Ten artykuł jest siódmą częścią serii poświęconej nazwanym wyrażeniom tabelowym. W części 5 i 6 omówiłem aspekty pojęciowe wspólnych wyrażeń tabelowych (CTE). W tym miesiącu i następnym skupiam się na rozważaniach dotyczących optymalizacji CTE.
Zacznę od szybkiego powrotu do koncepcji rozgnieżdżania nazwanych wyrażeń tabelowych i zademonstrowania jej zastosowania do CTE. Następnie skupię się na rozważaniach dotyczących wytrwałości. Opowiem o aspektach trwałości rekurencyjnych i nierekurencyjnych CTE. Wyjaśnię, kiedy trzymanie się CTE ma sens, a kiedy faktycznie bardziej sensowna jest praca z tabelami tymczasowymi.
W moich przykładach będę kontynuował korzystanie z przykładowych baz danych TSQLV5 i PerformanceV5. Skrypt, który tworzy i wypełnia TSQLV5, można znaleźć tutaj, a jego diagram ER znajduje się tutaj. Skrypt, który tworzy i wypełnia PerformanceV5, znajdziesz tutaj.
Zastępowanie/rozmieszczanie
W części 4 serii, która skupiała się na optymalizacji tabel pochodnych, opisałem proces rozgnieżdżania/podstawiania wyrażeń tabelarycznych. Wyjaśniłem, że kiedy SQL Server optymalizuje zapytanie obejmujące tabele pochodne, stosuje reguły transformacji do początkowego drzewa operatorów logicznych generowanych przez parser, prawdopodobnie przesuwając rzeczy poza granice wyrażeń tabelowych. Dzieje się tak do tego stopnia, że podczas porównywania planu zapytania przy użyciu tabel pochodnych z planem zapytania, który odnosi się bezpośrednio do bazowych tabel podstawowych, w których samodzielnie zastosowano logikę rozgnieżdżania, wyglądają tak samo. Opisałem również technikę zapobiegania rozgnieżdżaniu przy użyciu filtra TOP z bardzo dużą liczbą wierszy jako danych wejściowych. Zademonstrowałem kilka przypadków, w których ta technika była całkiem przydatna — jeden, w którym celem było uniknięcie błędów, a drugi ze względów optymalizacyjnych.
Wersja TL;DR podstawiania/rozmieszczania CTE polega na tym, że proces jest taki sam, jak w przypadku tabel pochodnych. Jeśli jesteś zadowolony z tego stwierdzenia, możesz pominąć tę sekcję i przejść od razu do następnej sekcji o Trwałości. Nie przegapisz niczego ważnego, czego wcześniej nie czytałeś. Jeśli jednak jesteś podobny do mnie, prawdopodobnie chcesz dowodu, że tak rzeczywiście jest. Następnie prawdopodobnie zechcesz kontynuować czytanie tej sekcji i przetestować kod, którego używam, ponownie odwiedzając kluczowe przykłady rozmieszczania, które wcześniej zademonstrowałem z tabelami pochodnymi, i przekonwertować je, aby używały CTE.
W części 4 zademonstrowałem następujące zapytanie (nazwiemy je Zapytanie 1):
UŻYJ TSQLV5; SELECT idzamowienia, datazamowienia FROM ( SELECT * FROM ( SELECT * FROM ( SELECT * FROM Sprzedaż.Zamówienia WHERE datazamowienia>='20180101' ) AS D1 WHERE datazamówienia>='20180201' ) AS D2 WHERE datazamówienia>='20180301' ) AS D3 GDZIE data zamówienia>='20180401';
Zapytanie obejmuje trzy poziomy zagnieżdżenia tabel pochodnych oraz zapytanie zewnętrzne. Każdy poziom filtruje inny zakres dat zamówień. Plan dla zapytania 1 pokazano na rysunku 1.
 Rysunek 1:Plan wykonania dla zapytania 1
Rysunek 1:Plan wykonania dla zapytania 1
Plan na rysunku 1 wyraźnie pokazuje, że miało miejsce rozgnieżdżanie tabel pochodnych, ponieważ wszystkie predykaty filtrów zostały połączone w jeden obejmujący predykat filtru.
