Ten artykuł jest piątą częścią serii o wyrażeniach tabelowych. W części 1 przedstawiłem tło wyrażeń tabelowych. W części 2, części 3 i części 4 omówiłem zarówno logiczne, jak i optymalizacyjne aspekty tabel pochodnych. W tym miesiącu rozpoczynam omówienie wspólnych wyrażeń tabelowych (CTE). Podobnie jak w przypadku tabel pochodnych, najpierw zajmę się logicznym traktowaniem CTE, a w przyszłości przejdę do kwestii optymalizacji.
W moich przykładach użyję przykładowej bazy danych o nazwie TSQLV5. Skrypt, który go tworzy i wypełnia, można znaleźć tutaj, a jego diagram ER znajduje się tutaj.
CTE
Zacznijmy od terminu powszechne wyrażenie tabelowe . Ani ten termin, ani jego akronim CTE nie występują w specyfikacji normy ISO/IEC SQL. Możliwe więc, że termin pochodzi z jednego z produktów bazodanowych, a później został przyjęty przez niektórych innych dostawców baz danych. Znajdziesz go w dokumentacji Microsoft SQL Server i Azure SQL Database. T-SQL obsługuje to począwszy od SQL Server 2005. Standard używa terminu wyrażenie zapytania do reprezentowania wyrażenia, które definiuje jeden lub więcej CTE, w tym zapytanie zewnętrzne. Używa terminu z elementem listy do reprezentowania tego, co T-SQL nazywa CTE. Wkrótce przedstawię składnię wyrażenia zapytania.
Pomijając źródło terminu, powszechne wyrażenie tabelowe lub CTE , jest terminem powszechnie używanym przez praktyków T-SQL dla struktury, na której koncentruje się ten artykuł. Więc najpierw zastanówmy się, czy jest to odpowiedni termin. Doszliśmy już do wniosku, że termin wyrażenie tabelowe jest odpowiedni dla wyrażenia, które koncepcyjnie zwraca tabelę. Tabele pochodne, CTE, widoki i funkcje z wartościami w tabeli wbudowanej to wszystkie typy nazwanych wyrażeń tabelowych obsługiwanych przez T-SQL. Tak więc wyrażenie tabeli część wspólnego wyrażenia tabelowego z pewnością wydaje się właściwe. Co do wspólnego częścią tego terminu, prawdopodobnie ma to związek z jedną z zalet konstrukcyjnych współczynników CTE nad tabelami pochodnymi. Pamiętaj, że nie można ponownie użyć nazwy tabeli pochodnej (a dokładniej nazwy zmiennej zakresu) w zapytaniu zewnętrznym. I odwrotnie, nazwa CTE może być użyta wielokrotnie w zapytaniu zewnętrznym. Innymi słowy nazwa CTE jest powszechna do zewnętrznego zapytania. Oczywiście zademonstruję ten aspekt projektowania w tym artykule.
CTE dają podobne korzyści do tabel pochodnych, w tym umożliwiają tworzenie rozwiązań modułowych, ponowne wykorzystywanie aliasów kolumn, pośrednią interakcję z funkcjami okna w klauzulach, które normalnie na nie nie pozwalają, wspieranie modyfikacji, które pośrednio polegają na FETCH TOP lub OFFSET FETCH ze specyfikacją zamówienia, i inni. Istnieją jednak pewne zalety projektowe w porównaniu z tabelami pochodnymi, które omówię szczegółowo po dostarczeniu składni struktury.
Składnia
Oto standardowa składnia wyrażenia zapytania:
7.17
Funkcja
Określ tabelę.
Format
[
[
AS
|
[
|
[
|
[
|
[
CORRESPONDING [ BY
FETCH { FIRST | NEXT } [
|
7.18
Funkcja
Określ generowanie informacji o kolejności i wykrywaniu cykli w wyniku rekurencyjnych wyrażeń zapytań.
Format
SEARCH
GŁĘBOKOŚĆ FIRST BY
CYCLE
DEFAULT
7.3
Funkcja
Określ zestaw
Termin standardowy wyrażenie zapytania reprezentuje wyrażenie zawierające klauzulę WITH, z listą , który składa się z co najmniej jednego z elementami listy i zapytanie zewnętrzne. T-SQL odnosi się do standardu z elementem listy jako CTE.
