Kopie zapasowe mają kluczowe znaczenie, jeśli chodzi o bezpieczeństwo danych. Są one najlepszym rozwiązaniem do odzyskiwania danych po awarii — nie masz dostępnych węzłów bazy danych, a Twoje centrum danych mogło dosłownie zniknąć z dymem, ale dopóki masz kopię zapasową danych, nadal możesz odzyskać dane z takiej sytuacji.
Zazwyczaj kopie zapasowe są używane do odzyskiwania w różnych typach przypadków:
- przypadkowe DROP TABLE lub DELETE bez klauzuli WHERE lub z klauzulą WHERE, która nie była wystarczająco precyzyjna.
- aktualizacja bazy danych, która kończy się niepowodzeniem i uszkadza dane
- awaria/uszkodzenie nośnika pamięci
Czy przywracanie z kopii zapasowej nie wystarczy? Co to musi być punkt w czasie? Musimy pamiętać, że kopia zapasowa to migawka danych zrobionych w danym momencie. Jeśli zrobisz kopię zapasową o 1:00, a tabela została przypadkowo usunięta o 11:00, możesz przywrócić dane do 1:00, ale co ze zmianami, które zaszły między 1:00 a 11:00? Te zmiany zostaną utracone, chyba że będziesz mógł odtworzyć modyfikacje, które miały miejsce w międzyczasie. Na szczęście MySQL posiada taki mechanizm przechowywania zmian - logi binarne. Możesz wiedzieć, że te logi są używane do replikacji — MySQL używa ich do przechowywania wszystkich zmian, które zaszły w urządzeniu głównym, a urządzenie podrzędne używa ich do odtworzenia tych zmian i zastosowania ich do swojego zestawu danych. Ponieważ logi przechowują wszystkie zmiany, możesz ich również użyć do odtworzenia ruchu. W tym poście na blogu przyjrzymy się, w jaki sposób ClusterControl może pomóc w przeprowadzeniu odzyskiwania do punktu w czasie (PITR).
Tworzenie kopii zapasowej zgodnej z odzyskiwaniem do określonego momentu
Przede wszystkim porozmawiajmy o warunkach wstępnych. Host, z którego wykonujesz kopie zapasowe, musi mieć włączone dzienniki binarne. Bez nich PITR nie jest możliwy. Drugie wymaganie - host, z którego wykonujesz kopie zapasowe, powinien mieć wszystkie logi binarne wymagane do przywrócenia do danego punktu w czasie. Jeśli użyjesz zbyt agresywnej rotacji dzienników binarnych, może to stać się problemem.
Zobaczmy więc, jak korzystać z tej funkcji w ClusterControl. Przede wszystkim musisz wykonać kopię zapasową, która jest zgodna z PITR. Taka kopia zapasowa musi być pełna, kompletna i spójna. W przypadku xtrabackup, o ile zawiera pełny zestaw danych (nie uwzględniłeś tylko podzbioru schematów), będzie on kompatybilny z PITR.
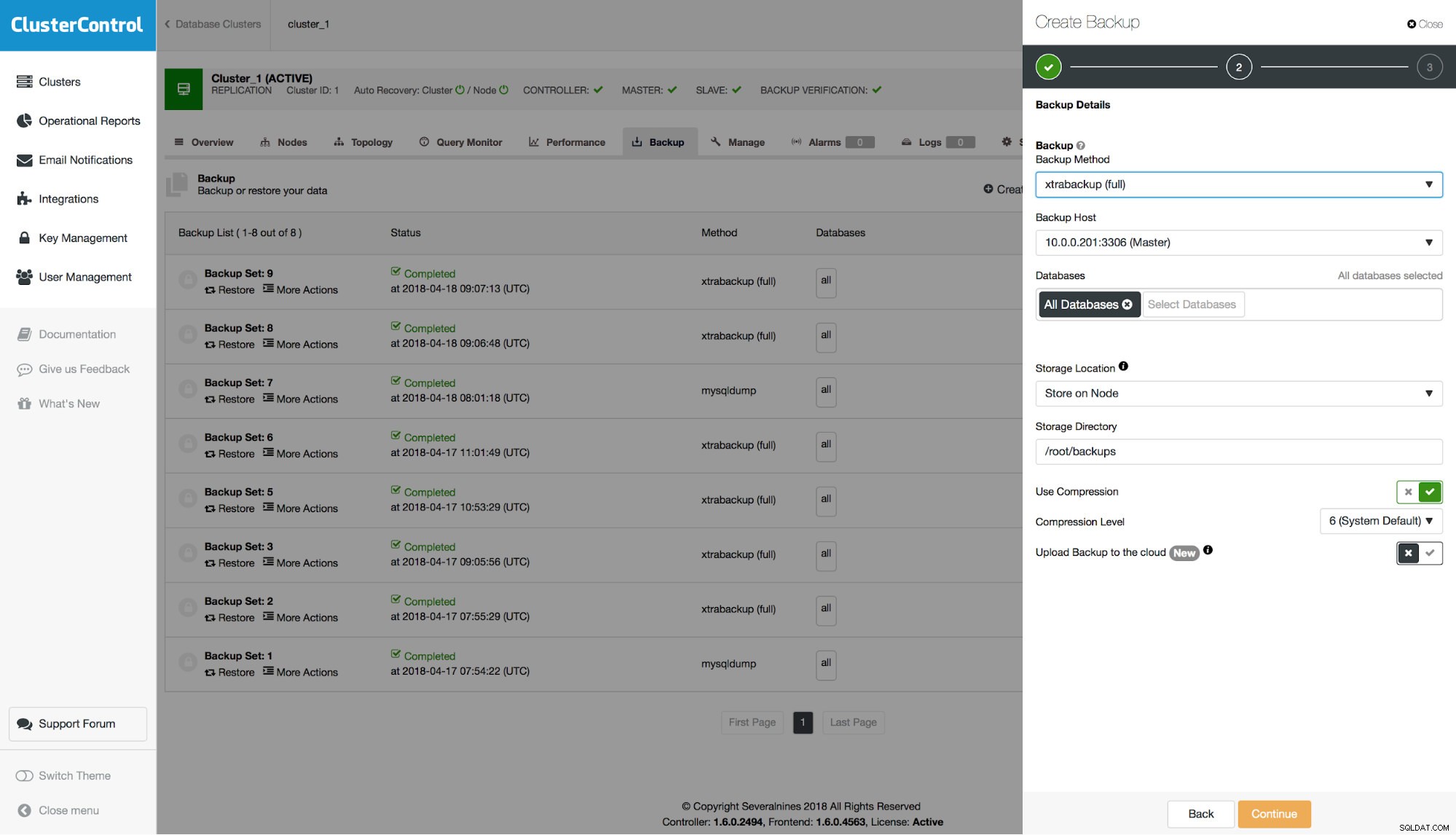
W przypadku mysqldump istnieje możliwość uczynienia go kompatybilnym z PITR. Po włączeniu tej opcji wszystkie niezbędne opcje zostaną skonfigurowane (na przykład nie będzie można wybrać oddzielnych schematów do uwzględnienia w zrzucie), a kopia zapasowa zostanie oznaczona jako dostępna do odzyskania do określonego momentu.
