To jest druga część materiału poświęconego wyszukiwaniu semantycznemu SQL Server . W poprzednim artykule omówiliśmy podstawy. Teraz skupimy się na porównaniu dokumentów przechowywanych w systemie plików Windows i analizie porównawczej z wyszukiwaniem semantycznym w SQL Server.
Wykonywanie analizy porównawczej dokumentów opartych na nazwach
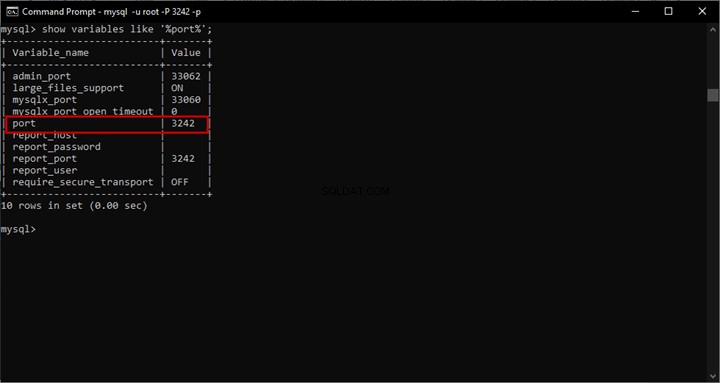
Przeprowadzimy analizę porównawczą dokumentów w oparciu o ich standardowe nazewnictwo. W tym momencie zróbmy szybkie sprawdzenie, wysyłając zapytanie do Próbki pliku strumienia pracowników baza danych, którą założyliśmy wcześniej:
-- Wyświetl przechowywane dokumenty zarządzane przez tabelę plików, aby sprawdzić SELECT stream_id ,[name] ,file_type ,creation_timeFROM EmployeesFilestreamSample.dbo.EmployeesDocumentStore Wyniki muszą pokazać nam przechowywane dokumenty:
Lista kontrolna wyszukiwania semantycznego
Mamy już bazę danych i dwa przykładowe dokumenty MS Word w systemie plików przy użyciu tabeli plików (możesz odwołać się do części 1, aby odświeżyć wiedzę, jeśli zajdzie taka potrzeba). Jednak to nie automatycznie kwalifikuje nasze dokumenty do scenariusza wyszukiwania semantycznego.
Wyszukiwanie semantyczne można włączyć na jeden z następujących sposobów:
- Jeśli masz już skonfigurowane Wyszukiwanie pełnotekstowe , możesz włączyć wyszukiwanie semantyczne w jednym kroku.
- Możesz ustawić wyszukiwanie semantyczne bezpośrednio, ale zanim będziesz musiał również skonfigurować wyszukiwanie pełnotekstowe.
Test wyszukiwania pełnotekstowego przed konfiguracją wyszukiwania semantycznego
Jeśli zapytanie pełnotekstowe działa, wystarczy włączyć wyszukiwanie semantyczne. Aby to sprawdzić, uruchom zapytanie pełnotekstowe w żądanej tabeli:
-- Wyszukiwanie słowa Pracownik przy użyciu wyszukiwania pełnotekstowego w tabeli plików EmployeesDocumentStoreSELECT [nazwa] FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(nazwa,'Pracownik') Wynik:
Dlatego musimy najpierw spełnić wymagania wyszukiwania pełnotekstowego, a następnie włączyć wyszukiwanie semantyczne.
