Czy nadal trzymasz się projektu nadrzędnego/podrzędnego, czy też chciałbyś wypróbować coś nowego, na przykład hierarchyID SQL Server? Cóż, to naprawdę nowość, ponieważ hierarchyID jest częścią SQL Server od 2008 roku. Oczywiście sama nowość nie jest przekonującym argumentem. Pamiętaj jednak, że Microsoft dodał tę funkcję, aby lepiej reprezentować relacje jeden-do-wielu na wielu poziomach.
Możesz się zastanawiać, jaką to robi różnicę i jakie korzyści czerpiesz z używania hierarchyID zamiast zwykłych relacji rodzic/dziecko. Jeśli nigdy nie badałeś tej opcji, może to być dla Ciebie zaskakujące.
Prawda jest taka, że nie badałem tej opcji od czasu jej wydania. Jednak kiedy w końcu to zrobiłem, uznałem to za świetną innowację. To ładniej wyglądający kod, ale ma w sobie znacznie więcej. W tym artykule dowiemy się o tych wszystkich doskonałych możliwościach.
Zanim jednak zagłębimy się w specyfikę korzystania z SQL Server hierarchyID, wyjaśnijmy jego znaczenie i zakres.
Co to jest identyfikator hierarchii serwera SQL?
SQL Server hierarchyID to wbudowany typ danych przeznaczony do reprezentowania drzew, które są najczęstszym typem danych hierarchicznych. Każdy element w drzewie jest nazywany węzłem. W formacie tabeli jest to wiersz z kolumną typu danych hierarchyID.
Zazwyczaj hierarchie demonstrujemy za pomocą projektu tabeli. Kolumna ID reprezentuje węzeł, a inna kolumna oznacza rodzica. W przypadku SQL Server HierarchyID potrzebujemy tylko jednej kolumny z typem danych hierarchyID.
Gdy wysyłasz zapytanie do tabeli z kolumną hierarchyID, zobaczysz wartości szesnastkowe. Jest to jeden z wizualnych obrazów węzła. Innym sposobem jest ciąg:
„/” oznacza węzeł główny;
„/1/”, „/2/”, „/3/” lub „/n/” oznaczają dzieci – bezpośredni potomkowie od 1 do n;
‘/1/1/’ lub ‘/1/2/’ to „dzieci dzieci – „wnuki”. Ciąg taki jak „/1/2/” oznacza, że pierwsze dziecko z korzenia ma dwoje dzieci, które z kolei są dwójkami wnuków korzenia.
Oto próbka tego, jak to wygląda:
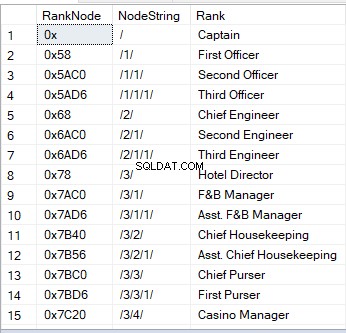
W przeciwieństwie do innych typów danych kolumny hierarchyID mogą korzystać z wbudowanych metod. Na przykład, jeśli masz kolumnę hierarchyID o nazwie RankNode , możesz mieć następującą składnię:
RankNode.
Metody identyfikatorów hierarchii serwera SQL
Jedną z dostępnych metod jest IsDescendantOf . Zwraca 1, jeśli bieżący węzeł jest potomkiem wartości hierarchyID.
Możesz napisać kod za pomocą tej metody podobnej do poniższej:
SELECT
r.RankNode
,r.Rank
FROM dbo.Ranks r
WHERE r.RankNode.IsDescendantOf(0x58) = 1Inne metody używane z hierarchyID są następujące:
- GetRoot – statyczna metoda zwracająca korzeń drzewa.
- GetDescendant – zwraca węzeł potomny rodzica.
- GetAncestor – zwraca hierarchyID reprezentujący n-tego przodka danego węzła.
- GetLevel – zwraca liczbę całkowitą, która reprezentuje głębokość węzła.
- ToString – zwraca ciąg z logiczną reprezentacją węzła. ToString jest wywoływana niejawnie, gdy następuje konwersja z hierarchyID na typ ciągu.
- GetReparentedValue – przenosi węzeł ze starego rodzica do nowego rodzica.
- Parse – działa jako przeciwieństwo ToString . Konwertuje widok ciągu hierarchyID wartość szesnastkową.