Wyjaśniłem, że możesz zapobiec procesowi rozgnieżdżania, używając znaczącego filtra TOP (w przeciwieństwie do TOP 100 PERCENT) z bardzo dużą liczbą wierszy jako danych wejściowych, jak pokazuje następujące zapytanie (nazwiemy je Zapytanie 2):
SELECT identyfikator zamówienia, data zamówienia FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE datazam 20180201' ) AS D2 WHERE data zamówienia>='20180301' ) AS D3 WHERE data zamówienia>='20180401';
Plan dla zapytania 2 pokazano na rysunku 2.
 Rysunek 2:Plan wykonania dla zapytania 2
Rysunek 2:Plan wykonania dla zapytania 2
Plan wyraźnie pokazuje, że rozgnieżdżanie nie miało miejsca, ponieważ można skutecznie zobaczyć wyprowadzone granice tabeli.
Wypróbujmy te same przykłady przy użyciu CTE. Oto zapytanie 1 przekonwertowane na używanie CTE:
WITH C1 AS ( SELECT * FROM Sales.Orders WHERE datazamowienia>='20180101' ), C2 AS ( SELECT * FROM C1 WHERE datazamowienia>='20180201' ), C3 AS ( SELECT * FROM C2 WHERE datazamowienia>=' 20180301' ) SELECT identyfikator zamówienia, data zamówienia FROM C3 WHERE data zamówienia>='20180401';
Dostajesz dokładnie taki sam plan, jak pokazano wcześniej na Rysunku 1, gdzie widać, że miało miejsce rozgnieżdżanie.
Oto zapytanie 2 przekonwertowane na używanie CTE:
WITH C1 AS ( SELECT TOP (9223372036854775807) * FROM Sales.Orders WHERE data zamówienia>='20180101' ), C2 AS ( SELECT TOP (9223372036854775807) * FROM C1 WHERE data order>='20180201' ), C3 AS ( SELECT TOP (9223372036854775807) * FROM C2 WHERE datazamDostajesz taki sam plan, jak pokazano wcześniej na Rysunku 2, gdzie widać, że rozgnieżdżanie nie miało miejsca.
Następnie wróćmy do dwóch przykładów, których użyłem, aby zademonstrować praktyczność techniki zapobiegania rozgnieżdżaniu — tylko tym razem przy użyciu CTE.
Zacznijmy od błędnego zapytania. Następujące zapytanie próbuje zwrócić wiersze zamówienia z rabatem większym niż minimalny rabat i gdzie odwrotność rabatu jest większa niż 10:
SELECT id zamówienia, id produktu, rabat FROM Sprzedaż.SzczegółyZamówienia WHERE rabat> (SELECT MIN(rabat) FROM Sprzedaż.SzczegółyZamówienia) AND 1.0 / rabat> 10.0;Minimalna zniżka nie może być ujemna, a raczej równa zero lub wyższa. Tak więc prawdopodobnie myślisz, że jeśli wiersz ma zerową zniżkę, pierwszy predykat powinien mieć wartość fałszu, a zwarcie powinno uniemożliwić próbę oszacowania drugiego predykatu, a tym samym uniknąć błędu. Jednak po uruchomieniu tego kodu pojawia się błąd dzielenia przez zero:
Komunikat 8134, poziom 16, stan 1, wiersz 99 Wystąpił błąd dzielenia przez zero.Problem polega na tym, że chociaż SQL Server obsługuje koncepcję zwarcia na poziomie przetwarzania fizycznego, nie ma pewności, że oceni predykaty filtra w kolejności pisemnej od lewej do prawej. Typową próbą uniknięcia takich błędów jest użycie nazwanego wyrażenia tabelowego, które obsługuje część logiki filtrowania, która ma zostać przeanalizowana jako pierwsza, a zewnętrzne zapytanie obsługuje logikę filtrowania, która ma być oceniana jako druga. Oto próba rozwiązania przy użyciu CTE:
WITH C AS ( SELECT * FROM Sales.OrderDetails WHERE rabat> (SELECT MIN(rabat) FROM Sales.OrderDetails) ) SELECT identyfikator zamówienia, identyfikator produktu, rabat FROM C WHERE 1.0 / rabat> 10.0;Niestety, rozgnieżdżenie wyrażenia tabeli skutkuje logicznym odpowiednikiem oryginalnego zapytania o rozwiązanie, a przy próbie uruchomienia tego kodu ponownie pojawia się błąd dzielenia przez zero:
Komunikat 8134, poziom 16, stan 1, wiersz 108. Wystąpił błąd dzielenia przez zero.Używając naszego triku z filtrem TOP w wewnętrznym zapytaniu, zapobiegasz rozgnieżdżaniu wyrażenia tabeli, na przykład:
WITH C AS ( SELECT TOP (9223372036854775807) * FROM Sales.OrderDetails WHERE rabat> (SELECT MIN(rabat) FROM Sales.OrderDetails) ) SELECT identyfikator zamówienia, identyfikator produktu, rabat FROM C WHERE 1.0 / rabat> 10.0;Tym razem kod działa pomyślnie bez żadnych błędów.