Włączanie semantycznego wyszukiwania do użytku
Do korzystania z wyszukiwania semantycznego wymagane są co najmniej dwa z następujących punktów:
- Unikalny indeks
- Katalog pełnotekstowy
- Indeks pełnotekstowy
Wykonaj następujący skrypt T-SQL, aby utworzyć unikalny indeks:
-- Utwórz unikalny indeks wymagany dla wyszukiwania semantycznego UTWÓRZ UNIKALNY INDEKS UQ_Stream_Id ON EmployeesDocumentStore(stream_id) GO Utwórz katalog pełnotekstowy na podstawie nowo utworzonego unikalnego indeksu. Następnie utwórz indeks pełnotekstowy, jak pokazano poniżej:
-- Przygotowanie wyszukiwania semantycznego do użycia z tabelą plikówCREATE FULLTEXT CATALOG EmployeesFileTableCatalog WITH ACCENT_SENSITIVITY =ON;CREATE FULLTEXT INDEX ON EmployeesDocumentStore(nazwa LANGUAGE 1033 STATYSTYCZNE_SEMANTYCZNE_SEMANTYCZNE_33_typ pliku KLUCZOWY INDEKS UQ_Stream_IdON EmployeesFileTableCatalog Z CHANGE_TRACKING AUTO, STOPLIST=SYSTEM; Wyniki:
Test wyszukiwania pełnotekstowego po skonfigurowaniu wyszukiwania semantycznego
Uruchommy to samo zapytanie pełnotekstowe, aby wyszukać słowo Pracownik w przechowywanych dokumentach:
-- Wyszukiwanie (po skonfigurowaniu wyszukiwania semantycznego) słowo Pracownik przy użyciu wyszukiwania pełnotekstowego w tabeli plików EmployeesDocumentStoreSELECT [nazwa] FROM [EmployeesFilestreamSample].[dbo].[EmployeesDocumentStore] WHERE CONTAINS(nazwa,'Pracownik') Wynik:
Zapytania pełnotekstowe mogą działać z tabelą plików, gdy przygotowujemy ją do wyszukiwania semantycznego.
Dodaj więcej dokumentów MS Word
Idziemy do StoreDokumentów Pracowników File Table i kliknij Przeglądaj katalog FileTable :
Utwórz i zapisz nowy dokument o nazwie Pracownik kontraktowy Sadaf :
Następnie dodaj następujący tekst do nowo utworzonego dokumentu. Pierwsza linia musi być tytułem dokumentu!
Pracownik kontraktowy Sadaf (tytuł)
Sadaf jest bardzo wydajnym analitykiem biznesowym, który wykonuje pracę opartą na kontaktach. Jest w pełni zdolna do obsługi wymagań biznesowych i przekształcania ich w specyfikacje techniczne, nad którymi pracują deweloperzy. Jest bardzo doświadczonym analitykiem biznesowym.
Dodaj kolejny dokument o nazwie Mike Stały pracownik :
Zaktualizuj dokument następującym tekstem:
Mike Stały pracownik (tytuł dokumentu)
Mike jest świeżo upieczonym programistą, którego doświadczenie obejmuje tworzenie stron internetowych. Szybko się uczy i chętnie pracuje nad każdym projektem. Ma silne umiejętności rozwiązywania problemów, ale ma mniejszą wiedzę biznesową. Potrzebuje pomocy innych programistów lub analityków biznesowych, aby zrozumieć problem i spełnić wymagania.
Jest dobry, gdy pracuje nad małymi projektami, ale ma problemy z dużym lub złożonym projektem.
Mamy cztery dokumenty przechowywane w systemie plików Windows zarządzanym przez tabelę plików. Dokumenty te powinny być wykorzystywane przez wyszukiwanie semantyczne (w tym wyszukiwanie pełnotekstowe).
Ważne:Chociaż właśnie zapisaliśmy cztery dokumenty MS Word w folderze jako przykład, możesz sobie wyobrazić, jak ważne jest korzystanie z wyszukiwania semantycznego, gdy setki takich dokumentów są utrzymywane przez bazę danych SQL Server i musisz przeszukiwać te dokumenty aby znaleźć cenne informacje.
Standardowe nazewnictwo dokumentów ma duże znaczenie dla pomyślnej implementacji tego podejścia.