T-SQL nie obsługuje wszystkich standardowych elementów składni. Na przykład nie obsługuje niektórych bardziej zaawansowanych rekurencyjnych elementów zapytań, które pozwalają kontrolować kierunek wyszukiwania i obsługiwać cykle w strukturze wykresu. Zapytania rekurencyjne są tematem artykułu w przyszłym miesiącu.
Oto składnia T-SQL dla uproszczonego zapytania względem CTE:
Oto przykład prostego zapytania dotyczącego CTE reprezentującego klientów z USA:
Znajdziesz te same trzy części w oświadczeniu przeciwko CTE, tak jak w przypadku oświadczenia przeciwko tabeli pochodnej:
To, co różni się od projektu CTE w porównaniu do tabel pochodnych, to lokalizacja w kodzie tych trzech elementów. W przypadku tabel pochodnych zapytanie wewnętrzne jest zagnieżdżone w klauzuli FROM zapytania zewnętrznego, a nazwa wyrażenia tabelowego jest przypisywana po samym wyrażeniu tabelowym. Elementy są ze sobą powiązane. I odwrotnie, w przypadku CTE kod oddziela trzy elementy:najpierw przypisujesz nazwę wyrażenia tabeli; po drugie określasz wyrażenie tabeli — od początku do końca bez przerw; po trzecie określasz zapytanie zewnętrzne — od początku do końca bez przerw. Później w sekcji „Rozważania projektowe” wyjaśnię implikacje tych różnic projektowych.
Słowo o CTE i użyciu średnika jako terminatora instrukcji. Niestety, w przeciwieństwie do standardowego SQL, T-SQL nie wymusza zakończenia wszystkich instrukcji średnikiem. Jednak w T-SQL jest bardzo niewiele przypadków, w których kod bez terminatora jest niejednoznaczny. W takich przypadkach wypowiedzenie jest obowiązkowe. Jeden z takich przypadków dotyczy faktu, że klauzula WITH jest używana do wielu celów. Jednym z nich jest zdefiniowanie CTE, drugim jest zdefiniowanie podpowiedzi tabeli dla zapytania, a jest kilka dodatkowych przypadków użycia. Na przykład w poniższej instrukcji klauzula WITH jest używana do wymuszenia serializowanego poziomu izolacji za pomocą wskazówki dotyczącej tabeli:
Potencjał niejednoznaczności występuje wtedy, gdy masz niezakończoną instrukcję poprzedzającą definicję CTE, w którym to przypadku parser może nie być w stanie stwierdzić, czy klauzula WITH należy do pierwszej czy drugiej instrukcji. Oto przykład ilustrujący to:
W tym przypadku parser nie może stwierdzić, czy klauzula WITH ma zostać użyta do zdefiniowania podpowiedzi do tabeli Customers w pierwszej instrukcji, czy też do uruchomienia definicji CTE. Pojawia się następujący błąd:
Poprawka polega oczywiście na zamknięciu instrukcji poprzedzającej definicję CTE, ale najlepszą praktyką jest zakończenie wszystkich instrukcji:
Być może zauważyłeś, że niektórzy ludzie zaczynają swoje definicje CTE jako praktyka od średnika, na przykład:
Celem tej praktyki jest zmniejszenie możliwości przyszłych błędów. Co się stanie, jeśli później ktoś doda niezakończoną wypowiedź tuż przed twoją definicją CTE w skrypcie i nie zawraca sobie głowy sprawdzaniem całego skryptu, a jedynie swoją wypowiedź? Twój średnik tuż przed klauzulą WITH faktycznie staje się ich terminatorem instrukcji. Z pewnością widać praktyczność tej praktyki, ale jest to trochę nienaturalne. Zalecane, choć trudniejsze do osiągnięcia, jest zaszczepienie w organizacji dobrych praktyk programistycznych, w tym usunięcie wszystkich oświadczeń.
Pod względem reguł składni, które mają zastosowanie do wyrażenia tabelowego używanego jako zapytanie wewnętrzne w definicji CTE, są one takie same, jak te, które mają zastosowanie do wyrażenia tabelowego używanego jako zapytanie wewnętrzne w definicji tabeli pochodnej. Są to:
Aby uzyskać szczegółowe informacje, zobacz sekcję „Wyrażenie tabelowe to tabela” w części 2 serii.