Strategie indeksowania SQL Server HierarchyID
Aby zapytania dotyczące tabel korzystające z hierarchyID działały tak szybko, jak to możliwe, należy zindeksować kolumnę. Istnieją dwie strategie indeksowania:
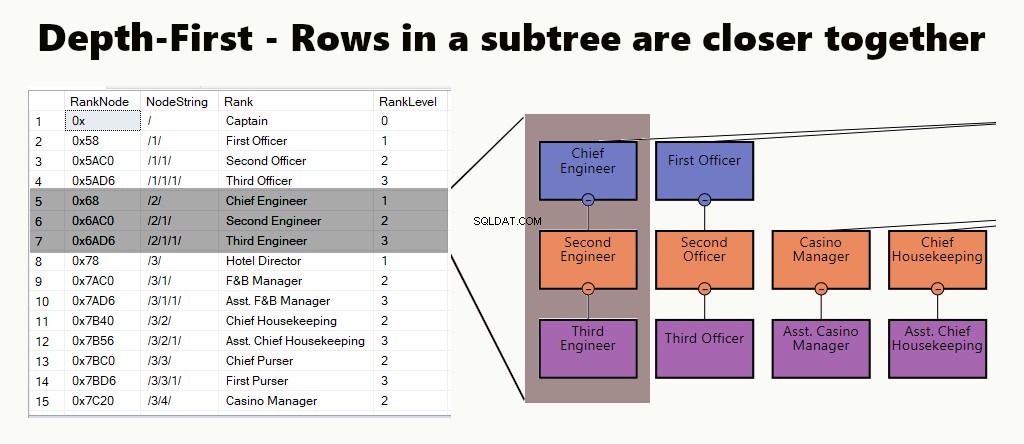
PIERWSZA GŁĘBOKOŚĆ
W indeksie na pierwszym miejscu, wiersze poddrzewa są bliżej siebie. Nadaje się do zapytań, takich jak znalezienie działu, jego podjednostek i pracowników. Innym przykładem jest menedżer i jego pracownicy trzymani bliżej siebie.
W tabeli można zaimplementować indeks wgłębny, tworząc indeks klastrowy dla węzłów. Następnie wykonujemy jeden z naszych przykładów, tak po prostu.
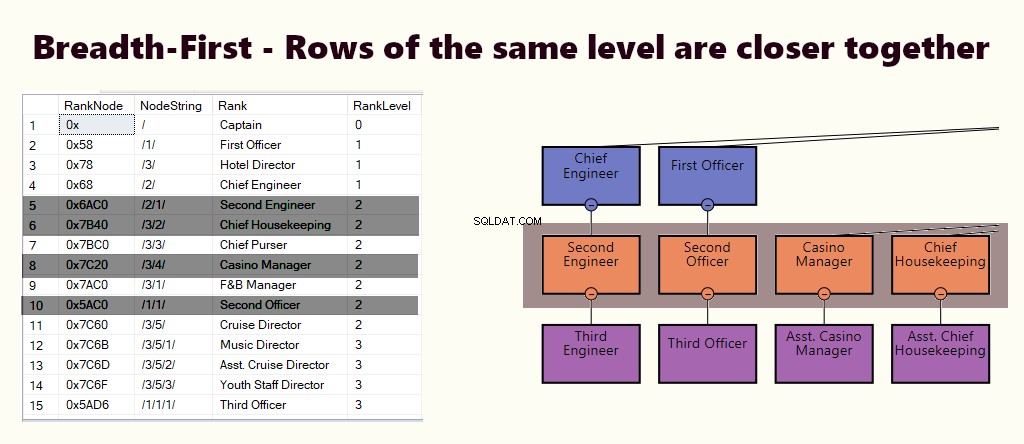
PIERWSZA OD ŚRUBY
W indeksie wszerz, wiersze tego samego poziomu są bliżej siebie. Nadaje się do zapytań, takich jak znalezienie wszystkich bezpośrednio podlegających menedżerowi pracowników. Jeśli większość zapytań jest podobna do tego, utwórz indeks klastrowy na podstawie (1) poziomu i (2) węzła.
To zależy od Twoich wymagań, czy potrzebujesz indeksu w głąb, wszerz, czy obu. Musisz zrównoważyć znaczenie typu zapytania i instrukcji DML, które wykonujesz na tabeli.
Ograniczenia hierarchii ID serwera SQL
Niestety, użycie hierarchyID nie może rozwiązać wszystkich problemów:
- SQL Server nie może odgadnąć, jakie jest dziecko rodzica. Musisz zdefiniować drzewo w tabeli.
- Jeśli nie używasz ograniczenia przez unikalność, wygenerowana wartość hierarchyID nie będzie unikalna. Za rozwiązanie tego problemu odpowiada deweloper.
- Relacje węzła nadrzędnego i podrzędnego nie są wymuszane jak relacja klucza obcego. Dlatego przed usunięciem węzła zapytaj o wszelkich istniejących potomków.
Wizualizacja hierarchii
Zanim przejdziemy dalej, rozważ jeszcze jedno pytanie. Patrząc na zestaw wyników z ciągami węzłów, czy uważasz, że wizualizacja hierarchii jest trudna dla twoich oczu?
Dla mnie to wielkie tak, bo nie jestem młodszy.
Z tego powodu wraz z naszymi tabelami bazy danych będziemy używać Power BI i wykresu hierarchii firmy Akvelon. Pomogą wyświetlić hierarchię na schemacie organizacyjnym. Mam nadzieję, że ułatwi to pracę.
Teraz przejdźmy do rzeczy.
