest reprezentowany przez zestaw kilku pól (pole1, pole2, …) w tabeli „referencyjna tabela”.
Teraz zaktualizujmy pola PositionID i DepartmentID wartościami identyfikatorów z tabel referencyjnych.
W tym celu użyjemy polecenia UPDATE:
UPDATE e SET PositionID=(SELECT ID FROM Positions WHERE Name=e.Position), DepartmentID=(SELECT ID FROM Departments WHERE Name=e.Department) FROM Employees e
Uruchom następujące zapytanie:
SELECT * FROM Employees
| ID | Nazwa | Urodziny | Pozycja | Dział | Identyfikator pozycji | Identyfikator działu | |
| 1000 | Jan | NULL | NULL | Prezes | Administracja | 2 | 1 |
| 1001 | Daniel | NULL | NULL | Programista | IT | 3 | 3 |
| 1002 | Mike | NULL | NULL | Księgowy | Dział kont | 1 | 2 |
| 1003 | Jordania | NULL | NULL | Starszy programista | IT | 4 | 3 |
Jak widać, pola PositionID i DepartmentID pasują do stanowisk i działów. W ten sposób możesz usunąć pola Stanowisko i Dział w tabeli Pracownicy, wykonując następujące polecenie:
ALTER TABLE Employees DROP COLUMN Position,Department
Teraz uruchom to oświadczenie:
SELECT * FROM Employees
| ID | Nazwa | Urodziny | Poczta e-mail | Identyfikator pozycji | Identyfikator działu |
| 1000 | Jan | NULL | NULL | 2 | 1 |
| 1001 | Daniel | NULL | NULL | 3 | 3 |
| 1002 | Mike | NULL | NULL | 1 | 2 |
| 1003 | Jordania | NULL | NULL | 4 | 3 |
Therefore, we do not have information overload. We can define the names of positions and departments by their identifiers using the values in the reference tables:
SELECT e.ID,e.Name,p.Name PositionName,d.Name DepartmentName FROM Employees e LEFT JOIN Departments d ON d.ID=e.DepartmentID LEFT JOIN Positions p ON p.ID=e.PositionID
| ID | Name | PositionName | DepartmentName |
| 1000 | John | CEO | Administration |
| 1001 | Daniel | Programmer | IT |
| 1002 | Mike | Accountant | Accounts dept |
| 1003 | Jordan | Senior programmer | IT |
In the object inspector, we can see all the objects created for this table. Here we can also manipulate these objects in different ways, for example, rename or delete the objects.
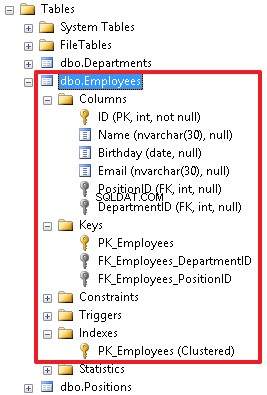
In addition, it should be noted that it is possible to create a recursive reference.
Let’s consider this particular example.
Let’s add the ManagerID field to the table with employees. This new field will define an employee to whom this employee is subordinated.
ALTER TABLE Employees ADD ManagerID int
This field permits the NULL value as well.
Now, we will create a FOREIGN KEY for the Employees table:
ALTER TABLE Employees ADD CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID)
Then create a diagram and check how our tables are linked:
As you can see, the Employees table is linked with the Positions and Departments tables and is a recursive reference.
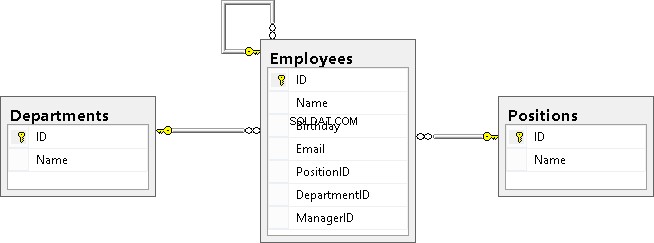
Finally, I would like to note that reference keys can include additional properties such as ON DELETE CASCADE and ON UPDATE CASCADE. They define the behavior when deleting or updating a record that is referenced from the reference table. If these properties are not specified, then we cannot change the ID of the record in the reference table referenced from the other table. Also, we cannot delete this record from the reference table until we remove all the rows that refer to this record or update the references to another value in these rows.