Proste liczenie dokumentów
Możemy porównać te dokumenty i zdefiniować różnice i podobieństwa w oparciu o ich standardowe nazewnictwo przy użyciu Semantic Search. Na przykład proste zapytanie może nam podać całkowitą liczbę dokumentów przechowywanych w folderze Windows:
-- Pobieranie całkowitej liczby przechowywanych dokumentówSELECT COUNT(*) AS Total_Documents FROM EmployeesDocumentStore 
Porównanie pracowników stałych i kontraktowych
Tym razem używamy Semantic Search do porównania liczby pracowników stałych i kontraktowych w naszej organizacji:
-- Tworzenie tabeli podsumowań zmiennaDECLARE @Documents TABLE(DocumentType VARCHAR(100),DocumentsCount INT)INSERT INTO @Documents — Przechowywanie całkowitej liczby przechowywanych dokumentów w tabeli podsumowańSELECT 'Total Documents',COUNT(*) AS Total_Documents FROM EmployeesDocumentStoreINSERT INTO @Documents -- Przechowywanie całkowitej liczby dokumentów stałych pracowników przechowywanych w tabeli podsumowującejSELECT 'Total Permanent Employees',COUNT(*) FROM semantickeyphraseable (EmployeesDocumentStore, *)WHERE keyphrase ='ERT --STORING @Documents' . całkowita liczba przechowywanych dokumentów stałych pracowników SELECT 'Całkowita liczba pracowników kontraktowych',COUNT(*) FROM semantickeyphrasetable (EmployeesDocumentStore, *)WHERE keyphrase ='Contract'SELECT DocumentType,DocumentsCount FROM @Documents Wynik:
Uruchommy proste (oparte na nazwie dokumentu) zapytanie wyszukiwania semantycznego, aby wyświetlić frazę kluczową i jego względny wynik dla każdego dokumentu:
-- Pobieranie frazy kluczowej i względnego wyniku dla wszystkich dokumentówSELECT * FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) ORDER BY score Wynik:
Dodajmy więcej szczegółów do nazw dokumentów. Zmienimy ich nazwy w następujący sposób:
- Asif Permanent Employee – Doświadczony Project Manager
- Mike Stały Pracownik – Świeży Programista
- Peter Stały Pracownik – Kierownik ds. Świeżych Projektów
- Pracownik kontraktowy Sadaf — doświadczony analityk biznesowy
Znajdowanie nowych pracowników (dokumenty)
Znajdź dokumenty dotyczące nowych pracowników na podstawie ich tytułów (standardowe nazewnictwo):
-- Uzyskiwanie punktacji opartej na nazwie dokumentu w celu znalezienia nowych pracowników dla nowego projektu SELECT (nazwa SELECT z EmployeesDocumentStore, gdzie path_locator=document_key) jako DocumentName,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) gdzie keyphrase='fresh 'zamówienie według DocumentName opis Wyniki:
Znajdowanie doświadczonych pracowników (dokumenty)
Załóżmy, że chcemy szybko przejrzeć wszystkie szczegóły dotyczące doświadczonych pracowników dla nadchodzącego złożonego projektu. Użyj następującego zapytania wyszukiwania semantycznego:
-- Pobieranie punktacji opartej na nazwie dokumentu w celu znalezienia wszystkich doświadczonych pracownikówSELECT (WYBIERZ nazwę z EmployeesDocumentStore, gdzie path_locator=document_key) jako DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME) gdzie keyphrase='bydoświadczony' NazwaDokumentu Wynik:
Znalezienie wszystkich kierowników projektów (dokumentów)
Na koniec, jeśli chcemy szybko przejrzeć dokumenty dla wszystkich kierowników projektów, potrzebujemy następującego zapytania wyszukiwania semantycznego:
-- Pobieranie punktacji opartej na nazwie dokumentu w celu znalezienia wszystkich kierowników projektów SELECT (WYBIERZ nazwę z EmployeesDocumentStore, gdzie path_locator=document_key) jako DocumentName ,keyphrase,score FROM semantickeyphrasetable(EmployeesDocumentStore, NAME)gdzie keyphrase='Project'Wyniki:
Po wdrożeniu instrukcji możesz z powodzeniem przechowywać nieustrukturyzowane dane, takie jak dokumenty MS Word, w folderze Windows przy użyciu tabeli plików.
Przegląd analizy opartej na nazwach
Do tej pory nauczyliśmy się przeprowadzać analizę opartą na nazwach dokumentów przechowywanych w tabeli plików za pomocą wyszukiwania semantycznego. Musimy jednak spełnić następujące warunki:
- Standardowe nazewnictwo powinno być na miejscu.
- Nazwiska powinny zawierać informacje wymagane do analizy.
Te warunki są również ograniczeniami analizy opartej na nazwie. Ale to nie znaczy, że nie możemy wiele z tym zrobić.
Skupiamy się na podejściu wyszukiwania semantycznego opartego na nazwach/kolumnach.