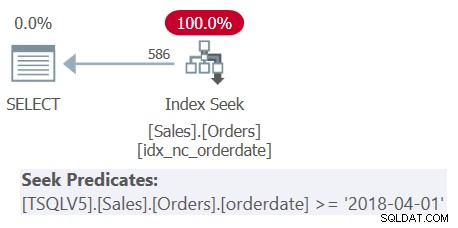
Przejdźmy do przykładu, w którym wykorzystujesz technikę do zapobiegania rozgnieżdżaniu w celu optymalizacji. Poniższy kod zwraca tylko nadawców, których maksymalna data zamówienia przypada 1 stycznia 2018 r. lub później:
USE PerformanceV5; WITH C AS ( SELECT S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid, maxod FROM C WHERE maxod> =„20180101”;Jeśli zastanawiasz się, dlaczego nie skorzystać ze znacznie prostszego rozwiązania z pogrupowanym zapytaniem i filtrem HAVING, ma to związek z zagęszczeniem kolumny shipperid. Tabela Zamówienia zawiera 1 000 000 zamówień, a wysyłki tych zamówień były obsługiwane przez pięciu nadawców, co oznacza, że średnio każdy nadawca obsłużył 20% zamówień. Plan zgrupowanego zapytania obliczającego maksymalną datę zamówienia na dostawcę przeskanowałby wszystkie 1 000 000 wierszy, co dałoby tysiące odczytów stron. Rzeczywiście, jeśli podświetlisz tylko wewnętrzne zapytanie CTE (nazwiemy je Zapytanie 3), obliczając maksymalną datę zamówienia na nadawcę i sprawdzisz jego plan wykonania, otrzymasz plan pokazany na rysunku 3.
Rysunek 3:Plan wykonania dla zapytania 3
Plan skanuje pięć wierszy w indeksie klastrowym na nadawcach. Dla każdego nadawcy plan stosuje wyszukiwanie według indeksu pokrycia w Zamówieniach, gdzie (nadawca, data zamówienia) to klucze wiodące indeksu, przechodzące bezpośrednio do ostatniego wiersza w każdej sekcji nadawcy na poziomie liścia, aby pobrać maksymalną datę zamówienia dla bieżącego spedytor. Ponieważ mamy tylko pięciu spedytorów, jest tylko pięć operacji wyszukiwania indeksu, co daje bardzo wydajny plan. Oto miary wydajności, które uzyskałem, gdy wykonałem wewnętrzne zapytanie CTE:
czas trwania:0 ms, procesor:0 ms, odczyt:15Jednak po uruchomieniu kompletnego rozwiązania (nazwiemy je Zapytanie 4), otrzymasz zupełnie inny plan, jak pokazano na rysunku 4.