Jeśli zapytasz doświadczonych programistów T-SQL, czy wolą używać tabel pochodnych, czy CTE, nie wszyscy zgodzą się, co jest lepsze. Oczywiście różni ludzie mają różne preferencje stylizacyjne. Czasami używam tabel pochodnych, a czasami CTE. Dobrze jest być w stanie świadomie identyfikować specyficzne różnice językowe między tymi dwoma narzędziami i wybierać w oparciu o swoje priorytety w danym rozwiązaniu. Z czasem i doświadczeniem dokonujesz wyborów bardziej intuicyjnie.
Ponadto ważne jest, aby nie mylić użycia wyrażeń tabelowych i tabel tymczasowych, ale jest to dyskusja związana z wydajnością, którą omówię w przyszłym artykule.
CTE mają rekurencyjne możliwości zapytań, a tabele pochodne nie. Tak więc, jeśli musisz na nich polegać, naturalnie wybierzesz CTE. Zapytania rekurencyjne są tematem artykułu w przyszłym miesiącu.
W części 2 wyjaśniłem, że zagnieżdżanie tabel pochodnych jest dla mnie zwiększaniem złożoności kodu, ponieważ utrudnia to przestrzeganie logiki. Podałem następujący przykład, określając lata zamówień, w których zamówienia złożyło ponad 70 klientów:
CTE nie obsługują zagnieżdżania. Dlatego podczas przeglądania lub rozwiązywania problemów z rozwiązaniem opartym na CTE nie gubisz się w zagnieżdżonej logice. Zamiast zagnieżdżania, budujesz bardziej modułowe rozwiązania, definiując wiele CTE w ramach tej samej instrukcji WITH, oddzielone przecinkami. Każdy z CTE jest oparty na zapytaniu pisanym od początku do końca bez przerw. Uważam to za dobrą rzecz z punktu widzenia przejrzystości kodu i łatwości konserwacji.
Oto rozwiązanie powyższego zadania przy użyciu CTE:
Bardziej podoba mi się rozwiązanie oparte na CTE. Ale ponownie zapytaj doświadczonych programistów, które z powyższych dwóch rozwiązań preferują, i nie wszyscy się zgodzą. Niektórzy faktycznie wolą zagnieżdżoną logikę i możliwość zobaczenia wszystkiego w jednym miejscu.
Jedną z bardzo wyraźnych zalet CTE nad tabelami pochodnymi jest konieczność interakcji z wieloma wystąpieniami tego samego wyrażenia tabeli w rozwiązaniu. Zapamiętaj następujący przykład oparty na tabelach pochodnych z części 2 serii:
To rozwiązanie zwraca lata zamówień, liczbę zamówień w ciągu roku oraz różnicę między liczbą zamówień w bieżącym i poprzednim roku. Tak, możesz to zrobić łatwiej dzięki funkcji LAG, ale nie skupiam się tutaj na znalezieniu najlepszego sposobu na osiągnięcie tego bardzo konkretnego zadania. Używam tego przykładu, aby zilustrować pewne aspekty projektowania języka nazwanych wyrażeń tabelowych.
Problem z tym rozwiązaniem polega na tym, że nie można przypisać nazwy do wyrażenia tabelowego i ponownie użyć go w tym samym kroku przetwarzania kwerendy logicznej. Nazywasz tabelę pochodną po samym wyrażeniu tabeli w klauzuli FROM. Jeśli zdefiniujesz i nazwiesz tabelę pochodną jako pierwsze dane wejściowe sprzężenia, nie można również ponownie użyć tej nazwy tabeli pochodnej jako drugich danych wejściowych tego samego sprzężenia. Jeśli musisz połączyć dwa wystąpienia tego samego wyrażenia tabelowego, w przypadku tabel pochodnych nie masz innego wyboru, jak tylko zduplikować kod. To właśnie zrobiłeś w powyższym przykładzie. I odwrotnie, nazwa CTE jest przypisywana jako pierwszy element kodu spośród wyżej wymienionych trzech (nazwa CTE, zapytanie wewnętrzne, zapytanie zewnętrzne). W terminach dotyczących przetwarzania zapytań logicznych, zanim dojdziesz do zapytania zewnętrznego, nazwa CTE jest już zdefiniowana i dostępna. Oznacza to, że możesz wchodzić w interakcje z wieloma wystąpieniami nazwy CTE w zewnętrznym zapytaniu, na przykład:
To rozwiązanie ma wyraźną przewagę programowalności w stosunku do rozwiązania opartego na tabelach pochodnych, ponieważ nie trzeba utrzymywać dwóch kopii tego samego wyrażenia tabelowego. Jest więcej do powiedzenia na ten temat z perspektywy przetwarzania fizycznego i porównaj to z użyciem tabel tymczasowych, ale zrobię to w przyszłym artykule, który skupia się na wydajności.