For example, let’s re-create the table and specify the ON DELETE CASCADE property for FK_Employees_DepartmentID:
DROP TABLE Employees CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID) ON DELETE CASCADE, CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID) ) INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Let’s delete the department with identifier ‘3’ from the Departments table:
DELETE Departments WHERE ID=3
Let’s view the data in table Employees:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | |
| 1000 | John | 1955-02-19 | NULL | 2 | 1 | NULL |
| 1002 | Mike | 1976-06-07 | NULL | 1 | 2 | 1000 |
As you can see, data of Department ‘3’ has been deleted from the Employees table as well.
The ON UPDATE CASCADE property has similar behavior, but it works when updating the ID value in the reference table. For example, if we change the position ID in the Positions reference table, then DepartmentID in the Employees table will receive a new value, which we have specified in the reference table. But in this case this cannot be demonstrated, because the ID column in the Departments table has the IDENTITY property, which will not allow us to execute the following query (change the department identifier from 3 to 30):
UPDATE Departments SET ID=30 WHERE ID=3
The main point is to understand the essence of these 2 options ON DELETE CASCADE and ON UPDATE CASCADE. I apply these options very rarely, and I recommend that you think carefully before you specify them in the reference constraint, because If an entry is accidentally deleted from the reference table, this can lead to big problems and create a chain reaction.
Let’s restore department ‘3’:
-- we permit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments ON INSERT Departments(ID,Name) VALUES(3,N'IT') -- we prohibit to add or modify the IDENTITY value SET IDENTITY_INSERT Departments OFF
We completely clear the Employees table using the TRUNCATE TABLE command:
TRUNCATE TABLE Employees
Again, we will add data using the INSERT command:
INSERT Employees (ID,Name,Birthday,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',2,1,NULL), (1001,N'Daniel','19831203',3,3,1003), (1002,N'Mike','19760607',1,2,1000), (1003,N'Jordan','19820417',4,3,1000)
Podsumowanie:
We have described the following DDL commands:
• Adding the IDENTITY property to a field allows to make this field automatically populated (count field) for the table;
• ALTER TABLE table_name ADD field_list with_features – allows you to add new fields to the table;
• ALTER TABLE table_name DROP COLUMN field_list – allows you to delete fields from the table;
• ALTER TABLE table_name ADD CONSTRAINT constraint_name FOREIGN KEY (fields) REFERENCES reference_table – allows you to determine the relationship between a table and a reference table.
Other constraints – UNIQUE, DEFAULT, CHECK
Using the UNIQUE constraint, you can say that the values for each row in a given field or in a set of fields must be unique. In the case of the Employees table, we can apply this restriction to the Email field. Let’s first fill the Email values, if they are not yet defined:
UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1000 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1001 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1002 UPDATE Employees SET Email='example@sqldat.com' WHERE ID=1003
Now, you can impose the UNIQUE constraint on this field:
ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE(Email)
Thus, a user will not be able to enter the same email for several employees.
The UNIQUE constraint has the following structure:the «UQ» prefix followed by the table name and a field name (after the underscore), to which the restriction applies.
When you need to add the UNIQUE constraint for the set of fields, we will list them separated by commas:
ALTER TABLE table_name ADD CONSTRAINT constraint_name UNIQUE(field1,field2,…)
By adding a DEFAULT constraint to a field, we can specify a default value that will be inserted if, when inserting a new record, this field is not listed in the list of fields in the INSERT command. You can set this restriction when creating a table.
Let’s add the HireDate field to the Employees table and set the current date as a default value:
ALTER TABLE Employees ADD HireDate date NOT NULL DEFAULT SYSDATETIME()
If the HireDate column already exists, then we can use the following syntax:
ALTER TABLE Employees ADD DEFAULT SYSDATETIME() FOR HireDate
To specify the default value, execute the following command:
ALTER TABLE Employees ADD CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME() FOR HireDate
As there was no such column before, then when adding it, the current date will be inserted into each entry of the HireDate field.