Rysunek 4:Plan wykonania dla zapytania 4
Stało się tak, że SQL Server rozpakował wyrażenie tabelowe, przekształcając rozwiązanie w logiczny odpowiednik zapytania zgrupowanego, co skutkowało pełnym skanowaniem indeksu w Zamówieniach. Oto numery wydajności, które otrzymałem dla tego rozwiązania:
czas trwania:316 ms, procesor:281 ms, odczyt:3854Potrzebujemy tutaj, aby zapobiec rozgnieżdżeniu wyrażenia tabeli, tak aby zapytanie wewnętrzne zostało zoptymalizowane za pomocą wyszukiwania względem indeksu w Orders, a zapytanie zewnętrzne spowodowało dodanie operatora filtru w plan. Osiągasz to, korzystając z naszego triku, dodając filtr TOP do wewnętrznego zapytania, tak jak to (nazwiemy to rozwiązanie Zapytanie 5):
WITH C AS ( SELECT TOP (9223372036854775807) S.shipperid, (SELECT MAX(O.orderdate) FROM dbo.Orders AS O WHERE O.shipperid =S.shipperid) AS maxod FROM dbo.Shippers AS S ) SELECT shipperid , maxod FROM C WHERE maxod>='20180101';Plan tego rozwiązania pokazano na rysunku 5.
Rysunek 5:Plan wykonania dla zapytania 5
Z planu wynika, że osiągnięto zamierzony efekt, co potwierdzają dane dotyczące wydajności:
czas trwania:0 ms, procesor:0 ms, odczyt:15Tak więc nasze testy potwierdzają, że SQL Server obsługuje podstawianie/rozmieszczanie CTE tak samo, jak w przypadku tabel pochodnych. Oznacza to, że nie powinieneś preferować jednego nad drugim ze względu na optymalizację, a raczej ze względu na różnice koncepcyjne, które są dla Ciebie ważne, jak omówiono w Części 5.
Trwałość
Powszechnym błędnym przekonaniem dotyczącym CTE i ogólnie nazwanych wyrażeń tabelowych jest to, że służą one jako pewnego rodzaju wehikuł trwałości. Niektórzy uważają, że SQL Server utrwala zestaw wyników wewnętrznego zapytania w tabeli roboczej, a zapytanie zewnętrzne faktycznie współdziała z tą tabelą roboczą. W praktyce zwykłe nierekurencyjne CTE i tabele pochodne nie są utrwalane. Opisałem logikę rozgnieżdżania, którą SQL Server stosuje podczas optymalizacji zapytania obejmującego wyrażenia tabelowe, czego wynikiem jest plan, który współdziała bezpośrednio z bazowymi tabelami. Należy zauważyć, że optymalizator może zdecydować się na użycie tabel roboczych do utrwalenia pośrednich zestawów wyników, jeśli ma to sens ze względu na wydajność lub z innych powodów, takich jak ochrona przed Halloween. Gdy to zrobi, zobaczysz w planie operatory buforowania lub buforowania indeksowego. Jednak takie wybory nie są związane z użyciem wyrażeń tabelowych w zapytaniu.
Rekursywne CTE
Istnieje kilka wyjątków, w których SQL Server utrwala dane wyrażenia tabeli. Jednym z nich jest wykorzystanie widoków indeksowanych. Jeśli utworzysz indeks klastrowany w widoku, SQL Server utrwali zestaw wyników wewnętrznego zapytania w indeksie klastrowym widoku i synchronizuje go z wszelkimi zmianami w bazowych tabelach podstawowych. Innym wyjątkiem jest użycie zapytań rekurencyjnych. SQL Server musi utrwalać pośrednie zestawy wyników kotwicy i zapytań rekurencyjnych w buforze, aby mógł uzyskać dostęp do zestawu wyników ostatniej rundy reprezentowanego przez rekurencyjne odwołanie do nazwy CTE za każdym razem, gdy wykonywany jest rekurencyjny element członkowski.
Aby to zademonstrować, użyję jednego z rekurencyjnych zapytań z części 6 serii.