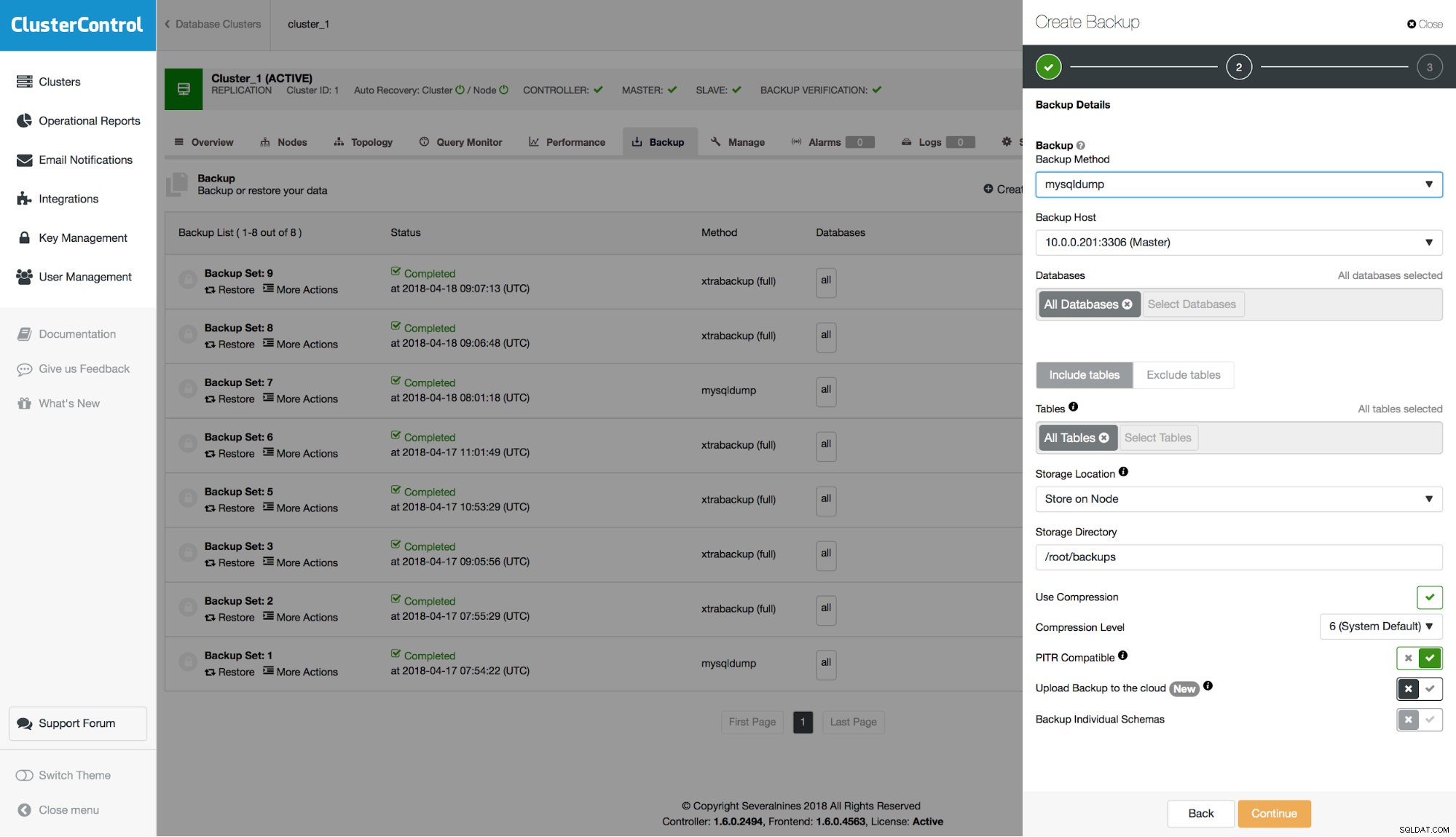
Odzyskiwanie do określonego momentu z kopii zapasowej
Najpierw musisz wybrać kopię zapasową do przywrócenia.
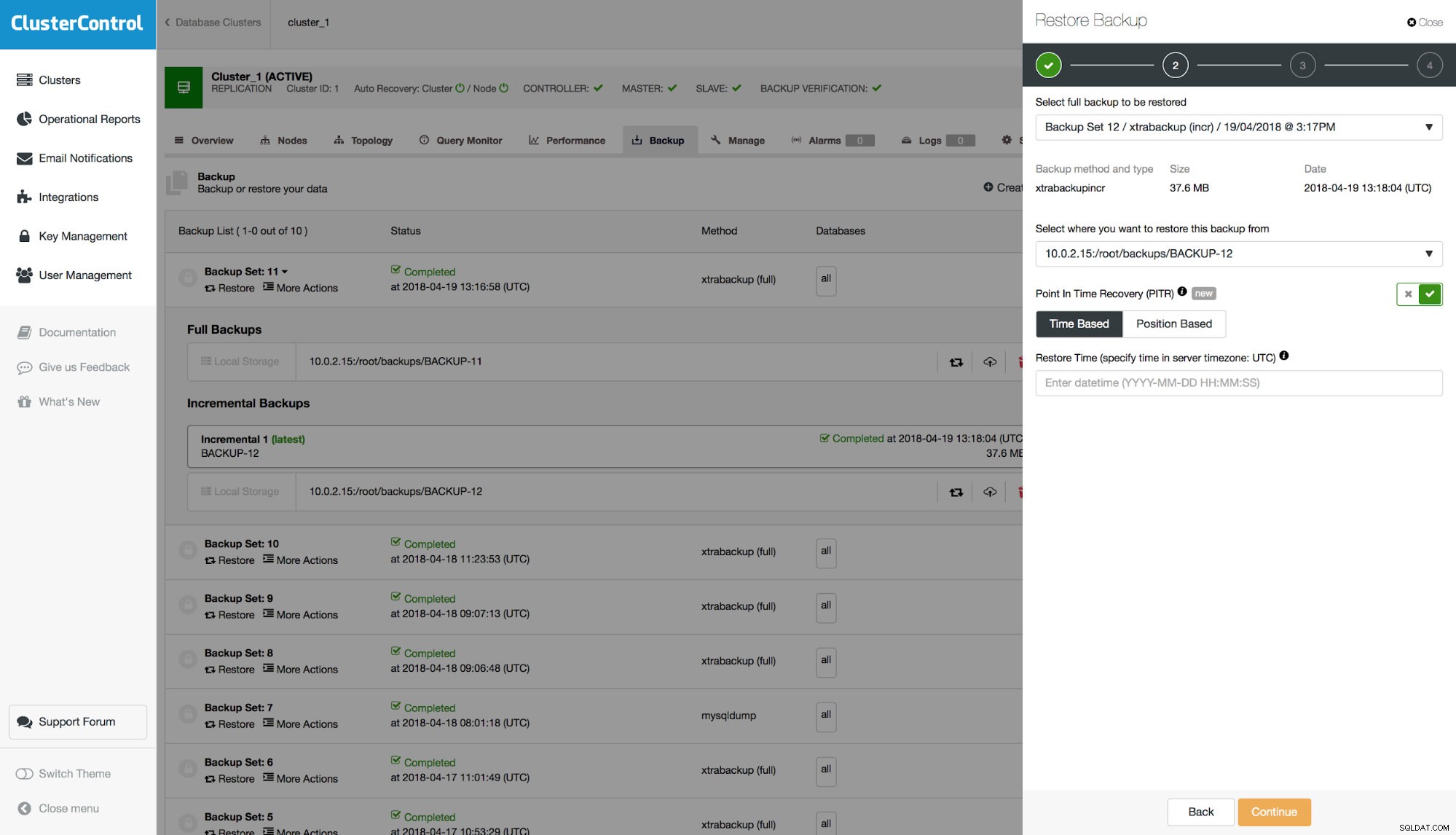
Jeśli kopia zapasowa jest zgodna z PITR, zostanie wyświetlona opcja wykonania odzyskiwania do określonego punktu w czasie. Będziesz mieć do tego dwie opcje – „Na podstawie czasu” i „Na podstawie pozycji”. Omówmy różnicę między tymi dwiema opcjami.