When creating a new record, the current date will be also automatically added, unless we explicitly specify it, i.e. specify in the list of columns. Let’s demonstrate this with an example, where we will not specify the HireDate field in the list of the values added:
INSERT Employees(ID,Name,Email)VALUES(1004,N'Ostin',' example@sqldat.com')
To check the result, run the command:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | ManagerID | HireDate | |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | NULL | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 4 | 1003 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 1000 | 2015-04-08 |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 1000 | 2015-04-08 |
| 1004 | Ostin | NULL | example@sqldat.com | NULL | NULL | NULL | 2015-04-08 |
The CHECK constraint is used when it is necessary to check the values being inserted in the fields. For example, let’s impose this constraint on the identification number field, which is an employee ID (ID). Let’s limit the identification numbers to be in the range from 1000 to 1999:
ALTER TABLE Employees ADD CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999)
The constraint name is usually as follows:the «CK_» prefix first followed by the table name and a field name, for which constraint is imposed.
Let’s add an invalid record to check if the constraint is working properly (we will get the corresponding error):
INSERT Employees(ID,Email) VALUES(2000,'example@sqldat.com')
Now, let’s change the value being inserted to 1500 and make sure that the record is inserted:
INSERT Employees(ID,Email) VALUES(1500,'example@sqldat.com')
We can also create UNIQUE and CHECK constraints without specifying a name:
ALTER TABLE Employees ADD UNIQUE(Email) ALTER TABLE Employees ADD CHECK(ID BETWEEN 1000 AND 1999)
Still, this is a bad practice and it is desirable to explicitly specify the constraint name so that users can see what each object defines:
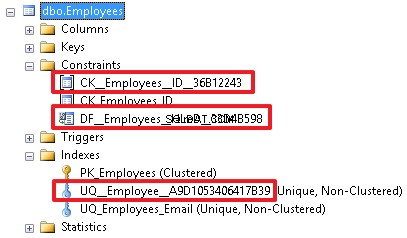
A good name gives us more information about the constraint. And, accordingly, all these restrictions can be specified when creating a table, if it does not exist yet.
Let’s delete the table:
DROP TABLE Employees
Let’s re-create the table with all the specified constraints using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL DEFAULT SYSDATETIME(), -- I have an exception for DEFAULT CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT UQ_Employees_Email UNIQUE (Email), CONSTRAINT CK_Employees_ID CHECK (ID BETWEEN 1000 AND 1999) )
Finally, let’s insert our employees in the table:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3), (1002,N'Mike','19760607',' example@sqldat.com ',1,2), (1003,N'Jordan','19820417',' example@sqldat.com',4,3)
Some words about the indexes created with the PRIMARY KEY and UNIQUE constraints
When creating the PRIMARY KEY and UNIQUE constraints, the indexes with the same names (PK_Employees and UQ_Employees_Email) are automatically created. By default, the index for the primary key is defined as CLUSTERED, and for other indexes, it is set as NONCLUSTERED.
It should be noted that the clustered index is not used in all DBMSs. A table can have only one clustered (CLUSTERED) index. It means that the records of the table will be ordered by this index. In addition, we can say that this index has direct access to all the data in the table. This is the main index of the table. A clustered index can help with the optimization of queries. If we want to set the clustered index for another index, then when creating the primary key, we should specify the NONCLUSTERED property:
ALTER TABLE table_name ADD CONSTRAINT constraint_name PRIMARY KEY NONCLUSTERED(field1,field2,…)
Let’s specify the PK_Employees constraint index as nonclustered, while the UQ_Employees_Email constraint index – as clustered. At first, delete these constraints:
ALTER TABLE Employees DROP CONSTRAINT PK_Employees ALTER TABLE Employees DROP CONSTRAINT UQ_Employees_Email
Now, create them with the CLUSTERED and NONCLUSTERED indexes:
ALTER TABLE Employees ADD CONSTRAINT PK_Employees PRIMARY KEY NONCLUSTERED (ID) ALTER TABLE Employees ADD CONSTRAINT UQ_Employees_Email UNIQUE CLUSTERED (Email)
Once it is done, you can see that records have been sorted by the UQ_Employees_Email clustered index:
SELECT * FROM Employees
| ID | Name | Birthday | PositionID | DepartmentID | HireDate | |
| 1003 | Jordan | 1982-04-17 | example@sqldat.com | 4 | 3 | 2015-04-08 |
| 1000 | John | 1955-02-19 | example@sqldat.com | 2 | 1 | 2015-04-08 |
| 1001 | Daniel | 1983-12-03 | example@sqldat.com | 3 | 3 | 2015-04-08 |
| 1002 | Mike | 1976-06-07 | example@sqldat.com | 1 | 2 | 2015-04-08 |
For reference tables, it is better when a clustered index is built on the primary key, as in queries we often refer to the identifier of the reference table to obtain a name (Position, Department). The clustered index has direct access to the rows of the table, and hence it follows that we can get the value of any column without additional overhead.