Użyj następującego kodu, aby utworzyć tabelę Employees w bazie danych tempdb, wypełnić ją przykładowymi danymi i utworzyć indeks pomocniczy:
WŁĄCZ NR LICZNIKA; UŻYWAJ bazy danych; DROP TABLE IF EXISTS dbo.Employees; GO CREATE TABLE dbo.Employees ( empid INT NOT NULL CONSTRAINT PK_Employees PRIMARY KEY, mgrid INT NULL CONSTRAINT FK_Employees_Employees REFERENCES dbo.Employees, nazwa pracownika VARCHAR NULL, zarobki, MON NULL) (MON NULL) INSERT INTO dbo.Employees(empid, mgrid, empname, pensja) VALUES(1, NULL, 'David' , $1000,00), (2, 1, 'Eitan' , 700,00 $), (3, 1, 'Ina' , 7500.00 $) , (4, 2, 'Seraph' , 500,00 USD), (5, 2, 'Jiru' , 5500.00 USD), (6, 2, 'Steve' , 4500.00 USD), (7, 3, 'Aaron' , 500,00 USD), ( 8, 5, 'Lilach' , 300,00 zł), (9, 7, 'Rita' , 300,00 zł), (10, 5, 'Sean' , 300,00 zł), (11, 7, 'Gabriel', 300,00 zł), (12, 9, 'Emilia' , 200,00 USD), (13, 9, 'Michael', 200,00 USD), (14, 9, 'Didi' , 1500 USD); UTWÓRZ UNIKALNY INDEKS idx_unc_mgrid_empid NA dbo.Employees(mgrid, empid) INCLUDE(empname, pensja); IdźUżyłem następującego rekurencyjnego CTE, aby zwrócić wszystkie podwładne menedżera głównego poddrzewa wejściowego, używając pracownika 3 jako menedżera wejściowego w tym przykładzie:
DECLARE @root AS INT =3; WITH C AS ( SELECT empid, mgrid, empname FROM dbo.Employees WHERE empid =@root UNION ALL SELECT S.empid, S.mgrid, S.empname FROM C AS M INNER JOIN dbo.Employees AS S ON S.mgrid =M .empid ) SELECT empid, mgrid, empname FROM C;Plan dla tego zapytania (nazwiemy go Zapytanie 6) pokazano na rysunku 6.
Rysunek 6:Plan wykonania dla zapytania 6
Zauważ, że pierwszą rzeczą, która dzieje się w planie, na prawo od głównego węzła SELECT, jest utworzenie tabeli roboczej opartej na B-drzewie, reprezentowanej przez operator Index Spool. Górna część planu obsługuje logikę elementu zakotwiczenia. Pobiera on wejściowy wiersz pracownika z indeksu klastrowego dotyczącego pracowników i zapisuje go w buforze. Dolna część planu reprezentuje logikę rekurencyjnego elementu członkowskiego. Jest wykonywany wielokrotnie, dopóki nie zwróci pustego zestawu wyników. Zewnętrzne dane wejściowe do operatora zagnieżdżonych pętli uzyskują menedżerów z poprzedniej rundy ze szpuli (operator tabeli buforowania). Wewnętrzne dane wejściowe używają operatora Index Seek względem nieklastrowego indeksu utworzonego na Employees(mgrid, empid) w celu uzyskania bezpośrednich podwładnych menedżerów z poprzedniej rundy. Zestaw wyników każdego wykonania dolnej części planu jest również zapisywany w buforze indeksu. Zauważ, że w sumie do szpuli zostało zapisanych 7 wierszy. Jeden zwrócony przez członka zakotwiczenia i 6 kolejnych zwróconych przez wszystkie egzekucje elementu rekurencyjnego.
Na marginesie, warto zauważyć, jak plan obsługuje domyślny limit maxrecursion, który wynosi 100. Zauważ, że dolny operator Compute Scalar stale zwiększa wewnętrzny licznik o nazwie Expr1011 o 1 przy każdym wykonaniu rekurencyjnego elementu członkowskiego. Następnie operator Assert ustawia flagę na zero, jeśli ten licznik przekroczy 100. W takim przypadku SQL Server zatrzymuje wykonywanie zapytania i generuje błąd.
Kiedy nie nalegać
Wracając do nierekurencyjnych CTE, które zwykle nie są utrwalane, z perspektywy optymalizacji należy ustalić, kiedy warto ich używać w porównaniu z rzeczywistymi narzędziami utrwalania, takimi jak tabele tymczasowe i zmienne tabelowe. Omówię kilka przykładów, aby pokazać, kiedy każde podejście jest bardziej optymalne.