Zastosowania SQL Server HierarchyID
Możesz użyć HierarchyID w następujących scenariuszach biznesowych:
- Struktura organizacyjna
- Foldery, podfoldery i pliki
- Zadania i podzadania w projekcie
- Strony i podstrony witryny internetowej
- Dane geograficzne z krajami, regionami i miastami
Nawet jeśli Twój scenariusz biznesowy jest podobny do powyższego i rzadko wykonujesz zapytania w sekcjach hierarchii, nie potrzebujesz hierarchyID.
Na przykład Twoja organizacja przetwarza listy płac pracowników. Czy potrzebujesz dostępu do poddrzewa, aby przetworzyć czyjąś listę płac? Zupełnie nie. Jeśli jednak przetwarzasz prowizje osób w systemie marketingu wielopoziomowego, może być inaczej.
W tym poście wykorzystujemy część struktury organizacyjnej i łańcucha dowodzenia na statku wycieczkowym. Struktura została zaadaptowana ze schematu organizacyjnego stąd. Spójrz na to na rysunku 4 poniżej:

Teraz możesz zwizualizować omawianą hierarchię. W tym poście używamy poniższych tabel:
- Statki – to stół z listą statków wycieczkowych.
- Rankingi – to tabela rang załogi. Tam ustanawiamy hierarchie za pomocą hierarchyID.
- Załoga – jest lista załóg każdego statku i ich stopni.
Struktura tabeli każdego przypadku jest następująca:
CREATE TABLE [dbo].[Vessel](
[VesselId] [int] IDENTITY(1,1) NOT NULL,
[VesselName] [varchar](20) NOT NULL,
CONSTRAINT [PK_Vessel] PRIMARY KEY CLUSTERED
(
[VesselId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Ranks](
[RankId] [int] IDENTITY(1,1) NOT NULL,
[Rank] [varchar](50) NOT NULL,
[RankNode] [hierarchyid] NOT NULL,
[RankLevel] [smallint] NOT NULL,
[ParentRankId] [int] -- this is redundant but we will use this to compare
-- with parent/child
) ON [PRIMARY]
GO
CREATE UNIQUE NONCLUSTERED INDEX [IX_RankId] ON [dbo].[Ranks]
(
[RankId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE UNIQUE CLUSTERED INDEX [IX_RankNode] ON [dbo].[Ranks]
(
[RankNode] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
GO
CREATE TABLE [dbo].[Crew](
[CrewId] [int] IDENTITY(1,1) NOT NULL,
[CrewName] [varchar](50) NOT NULL,
[DateHired] [date] NOT NULL,
[RankId] [int] NOT NULL,
[VesselId] [int] NOT NULL,
CONSTRAINT [PK_Crew] PRIMARY KEY CLUSTERED
(
[CrewId] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Ranks] FOREIGN KEY([RankId])
REFERENCES [dbo].[Ranks] ([RankId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Ranks]
GO
ALTER TABLE [dbo].[Crew] WITH CHECK ADD CONSTRAINT [FK_Crew_Vessel] FOREIGN KEY([VesselId])
REFERENCES [dbo].[Vessel] ([VesselId])
GO
ALTER TABLE [dbo].[Crew] CHECK CONSTRAINT [FK_Crew_Vessel]
GOWstawianie danych tabeli z SQL Server HierarchyID
Pierwszym zadaniem przy dokładnym użyciu hierarchyID jest dodanie rekordów do tabeli z hieraryID kolumna. Można to zrobić na dwa sposoby.
Korzystanie z ciągów
Najszybszym sposobem wstawienia danych z hierarchyID jest użycie ciągów. Aby zobaczyć to w akcji, dodajmy kilka rekordów do Rankingów tabela.
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Captain', '/',0)
,('First Officer','/1/',1)
,('Chief Engineer','/2/',1)
,('Hotel Director','/3/',1)
,('Second Officer','/1/1/',2)
,('Second Engineer','/2/1/',2)
,('F&B Manager','/3/1/',2)
,('Chief Housekeeping','/3/2/',2)
,('Chief Purser','/3/3/',2)
,('Casino Manager','/3/4/',2)
,('Cruise Director','/3/5/',2)
,('Third Officer','/1/1/1/',3)
,('Third Engineer','/2/1/1/',3)
,('Asst. F&B Manager','/3/1/1/',3)
,('Asst. Chief Housekeeping','/3/2/1/',3)
,('First Purser','/3/3/1/',3)
,('Asst. Casino Manager','/3/4/1/',3)
,('Music Director','/3/5/1/',3)
,('Asst. Cruise Director','/3/5/2/',3)
,('Youth Staff Director','/3/5/3/',3)Powyższy kod dodaje 20 rekordów do tabeli Rangi.
Jak widać, struktura drzewa została zdefiniowana w INSERT oświadczenie powyżej. Jest to łatwo dostrzegalne, gdy używamy sznurków. Poza tym SQL Server konwertuje je na odpowiednie wartości szesnastkowe.
Korzystanie z funkcji Max(), GetAncestor() i GetDescendant()
Użycie ciągów odpowiada zadaniu wypełniania początkowych danych. Na dłuższą metę potrzebny jest kod do obsługi wstawiania bez dostarczania ciągów.