PITR „oparty na czasie”
Dzięki tej opcji możesz podać datę i godzinę, do której kopia zapasowa powinna zostać przywrócona. Można go zdefiniować z dokładnością do jednej sekundy. Nie gwarantuje to, że wszystkie dane zostaną przywrócone, ponieważ nawet przy bardzo precyzyjnym określeniu czasu w ciągu jednej sekundy w dzienniku binarnym może zostać zapisanych wiele zdarzeń. Załóżmy, że wiesz, że utrata danych nastąpiła 18 kwietnia o godzinie 10:00:01. Do formularza wpisujesz następującą datę i godzinę:„2018-04-18 10:00:00”. Pamiętaj, że powinieneś używać czasu opartego na ustawieniach strefy czasowej na serwerze bazy danych, na którym utworzono kopię zapasową.
Nadal może się zdarzyć, że utrata danych nie była nawet pierwszą, która miała miejsce o 10:00:01, więc niektóre zdarzenia zostaną w tym procesie utracone. Zobaczmy, co to oznacza.
W ciągu jednej sekundy w dziennikach binarnych może być rejestrowanych wiele zdarzeń. Rozważmy taki przypadek:
10:00:00 - zdarzenia A,B,C,D,E,F
10:00:01 - zdarzenia V,W,X,Y,Z
gdzie X to zdarzenie utraty danych. Z dokładnością co do sekundy możesz przywrócić wszystko, co wydarzyło się o 10:00:00 (a więc do F) lub do 10:00:01 (do Z). Ten ostatni przypadek jest bezużyteczny, ponieważ X zostałby ponownie wykonany. W pierwszym przypadku brakuje nam V i W.
Dlatego przywracanie na podstawie pozycji jest bardziej precyzyjne. Możesz powiedzieć „Chcę przywrócić do W”.
Przywracanie na podstawie czasu jest najbardziej precyzyjne, jakie można uzyskać, bez konieczności przechodzenia do dzienników binarnych i definiowania dokładnej pozycji, w której chcesz przywrócić. To prowadzi nas do drugiej metody wykonywania PITR.
PITR „na podstawie pozycji”
Tutaj wymagane jest pewne doświadczenie z narzędziami wiersza poleceń dla MySQL, a mianowicie narzędziem mysqlbinlog. Z drugiej strony będziesz mieć najlepszą kontrolę nad sposobem odzyskiwania.
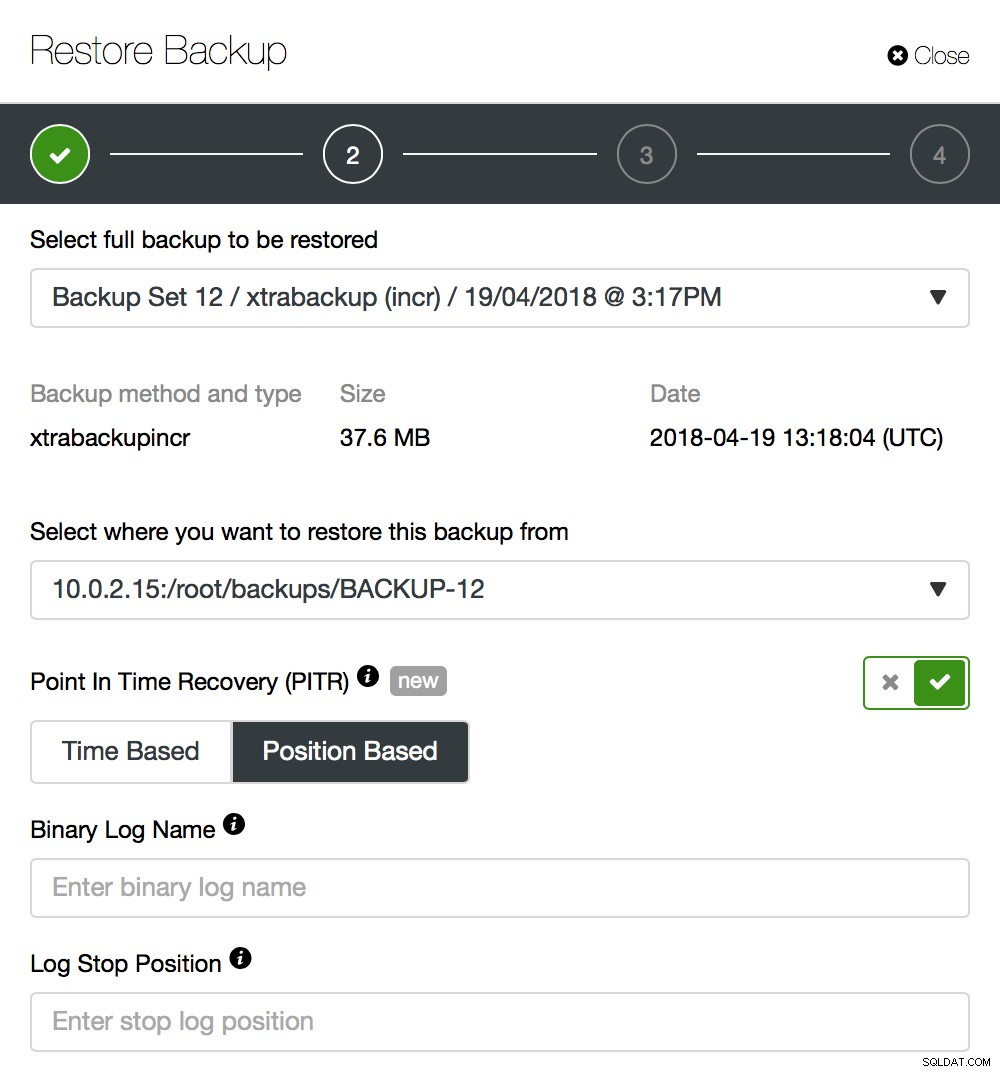
Przejdźmy przez prosty przykład. Jak widać na powyższym zrzucie ekranu, będziesz musiał przekazać nazwę dziennika binarnego i pozycję dziennika binarnego, do którego punktu kopia zapasowa powinna zostać przywrócona. W większości przypadków powinna to być ostatnia pozycja przed utratą danych.