Zacznijmy od przykładu, w którym CTE radzą sobie lepiej niż tabele tymczasowe. Dzieje się tak często, gdy nie masz wielu ocen tego samego CTE, a raczej jest to rozwiązanie modułowe, w którym każdy CTE jest oceniany tylko raz. Poniższy kod (nazwiemy go Zapytanie 7) wysyła zapytanie do tabeli Zamówienia w bazie danych Wydajność, która ma 1 000 000 wierszy, aby zwrócić lata zamówienia, w których zamówienia złożyło ponad 70 różnych klientów:
USE PerformanceV5; WITH C1 AS ( SELECT YEAR (data zamówienia) AS rok zamówienia, custid FROM dbo.Orders ), C2 AS ( SELECT rok zamówienia, COUNT (DISTINCT custid) AS numcust FROM C1 GROUP BY rok zamówienia ) SELECT rok zamówienia, numcust FROM C2 WHERE numcust> 70;To zapytanie generuje następujące dane wyjściowe:
numcusty z roku zamówienia ----------- ----------- 2015 992 2017 20000 2018 20000 2019 20000 2016 20000Uruchomiłem ten kod przy użyciu SQL Server 2019 Developer Edition i otrzymałem plan pokazany na rysunku 7.
Rysunek 7:Plan wykonania dla zapytania 7
Zauważ, że rozgnieżdżenie CTE zaowocowało planem, który pobiera dane z indeksu w tabeli Orders i nie obejmuje żadnego buforowania wewnętrznego zestawu wyników zapytania CTE. Podczas wykonywania tego zapytania na moim komputerze otrzymałem następujące wartości wydajności:
czas trwania:265 ms, procesor:828 ms, odczyt:3970, zapis:0Teraz wypróbujmy rozwiązanie, które używa tabel tymczasowych zamiast CTE (nazwiemy to Rozwiązaniem 8), na przykład:
SELECT YEAR(data zamówienia) AS rok zamówienia, custid INTO #T1 FROM dbo.Orders; SELECT rok zamówienia, COUNT(DISTINCT custid) AS numcust INTO #T2 Z #T1 GROUP BY rok zamówienia; SELECT rokzamówienia, numcusty FROM #T2 WHERE numcusty> 70; DROP TABLE #T1, #T2;Plany tego rozwiązania pokazano na rysunku 8.
Rysunek 8:Plany rozwiązania 8
Zwróć uwagę, że operatory Table Insert zapisują zestawy wyników do tabel tymczasowych #T1 i #T2. Pierwszy jest szczególnie kosztowny, ponieważ zapisuje 1 000 000 wierszy do #T1. Oto numery wydajności, które otrzymałem za tę egzekucję:
czas trwania:454 ms, procesor:1517 ms, odczyt:14359, zapis:359Jak widać, rozwiązanie z CTE jest znacznie bardziej optymalne.
Kiedy nalegać
Czy jest więc tak, że rozwiązanie modułowe, które obejmuje tylko jedną ocenę każdego CTE, jest zawsze preferowane niż stosowanie tabel tymczasowych? Niekoniecznie. W rozwiązaniach opartych na CTE, które obejmują wiele etapów i prowadzą do skomplikowanych planów, w których optymalizator musi zastosować wiele szacunków kardynalności w wielu różnych punktach planu, możesz skończyć z nagromadzonymi niedokładnościami, które prowadzą do nieoptymalnych wyborów. Jedną z technik prób radzenia sobie z takimi przypadkami jest utrzymywanie pewnych pośrednich zestawów wyników w tabelach tymczasowych, a nawet tworzenie ich indeksów, jeśli to konieczne, dając optymalizatorowi nowy start ze świeżymi statystykami, zwiększając prawdopodobieństwo uzyskania lepszej jakości szacunków kardynalności, które miejmy nadzieję, że doprowadzi do bardziej optymalnych wyborów. To, czy jest to lepsze niż rozwiązanie, które nie korzysta z tabel tymczasowych, musisz przetestować. Czasami kompromis polegający na dodatkowym koszcie utrzymywania pośrednich zestawów wyników w celu uzyskania lepszej jakości szacunków kardynalności będzie tego wart.