Aby wykonać to zadanie, pobierz ostatni węzeł używany przez rodzica lub przodka. Realizujemy to za pomocą funkcji MAX() i GetAncestor() . Zobacz przykładowy kod poniżej:
-- add a bartender rank reporting to the Asst. F&B Manager
DECLARE @MaxNode HIERARCHYID
DECLARE @ImmediateSuperior HIERARCHYID = 0x7AD6
SELECT @MaxNode = MAX(RankNode) FROM dbo.Ranks r
WHERE r.RankNode.GetAncestor(1) = @ImmediateSuperior
INSERT INTO dbo.Ranks
([Rank], RankNode, RankLevel)
VALUES
('Bartender', @ImmediateSuperior.GetDescendant(@MaxNode,NULL),
@ImmediateSuperior.GetDescendant(@MaxNode, NULL).GetLevel())Poniżej znajdują się punkty zaczerpnięte z powyższego kodu:
- Po pierwsze, potrzebujesz zmiennej dla ostatniego węzła i bezpośredniego przełożonego.
- Ostatni węzeł można uzyskać za pomocą MAX() przeciwko RankNode dla określonego rodzica lub bezpośredniego przełożonego. W naszym przypadku jest to Assistant F&B Manager z wartością węzła 0x7AD6.
- Następnie, aby upewnić się, że nie pojawi się duplikat dziecka, użyj @ImmediateSuperior.GetDescendant(@MaxNode, NULL) . Wartość w @MaxNode jest ostatnim dzieckiem. Jeśli nie jest NULL , GetDescendant() zwraca następną możliwą wartość węzła.
- Ostatni, GetLevel() zwraca poziom nowo utworzonego węzła.
Odpytywanie danych
Po dodaniu rekordów do naszej tabeli, czas na zapytanie. Dostępne są 2 sposoby wyszukiwania danych:
Zapytanie o bezpośrednich potomków
Kiedy szukamy pracowników bezpośrednio podlegających kierownikowi, musimy wiedzieć dwie rzeczy:
- Wartość węzła menedżera lub rodzica
- Poziom pracownika pod kierownictwem
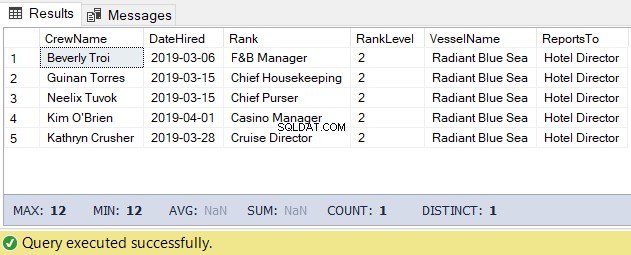
Do tego zadania możemy wykorzystać poniższy kod. Wynikiem jest lista załogi pod kierownictwem hotelu.
-- Get the list of crew directly reporting to the Hotel Director
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
DECLARE @Level SMALLINT = @Node.GetLevel()
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1
AND b.RankLevel = @Level + 1 -- add 1 for the level of the crew under the
-- Hotel DirectorWynik powyższego kodu jest następujący na rysunku 5:
Zapytanie o poddrzewa
Czasami trzeba też spisać dzieci i dzieci dzieci od dołu. Aby to zrobić, musisz mieć hierarchyID rodzica.
Zapytanie będzie podobne do poprzedniego kodu, ale bez konieczności zdobywania poziomu. Zobacz przykład kodu:
-- Get the list of the crew under the Hotel Director down to the lowest level
DECLARE @Node HIERARCHYID = 0x78 -- the Hotel Director's node/hierarchyid
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,(SELECT Rank FROM dbo.Ranks WHERE RankNode = b.RankNode.GetAncestor(1)) AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
WHERE b.RankNode.IsDescendantOf(@Node)=1Wynik powyższego kodu:
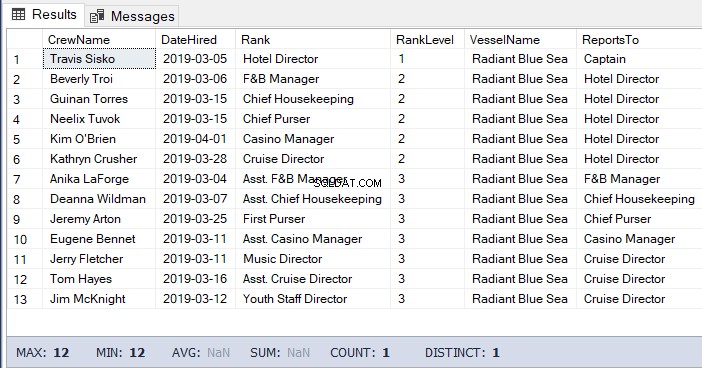
Przenoszenie węzłów za pomocą SQL Server HierarchyID
Inną standardową operacją na danych hierarchicznych jest przeniesienie potomka lub całego poddrzewa do innego rodzica. Zanim jednak przejdziemy dalej, zwróć uwagę na jeden potencjalny problem:
Potencjalny problem
- Po pierwsze, ruchome węzły wymagają operacji we/wy. To, jak często przenosisz węzły, może być decydującym czynnikiem, jeśli używasz hierarchyID lub zwykłego rodzica/dziecka.