Wyświetl kolumny nazw dokumentów
Zobaczmy niektóre z głównych kolumn tabeli Dokumenty, w tym Nazwa kolumna:
USE EmployeesFilestreamSample-- Wyświetl kolumnę nazwy z typami plików przechowywanych dokumentów w tabeli plików do analizy SELECT nazwa,typ_pliku FROM dbo.EmployeesDocumentStore Wynik:
Zrozumienie funkcji SEMANTICKEYPHRASETABLE
SQL Server oferuje SEMANTICKEYPHRASETABLE funkcja analizy dokumentu za pomocą wyszukiwania semantycznego. Składnia jest następująca:
SEMANTICKEYPHRASETABLE ( tabela, { kolumna | (lista_kolumn) | * } [ , klucz_źródłowy ] ) Ta funkcja podaje nam kluczowe frazy związane z dokumentem. Możemy je wykorzystać do analizy dokumentów na podstawie ich nazw lub treści. W naszym przypadku musimy nie tylko korzystać z tej funkcji, ale także rozumieć, jak właściwie z niej korzystać.
Funkcja wymaga następujących danych:
- Nazwa tabeli plików, która ma być używana do analizy wyszukiwania semantycznego.
- Nazwa kolumny, która ma być używana do analizy wyszukiwania semantycznego.
Następnie zwraca następujące dane:
- Id kolumny – numer kolumny
- Klucz_dokumentu – domyślny klucz podstawowy dla dokumentu tabeli plików
- Fraza kluczowa – to fraza, którą Semantic Search postanawia zindeksować do analizy. Dotyczy to zarówno nazwy, jak i treści dokumentu, w zależności od tego, w której kolumnie chcemy zobaczyć kluczowe frazy
- Wynik – określa siłę frazy kluczowej powiązanej z dokumentem, np. jak dokument jest najlepiej rozpoznawany przez frazę kluczową. Wynik może wynosić od 0,0 do 1,0.
Analiza wszystkich dokumentów za pomocą funkcji SEMANTICKEYPHRASETABLE
Używamy SEMANTICKEYPHRASETABLE funkcja do analizy nazw dokumentów przechowywanych w folderze Windows zarządzanym przez tabelę plików.
Wykonaj następujący skrypt T-SQL:
USE EmployeesFilestreamSample-- Wyświetl frazy kluczowe i ich wynik dla kolumny nazwy SELECT * FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name)kolejność według wyniku opis Wynik:
Mamy listę wszystkich fraz kluczowych dołączonych do wszystkich dokumentów wraz z ich punktacją. column_id 3 w górnym rzędzie jest nazwisko kolumna. Dodatkowo, wywołaliśmy również funkcję, podając tę kolumnę (nazwa):
Możesz znaleźć klucz_dokumentu : 0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 uruchamiający następujący skrypt (chociaż jasne jest, że ten dokument to ten, w którym nazwa zawiera frazę kluczową sadaf ):
USE EmployeesFilestreamSample-- znajdowanie nazwy dokumentu według klucza (path_locator)SELECT nazwa,path_locator FROM dbo.EmployeesDocumentStoreWHERE path_locator=0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260 Wynik:
fraza kluczowa sadaf otrzymał najlepszy wynik :1.0 .
Tak więc w przypadku standardowego nazewnictwa dokumentów z wystarczającą ilością informacji do analizy wyszukiwania semantycznego, nasza fraza kluczowa sadaf najlepiej pasuje do tej konkretnej nazwy dokumentu.
Analiza konkretnego dokumentu za pomocą funkcji SEMANTICKEYPHRASETABLE
Możemy zawęzić naszą analizę wyszukiwania semantycznego na podstawie nazwy kolumna. Na przykład musimy tylko wyświetlić kolumnę nazwa- oparte na frazach kluczowych danego dokumentu. Klucz dokumentu możemy określić w SEMANTICKEYPHRASETABLE Funkcja.