Jedna z zalet kodu opartego na tabelach pochodnych w porównaniu z kodem opartym na CTE ma związek z właściwością zamknięcia, którą powinno posiadać wyrażenie tabeli. Pamiętaj, że właściwość domknięcia wyrażenia relacyjnego mówi, że zarówno dane wejściowe, jak i dane wyjściowe są relacjami, a zatem wyrażenie relacyjne może być użyte tam, gdzie oczekuje się relacji, jako dane wejściowe do jeszcze innego wyrażenia relacyjnego. Podobnie wyrażenie tabelowe zwraca tabelę i powinno być dostępne jako tabela wejściowa dla innego wyrażenia tabelowego. Dotyczy to zapytania opartego na tabelach pochodnych — można go używać tam, gdzie oczekiwana jest tabela. Na przykład możesz użyć zapytania opartego na tabelach pochodnych jako wewnętrznego zapytania definicji CTE, jak w poniższym przykładzie:
Jednak to samo nie dotyczy zapytania opartego na CTE. Mimo że koncepcyjnie ma być uważane za wyrażenie tabelowe, nie można go używać jako wewnętrznego zapytania w definicjach tabel pochodnych, podzapytaniach i samych CTE. Na przykład poniższy kod nie jest poprawny w T-SQL:
Dobrą wiadomością jest to, że możesz użyć zapytania opartego na CTE jako zapytania wewnętrznego w widokach i wbudowanych funkcjach z wartościami tabelarycznymi, które omówię w przyszłych artykułach.
Pamiętaj też, że zawsze możesz zdefiniować inne CTE na podstawie ostatniego zapytania, a następnie wywołać interakcję z zapytaniem zewnętrznym z tym CTE:
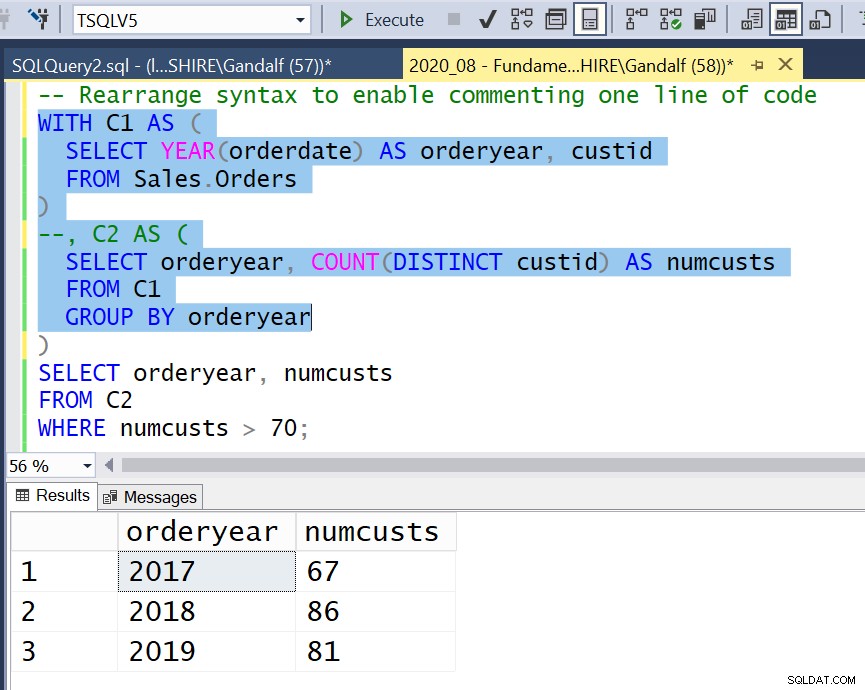
Z punktu widzenia rozwiązywania problemów, jak wspomniano, zwykle łatwiej jest mi postępować zgodnie z logiką kodu opartego na CTE w porównaniu z kodem opartym na tabelach pochodnych. Jednak rozwiązania oparte na tabelach pochodnych mają tę zaletę, że można podświetlić dowolny poziom zagnieżdżenia i uruchomić go niezależnie, jak pokazano na rysunku 1.