- Po drugie, przeniesienie węzła w projekcie nadrzędnym/podrzędnym aktualizuje jeden wiersz. W tym samym czasie, gdy przenosisz węzeł z hierarchyID, aktualizuje jeden lub więcej wierszy. Liczba wierszy, których to dotyczy, zależy od głębokości poziomu hierarchii. Może to przerodzić się w poważny problem z wydajnością.
Rozwiązanie
Możesz poradzić sobie z tym problemem za pomocą projektu bazy danych.
Rozważmy projekt, którego tutaj użyliśmy.
Zamiast określać hierarchię załogi tabeli, zdefiniowaliśmy ją w Rankingach stół. To podejście różni się od Pracownika tabela w AdventureWorks przykładowa baza danych i oferuje następujące korzyści:
- Członkowie załogi poruszają się częściej niż szeregi na statku. Ten projekt ograniczy ruchy węzłów w hierarchii. W rezultacie minimalizuje problem zdefiniowany powyżej.
- Definiowanie więcej niż jednej hierarchii w Załodze tabela jest bardziej skomplikowana, ponieważ dwa statki potrzebują dwóch kapitanów. Rezultatem są dwa węzły główne.
- Jeśli chcesz wyświetlić wszystkie stopnie z odpowiednim członkiem załogi, możesz użyć LEWY DOŁĄCZ. Jeśli nikt nie jest na pokładzie dla tej rangi, pokazuje puste miejsce na pozycję.
Przejdźmy teraz do celu tej sekcji. Dodaj węzły podrzędne pod niewłaściwymi rodzicami.
Aby zobrazować to, co zamierzamy zrobić, wyobraź sobie hierarchię podobną do poniższej. Zwróć uwagę na żółte węzły.

Przenieś węzeł bez dzieci
Przenoszenie węzła podrzędnego wymaga:
- Zdefiniuj hierarchyID węzła podrzędnego do przeniesienia.
- Zdefiniuj identyfikator hierarchii starego rodzica.
- Zdefiniuj identyfikator hierarchii nowego rodzica.
- Użyj AKTUALIZACJI z GetReparentedValue() aby fizycznie przenieść węzeł.
Zacznij od przeniesienia węzła bez dzieci. W poniższym przykładzie przenosimy personel rejsu spod dyrektora rejsu do doc. Dyrektor rejsu.
-- Moving a node with no child node
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 24 -- the cruise staff
SELECT @OldParent = @NodeToMove.GetAncestor(1)
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 19 -- the assistant cruise director
UPDATE dbo.Ranks
SET RankNode = @NodeToMove.GetReparentedValue(@OldParent,@NewParent)
WHERE RankNode = @NodeToMovePo zaktualizowaniu węzła dla węzła zostanie użyta nowa wartość szesnastkowa. Odświeżenie mojego połączenia Power BI z SQL Server – zmieni to wykres hierarchii, jak pokazano poniżej:
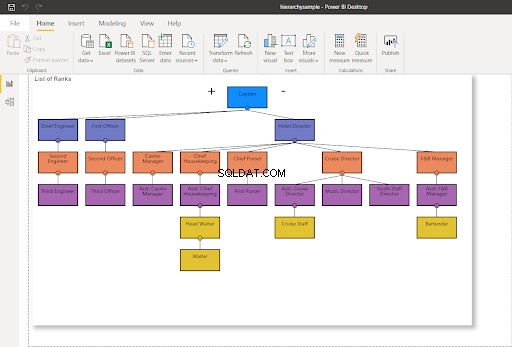
Na rysunku 8 personel rejsu nie podlega już dyrektorowi rejsu – zmieniono go na raportowanie do asystenta dyrektora rejsu. Porównaj to z rysunkiem 7 powyżej.
Przejdźmy teraz do następnego etapu i przenieś głównego kelnera do Asystenta F&B Managera.
Przenieś węzeł z dziećmi
W tej części jest wyzwanie.
Chodzi o to, że poprzedni kod nie będzie działał z węzłem z nawet jednym dzieckiem. Pamiętamy, że przeniesienie węzła wymaga aktualizacji jednego lub więcej węzłów podrzędnych.
Co więcej, na tym się nie kończy. Jeśli nowy rodzic ma już dziecko, możemy wpaść na zduplikowane wartości węzłów.
W tym przykładzie musimy zmierzyć się z tym problemem:doc. F&B Manager ma węzeł podrzędny Bartender.
