Czym są unikalne ograniczenia kluczowe?
Ograniczenie unikatowe to reguła, która ogranicza wpisy kolumn do unikatowych. Innymi słowy, tego typu ograniczenia uniemożliwiają wstawianie duplikatów do kolumny. Unikalne ograniczenie jest jednym z instrumentów egzekwowania integralności danych w bazie danych SQL Server. Ponieważ tabela może mieć tylko jeden klucz podstawowy, możesz użyć ograniczenia unikalności, aby wymusić unikalność kolumny lub kombinacji kolumn, które nie stanowią klucza podstawowego.
Utworzenie unikatowego ograniczenia w kolumnie automatycznie tworzy unikatowy indeks. W ten sposób SQL Server realizuje wymóg integralności ograniczenia unikatowego. W związku z tym podczas próby wstawienia zduplikowanej wartości do kolumny, w której zdefiniowano ograniczenie przez unikalność, Aparat baz danych wykryje naruszenie ograniczenia przez unikalność i wystawi odpowiedni błąd. W rezultacie wiersz ze zduplikowanymi wartościami nie zostanie dodany do tabeli.
Tworzenie unikalnego ograniczenia
Poniższe przykładowe zapytanie tworzy grupę Studentów tabeli i unikatowego ograniczenia w Zaloguj się tak, aby nie było uczniów o tym samym loginie.
CREATE TABLE Students ( Login CHAR NOT NULL ,CONSTRAINT AK_Student_Login UNIQUE (Login) ); GO
Jeśli Uczniowie tabela już istnieje, możesz użyć następującego przykładowego zapytania, aby utworzyć ograniczenie przez unikalność.
ALTER TABLE Students ADD CONSTRAINT AK_Student_Login UNIQUE (Login); GO
Należy zauważyć, że po dodaniu ograniczenia unikatowego do istniejącej tabeli Aparat baz danych sprawdza, czy kolumna, do której dodano ograniczenie, zawiera zduplikowane wartości. Jeśli istnieją takie wartości, ograniczenie nie zostanie dodane, zwracając błąd.
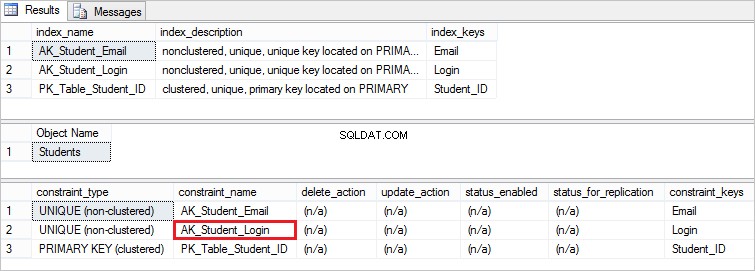
Teraz, aby sprawdzić, czy ograniczenie przez unikalność zostało rzeczywiście dodane, wykonaj następujące instrukcje:
EXEC sp_helpindex Students EXEC sp_helpconstraint Students
Oto ograniczenie, które stworzyliśmy:
Tworzenie unikatowego ograniczenia w SQL Server Management Studio
Załóżmy, że musimy zdefiniować unikatowe ograniczenie w Login kolumna to Studenci tabela.
1. W Eksploratorze obiektów , kliknij prawym przyciskiem myszy Uczniowie tabeli i kliknij Projekt .
2. Kliknij prawym przyciskiem myszy Projektant tabel i wybierz Indeksy/klucze…
3. W Indeksach/Kluczach kliknij Dodaj .
4. W sekcji Ogólne sekcji, kliknij Kolumny a następnie kliknij przycisk z wielokropkiem. W kolumnach indeksu w oknie wybierz kolumny, które chcesz uwzględnić w ograniczeniu unikatowości.