Ktoś wykonał polecenie SQL, które spowodowało poważną utratę danych:
mysql> DROP TABLE sbtest1;
Query OK, 0 rows affected (0.02 sec)Nasza aplikacja natychmiast zaczęła narzekać:
sysbench 1.1.0-ecf1191 (using bundled LuaJIT 2.1.0-beta3)
Running the test with following options:
Number of threads: 2
Report intermediate results every 1 second(s)
Initializing random number generator from current time
Initializing worker threads...
Threads started!
FATAL: mysql_drv_query() returned error 1146 (Table 'sbtest.sbtest1' doesn't exist) for query 'DELETE FROM sbtest1 WHERE id=5038'
FATAL: `thread_run' function failed: /usr/local/share/sysbench/oltp_common.lua:490: SQL error, errno = 1146, state = '42S02': Table 'sbtest.sbtest1' doesn't existMamy kopię zapasową, ale chcemy przywrócić wszystkie dane do tego fatalnego momentu. Przede wszystkim zakładamy, że aplikacja nie działa, więc możemy odrzucić wszystkie zapisy, które miały miejsce po DROP TABLE jako nieistotne. Jeśli Twoja aplikacja działa do pewnego stopnia, będziesz musiał później scalić pozostałe zmiany. Ok, przeanalizujmy logi binarne, aby znaleźć pozycję instrukcji DROP TABLE. Ponieważ chcemy uniknąć analizowania wszystkich dzienników binarnych, sprawdźmy, jaką pozycję obejmowała nasza najnowsza kopia zapasowa. Możesz to sprawdzić, sprawdzając logi dla najnowszego zestawu kopii zapasowych i poszukaj wiersza podobnego do tego:
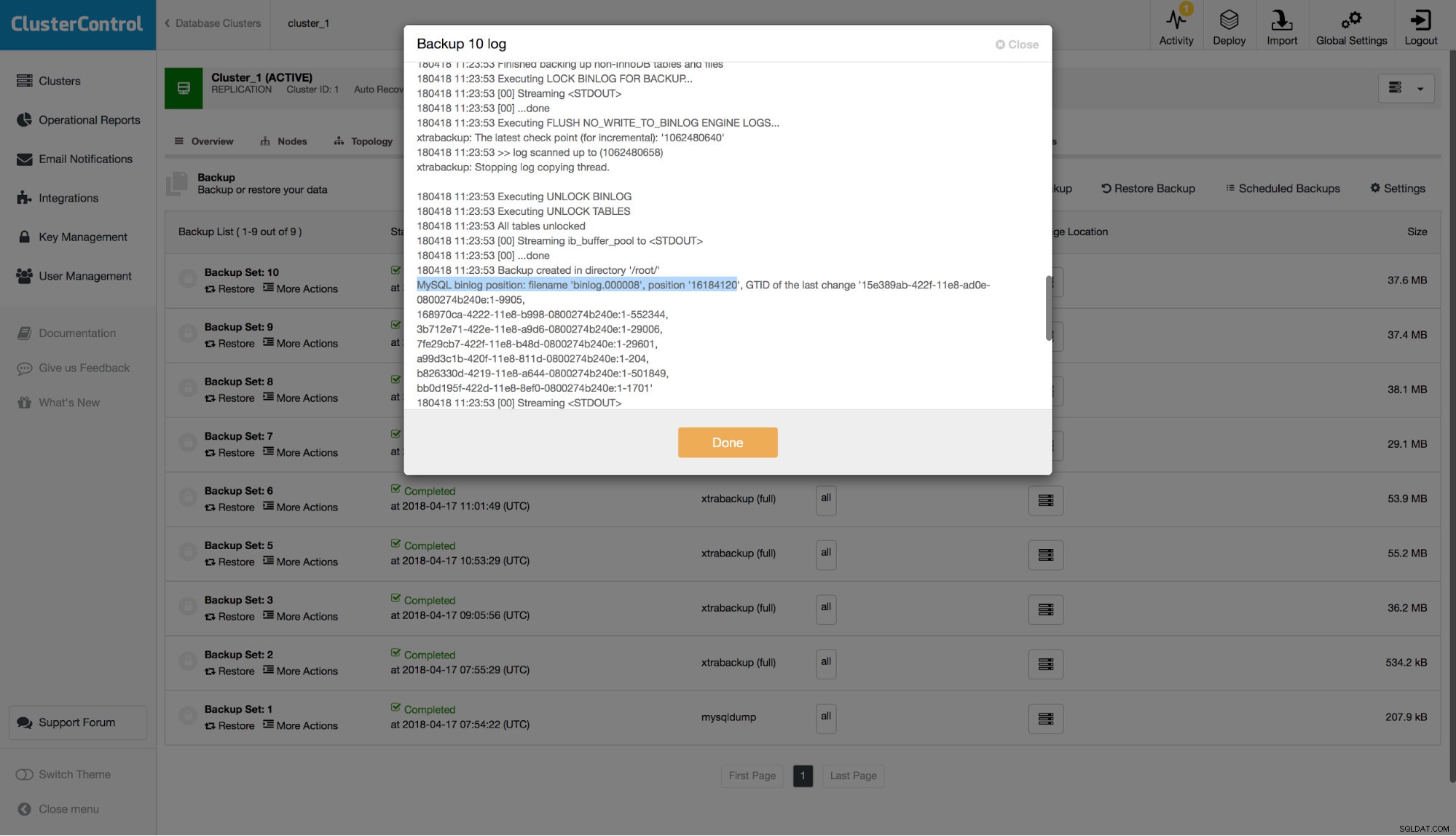
Mówimy więc o nazwie pliku „binlog.000008” i pozycji „16184120”. Wykorzystajmy to jako nasz punkt wyjścia. Sprawdźmy, jakie mamy binarne pliki dziennika:
example@sqldat.com:~# ls -alh /var/lib/mysql/binlog.*
-rw-r----- 1 mysql mysql 58M Apr 17 08:31 /var/lib/mysql/binlog.000001
-rw-r----- 1 mysql mysql 116M Apr 17 08:59 /var/lib/mysql/binlog.000002
-rw-r----- 1 mysql mysql 379M Apr 17 09:30 /var/lib/mysql/binlog.000003
-rw-r----- 1 mysql mysql 344M Apr 17 10:54 /var/lib/mysql/binlog.000004
-rw-r----- 1 mysql mysql 892K Apr 17 10:56 /var/lib/mysql/binlog.000005
-rw-r----- 1 mysql mysql 74M Apr 17 11:03 /var/lib/mysql/binlog.000006
-rw-r----- 1 mysql mysql 5.2M Apr 17 11:06 /var/lib/mysql/binlog.000007
-rw-r----- 1 mysql mysql 21M Apr 18 11:35 /var/lib/mysql/binlog.000008
-rw-r----- 1 mysql mysql 59K Apr 18 11:35 /var/lib/mysql/binlog.000009
-rw-r----- 1 mysql mysql 144 Apr 18 11:35 /var/lib/mysql/binlog.indexTak więc oprócz „binlog.000008” mamy również do sprawdzenia „binlog.000009”. Uruchommy polecenie, które przekonwertuje logi binarne na format SQL, zaczynając od pozycji, którą znaleźliśmy w logu kopii zapasowej:
example@sqldat.com:~# mysqlbinlog --start-position='16184120' --verbose /var/lib/mysql/binlog.000008 /var/lib/mysql/binlog.000009 > binlog.outWęzeł „--verbose” jest wymagany do dekodowania zdarzeń opartych na wierszach. Nie jest to koniecznie wymagane w przypadku szukanej przez nas tabeli DROP, ale może być potrzebne w przypadku innych rodzajów wydarzeń.