Gotowy? Oto kod:
-- Move a node with at least one child
DECLARE @NodeToMove HIERARCHYID
DECLARE @OldParent HIERARCHYID
DECLARE @NewParent HIERARCHYID
SELECT @NodeToMove = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 22 -- the head waiter
SELECT @OldParent = @NodeToMove.GetAncestor(1) -- head waiter's old parent
--> asst chief housekeeping
SELECT @NewParent = r.RankNode
FROM dbo.Ranks r
WHERE r.RankId = 14 -- the assistant f&b manager
DECLARE children_cursor CURSOR FOR
SELECT RankNode FROM dbo.Ranks r
WHERE RankNode.GetAncestor(1) = @OldParent;
DECLARE @ChildId hierarchyid;
OPEN children_cursor
FETCH NEXT FROM children_cursor INTO @ChildId;
WHILE @@FETCH_STATUS = 0
BEGIN
START:
DECLARE @NewId hierarchyid;
SELECT @NewId = @NewParent.GetDescendant(MAX(RankNode), NULL)
FROM dbo.Ranks r WHERE RankNode.GetAncestor(1) = @NewParent; -- ensure
--to get a new id in case there's a
--sibling
UPDATE dbo.Ranks
SET RankNode = RankNode.GetReparentedValue(@ChildId, @NewId)
WHERE RankNode.IsDescendantOf(@ChildId) = 1;
IF @@error <> 0 GOTO START -- On error, retry
FETCH NEXT FROM children_cursor INTO @ChildId;
END
CLOSE children_cursor;
DEALLOCATE children_cursor;W powyższym przykładzie kodu iteracja rozpoczyna się od konieczności przeniesienia węzła do dziecka na ostatnim poziomie.
Po uruchomieniu Rankingi tabela zostanie zaktualizowana. I znowu, jeśli chcesz zobaczyć zmiany wizualnie, odśwież raport usługi Power BI. Zobaczysz zmiany podobne do tych poniżej:
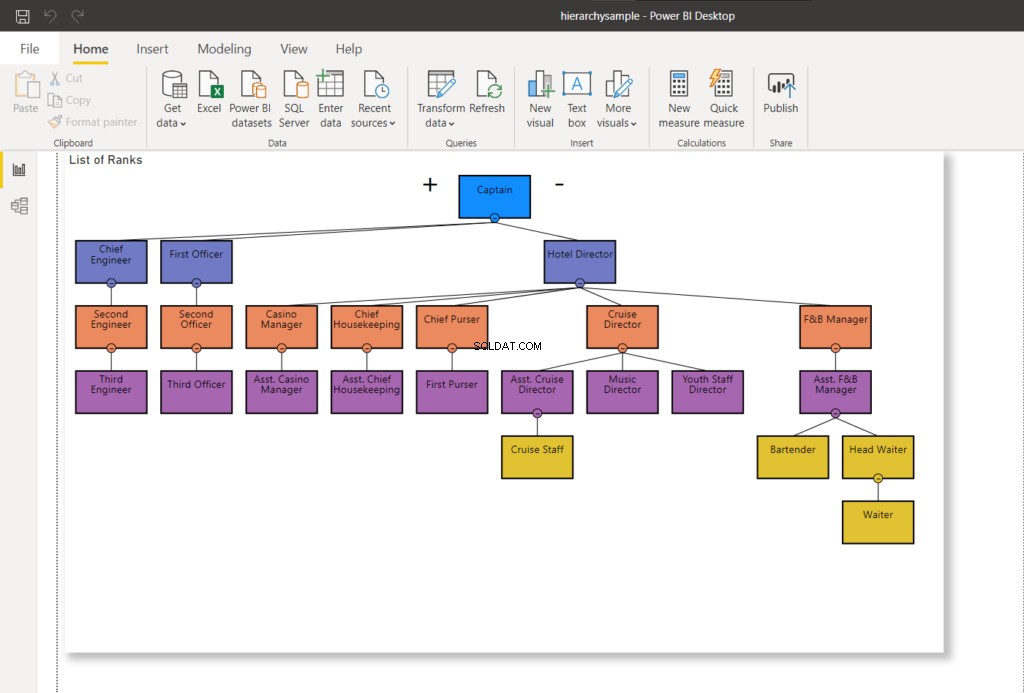
Zalety używania SQL Server HierarchyID w porównaniu z nadrzędnym/podrzędnym
Aby przekonać kogokolwiek do korzystania z funkcji, musimy poznać korzyści.
Dlatego w tej sekcji będziemy porównywać wyrażenia przy użyciu tych samych tabel, co te od początku. Jeden użyje hierarchyID, a drugi użyje podejścia rodzic/dziecko. Zestaw wyników będzie taki sam dla obu podejść. Spodziewamy się tego w tym ćwiczeniu, tak jak to z Rysunek 6 powyżej.
Teraz, gdy wymagania są precyzyjne, przyjrzyjmy się dokładnie korzyściom.
Prostszy kod
Zobacz kod poniżej:
-- List down all the crew under the Hotel Director using hierarchyID
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.RANK AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON d.RankNode = b.RankNode.GetAncestor(1)
WHERE a.VesselId = 1
AND b.RankNode.IsDescendantOf(0x78)=1Ten przykład wymaga tylko wartości hierarchyID. Możesz dowolnie zmieniać wartość bez zmiany zapytania.