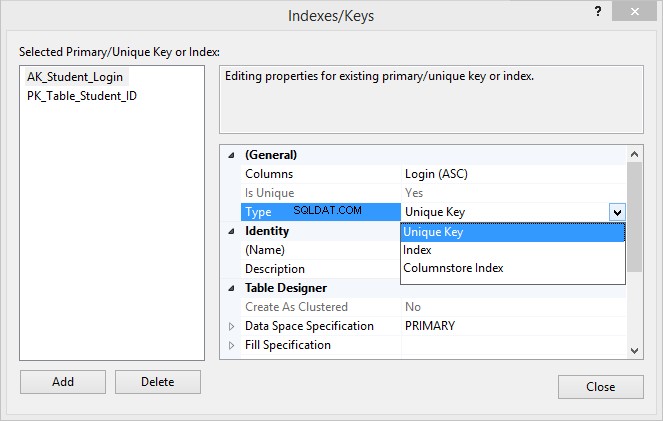
5. W sekcji Ogólne sekcji, kliknij Typ i wybierz Unikalny klucz z listy rozwijanej.
6. Pod Tożsamością podaj nazwę ograniczenia (w naszym przypadku AK_Student_Login ) i kliknij Zamknij aby zapisać nowo utworzone ograniczenie.
Teraz, jeśli przejdziesz do Studentów tabela w Eksploratorze obiektów i kliknij Indeksy zobaczysz, że tabela zawiera klucz podstawowy i ograniczenie unikatowości AK_Student_Login .
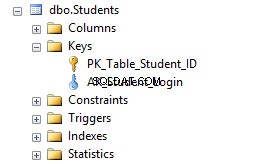
Czym różnią się unikalne ograniczenia od kluczy podstawowych?
Podobnie jak w przypadku ograniczenia przez unikalność, klucz podstawowy jest również używany do wymuszania integralności danych w tabeli. Ale głównym celem klucza podstawowego jest jednoznaczne zidentyfikowanie każdego rekordu w tabeli i zaimplementowanie właściwych relacji między tabelami w bazie danych. Klucz podstawowy jest wymagany w 99% tabel, aby umożliwić prawidłowy dostęp do wierszy tabeli. Może być tylko jeden klucz podstawowy na tabelę zdefiniowany w jednej lub więcej niż jednej kolumnie.
Unikalne ograniczenia są używane w szczególności, aby zapobiec wstawianiu zduplikowanych wartości do kolumny. Może istnieć kilka kolumn z unikalnymi ograniczeniami lub w tabeli może nie być żadnych unikalnych ograniczeń. Nie są one obowiązkowe dla tabeli w przeciwieństwie do kluczy podstawowych.
Załóżmy, że mamy Studentów tabela zawierająca dane osobowe każdego studenta na uczelni. Tabela zawiera identyfikator ucznia kolumna, która jest kluczem podstawowym i przechowuje unikalny identyfikator każdego konkretnego ucznia. Ta kolumna klucza podstawowego służy do jednoznacznej identyfikacji każdego studenta na uniwersytecie.
Jednocześnie Studenci tabela zawiera takie kolumny jak Email , Numer ubezpieczenia społecznego i Zaloguj się a każda z tych kolumn musi przechowywać unikalne wartości. Ponieważ w tabeli jest już jeden klucz podstawowy, zamiast tego użyjemy ograniczeń unikalności, aby narzucić unikalność tym kolumnom. W ten sposób tabela może mieć wiele unikalnych ograniczeń i tylko jeden klucz podstawowy.
Inną rzeczą, która różni unikatowe ograniczenie od klucza podstawowego jest to, że klucz podstawowy nie zezwala na żadne NULL wartości w kolumnie, podczas gdy kolumna z ograniczeniem unikalności może zawierać NULL wartość, ale tylko jedną, ponieważ SQL Server interpretuje dwie wartości NULL jako te same.
Załóżmy, że w e-mailu utworzono ograniczenie niepowtarzalności kolumna Uczniów stół. Spróbujmy wstawić dwa wiersze, oba z NULL s w e-mailu pola:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (1, 'John White', 19, NULL, 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (2, 'James Marvin', 21, NULL, 987-65-4321, 'Marvin_J17') GO
Otrzymujemy następujący komunikat o błędzie:

Cóż, jest to przewidywalne zachowanie, ponieważ zduplikowane wartości, nawet jeśli są wartościami NULL, nie są dozwolone przez ograniczenie unikatowości.
Unikalne ograniczenie a unikalny indeks
Chociaż zarówno ograniczenie unikatowe, jak i indeks unikatowy są dwiema zupełnie różnymi niepowiązanymi jednostkami bazy danych, mają ten sam cel i taki sam wpływ na wydajność programu SQL Server. Obie zapewniają niepowtarzalność danych w kolumnie.