Najpierw identyfikujemy klucz dokumentu dla tego dokumentu, w którym chcemy zobaczyć wszystkie kluczowe frazy. Uruchom następujący skrypt T-SQL:
-- Znajdź document_key dokumentu, którego nazwa zawiera PeterSELECT name,path_locator jako document_key Z nazwy EmployeesDocumentStoreWHERE, np. „%Peter%” Klucz dokumentu to 0xFF6A92952500812FF013376870181CFA6D7C070220
Teraz przejrzyjmy ten dokument dotyczący wszystkich fraz kluczowych, które mogą określać nazwę dokumentu:
-- Wyświetl wszystkie frazy kluczowe i ich wynik dla dokumentu związanego ze stałym pracownikiem Peter SELECT column_id,name,keyphrase,score FROM SEMANTICKEYPHRASETABLE(EmployeesDocumentStore,name,0xFF6A92952500812FF013376870181CFA6D7C070220)eboes. opis punktacji Wyniki:
Fraza kluczowa pracownik otrzymuje najwyższy wynik w tym dokumencie. Widzimy, że wszystkie słowa w kolumnie są frazami kluczowymi, które określają znaczenie dokumentu.
Zrozumienie funkcji SEMANTICSSIMILARITYTABLE
Ta funkcja pomaga nam porównać jeden dokument ze wszystkimi innymi dokumentami na podstawie fraz kluczowych. Składnia tej funkcji jest następująca:
SEMANTICSIMILARITYTABLE ( tabela, { kolumna | (lista_kolumn) | * }, klucz_źródłowy ) Wymaga nazwy tabeli, kolumny i klucza dokumentu, aby pasowały do innych dokumentów. Na przykład możemy stwierdzić, że dwa dokumenty są podobne, jeśli mają dobry wynik dopasowania frazy.
Porównywanie dokumentów za pomocą funkcji SEMANTICSSIMILARITYTABLE
Porównajmy dokument z innymi dokumentami za pomocą TABELI SEMANTICSSIMILARITY Funkcja.
Porównanie wszystkich dokumentów kierowników projektów
Musimy zobaczyć wszystkie dokumenty związane z kierownikami projektów. Z powyższych przykładów wiemy, że klucz dokumentu dla określonego dokumentu to 0xFF6A92952500812FF013376870181CFA6D7C070220 . Dlatego możemy użyć tego klucza do znalezienia innych dopasowań, w tym kierowników projektów:
USE EmployeesFilestreamSample-- Wyświetl wszystkie dokumenty ściśle związane z kierownikiem projektu Peter SELECT SST.source_column_id,SST.matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFF6A92JO53700702C01boEStore .path_locator=SST.matched_document_keyorder według opisu wyniku Wynik:
Najbliżej powiązanym dokumentem jest Asif Permanent Employee – Doświadczony Project Manager.docx . Ma to sens, ponieważ obaj pracownicy są pracownikami stałymi i obaj są kierownikami projektów.
Porównanie dokumentów doświadczonego analityka biznesowego
Teraz porównamy dokumenty związane z doświadczonym analitykiem biznesowym s i znajdź najbliższe dopasowanie za pomocą wyszukiwania semantycznego. Ograniczamy się do analizy opartej na nazwie dokumentu:
UŻYJ EmployeesFilestreamSample-- Znajdowanie klucza_dokumentu dla doświadczonego analityka biznesowegowybierz nazwę,path_locator jako klucz_dokumentu z EmployeesDocumentStore, np. „%doświadczony analityk biznesowy%”-- Wyświetl wszystkie dokumenty ściśle związane z doświadczonym analitykiem biznesowym.SELECT SST.source_column_id,SST. matched_column_id,EDS.name,SCORE FROM SEMANTICSIMILARITYTABLE(EmployeesDocumentStore,name,0xFD89E1811D4F3B2FEB1012DF0C8016F9ACEB2F3260) SSTINNER JOIN dbo.EmployeesLoyeesDocument_Storage_Store_ScoreDs. Wynik:
Jak widać z powyższych wyników, najbardziej zbliżony do dokumentu związanego z doświadczonym analitykiem biznesowym to dokument doświadczonego kierownika projektu ponieważ obaj są doświadczeni . Niemniej jednak wynik 0,3 wskazuje, że te dwa dokumenty nie mają wiele wspólnego.
Wniosek
Gratulacje! Z powodzeniem nauczyliśmy się przechowywać dokumenty w folderach Windows i analizować je za pomocą wyszukiwania semantycznego. Zbadaliśmy również funkcje, które można wykorzystać w praktyce. Teraz możesz zastosować nową wiedzę i wypróbować następujące ćwiczenia, aby
Czekajcie na dalsze materiały!