Teraz porównaj stwierdzenie dla podejścia rodzic/dziecko dające ten sam zestaw wyników:
-- List down all the crew under the Hotel Director using parent/child
SELECT
a.CrewName
,a.DateHired
,b.Rank
,b.RankLevel
,c.VesselName
,d.Rank AS ReportsTo
FROM dbo.Crew a
INNER JOIN dbo.Vessel c ON a.VesselId = c.VesselId
INNER JOIN dbo.Ranks b ON a.RankId = b.RankId
INNER JOIN dbo.Ranks d ON b.RankParentId = d.RankId
WHERE a.VesselId = 1
AND (b.RankID = 4) OR (b.RankParentID = 4 OR b.RankParentId >= 7)Co myślisz? Przykłady kodu są prawie takie same, z wyjątkiem jednego punktu.
GDZIE klauzula w drugim zapytaniu nie będzie elastyczna do dostosowania, jeśli wymagane jest inne poddrzewo.
Spraw, aby drugie zapytanie było wystarczająco ogólne, a kod będzie dłuższy. Ups!
Szybsze wykonywanie
Według Microsoftu „zapytania poddrzewa są znacznie szybsze dzięki hierarchyID” w porównaniu z danymi nadrzędnymi/podrzędnymi. Zobaczmy, czy to prawda.
Używamy tych samych zapytań co wcześniej. Jedną z istotnych metryk do wykorzystania w celu zwiększenia wydajności są odczyty logiczne z Zestaw we/wy STATYSTYK . Mówi ona, ile stron o wielkości 8 KB będzie potrzebnych SQL Server, aby uzyskać żądany zestaw wyników. Im wyższa wartość, tym większa liczba stron, do których SQL Server uzyskuje dostęp i które odczytuje, oraz wolniejsze działanie zapytania. Wykonaj WŁĄCZ IO STATISTICS i ponownie wykonaj dwa powyższe zapytania. Niższa wartość odczytów logicznych będzie zwycięzcą.
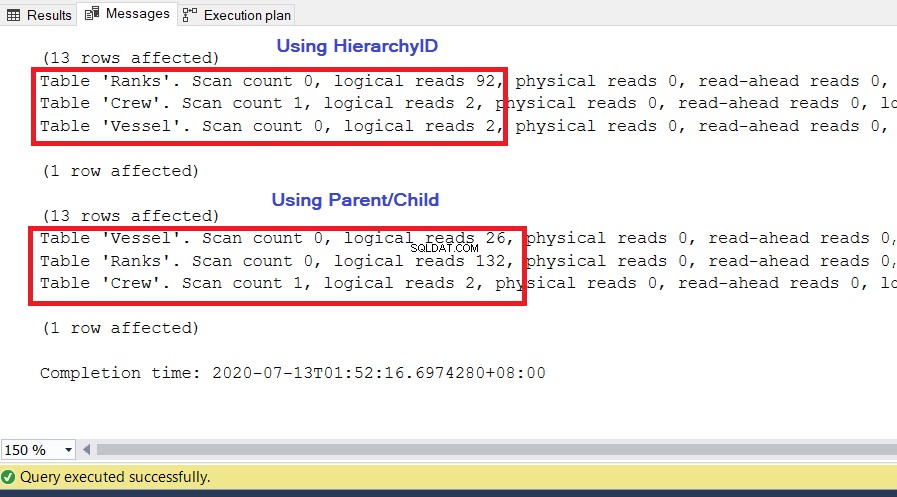
ANALIZA
Jak widać na rysunku 10, statystyki we/wy dla zapytania z hierarchyID mają niższe odczyty logiczne niż ich odpowiedniki nadrzędne/podrzędne. Zwróć uwagę na następujące punkty w tym wyniku:
- Statek tabela jest najbardziej godną uwagi z trzech tabel. Użycie hierarchyID wymaga tylko 2 * 8KB =16KB stron do odczytania przez SQL Server z pamięci podręcznej (pamięci). Tymczasem użycie rodzica/dziecka wymaga 26 * 8 KB =208 KB stron – znacznie więcej niż przy użyciu hierarchyID.
- Rankingi tabela, która zawiera naszą definicję hierarchii, wymaga 92 * 8KB =736KB. Z drugiej strony użycie rodzica/dziecka wymaga 132 * 8KB =1056KB.
- Załoga tabela potrzebuje 2 * 8KB =16KB, co jest takie samo dla obu podejść.
Kilobajty stron mogą być na razie niewielką wartością, ale mamy tylko kilka rekordów. Daje nam jednak wyobrażenie o tym, jak obciążające będzie nasze zapytanie na dowolnym serwerze. Aby poprawić wydajność, możesz wykonać jedną lub więcej z następujących czynności:
- Dodaj odpowiednie indeksy
- Zmień strukturę zapytania
- Aktualizuj statystyki
Jeśli zrobisz powyższe, a odczyty logiczne zmniejszą się bez dodawania kolejnych rekordów, wydajność wzrośnie. Dopóki sprawisz, że odczyty logiczne będą niższe niż w przypadku korzystania z hierarchyID, będzie to dobra wiadomość.