Innym typowym przypadkiem, w którym preferowanym podejściem jest użycie tabel tymczasowych, jest sytuacja, w której rozwiązanie oparte na CTE ma wiele ocen tego samego CTE, a wewnętrzne zapytanie CTE jest dość drogie. Rozważ następujące rozwiązanie oparte na CTE (nazwiemy je Zapytanie 9), które do każdego roku i miesiąca zamówienia dopasowuje inny rok i miesiąc zamówienia, który ma najbliższą liczbę zamówień:
WITH OrdCount AS ( SELECT YEAR(data zamówienia) AS rokzamowienia, MONTH(datazamowienia) AS miesiączamowienia, COUNT(*) AS liczbazamówień FROM dbo.Orders GROUP BY YEAR(data zamówienia), MONTH(data zamówienia) ) SELECT O1.rokzamówienia, O1 .ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth, O2.numorders FROM OrdCount AS O2 GDZIE O2.rokzamówienia <> O1.rokzamówienia OR O2.miesiączamówienia <> O1.miesiączamówienia ZAMÓWIENIE PRZEZ ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2;To zapytanie generuje następujące dane wyjściowe:
rok zamówienia miesiąc zamówienia liczba rok zamówienia2 miesiąc zamówienia2 liczba zamówień2 ----------- ----------- ----------- -------- --- ----------- ----------- 2016 1 21262 2017 3 21267 2019 1 21227 2016 5 21229 2019 2 19145 2018 2 19125 2018 4 20561 2016 9 20554 2018 5 21209 2019 5 21210 2018 6 20515 2016 11 20513 2018 7 21194 2018 10 21197 2017 9 20542 2017 11 20539 2017 10 21234 2019 3 21235 2017 11 20539 2019 4 20537 2017 12 21183 2016 8 21185 2018 1 21241 2019 7 21238 2016 2 19844 2019 12 20184 2018 3 21222 2016 10 21222 2016 4 20526 2019 9 20527 2019 4 20537 2017 11 20539 2017 5 21203 2017 8 21199 2019 6 20531 2019 9 20527 2017 7 21217 2016 7 21218 2018 8 21283 2017 3 21267 2018 10 21197 2017 8 21199 2016 11 20513 2018 6 20515 2019 11 20494 2017 4 20498 2018 2 19125 2019 2 19145 2016 3 21211 2016 12 21212 2019 3 21235 2017 10 21234 2016 5 21229 2019 1 21227 2019 5 21210 201 6 3 21211 2017 6 20551 2016 9 20554 2017 8 21199 2018 10 21197 2018 9 20487 2019 11 20494 2016 10 21222 2018 3 21222 2018 11 20575 2016 6 20571 2016 12 21212 2016 3 21211 2019 12 20184 2018 9 20487 2017 1 21223 2016 10 21222 2017 2 19174 2019 2 19145 2017 3 21267 2016 1 21262 2017 4 20498 2019 11 20494 2016 6 20571 2018 11 20575 2016 7 21218 2017 7 21217 2019 7 21238 2018 1 21241 2016 8 21185 2017 12 21183 2019 8 21189 2016 8 21185 2016 9 20554 2017 6 20551 2019 9 20527 2016 4 20526 2019 10 21254 2016 1 21262 2015 12 1018 2018 2 19125 2018 12 21225 2017 1 21223 (49 wierszy, których dotyczy)Plan dla zapytania 9 pokazano na rysunku 9.