It is recommended that the clustered index should be applied to the fields that you use for selection very often.
Sometimes in tables, a key is created by the stubbed field. In this case, it is a good idea to specify the CLUSTERED index for an appropriate index and specify the NONCLUSTERED index when creating the stubbed field.
Summary:
We have analyzed all the constraint types that are created with the «ALTER TABLE table_name ADD CONSTRAINT constraint_name …» command:
- PRIMARY KEY;
- FOREIGN KEY controls links and data referential integrity;
- UNIQUE – serves for setting a unique value;
- CHECK – allows monitoring the correctness of added data;
- DEFAULT – allows specifying a default value;
- The «ALTER TABLE table_name DROP CONSTRAINT constraint_name» command allows deleting all the constraints.
Additionally, we have reviewed the indexes:CLUSTERED and UNCLUSTERED.
Creating unique indexes
I am going to analyze indexes created not for the PRIMARY KEY or UNIQUE constraints.
It is possible to set indexes by a field or a set of fields using the following command:
CREATE INDEX IDX_Employees_Name ON Employees(Name)
Also, you can add the CLUSTERED, NONCLUSTERED, and UNIQUE properties as well as specify the order:ASC (by default) or DESC.
CREATE UNIQUE NONCLUSTERED INDEX UQ_Employees_EmailDesc ON Employees(Email DESC)
When creating the nonclustered index, the NONCLUSTERED property can be dropped as it is set by default.
To delete the index, use the command:
DROP INDEX IDX_Employees_Name ON Employees
You can create simple indexes and constraints with the CREATE TABLE command.
At first, delete the table:
DROP TABLE Employees
Then, create the table with all the constraints and indexes using the CREATE TABLE command:
CREATE TABLE Employees( ID int NOT NULL, Name nvarchar(30), Birthday date, Email nvarchar(30), PositionID int, DepartmentID int, HireDate date NOT NULL CONSTRAINT DF_Employees_HireDate DEFAULT SYSDATETIME(), ManagerID int, CONSTRAINT PK_Employees PRIMARY KEY (ID), CONSTRAINT FK_Employees_DepartmentID FOREIGN KEY(DepartmentID) REFERENCES Departments(ID), CONSTRAINT FK_Employees_PositionID FOREIGN KEY(PositionID) REFERENCES Positions(ID), CONSTRAINT FK_Employees_ManagerID FOREIGN KEY (ManagerID) REFERENCES Employees(ID), CONSTRAINT UQ_Employees_Email UNIQUE(Email), CONSTRAINT CK_Employees_ID CHECK(ID BETWEEN 1000 AND 1999), INDEX IDX_Employees_Name(Name) )
Finally, add information about our employees:
INSERT Employees (ID,Name,Birthday,Email,PositionID,DepartmentID,ManagerID)VALUES (1000,N'John','19550219',' example@sqldat.com ',2,1,NULL), (1001,N'Daniel','19831203',' example@sqldat.com ',3,3,1003), (1002,N'Mike','19760607',' example@sqldat.com ',1,2,1000), (1003,N'Jordan','19820417',' example@sqldat.com',4,3,1000)
Keep in mind that it is possible to add values with the INCLUDE command in the nonclustered index. Thus, in this case, the INCLUDE index is a clustered index where the necessary values are linked to the index, rather than to the table. These indexes can improve the SELECT query performance if there are all the required fields in the index. However, it may lead to increasing the index size, as field values are duplicated in the index.
Abstract from MSDN. Here is how the syntax of the command to create indexes looks:
CREATE [ UNIQUE ] [ CLUSTERED | NONCLUSTERED ] INDEX index_name ON <object> ( column [ ASC | DESC ] [ ,...n ] ) [ INCLUDE ( column_name [ ,...n ] ) ]
Podsumowanie
Indexes can simultaneously improve the SELECT query performance and lead to poor speed for modifying table data. This happens, as you need to rebuild all the indexes for a particular table after each system modification.
The strategy on creating indexes may depend on many factors such as frequency of data modifications in the table.
Conclusion
As you can see, the DDL language is not as difficult as it may seem. I have provided almost all the main constructions. I wish you good luck with studying the SQL language.



