Wprowadzenie do indeksów SQL Server
Microsoft SQL Server jest uważany za jeden z systemów zarządzania relacyjnymi bazami danych (RDBMS ), w którym dane są logicznie zorganizowane w wiersze i kolumny, które są przechowywane w kontenerach danych zwanych tabelami. Fizycznie tabele są przechowywane jako 8 KB strony które mogą być zorganizowane w klastrach typu Heap lub B-Tree. W Stopie tabeli, nie ma kolejności sortowania, która steruje kolejnością danych na stronach danych i sekwencją stron w tej tabeli, ponieważ w tej tabeli nie ma zdefiniowanego indeksu klastrowanego, który wymusiłby mechanizm sortowania. Jeśli indeks klastrowany jest zdefiniowany w jednej kolumnie z grupy kolumn tabeli, dane zostaną posortowane wewnątrz stron danych na podstawie wartości kolumn klucza indeksu klastrowanego, a strony zostaną połączone ze sobą na podstawie tych wartości klucza indeksu. Ta posortowana tabela nosi nazwę tabela klastrowa .
W SQL Server indeks jest uważany za ważny i skuteczny klucz w procesie dostrajania wydajności. Celem tworzenia indeksu jest przyspieszenie dostępu do tabeli podstawowej i pobieranie żądanych danych bez konieczności skanowania wszystkich wierszy tabeli w celu zwrócenia żądanych danych. Możesz myśleć o indeksie bazy danych jako indeksie książek, który pomaga szybko znaleźć słowa w książce, bez konieczności czytania całej książki, aby znaleźć to słowo. Załóżmy na przykład, że musisz pobrać informacje o konkretnym kliencie za pomocą identyfikatora klienta. Jeśli nie ma zdefiniowanego indeksu dla kolumny Identyfikator klienta w tej tabeli, aparat SQL Server sprawdza wszystkie wiersze tabeli, jeden po drugim, w celu pobrania klienta o podanym identyfikatorze. Jeśli indeks jest zdefiniowany dla kolumny Customer ID w tej tabeli, SQL Server Engine będzie szukał żądanych wartości Customer ID w posortowanym indeksie, a nie w tabeli podstawowej, aby pobrać informacje o kliencie, zmniejszając liczbę skanowanych wierszy do pobrania danych.
W SQL Server indeks ma strukturę logiczną 8K stron lub węzłów indeksu w postaci B-drzewa. Struktura B-Tree zawiera trzy poziomy:Poziom główny która zawiera jedną stronę indeksu u góry B-drzewa, Poziom Liścia który znajduje się na dole B-drzewa i zawiera strony danych oraz Poziom średniozaawansowany który obejmuje wszystkie węzły znajdujące się między korzeniem a poziomem liścia, z wartościami klucza indeksu i wskaźnikami do kolejnych stron. Ten kształt B-drzewa zapewnia szybki sposób poruszania się po stronach danych od lewej do prawej i od góry do dołu, w oparciu o klucz indeksu.
W SQL Server istnieją dwa główne typy indeksów:indeks klastrowy w którym rzeczywiste dane są przechowywane na stronach indeksu na poziomie liści, z możliwością utworzenia tylko jednego indeksu klastrowego dla każdej tabeli, ponieważ dane wewnątrz stron danych i kolejność stron będą sortowane na podstawie indeksu klastrowego klucz. Jeśli zdefiniujesz ograniczenie klucza podstawowego w tabeli, indeks klastrowy zostanie utworzony automatycznie, jeśli wcześniej nie zdefiniowano indeksu klastrowego dla tej tabeli. Drugi rodzaj indeksów to indeks nieklastrowy który zawiera posortowaną kopię kolumn klucza indeksu i wskaźnik do pozostałych kolumn w tabeli podstawowej lub indeksie klastrowym, z możliwością utworzenia do 999 indeksów nieklastrowych dla każdej tabeli.
SQL Server zapewnia nam inne specjalne typy indeksów, takie jak indeks unikalny który jest tworzony automatycznie po zdefiniowaniu ograniczenia przez unikalność w celu wymuszenia niepowtarzalności określonych wartości kolumn, indeks złożony w którym więcej niż jedna kolumna klucza będzie uczestniczyć w kluczu indeksu, indeks pokrywający w którym wszystkie kolumny żądane przez określone zapytanie będą uczestniczyć w kluczu indeksu, indeksie filtrowanym jest to zoptymalizowany indeks nieklastrowy z predykatem filtra do indeksowania tylko niewielkiej części wierszy tabeli, indeks przestrzenny tworzony w kolumnach przechowujących dane przestrzenne, indeks XML tworzony na dużych obiektach binarnych (BLOB) XML w kolumnach typu danych XML, indeks magazynu kolumn w którym dane są zorganizowane w kolumnowym formacie danych, indeks pełnotekstowy tworzony przez silnik pełnotekstowy programu SQL Server i indeks skrótu który jest używany w tabelach zoptymalizowanych pod kątem pamięci.
Jak zwykłem nazywać indeks SQL Server, jest to miecz obosieczny , gdzie SQL Server Query Optimizer może skorzystać z dobrze zaprojektowanego indeksu, aby poprawić wydajność aplikacji poprzez przyspieszenie procesu pobierania danych. W przeciwieństwie do tego indeks, który został zaprojektowany w zły sposób, nie zostanie wybrany przez Optymalizator zapytań SQL Server i obniży wydajność aplikacji, spowalniając operacje modyfikacji danych i zużywając pamięć bez wykorzystywania jej w danych procesy pobierania. Dlatego lepiej jest najpierw postępować zgodnie z najlepszymi praktykami i wytycznymi dotyczącymi tworzenia indeksu, sprawdzić efekt tworzenia środowiska programistycznego i znaleźć kompromis między szybkością operacji pobierania danych a narzutem na dodanie tego indeksu na operacje modyfikacji danych i wymagania dotyczące miejsca tego indeksu przed zastosowaniem go w środowisku produkcyjnym.
Przed utworzeniem indeksu należy przestudiować różne aspekty, które wpływają na tworzenie i używanie indeksu. Obejmuje to typ obciążenia bazy danych, przetwarzania transakcji online (OLTP) lub przetwarzania analitycznego online (OLAP), rozmiaru tabeli , cechy kolumn tabeli , kolejność sortowania kolumn w zapytaniu, typ indeksu który odpowiada zapytaniu i właściwościom przechowywania, takim jak FILLFACTOR i PAD_INDEX opcje, które kontrolują procent miejsca na każdym poziomie liścia i na stronach poziomu pośredniego, które mają być wypełnione danymi.
Fragmentacja indeksu serwera SQL
Twoja praca jako DBA nie ogranicza się do tworzenia właściwego indeksu. Po utworzeniu indeksu należy monitorować użycie indeksu i statystyki, na przykład trzeba wiedzieć, czy indeks ten jest używany słabo lub wcale. W ten sposób możesz podać właściwe rozwiązanie, aby utrzymać te indeksy lub zastąpić je bardziej wydajnymi. W ten sposób utrzymasz najwyższą możliwą wydajność swojego systemu. Możesz zadać sobie pytanie:Dlaczego SQL Server Query Optimizer nie używa już mojego indeksu, chociaż robił to wcześniej?
Odpowiedź dotyczy głównie ciągłych zmian danych i schematu, które są wykonywane w tabeli bazowej, które powinny znaleźć odzwierciedlenie w indeksach. Z biegiem czasu i przy wszystkich tych zmianach strony indeksu stają się nieposortowane, powodując fragmentację indeksu. Innym powodem fragmentacji jest próba wstawienia nowej wartości lub zaktualizowania wartości bieżącej, a nowa wartość nie mieści się w aktualnie dostępnym wolnym miejscu. W takim przypadku strona zostanie podzielona na dwie strony, gdzie nowa strona zostanie fizycznie utworzona po ostatniej stronie. I możesz sobie wyobrazić czytanie z pofragmentowanego indeksu i liczbę stron, które powinny zostać zeskanowane, i oczywiście liczbę operacji we/wy wykonanych w celu pobrania kilku rekordów ze względu na odległość między tymi stronami. A ze względu na ten dodatkowy koszt korzystania z tego pofragmentowanego indeksu, SQL Server Query Optimizer zignoruje ten indeks.
Różne sposoby uzyskania fragmentacji indeksu
SQL Server zapewnia nam różne sposoby na uzyskanie procentowej fragmentacji indeksu. Pierwszym sposobem jest sprawdzenie procentu fragmentacji indeksu w Indeksie Właściwości w oknie Fragmentacja jak pokazano poniżej:
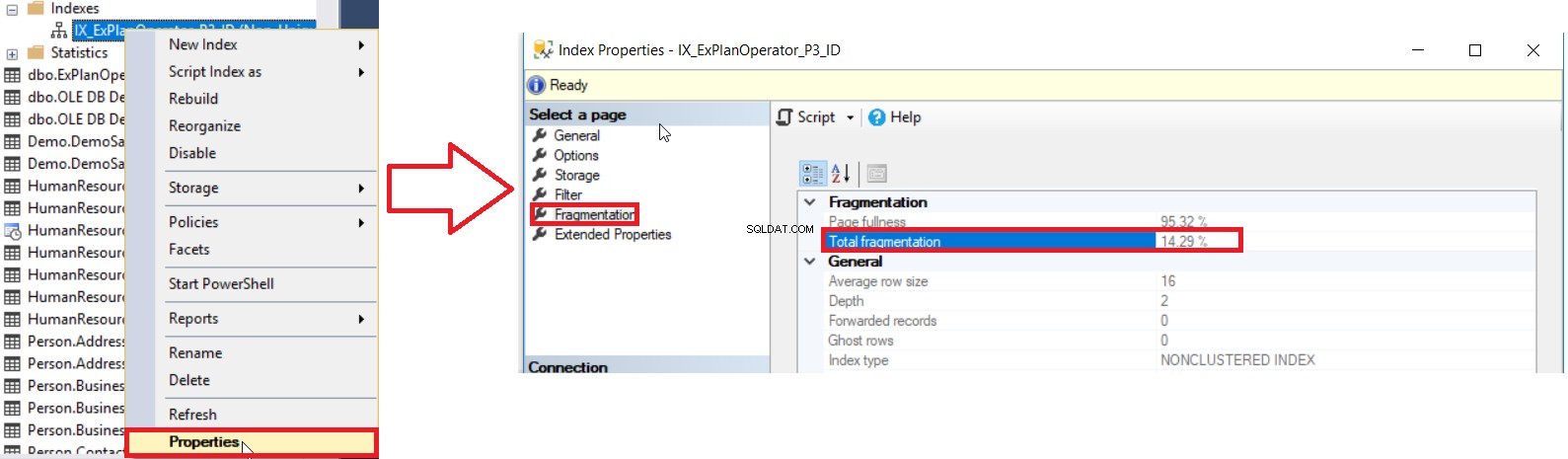
Aby jednak sprawdzić poziom fragmentacji wielu indeksów, należy najpierw przeprowadzić sprawdzenie metody interfejsu użytkownika dla wszystkich indeksów, jeden po drugim, co jest operacją czasochłonną. Drugą dostępną metodą sprawdzenia poziomu fragmentacji wszystkich indeksów bazy danych jest zapytanie DMF sys.dm_db_index_physical_stats i połączenie go z DMV sys.indexes w celu pobrania wszystkich informacji o tych indeksach, biorąc pod uwagę, że statystyki te zostaną odświeżone, gdy Usługa SQL Server jest uruchamiana ponownie przy użyciu zapytania podobnego do następującego:
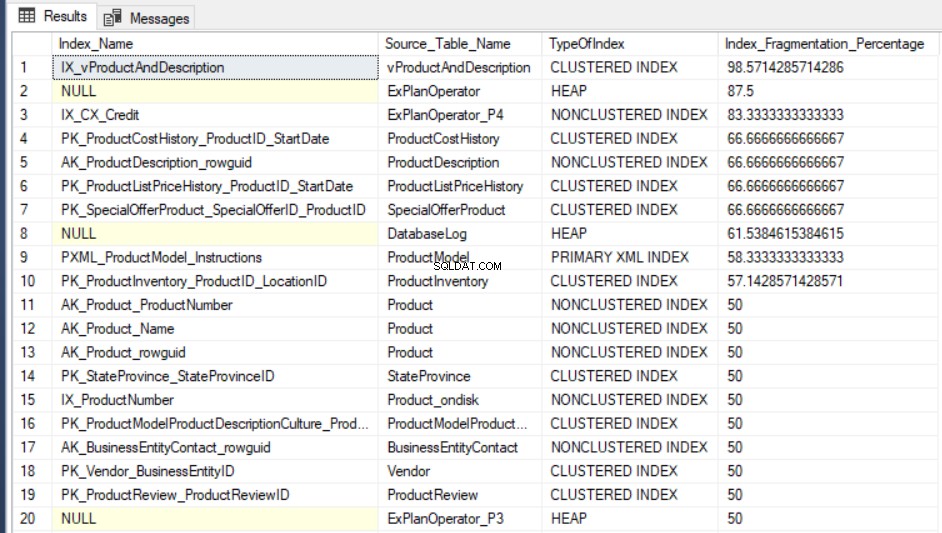
SELECT Indx.name AS Index_Name, OBJECT_NAME(Indx.OBJECT_ID) AS Source_Table_Name, Index_Stat.index_type_desc AS TypeOfIndex, Index_Stat.avg_fragmentation_in_percent Index_Fragmentation_Percentage FROM sys.dm_db_index_physical_stats(DB_ID(), NULL, NULL, NULL, NULL) Index_Stat INNER JOIN sys.indexes Indx ON Indx.object_id = Index_Stat.object_id AND Indx.index_id = Index_Stat.index_id ORDER BY Index_Fragmentation_Percentage DESC
Wynik wyjściowy zapytania AdventureWorks2016CTP3 testowa baza danych będzie podobna do następującej:
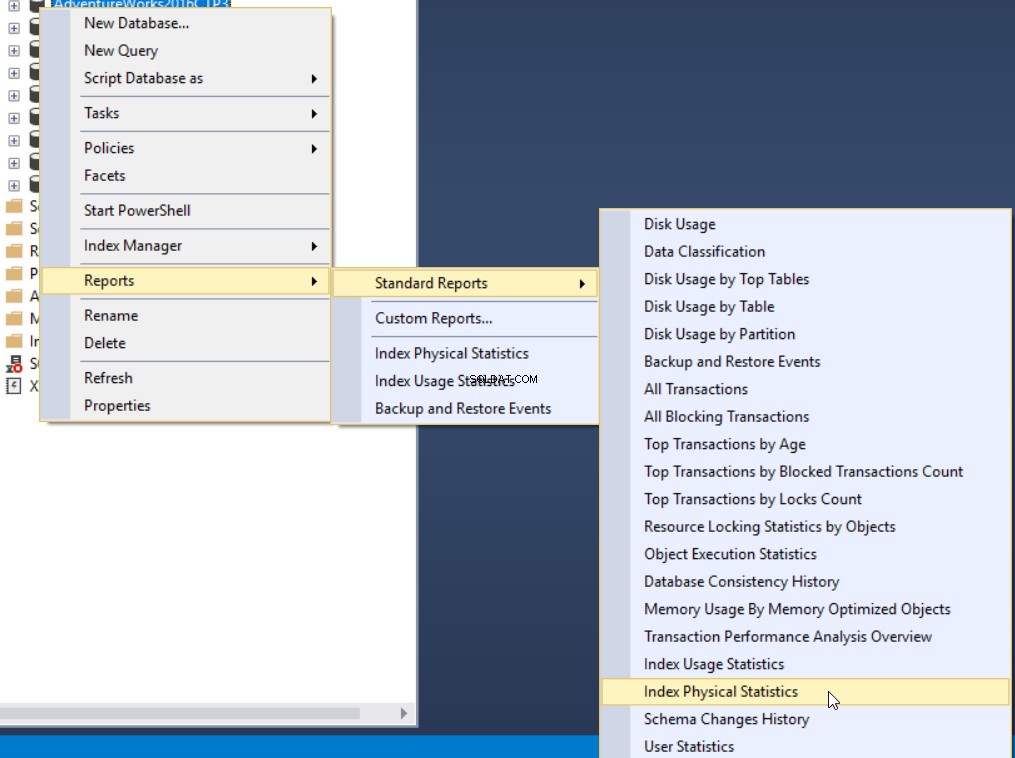
Trzecią metodą uzyskania procentu fragmentacji jest użycie wbudowanego w SQL Server standardowego raportu o nazwie Index Physical Statistics. Ten raport zawiera przydatne informacje na temat partycji indeksu, procentu fragmentacji, liczby stron w każdej partycji indeksu oraz zalecenia dotyczące sposobu rozwiązania problemu z fragmentacją indeksu przez odbudowanie lub reorganizację indeksu. Aby wyświetlić raport, kliknij prawym przyciskiem myszy swoją bazę danych, wybierz opcję Raporty, Raporty standardowe i wybierz Indeksuj statystyki fizyczne, jak poniżej:
W naszym przypadku wygenerowany raport będzie wyglądał tak:
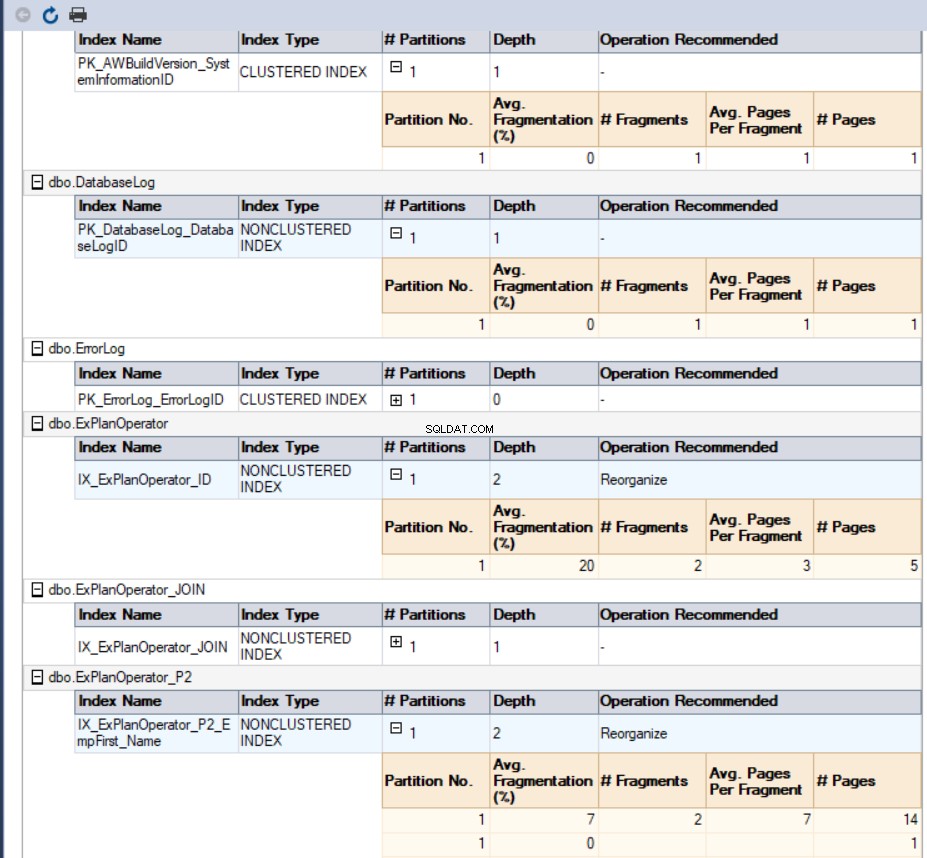
Ostatnim i najłatwiejszym sposobem pobrania procentu fragmentacji wszystkich indeksów bazy danych jest narzędzie dbForge Index Manager. Menedżer indeksu dbForge narzędzie to dodatek, który można dodać do SQL Server Management Studio w celu analizowania indeksów baz danych SQL Server, zapewniając bardzo przydatny raport ze stanem wybranych indeksów bazy danych i sugestiami dotyczącymi konserwacji, aby rozwiązać te problemy z fragmentacją indeksów.