Przeszukajmy nasze dane wyjściowe dla zapytania DROP TABLE:
example@sqldat.com:~# grep -B 7 -A 1 "DROP TABLE" binlog.out
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;
# at 20885554
#180418 11:24:32 server id 1 end_log_pos 20885678 CRC32 0xb38a427b Query thread_id=54 exec_time=0 error_code=0
use `sbtest`/*!*/;
SET TIMESTAMP=1524050672/*!*/;
DROP TABLE `sbtest1` /* generated by server */
/*!*/;W tej próbce możemy zobaczyć dwa zdarzenia. Najpierw na pozycji 20885489 ustawia zmienną GTID_NEXT.
# at 20885489
#180418 11:24:32 server id 1 end_log_pos 20885554 CRC32 0xb89f2e66 GTID last_committed=38168 sequence_number=38170 rbr_only=no
SET @@SESSION.GTID_NEXT= '7fe29cb7-422f-11e8-b48d-0800274b240e:38170'/*!*/;Po drugie, na pozycji 20885554 znajduje się nasz event DROP TABLE. Prowadzi to do wniosku, że powinniśmy wykonać PITR do pozycji 20885489. Jedyne pytanie, na które należy odpowiedzieć, to o którym logu binarnym mówimy. Możemy to sprawdzić, wyszukując wpisy rotacji binlogów:
example@sqldat.com:~# grep "Rotate to binlog" binlog.out
#180418 11:35:46 server id 1 end_log_pos 21013114 CRC32 0x2772cc18 Rotate to binlog.000009 pos: 4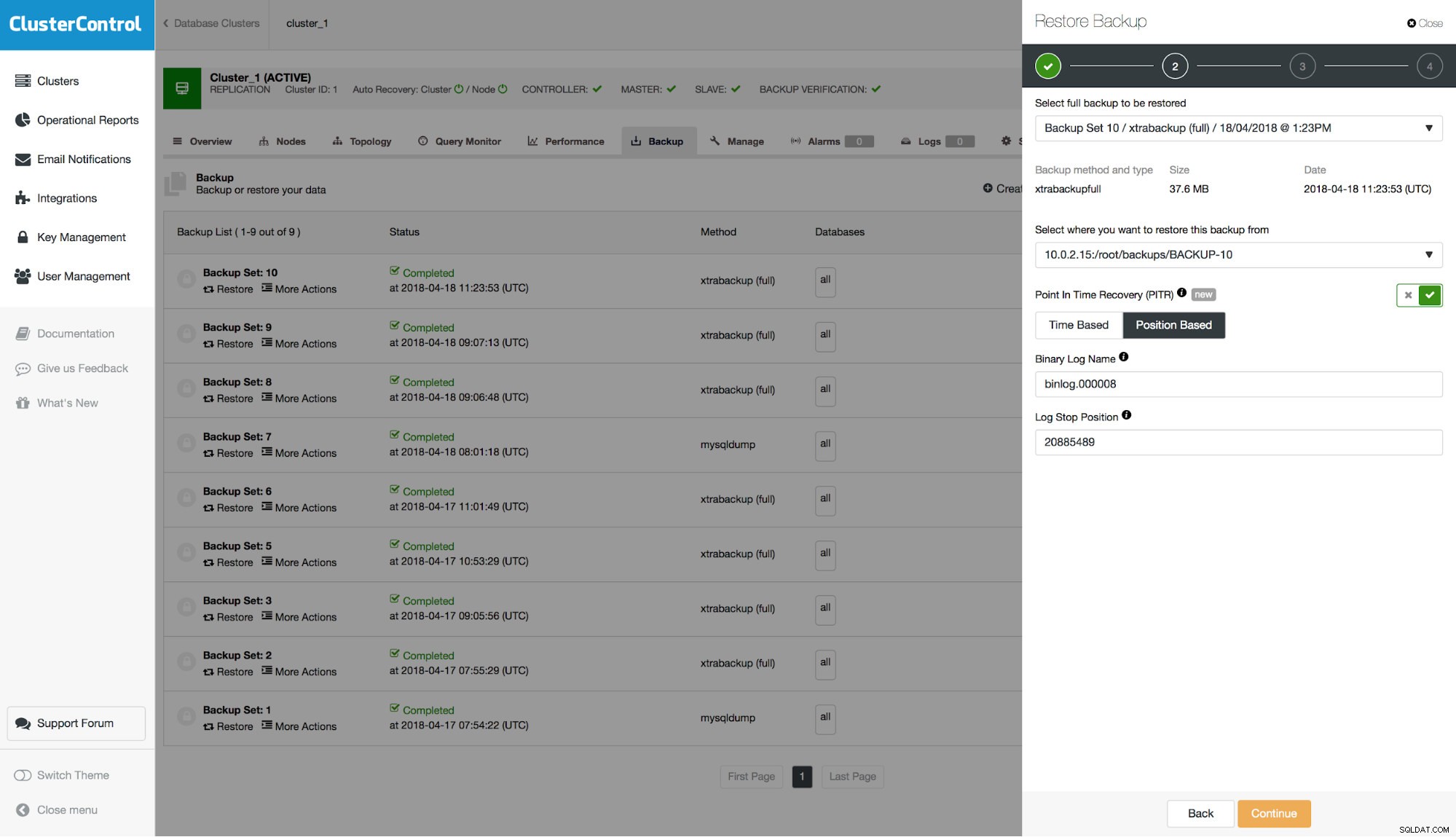
Jak widać po porównaniu dat, rotacja do binlog.000009 nastąpiła później, dlatego chcemy przekazać binlog.000008 jako plik binlog w formularzu.