Jednak w przeciwieństwie do indeksu unikatowego, nie można określić opcji IGNORE_DUP_KEY, DROP_EXISTING, PAD_INDEX i STATISTICS_NORECOMPUTE dla ograniczenia przez unikalność w instrukcjach ALTER TABLE.
Kiedy tworzysz unikalne ograniczenie dla kolumny, SQL Server automatycznie tworzy unikalny indeks dla kolumny, tak właśnie jest zaimplementowana ta funkcja w SQL Server.
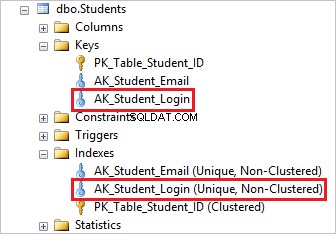
Aby usunąć unikalny indeks, musisz najpierw usunąć odpowiednie ograniczenie unikatowości, a to automatycznie usunie bazowy unikalny indeks.
Poniższa instrukcja usunie AK_Student_Login ograniczenie:
ALTER TABLE Students DROP CONSTRAINT AK_Student_Login; GO
Możesz to zobaczyć, upuszczając AK_Student_Login unikatowe ograniczenie usuwa odpowiadający mu indeks.
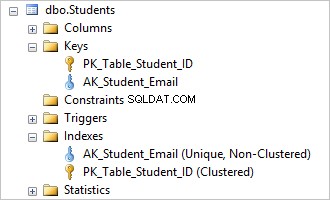
To było łatwe, teraz możesz wstawić identyczne wartości do Login kolumna.
Wyłączanie unikalnego ograniczenia
Istnieje opcja, która wyłącza unikatowe ograniczenie. Poniższe zapytanie ma wyłączyć wszystkie ograniczenia tabeli:
ALTER TABLE Students NOCHECK CONSTRAINT ALL GO
Po wykonaniu zapytania spróbujmy teraz wstawić zduplikowany rekord:
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, NULL, 123-45-6789, 'John555') GO
Otrzymujemy komunikat o naruszeniu unikatowego ograniczenia:

Wygląda więc na to, że ALTER TABLE
Pamiętaj jednak, że pod maską każdego unikalnego ograniczenia kryje się unikalny indeks i powinniśmy być w stanie wyłączyć unikalny indeks. W naszym przypadku AK_Student_Email unikalne ograniczenie utworzyło odpowiedni AK_Student_Email unikalny indeks w e-mailu kolumna. Użyjmy następującego zapytania, aby wyłączyć AK_Student_Email najpierw unikalny indeks.
ALTER INDEX AK_Student_Email ON Students DISABLE;
Zapytanie zostało pomyślnie zakończone, więc teraz wstawmy dwa rekordy ze zduplikowanym e-mailem pola do Uczniów tabela.
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (3, 'John White', 19, 'example@sqldat.com', 123-45-6789, 'John555') GO
INSERT INTO Students (Student_ID, Name, Age, Email, SSN, Login) VALUES (4, 'James Marvin', 21, 'example@sqldat.com', 987-65-4321, 'Marvin_J17') GO
To działa! Rekordy zostały wstawione do tabeli! Teraz wiemy, jak obejść ten problem „niepełnosprawności” za pomocą unikalnego ograniczenia.
Aby włączyć indeks, użyj następującego zapytania:
ALTER INDEX AK_Student_Email ON Students REBUILD;
Wniosek
Unikalne ograniczenia kluczowe pozwalają administratorom baz danych i programistom SQL wymusić i zachować unikalność danych w kolumnach tabeli, a także zastosować określone wymagania biznesowe dotyczące integralności danych. Zasadniczo nie ma istotnej różnicy w zachowaniu między ograniczeniem przez unikalność a unikalnym indeksem, z wyjątkiem faktu, że ograniczenie przez unikalność nie może być bezpośrednio wyłączone, a niektóre opcje tworzenia indeksu nie są dostępne dla ograniczeń przez unikalność w instrukcji ALTER TABLE.
Mam nadzieję, że ten artykuł był interesujący. Możesz zadawać pytania, zostawiać komentarze i sugestie dotyczące tego artykułu.
Zobacz też: SPRAWDŹ Ograniczenia w SQL Server