Ale po co odwoływać się do odczytów logicznych zamiast czasu, który upłynął?
Sprawdzanie czasu, jaki upłynął dla obu zapytań za pomocą SET STATISTICS TIME ON ujawnia niewielką liczbę milisekund różnic dla naszego małego zestawu danych. Ponadto serwer deweloperski może mieć inną konfigurację sprzętową, ustawienia programu SQL Server i inne obciążenie. Czas, który upłynął mniej niż milisekunda, może Cię oszukać, jeśli Twoje zapytanie działa tak szybko, jak się spodziewasz, czy nie.
DALSZE KOPANIE
WŁĄCZ IO STATYSTYK nie ujawnia, co dzieje się „za kulisami”. W tej sekcji dowiemy się, dlaczego SQL Server jest dostarczany z tymi liczbami, patrząc na plan wykonania.
Zacznijmy od planu wykonania pierwszego zapytania.
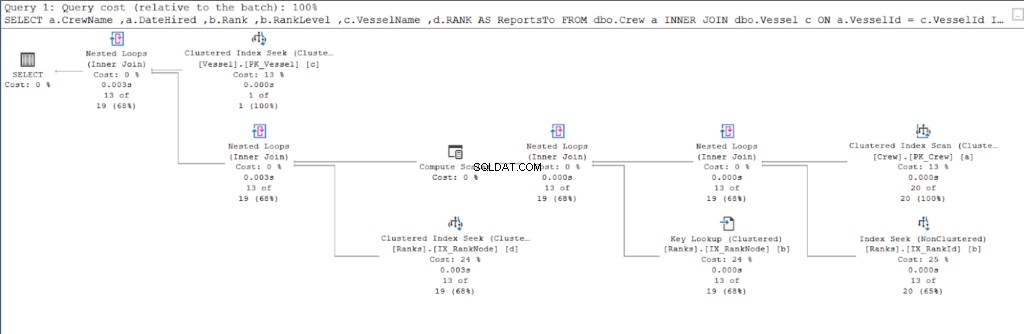
Teraz spójrz na plan wykonania drugiego zapytania.
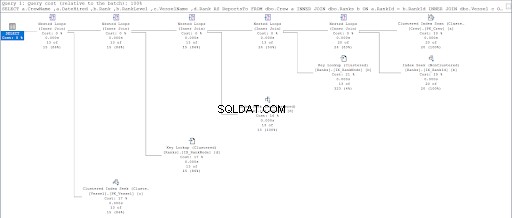
Porównując rysunki 11 i 12, widzimy, że SQL Server wymaga dodatkowego wysiłku, aby wygenerować zestaw wyników, jeśli używasz podejścia nadrzędny/podrzędny. GDZIE Klauzula jest odpowiedzialna za tę komplikację.
Jednak wadą może być również konstrukcja stołu. Do obu podejść użyliśmy tej samej tabeli:Rankingi stół. Dlatego próbowałem powielić Rankingi tabeli, ale używaj różnych indeksów klastrowych odpowiednich dla każdej procedury.
W rezultacie użycie hierarchyID nadal miało mniej odczytów logicznych w porównaniu z odpowiednikiem nadrzędnym/podrzędnym. Wreszcie udowodniliśmy, że Microsoft miał rację, twierdząc to.
Wniosek
Oto centralny moment dla hierarchyID:
- HierarchyID to wbudowany typ danych zaprojektowany z myślą o bardziej zoptymalizowanej reprezentacji drzew, które są najczęstszym typem danych hierarchicznych.
- Każdy element w drzewie jest węzłem, a wartości hierarchyID mogą być w formacie szesnastkowym lub łańcuchowym.
- HierarchyID ma zastosowanie do danych struktur organizacyjnych, zadań projektowych, danych geograficznych i tym podobnych.
- Istnieją metody przechodzenia i manipulowania danymi hierarchicznymi, takie jak GetAncestor (), GetDescendant (). GetLevel (), GetReparentedValue () i nie tylko.
- Tradycyjnym sposobem zapytania o dane hierarchiczne jest uzyskanie bezpośrednich potomków węzła lub uzyskanie poddrzew pod węzłem.
- Użycie hierarchyID do odpytywania poddrzew jest nie tylko prostsze w kodzie. Działa również lepiej niż rodzic/dziecko.
Projekt rodzic/dziecko wcale nie jest zły, a ten post nie ma go umniejszać. Jednak rozszerzenie opcji i wprowadzanie nowych pomysłów jest zawsze wielką korzyścią dla programisty.
Możesz sam wypróbować przykłady, które tu podaliśmy. Otrzymuj efekty i zobacz, jak możesz je zastosować w swoim następnym projekcie obejmującym hierarchie.
Jeśli podoba Ci się post i jego pomysły, możesz rozpowszechniać informacje, klikając przyciski udostępniania dla preferowanych mediów społecznościowych.