Rysunek 9:Plan wykonania dla zapytania 9
Górna część planu odpowiada instancji OrdCount CTE o aliasie O1. To odniesienie skutkuje jedną oceną CTE OrdCount. Ta część planu pobiera wiersze z indeksu w tabeli Zamówienia, grupuje je według roku i miesiąca oraz agreguje liczbę zamówień na grupę, uzyskując 49 wierszy. Dolna część planu odpowiada skorelowanej wyprowadzonej tabeli O2, która jest stosowana na wiersz od O1, stąd jest wykonywana 49 razy. Każde wykonanie wysyła zapytanie do OrdCount CTE, a zatem skutkuje oddzielną oceną wewnętrznego zapytania CTE. Widać, że dolna część planu skanuje wszystkie wiersze z indeksu na Zamówieniach, grupuje je i agreguje. Zasadniczo otrzymujesz w sumie 50 ocen CTE, co skutkuje 50-krotnym skanowaniem 1 000 000 wierszy z zamówień, grupowaniem i agregowaniem ich. Nie brzmi to jak bardzo wydajne rozwiązanie. Oto mierniki wydajności, które uzyskałem podczas wykonywania tego rozwiązania na moim komputerze:
czas trwania:16 sekund, procesor:56 sekund, odczyt:130404, zapis:0Biorąc pod uwagę, że zajmuje to tylko kilkadziesiąt miesięcy, znacznie bardziej wydajne byłoby użycie tymczasowej tabeli do przechowywania wyniku pojedynczej czynności, która grupuje i agreguje wiersze z Zamówienia, a następnie zawiera zarówno zewnętrzne, jak i wewnętrzne dane wejściowe operator APPLY wchodzi w interakcję z tabelą tymczasową. Oto rozwiązanie (nazwiemy je Rozwiązaniem 10) przy użyciu tabeli tymczasowej zamiast CTE:
SELECT YEAR(datazamowienia) AS rokzamowienia, MONTH(datazamowienia) AS miesiaczamowienia, COUNT(*) AS numorders INTO #OrdCount FROM dbo.Orders GROUP BY YEAR(datazamowienia), MONTH(datazamowienia); SELECT O1.orderyear, O1.ordermonth, O1.numorders, O2.orderyear AS orderyear2, O2.ordermonth AS ordermonth2, O2.numorders AS numorders2 FROM #OrdCount AS O1 CROSS APPLY ( SELECT TOP (1) O2.orderyear, O2.ordermonth , O2.numorders FROM #OrdCount AS O2 GDZIE O2.orderyear <> O1.orderyear OR O2.ordermonth <> O1.ordermonth ORDER BY ABS(O1.numorders - O2.numorders), O2.orderyear, O2.ordermonth ) AS O2; DROP TABLE #OrdCount;Tutaj indeksowanie tabeli tymczasowej nie ma większego sensu, ponieważ filtr TOP opiera się na obliczeniach w specyfikacji porządkowania, a zatem sortowanie jest nieuniknione. Jednak może się okazać, że w innych przypadkach, przy innych rozwiązaniach, warto rozważyć indeksowanie tabel tymczasowych. W każdym razie plan tego rozwiązania pokazano na rysunku 10.
Rysunek 10:Plany wykonania rozwiązania 10
Obserwuj na górnym planie, jak ciężkie podnoszenie obejmujące skanowanie 1 000 000 rzędów, grupowanie ich i agregowanie odbywa się tylko raz. Do tabeli tymczasowej #OrdCount zapisywanych jest 49 wierszy, a następnie dolny plan wchodzi w interakcję z tabelą tymczasową zarówno dla zewnętrznych, jak i wewnętrznych danych wejściowych operatora Nested Loops, który obsługuje logikę operatora APPLY.
Oto numery wydajności, które otrzymałem za wykonanie tego rozwiązania:
czas trwania:0,392 sekundy, procesor:0,5 sekundy, odczyt:3636, zapis:3Jest szybszy o rzędy wielkości niż rozwiązanie oparte na CTE.
Co dalej?
W tym artykule zacząłem omawiać zagadnienia optymalizacyjne związane z CTE. Pokazałem, że proces rozgnieżdżania/podstawiania, który ma miejsce w przypadku tabel pochodnych, działa w ten sam sposób w przypadku CTE. Omówiłem również fakt, że nierekurencyjne CTE nie są utrwalane i wyjaśniłem, że jeśli trwałość jest ważnym czynnikiem dla wydajności twojego rozwiązania, musisz sobie z tym poradzić, używając narzędzi takich jak tabele tymczasowe i zmienne tabel. W przyszłym miesiącu będę kontynuować dyskusję, omawiając dodatkowe aspekty optymalizacji CTE.