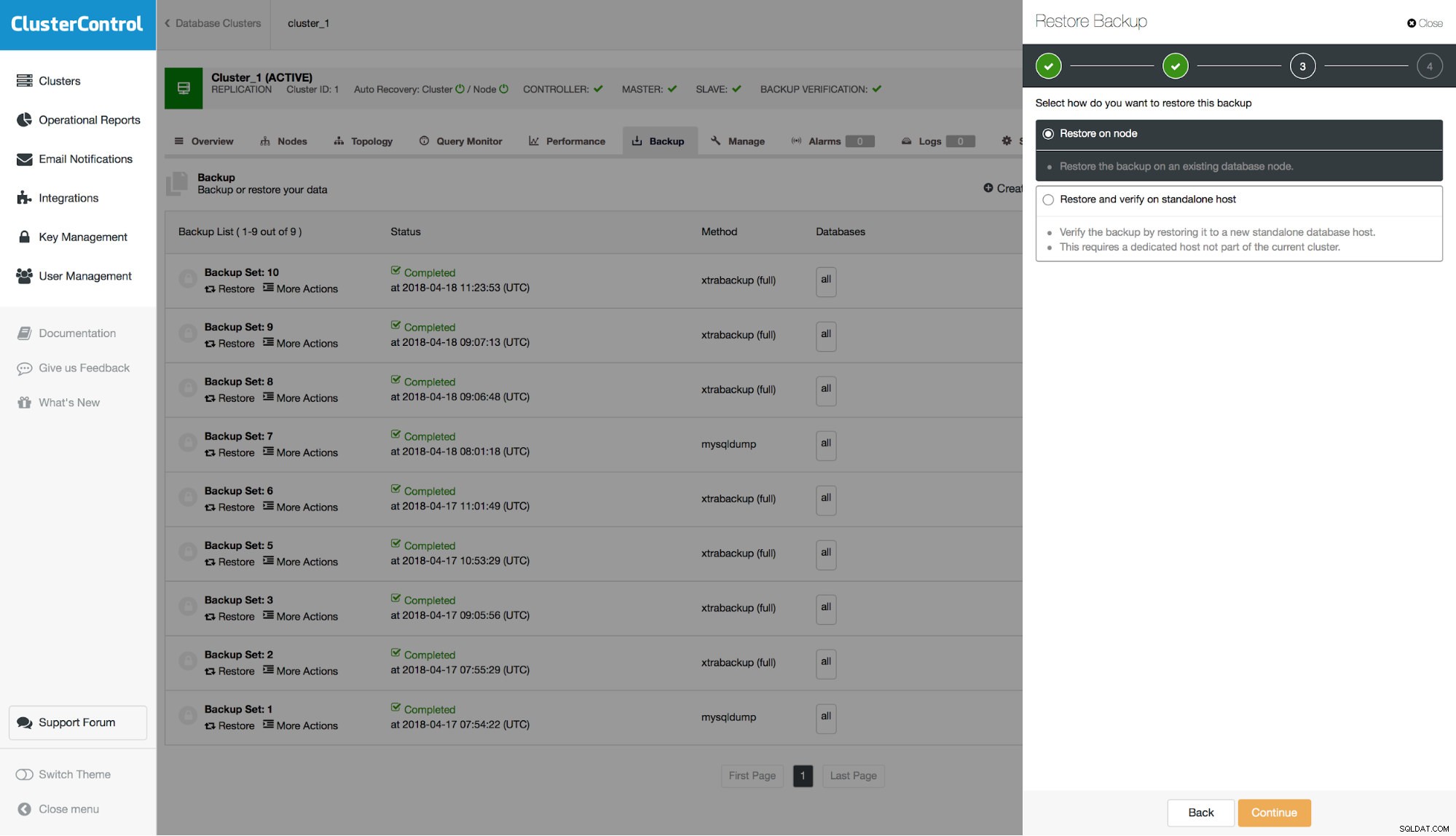
Następnie musimy zdecydować, czy zamierzamy przywrócić kopię zapasową w klastrze, czy też chcemy użyć zewnętrznego serwera do jej przywrócenia. Ta druga opcja może być przydatna, jeśli chcesz przywrócić tylko podzbiór danych. Możesz przywrócić pełną fizyczną kopię zapasową na osobnym hoście, a następnie użyć mysqldump, aby zrzucić brakujące dane i załadować je na serwer produkcyjny.
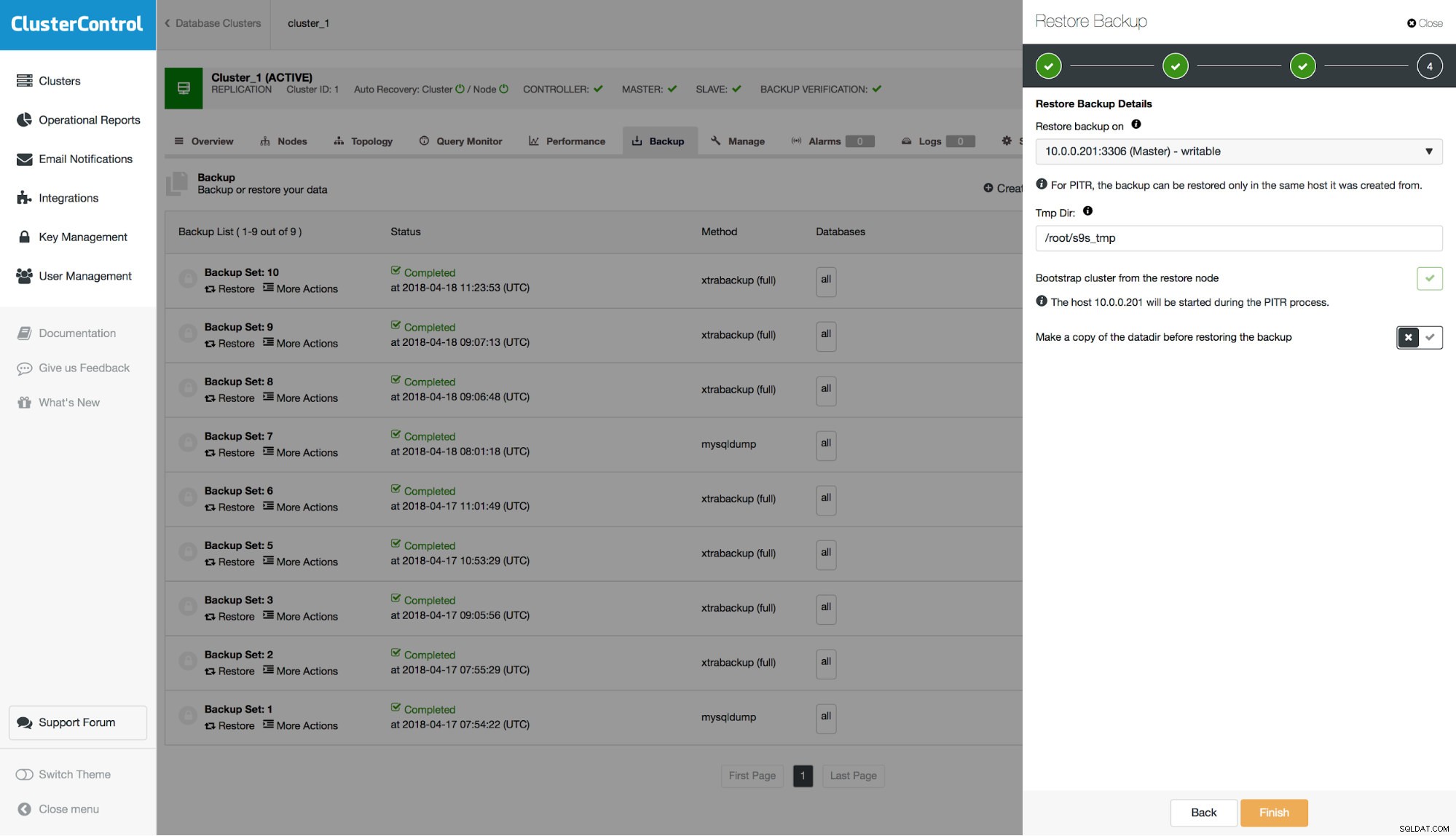
Należy pamiętać, że podczas przywracania kopii zapasowej w klastrze konieczne będzie odbudowanie węzłów innych niż odzyskany. W scenariuszu master - slave zazwyczaj będziesz chciał przywrócić kopię zapasową na urządzeniu master, a następnie odbudować z niego urządzenia slave.
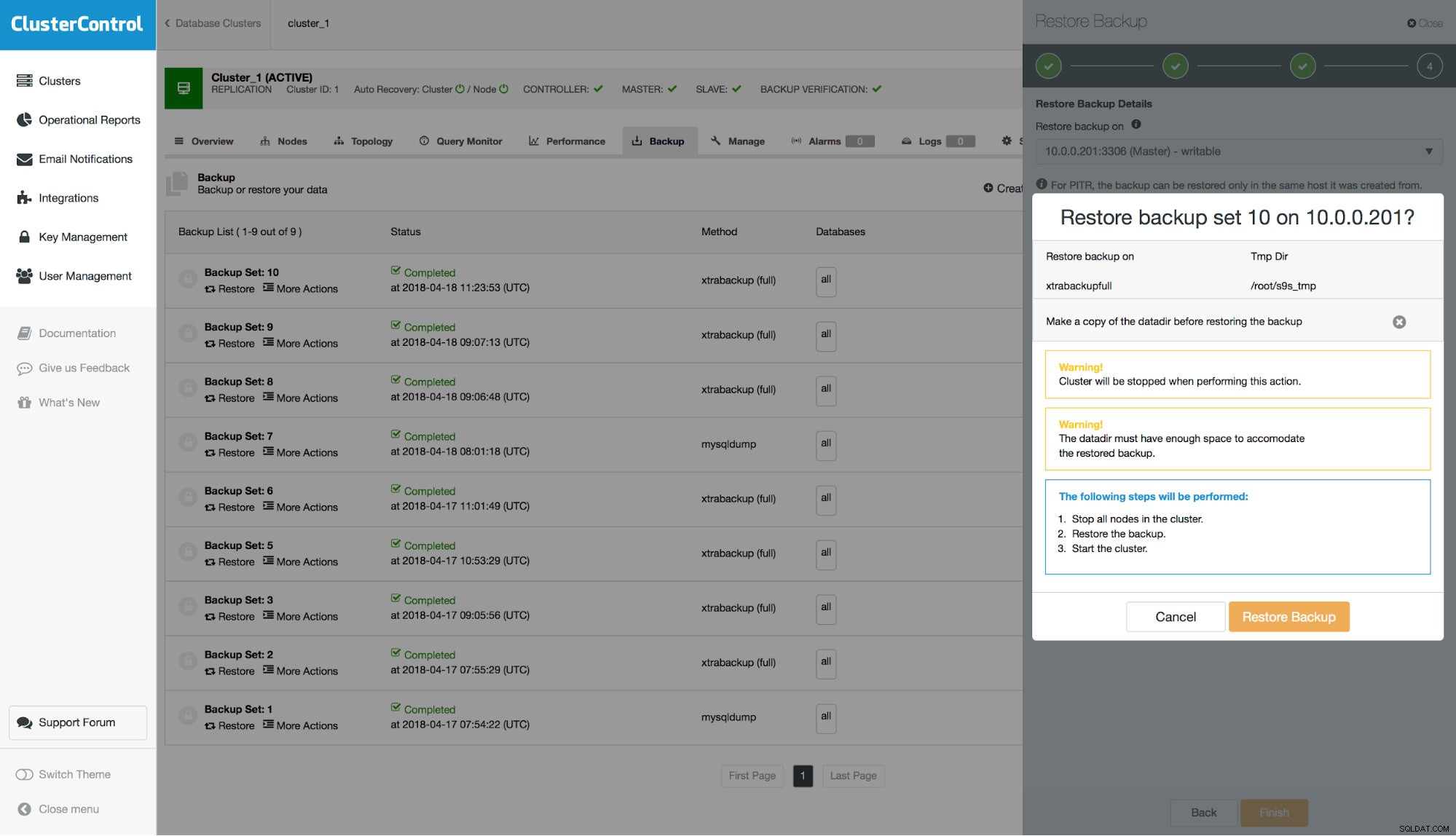
W ostatnim kroku zobaczysz podsumowanie działań, które wykona ClusterControl.