Z CTE rzeczy są trudniejsze. Aby kod zawierający CTE można było uruchomić, musi zaczynać się od klauzuli WITH, po której następuje jedno lub więcej nazwanych wyrażeń tabelowych w nawiasach oddzielonych przecinkami, po których następuje zapytanie bez nawiasów bez poprzedzającego przecinka. Jesteś w stanie podświetlić i uruchomić dowolne wewnętrzne zapytania, które są naprawdę niezależne, a także kompletny kod rozwiązania; jednak nie można wyróżnić i pomyślnie uruchomić żadnej innej pośredniej części rozwiązania. Na przykład Rysunek 2 pokazuje nieudaną próbę uruchomienia kodu reprezentującego C2.
Tak więc w przypadku CTE musisz uciec się do nieco niezręcznych środków, aby móc rozwiązać pośredni etap rozwiązania. Na przykład jednym z powszechnych rozwiązań jest tymczasowe wstawienie zapytania SELECT * FROM your_cte tuż pod odpowiednim CTE. Następnie podświetlasz i uruchamiasz kod, w tym wstrzyknięte zapytanie, a kiedy skończysz, usuwasz wstrzyknięte zapytanie. Rysunek 3 przedstawia tę technikę.
Problem polega na tym, że za każdym razem, gdy wprowadzasz zmiany w kodzie — nawet tymczasowe, drobne, takie jak powyżej — istnieje szansa, że przy próbie powrotu do oryginalnego kodu wprowadzisz nowy błąd.
Inną opcją jest nieco inny styl kodu, tak aby każda niepierwsza definicja CTE zaczynała się osobnym wierszem kodu, który wygląda tak:
Następnie za każdym razem, gdy chcesz uruchomić pośrednią część kodu do określonego CTE, możesz to zrobić przy minimalnych zmianach w kodzie. Używając komentarza do wiersza, komentujesz tylko ten jeden wiersz kodu, który odpowiada temu CTE. Następnie podświetlasz i uruchamiasz kod aż do wewnętrznego zapytania CTE, które jest teraz uważane za zapytanie zewnętrzne, jak pokazano na rysunku 4.
Jeśli nie jesteś zadowolony z tego stylu, masz jeszcze jedną opcję. Możesz użyć komentarza blokowego, który zaczyna się tuż przed przecinkiem poprzedzającym interesujący CTE i kończy się po otwartym nawiasie, jak pokazano na rysunku 5.
Sprowadza się to do osobistych preferencji. Zazwyczaj używam tymczasowo wstrzykniętej techniki zapytania SELECT *.
Istnieje pewne ograniczenie w obsłudze T-SQL dla konstruktorów wartości tabel w porównaniu ze standardem. Jeśli nie jesteś zaznajomiony z konstruktem, koniecznie zapoznaj się najpierw z częścią 2 serii, w której szczegółowo ją opiszę. Podczas gdy T-SQL umożliwia zdefiniowanie tabeli pochodnej na podstawie konstruktora wartości tabeli, nie pozwala na zdefiniowanie CTE na podstawie konstruktora wartości tabeli.
Oto obsługiwany przykład wykorzystujący tabelę pochodną:
Niestety podobny kod korzystający z CTE nie jest obsługiwany:
Ten kod generuje następujący błąd:
Istnieje jednak kilka obejść. Jednym z nich jest użycie zapytania do tabeli pochodnej, która z kolei jest oparta na konstruktorze wartości tabeli, jako wewnętrzne zapytanie CTE, na przykład:
Innym jest odwołanie się do techniki używanej przez ludzi przed wprowadzeniem konstruktorów z wartościami przechowywanymi w tabeli do T-SQL — przy użyciu serii zapytań FROMless oddzielonych operatorami UNION ALL, na przykład:
Zauważ, że aliasy kolumn są przypisywane zaraz po nazwie CTE.
Obie metody zostają zalgebrowane i zoptymalizowane w ten sam sposób, więc używaj tego, z którym Ci wygodniej.