Po zainstalowaniu dodatku dbForge Index Manager do swojego SSMS, możesz go uruchomić, klikając prawym przyciskiem myszy bazę danych do przeskanowania, wybierz Menedżer indeksów , a następnie Zarządzaj fragmentacją indeksu jak pokazano poniżej:
Narzędzie dbForge Index Manager pozwala uzyskać ogólny obraz fragmentacji wybranych indeksów bazy danych, z zaleceniami dotyczącymi odpowiednich działań w celu rozwiązania tego problemu, jak pokazano poniżej:

Narzędzie dbForge Index Manager umożliwia również przełączanie się między bazami danych, dostarczając nowy raport po zeskanowaniu tej bazy danych, jak pokazano poniżej:
Raport fragmentacji indeksów wygenerowany przez narzędzie dbForge Index Manager można wyeksportować do pliku CSV w celu przeanalizowania stanu fragmentacji indeksów, jak pokazano poniżej:
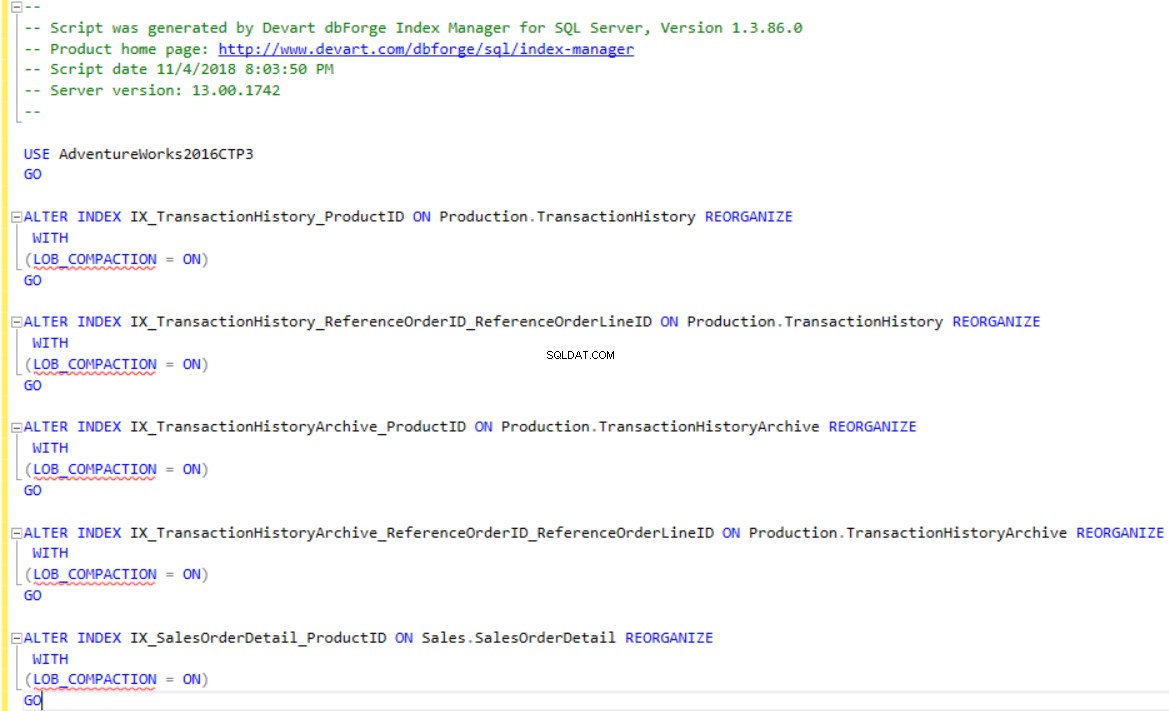
dbForge Index Manager umożliwia generowanie skryptów T-SQL do przebudowy lub reorganizacji indeksów zgodnie z zaleceniami narzędzia. Użyj Zmian skryptu opcja pokazania lub zapisania skryptu dla indeksów, które są pofragmentowane, jak pokazano poniżej:
Narzędzie dbForge Index Manager umożliwia naprawienie problemu fragmentacji indeksu bezpośrednio, klikając przycisk Napraw przycisk, który wykona zalecane działanie bezpośrednio na wybranych indeksach, pokazując stan naprawy w Wyniku kolumna, jak pokazano poniżej:

Jeśli klikniesz Przeanalizuj ponownie przycisk, ponownie przeskanuje fragmentację indeksu w bazie danych po pomyślnym wykonaniu operacji naprawy. To, co jest wymienione w tym artykule, jest tylko wstępem do tego, jak narzędzie dbForge Index Manager pomoże nam w identyfikacji i naprawie problemów z fragmentacją indeksu. Moją radą dla Ciebie jest pobranie go i sprawdzenie, co może Ci zaoferować to narzędzie.
Przydatne linki:
- Podstawy indeksowania
- Rodzaje indeksów
- Opisane indeksy klastrowe i nieklastrowe
- Struktury indeksów klastrowych
Przydatne narzędzie:
dbForge Index Manager – poręczny dodatek SSMS do analizy stanu indeksów SQL i rozwiązywania problemów z fragmentacją indeksów.