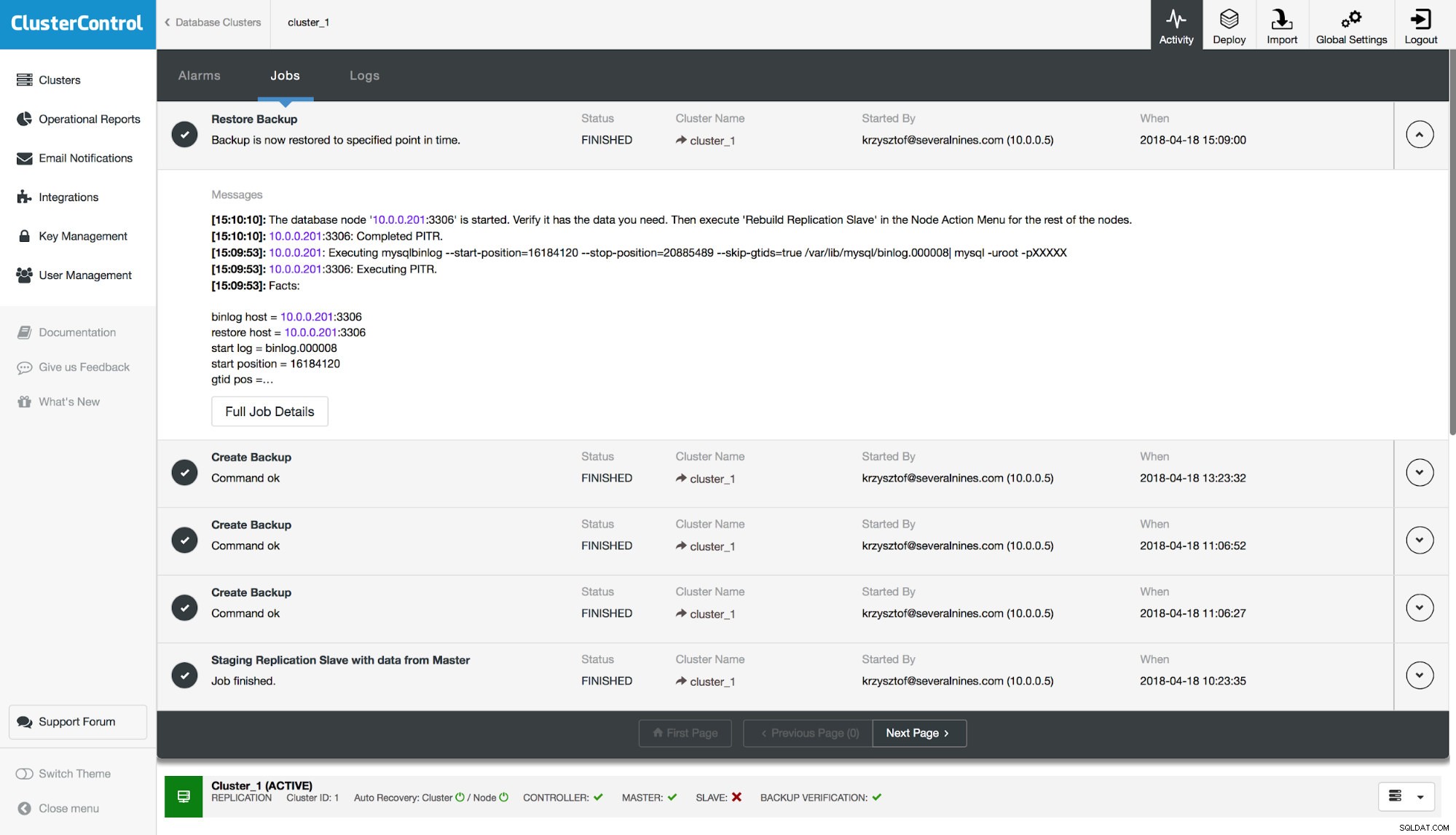
Na koniec, po przywróceniu kopii zapasowej, sprawdzimy, czy brakująca tabela została przywrócona, czy nie:
mysql> show tables from sbtest like 'sbtest1'\G
*************************** 1. row ***************************
Tables_in_sbtest (sbtest1): sbtest1
1 row in set (0.00 sec)Wszystko wydaje się w porządku, udało nam się przywrócić brakujące dane.
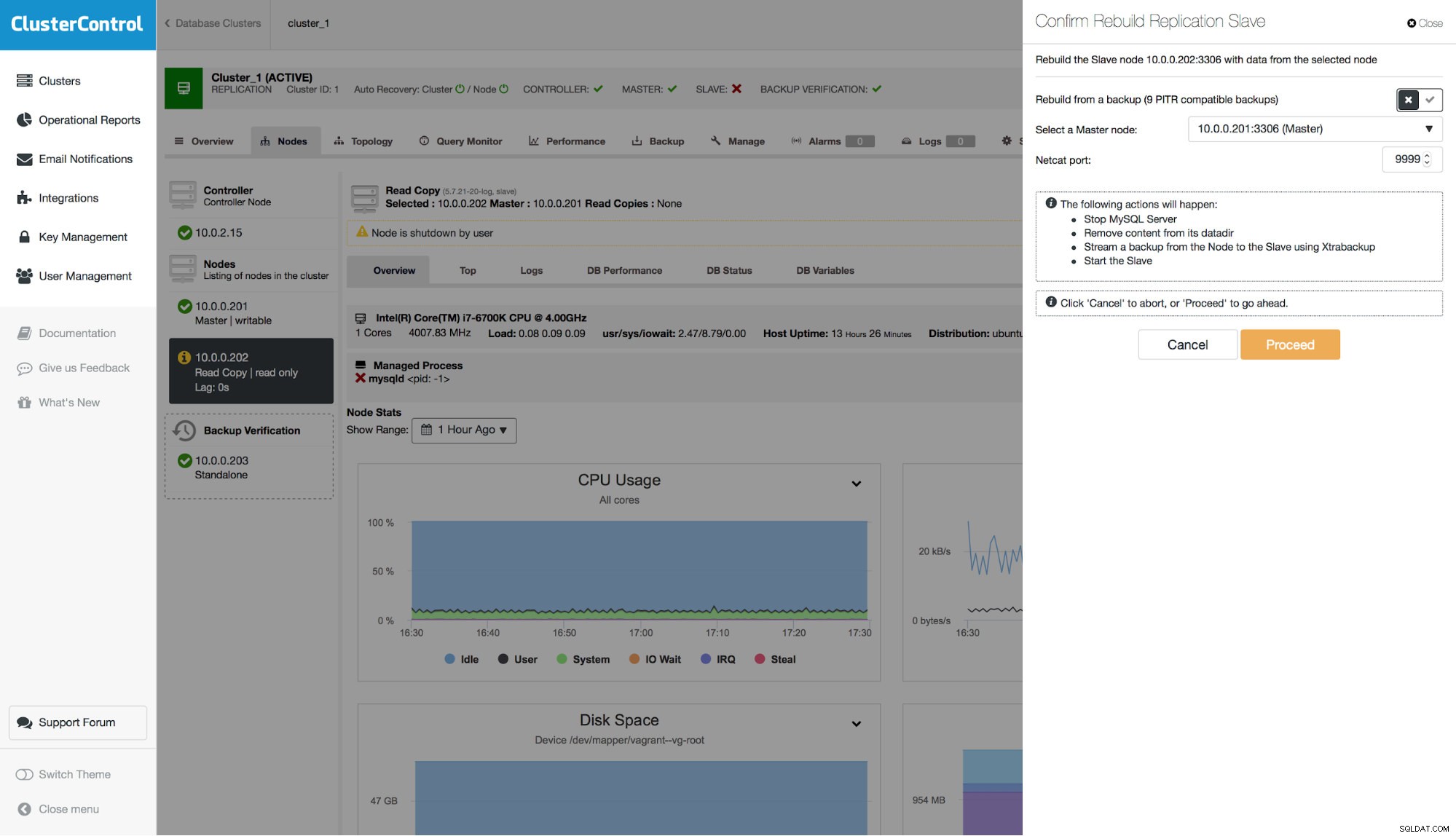
Ostatnim krokiem, jaki musimy zrobić, jest odbudowa naszego niewolnika. Należy pamiętać, że istnieje możliwość skorzystania z kopii zapasowej PITR. W tym przykładzie nie jest to możliwe, ponieważ urządzenie podrzędne replikuje zdarzenie DROP TABLE i nie jest zgodne z urządzeniem nadrzędnym.