Narzędziem, z którego dość często korzystam w swoich rozwiązaniach, jest pomocnicza tablica liczb. Jedną z opcji jest utworzenie tabeli liczb rzeczywistych w bazie danych i wypełnienie jej sekwencją o rozsądnej wielkości. Innym jest opracowanie rozwiązania, które generuje ciąg liczb w locie. W przypadku drugiej opcji chcesz, aby dane wejściowe były ogranicznikami pożądanego zakresu (nazwiemy je
Ten kod generuje następujące dane wyjściowe:
Pierwsze CTE o nazwie L0 oparte jest na konstruktorze wartości tabeli z dwoma wierszami. Rzeczywiste wartości są tam nieistotne; ważne jest to, że ma dwa rzędy. Następnie istnieje sekwencja pięciu dodatkowych CTE o nazwach od L1 do L5, z których każdy stosuje połączenie krzyżowe między dwoma wystąpieniami poprzedniego CTE. Poniższy kod oblicza liczbę wierszy potencjalnie generowanych przez każdy z CTE, gdzie @L jest numerem poziomu CTE:
Oto liczby, które otrzymujesz dla każdego CTE:
Przejście na poziom 5 daje ponad cztery miliardy wierszy. Powinno to wystarczyć w każdym praktycznym przypadku użycia, o którym myślę. Kolejny krok odbywa się w CTE o nazwie Nums. Za pomocą funkcji ROW_NUMBER można wygenerować sekwencję liczb całkowitych rozpoczynającą się od 1 w oparciu o niezdefiniowaną kolejność (ORDER BY (SELECT NULL)) i nazwać kolumnę wyników rownum. Na koniec, zewnętrzne zapytanie używa filtru TOP opartego na kolejności numerów wierszy, aby filtrować tyle liczb, ile żądana kardynalność sekwencji (@high – @low + 1) i oblicza liczbę wyniku n jako @low + rownum – 1.
Tutaj możesz naprawdę docenić piękno projektu CTE i oszczędności, które zapewnia, gdy budujesz rozwiązania w sposób modułowy. Ostatecznie proces rozpakowywania rozpakowuje 32 tabele, z których każda składa się z dwóch wierszy opartych na stałych. Widać to wyraźnie w planie wykonania tego kodu, jak pokazano na rysunku 6 za pomocą SentryOne Plan Explorer.
Każdy operator Constant Scan reprezentuje tabelę stałych z dwoma wierszami. Chodzi o to, że operator Top jest tym, który żąda tych wierszy i zwiera spięcie po otrzymaniu żądanej liczby. Zwróć uwagę na 10 wierszy wskazanych nad strzałką przechodzącą do operatora Top.
Wiem, że ten artykuł koncentruje się na koncepcyjnym potraktowaniu CTE, a nie na rozważaniach fizycznych/wydajnościowych, ale patrząc na plan, możesz naprawdę docenić zwięzłość kodu w porównaniu z rozwlekłością tego, na co przekłada się za kulisami.
Korzystając z tabel pochodnych, można w rzeczywistości napisać rozwiązanie, w którym każde odwołanie CTE zostanie zastąpione bazowym zapytaniem, które reprezentuje. To, co otrzymujesz, jest dość przerażające:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Format
WARTOŚCI
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Nieprawidłowa składnia w pobliżu „UC”. Jeśli ma to być wspólne wyrażenie tabelowe, musisz wyraźnie zakończyć poprzednią instrukcję średnikiem. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Rozważania projektowe
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Rysunek 1:Potrafi podświetlić i uruchomić część kodu za pomocą tabel pochodnych
Rysunek 1:Potrafi podświetlić i uruchomić część kodu za pomocą tabel pochodnych  Rysunek 2:Nie można podświetlić i uruchomić części kodu za pomocą CTE
Rysunek 2:Nie można podświetlić i uruchomić części kodu za pomocą CTE  Rysunek 3:Wstrzyknij SELECT * poniżej odpowiedniego CTE
Rysunek 3:Wstrzyknij SELECT * poniżej odpowiedniego CTE , cte_name AS (
 Rysunek 4:Zmień składnię, aby umożliwić komentowanie jednego wiersza kodu
Rysunek 4:Zmień składnię, aby umożliwić komentowanie jednego wiersza kodu  Rysunek 5:Użyj komentarza blokującego
Rysunek 5:Użyj komentarza blokującego Konstruktor wartości tabeli
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Nieprawidłowa składnia w pobliżu słowa kluczowego „VALUES”. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Tworzenie ciągu liczb
@low i @high ). Chcesz, aby Twoje rozwiązanie obsługiwało potencjalnie duże zasięgi. Oto moje rozwiązanie do tego celu, wykorzystujące CTE, z żądaniem zakresu od 1001 do 1010 w tym konkretnym przykładzie:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardynalność L0 2 L1 4 L2 16 L3 256 L4 65 536 L5 4.294.967.296  Rysunek 6:Plan generowania sekwencji liczb w zapytaniach
Rysunek 6:Plan generowania sekwencji liczb w zapytaniach DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Podsumowanie
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes